目录
- 本文内容
- 先决条件
- 使用 Apache Spark 进行交互式数据整理
- Azure 机器学习笔记本中的无服务器 Spark 计算
- 从 Azure Data Lake Storage (ADLS) Gen 2 导入和整理数据
- 从 Azure Blob 存储导入和处理数据
- 从 Azure 机器学习数据存储导入和整理数据
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

本文内容
数据整理已经成为机器学习项目中最重要的步骤之一。 Azure 机器学习与 Azure Synapse Analytics 集成,提供对 Apache Spark Pool(由 Azure Synapse 支持)的访问,以便使用 Azure 机器学习笔记本进行交互式数据整理。
先决条件
- 一个 Azure 订阅;如果你没有 Azure 订阅,请在开始之前创建一个免费帐户。
- Azure 机器学习工作区。 请参阅创建工作区资源。
- Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 请参阅创建 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。
- (可选):Azure Key Vault。 请参阅创建 Azure 密钥保管库。
- (可选):服务主体。 请参阅创建服务主体。
- (可选)Azure 机器学习工作区中附加的 Synapse Spark 池。
在开始数据整理任务之前,请了解存储机密的过程
- Azure Blob 存储帐户访问密钥
- 共享访问签名 (SAS) 令牌
- Azure Data Lake Storage (ADLS) Gen 2 服务主体信息
在 Azure 密钥保管库中。 还需要了解如何在 Azure 存储帐户中处理角色分配。 下面的部分讨论以下概念。 然后,我们将详细了解如何使用 Azure 机器学习笔记本中的 Spark 池进行交互式数据整理。
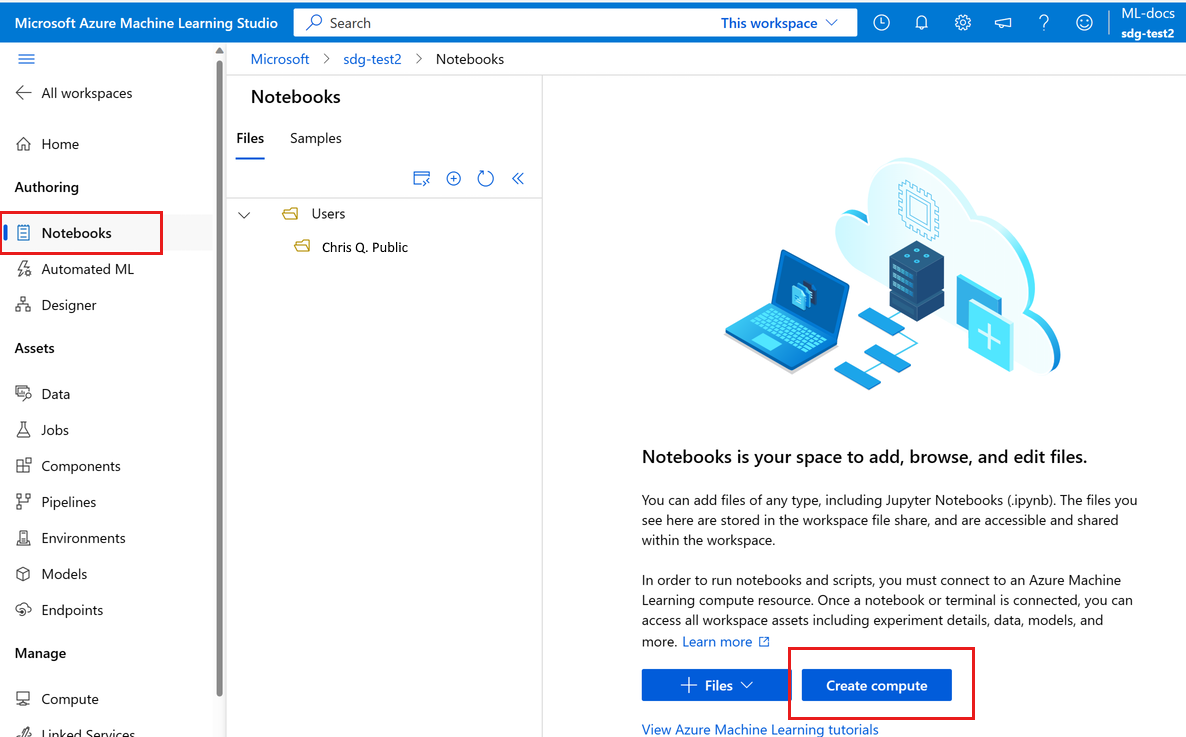
使用 Apache Spark 进行交互式数据整理
Azure 机器学习在 Azure 机器学习笔记本中提供无服务器 Spark 计算和附加的 Synapse Spark 池,用于与 Apache Spark 进行交互式数据整理。 无服务器 Spark 计算不需要在 Azure Synapse 工作区中创建资源。 相反,在 Azure 机器学习笔记本中可以直接使用完全托管的无服务器 Spark 计算。 要访问 Azure 机器学习中的 Spark 群集,最简单的方法是使用无服务器 Spark 计算。
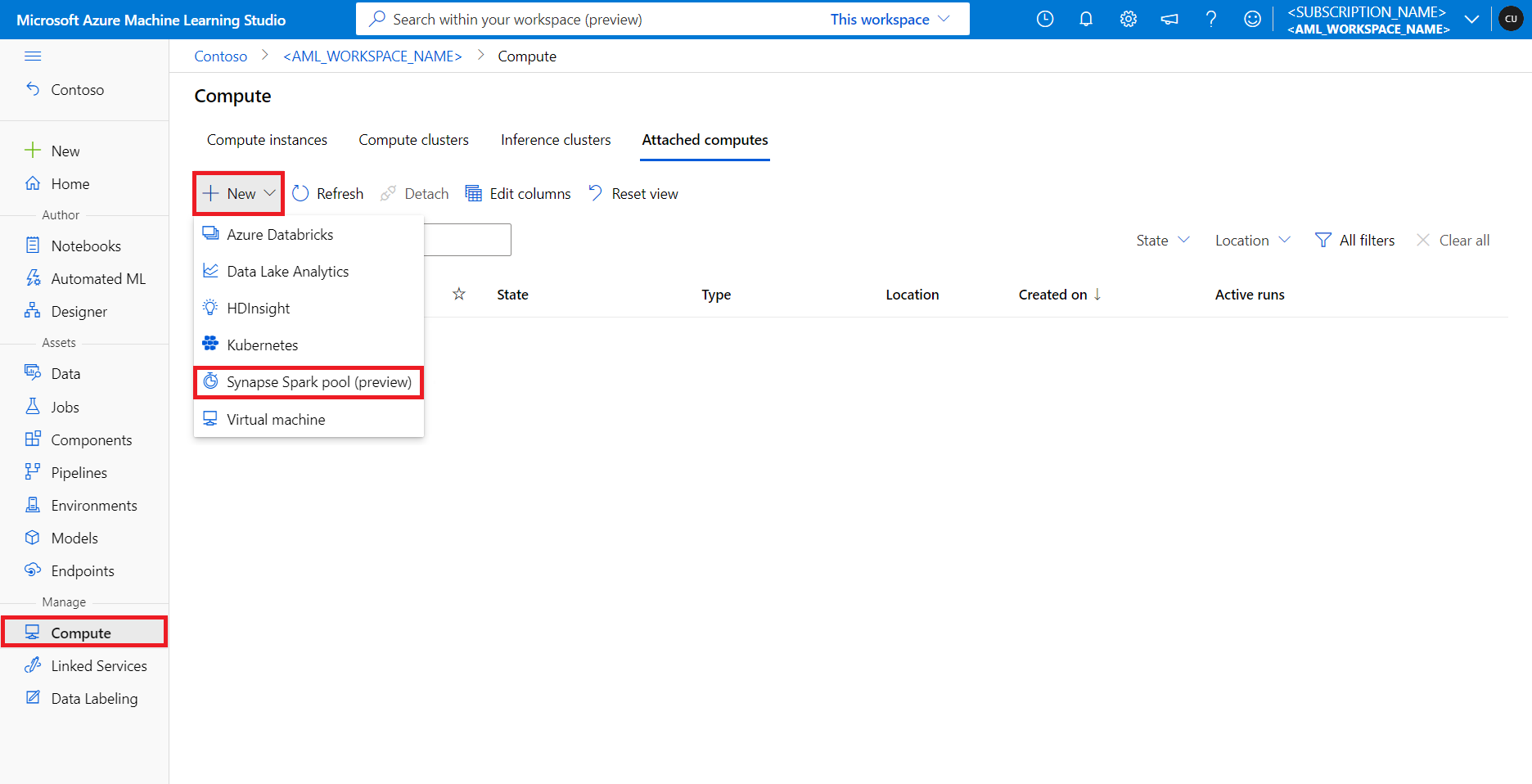
Azure 机器学习笔记本中的无服务器 Spark 计算
默认情况下,Azure 机器学习笔记本中提供了无服务器 Spark 计算。 若要在笔记本中访问它,请从“计算”选择菜单的“Azure 机器学习无服务器 Spark”下选择“无服务器 Spark 计算”。
笔记本 UI 还为无服务器 Spark 计算提供了 Spark 会话配置选项。 配置 Spark 会话:
