Redis为什么执行这么快?
1.基于内存存储实现。
我们都知道内存读写比在磁盘快很多的,Redis基于内存储存实现的数据。相对于数据库存在磁盘的MySql数据库,剩余磁盘I/O的消耗
2.redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正是因为单线程,如果某个命令执行过长如 keys,hgetall命令。会造成阻塞。
3.虚拟内存机机制
Redis直接构建了VM机制。不会像一般的系统调用系统函数处理,会浪费一定的时间去移动和请求。(备注:Redis的虚拟内存机制是啥? 虚拟内存机制就是暂时把不经常访问的数据从 内存交换到磁盘中,从而腾出宝贵的空间用于需要访问呢的数据(热数据))。通过VM功能可以实现冷热数据分离,是热数据人在内存中,冷数据保存在磁盘中,这样就 避免因为内存不足而造成访问数据下降的问题。
说说Redis的基本数据类型。
Redis常用的五种基本类型。
String(字符串),Hash(哈希),List(列表),Set(集合),Zset(排序集合)

String(字符串)
String字符串是Redis最基础的数据结构类型,他是二进制安全的,可以储存图片和序列化对象,最大值储存之512M.
简单使用举例:set key value, get key 等
使用场景:共享session,技术器,限流。
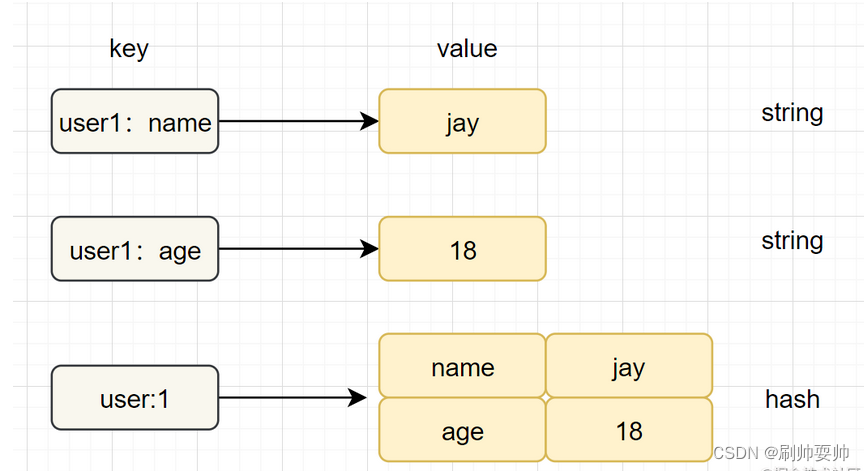
Hash(哈希)
简介:在Redis中。哈希类型是v(值)本身就是一个键值对(k-v)结构
简单使用举列:hset key field value,hget key field
应用场景:缓存用户信息等。
注意:如果开发使用 hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan.
List(列表)
简介:list类型用于储存多个有序的字符串,一个列表最多可以存储2^32-1个元素
应用场景:消息队列,文章队列
Set(集合)
简介:集合(Set)类型也是用于保存多个的字符串元素,但是不允许重复元素
简单使用举例:sadd key element [element ...]、smembers key
注意点:smembers和 lrange、hgetall 都数据比较中的命令,如果元素过多存在阻塞 Redis的可能,可以使用sscan 来完成。
应用场景: 用户标签,生成随机数抽奖,社交需求
有序集合(zset)
简介:已排序的字符串集合,同时元素不能重复
使用场景:积分排行榜,用户点赞排行榜。
什么是缓存击穿、缓存穿透、缓存雪崩?
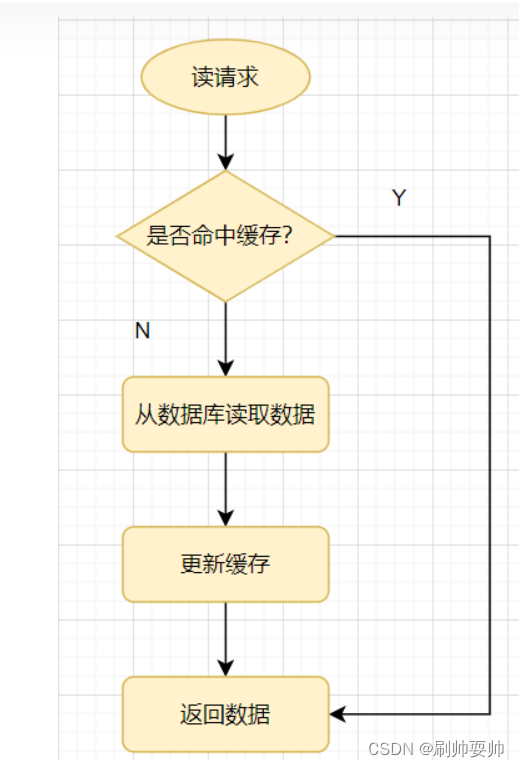
先来看一个常见的缓存使用方式:读请求来了,先查下缓存,缓存有值命中,就直接返回;缓存没有命中,就去查询数据库,然后把数据库的值更新到缓存,在返回。
缓存穿透:指的是 查询一个一定不存在的数据,由于缓存是不命中需要去数据库,导致这个不存在的数据每次请求都要到数据库查询,从而给数据库带来压力。
通俗点:读请求访问时,缓存和数据库都没有某个值,这样就会导致每次对这个值的查询请求都会穿透到数据库,这就缓存穿透。
缓存穿透一般都是这几中情况产生的:
业务/运维/开发 事务的操作,比如缓存和数据库的数据都被误删了。
客户非法请求攻击,比如客户故意捏造大量非法请求,读取不存在的业务数据。
解决方案:
1.缓存空对象。
