文章目录
- 前言
- NLP 历史回顾
- NLP任务
- 语料的标注
- AI语料标注师岗位职责
- Transformers
- Hugging Face
- 模型
- 中文文本分类
- 使用 NLTK 进行文本分类
- 参考链接
- 开源NLP
前言
学习NLP,解决两个问题:
- 如何使用别人训练好的模型?
- 如何基于别人的模型,加入自己的数据,训练得到自己的模型?
NLP 历史回顾
文法规则->统计语言学->神经网络方法
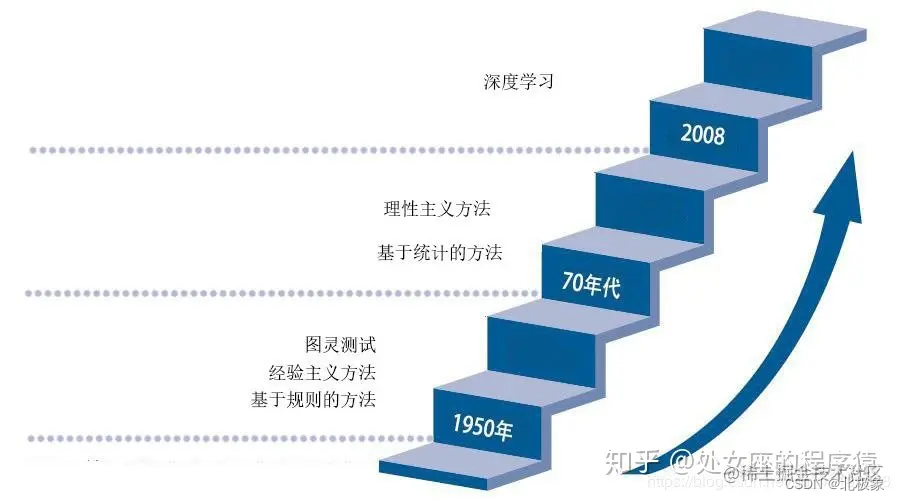
2017年谷歌提出了Transformer架构模型,2018年底,基于Transformer架构,谷歌推出了bert模型,bert模型一诞生,便在各大11项NLP基础任务中展现出了卓越的性能(一个排名榜单),现在很多模型都是基于或参考Bert模型进行改造。
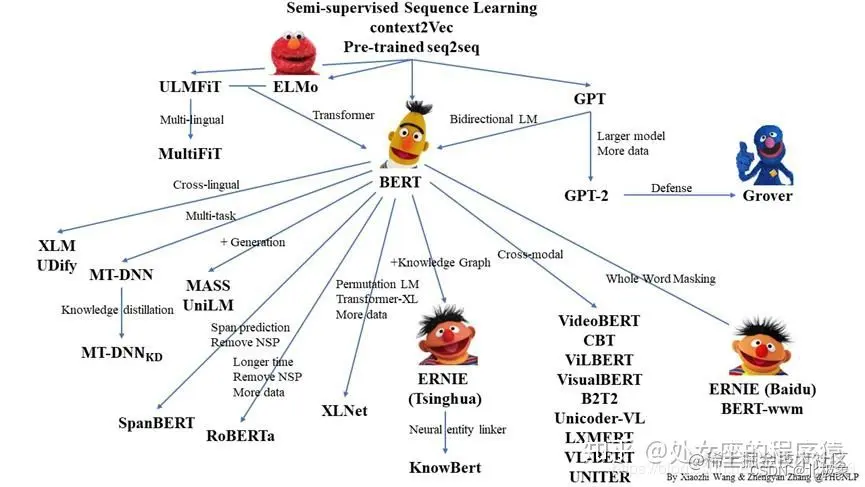
Transformer 架构是自然语言处理领域最近几乎所有主要发展的核心。这种 Transformer 架构的性能优于 RNN 和 CNN(卷积神经网络)。而且训练模型所需的计算资源也大为减少。
BERT (Bidirectional Encoder Representations)双向编码器表示是第一个无监督、深度双向的自然语言处理模型预训练系统。它只使用纯文本语料库进行训练。
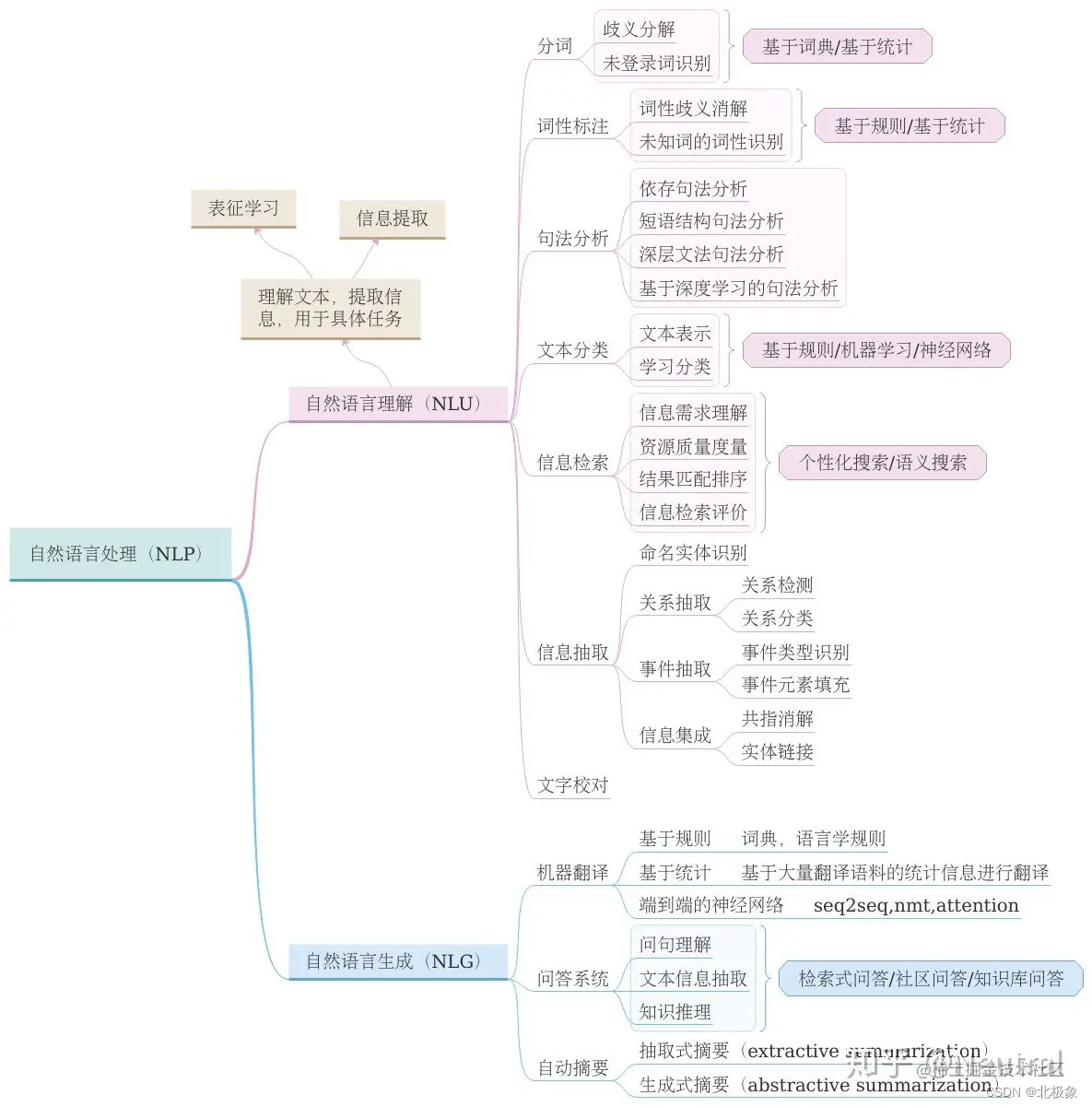
NLP任务
目前NLP可以处理的任务主要包含以下几个大类:问答系统,文档摘要,机器翻译,语音识别,文档分类等。
语料的标注
标注工具的选择,市面上有多种标注工具可供选择,例如MAE, Callisto,Brandeis Annotation Tool,Prodigy(收费)等。
AI语料标注师岗位职责
1.负责语料库的收集、整理和分类工作
2.根据需求完成数据预处理任务
3.使用自然语言处理技术对语料进行解析和分析,并产生文本数据
4.通过分析数据和算法实现自动化文本分类模型训练
5.持续优化模型性能和精度,提升效果
6.编写相关文档资料等,协助其他人员使用语料库
7.维护语料库并进行定期更新和维护
Transformers
Transformers 是由 Hugging Face 开发的一个 NLP 包,支持加载目前绝大部分的预训练模型。随着 BERT、GPT 等大规模语言模型的兴起,越来越多的公司和研究者采用 Transformers 库来构建 NLP 应用。
Hugging Face
Hugging Face Hub 平台为自然语言处理社区提供了一个中心化的地方,使人们可以共享和发现各种自然语言处理模型和数据集。该公司主要是提供nlp服务,同时它提供了一个很🐂的开源社区,这里可以找到大部分开源model。其对外提供了一个库 Transformers,Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成,并且Transformers 与 PyTorch、 TensorFlow 无缝整合。