-
选择屏幕顶部的“配置会话”。
-
从下拉菜单中选择“Apache Spark 版本”。
重要
适用于 Apache Spark 的 Azure Synapse 运行时:公告
- 适用于 Apache Spark 3.2 的 Azure Synapse 运行时:
- EOLA 公告日期:2023 年 7 月 8 日
- 支持结束日期:2024 年 7 月 8 日。 在此日期之后,将会禁用运行时。
- 为了获取持续支持和最佳性能,建议迁移到 Apache Sark 3.3。
- 适用于 Apache Spark 3.2 的 Azure Synapse 运行时:
-
从下拉菜单中选择“实例类型”。 当前支持以下实例类型:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
-
输入 Spark 会话超时值(以分钟为单位)。
-
选择是否动态分配执行程序
-
选择 Spark 会话的执行程序数量。
-
从下拉菜单中选择“执行程序大小”。
-
从下拉菜单中选择“驱动程序大小”。
-
要使用 Conda 文件配置 Spark 会话,请选中“上传 conda 文件”复选框。 然后,选择“浏览”,并选择具有所需 Spark 会话配置的 Conda 文件。
-
添加“配置设置”属性,在“属性”和“值”文本框中输入值,然后选择“添加”。
-
选择“应用”。
-
在“配置新会话?”弹出窗口中选择“停止会话”。
会话配置更改将被保存,并可用于使用无服务器 Spark 计算启动的另一个笔记本会话。
提示
如果使用会话级 Conda 包,并将配置变量 spark.hadoop.aml.enable_cache 设置为 true,则可以改善 Spark 会话冷启动时间。 会话首次启动时,具有会话级别 Conda 包的会话冷启动通常需要 10 到 15 分钟。 但是,配置变量设置为 true 时的后续会话冷启动通常需要 3 到 5 分钟。
从 Azure Data Lake Storage (ADLS) Gen 2 导入和整理数据
可以使用 abfss:// 数据 URI 按照以下两种数据访问机制之一访问和处理存储在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中的数据:
- 用户标识传递
- 基于服务主体的数据访问
提示
要使用无服务器 Spark 计算进行数据整理、对 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中的数据进行用户标识直通访问,需要的配置步骤是最少的。
若要使用用户标识传递开始交互式数据整理,请执行以下命令:
-
验证用户身份是否在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中获得了“参与者”和“存储 Blob 数据参与者”角色。
-
要使用无服务器 Spark 计算,请在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”。
-
要使用附加的 Synapse Spark 池,请从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