指的是在持久层没有命中的情况下,对key进行set(key,null)。尽管这种垃圾浪费了一些 内存空间,在redis内存空间优先的前提时,会影响其他热点key的命中率,所以,比较有效的的方法时正对这类数据设计一个较短的ttl,让其自动删除
2.布隆过滤器拦截。
在访问缓存层和持久层前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,当收到一个对key请求时先用布控过滤器验证key是否存在。如果存在进入缓存层、持久层。
{对于布隆过滤器的理解:布隆过滤器实际就是一个很长的二进制向量和一些列随机函数。布隆过滤器就是用于检查一个元素是否在一个集合中}。
他的优点就是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
缓存击穿:
当前key是一个热点key(列如一个秒杀活动),并发量很大。在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用奔溃。
解决方案:
分布式互斥锁,其他线程等待 重建缓存的线程执行完毕后,重新从从缓存获取即可。
缓存雪崩问题:
缓存雪崩:指的缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据数据库压力过大甚至down机。
可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
做二级缓存,或者双缓存策略:
采用多级缓存,本地进程作为一级缓存,redis作为二级缓存,不同级别的缓存设置的超时时间不同,即使某级缓存过期了,也有其他级别缓存兜底
如何保证redis 和MySQL数据的一致性。
读取binlog后分析,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
Redis 的持久化机制有哪些?优缺点说说
Redis是基于内存的非关系K-V数据库,既然他是基于内存的,如果Redis服务器挂了,数据就会丢失。为了避开数据丢失,Redis提供了持久化,就是把数据保存到磁盘。
Redis提供了RDB和AOF 两种持久化机制,它持久化文件加载流程如下:
RDB ,就是内存数据以快照的形式保存到磁盘上。
RDB持久化,是指在指定的时间间隔内,执行指定次数的写操作,将内存中的数据集快照写入磁盘中,它是Redis 默认的持久化方式。执行完操作后,会在指定目录下生成一个dump.rdb文件,Redis重启的时候,通过加载dump.rdb文件来恢复数据。
RDB的优点:
适合大规模的数据回复场景,如备份,全量复制等。
RDB缺点:
没办法做到实时 秒级持久化。
AOF(append only file)持久化,采用日志的形式 来记录每个写的操作,追加到文件中,重启时重新执行AOF文件中的命令 来回复数据。它主要解决数据持久化实时性问题。默认时不开启的。
AOF的优点:
数据的一致性和完整性更高。
AOF的缺点:
AOF记录的内容越多,文件越大,数据恢复变慢
延时双删策略:
先进行缓存清除,再执行update,最后(延迟N秒)再执行缓存清除。
那么第二次为什么需要在数据库修改后延迟一定时间再删除redis呢?
为了等待之前的一次读取数据库,并等待其数据写入到缓存,最后删除这次脏数据,所以是一次数据从数据库中发到服务器+缓存写入的时间
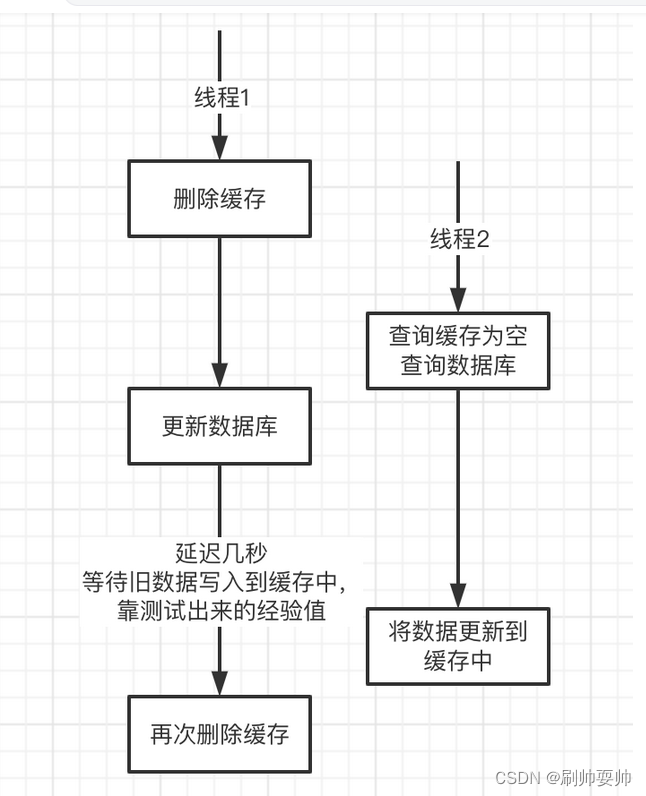
缺点:存在延时操作,所以会造成服务器的阻塞, 所以不适合高并发的场景