功能包括:
- 模型
- 数据集
- 模型验证
- 模型部署等
使开发人员可以更轻松地管理和使用自然语言处理模型,任何人都可以利用机器学习进行探索、实验、合作和构建技术。
模型
中文文本分类
中文文本分类,TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention, DPCNN, Transformer, 基于pytorch,开箱即用。
使用 NLTK 进行文本分类
使用朴素贝叶斯分类器训练:
from nltk.classify import NaiveBayesClassifiertrain_texts = [# ...
]
train_labels = [# ...
]train_features = [extract_feature(text) for text in train_texts]
train_samples = list(zip(train_features, train_labels))
classifier = NaiveBayesClassifier.train(train_samples)
评估:
from nltk.classify import accuracytest_texts = [# ...
]
test_labels = [# ...
]test_features = [extract_feature(text) for text in test_texts]
test_samples = list(zip(test_features, test_labels))
acc = accuracy(classifier, test_samples)
参考链接
- https://transformers.run/
- huggingface github
- Hugging Face
- 汉语自然语言处理
- 汉语自然语言处理-BERT的解读语言模型预训练
- 前端工程师如何快速使用一个NLP模型
- A Survey of Large Language Models
- 预训练模型下载
- 从零开始训练GPT
- 知乎看山杯第一名解决方案
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
- 知乎“看山杯” 夺冠记
开源NLP
- PaddleNLP
- HanLP

![[ 云计算 | AWS 实践 ] 使用 Java 列出存储桶中的所有 AWS S3 对象](https://img-blog.csdnimg.cn/a82e8ccbf79d485299e41259558d41a5.png)