这个 Titanic 数据整理代码示例显示了
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>格式的数据 URI 与pyspark.pandas和pyspark.ml.feature.Imputer的搭配使用。import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
若要通过服务主体按照访问权限来整理数据,请执行以下操作:
-
验证服务主体是否在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中获得了“参与者”和“存储 Blob 数据参与者”角色。
-
为服务主体租户 ID、客户端 ID 和客户端机密值创建 Azure 密钥保管库机密。
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
若要在配置中设置服务主体租户 ID、客户端 ID 和客户端密码,请执行以下代码示例。
-
代码中的
get_secret()调用取决于 Azure 密钥保管库的名称,以及为服务主体租户 ID、客户端 ID 和客户端密码创建的 Azure 密钥保管库机密的名称。 在配置中设置这些相应的属性名称/值:- 客户端 ID 属性:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 客户端机密属性:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 租户 ID 属性:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 租户 ID 值:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary# Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>")# Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net","org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net",client_id, ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net",client_secret, ) sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net","https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", ) - 客户端 ID 属性:
-
-
使用
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>格式的数据 URI 导入和转换数据,如使用 Titanic 数据的代码示例所示。

从 Azure Blob 存储导入和处理数据
可以使用存储帐户访问密钥或共享访问签名 (SAS) 令牌访问 Azure Blob 存储数据。 应将这些凭据作为机密存储在 Azure 密钥保管库中,并在会话配置中将其设置为属性。
若要开始交互式数据整理,请执行以下操作:
-
在左侧Azure 机器学习工作室面板中,选择“笔记本”。
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
若要配置存储帐户访问密钥或共享访问签名 (SAS) 令牌以便在 Azure 机器学习笔记本中访问数据,请执行以下操作:
-
对于访问密钥,请设置属性
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net,如以下代码片段所示:from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key ) -
对于 SAS 令牌,请设置属性
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net,如以下代码片段所示:from pyspark.sql import SparkSessionsc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set("fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net",sas_token, )备注
上述代码片段中的
get_secret()调用需要 Azure 密钥库的名称,以及为 Azure Blob 存储帐户访问密钥或 SAS 令牌创建的机密的名称
-
-
在同一笔记本中执行数据整理代码。 将数据 URI 的格式设置为
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>,类似于此代码片段所示:import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
从 Azure 机器学习数据存储导入和整理数据
若要从 Azure 机器学习数据存储访问数据,请使用 URI 格式azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>定义数据存储上数据的路径。 若要在笔记本会话中以交互方式处理 Azure 机器学习数据存储中的数据,请执行以下操作:
-
在“计算”选择菜单中,选择“Azure 机器学习无服务器 Spark”下的“无服务器 Spark 计算”,或者从“计算”选择菜单中选择“Synapse Spark 池”下附加的 Synapse Spark 池。
-
此代码示例显示了如何使用
azureml://数据存储 URIpyspark.pandas和pyspark.ml.feature.Imputer从 Azure 机器学习数据存储中读取和处理大量数据。import pyspark.pandas as pd from pyspark.ml.feature import Imputerdf = pd.read_csv("azureml://datastores/workspaceblobstore/paths/data/titanic.csv",index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy("mean" ) # Replace missing values in Age column with the mean value df.fillna(value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv("azureml://datastores/workspaceblobstore/paths/data/wrangled",index_col="PassengerId", )备注
此 Python 代码示例使用
pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
Azure 机器学习数据存储可以使用 Azure 存储帐户凭据访问数据
- 访问密钥
- SAS 令牌
- 服务主体 (service principal)
或提供无凭据的数据访问。 根据数据存储类型和基础 Azure 存储帐户类型,选择适当的身份验证机制来确保数据访问。 下表总结了用于访问 Azure 机器学习数据存储中的数据的身份验证机制:
| 存储帐户类型 | 无凭据数据访问 | 数据访问机制 | 角色分配 |
|---|---|---|---|
| Azure Blob | 否 | 访问密钥或 SAS 令牌 | 不需要角色分配 |
| Azure Blob | 是 | 用户标识传递* | 用户标识应在 Azure Blob 存储帐户中具有适当的角色分配 |
| Azure Data Lake Storage (ADLS) Gen 2 | 否 | 服务主体 | 服务主体应在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中具有适当的角色分配 |
| Azure Data Lake Storage (ADLS) Gen 2 | 是 | 用户标识传递 | 用户标识应在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中具有适当的角色分配 |
只有在未启用软删除的情况下,* 用户标识直通才适用于指向 Azure Blob 存储帐户的无凭据数据存储。
默认文件共享挂载到无服务器 Spark 计算和附加的 Synapse Spark 池。
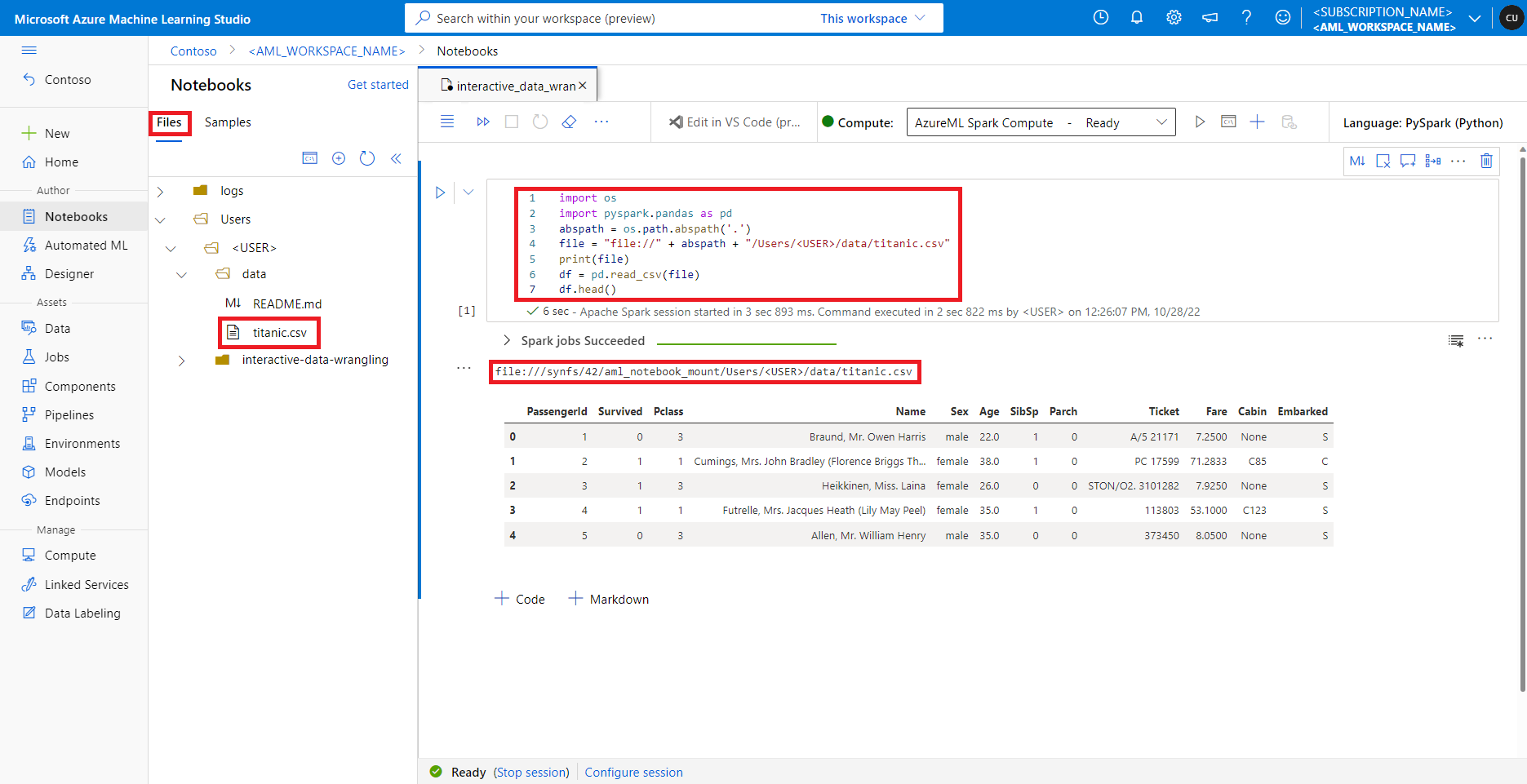
在 Azure 机器学习工作室中,默认文件共享中的文件显示在“文件”选项卡下的目录树中。笔记本代码可以使用 file:// 协议以及文件的绝对路径直接访问此文件共享中存储的文件,而无需进行更多配置。 此代码片段演示如何访问存储在默认文件共享上的文件:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputerabspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"],outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
备注
此 Python 代码示例使用 pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。