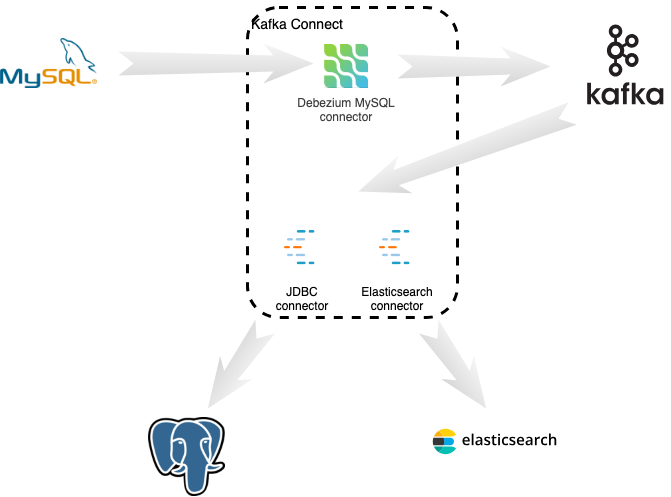
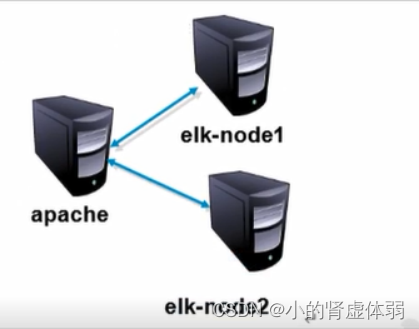
ELK集群部署环境准备
配置ELK日志分析系统
| 192.168.1.51 | elk-node1 | es、logstash、kibana |
| 192.168.1.52 | elk-node2 | es、logstash |
| 192.168.1.53 | apache | logstash |
(我这里是把虚拟机的配置全部都改为2核3G的)
2台linux 第1台:elk-node1 第2台:node2(双核、内存4G)
关闭防护机制
iptables -F
setenforce 0
systemctl stop firewalld
第1台
修改名字
hostnamectl set-hostname elk-node1
bash
主机映射vim修改配置文件在末尾添加(两台都做)
vim /etc/hosts
192.168.1.51 elk-node1
192.168.1.52 elk-node2
第2台
修改名字
hostnamectl set-hostname elk-node2
bash
1,2台都用系统自带java环境
java -version
2台rz上传软件包 第1台软件包全部上传 第2台只上传3个
安装elasticsearch软件 (rz logstash-5.5.1.rpm和elasticsearch-5.5.0.rpm)
第1,2台
rpm -ivh elasticsearch-5.5.0.rpm
rpm -ivh logstash-5.5.1.rpm
重新识别系统中的服务并且设置为开机自启动
systemctl daemon-reload
systemctl enable elasticsearch.service
修改node1,node2的配置文件
vim /etc/elasticsearch/elasticsearch.yml
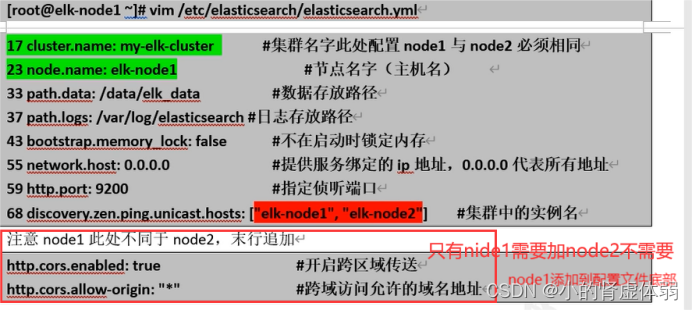
http.cors.enabled: true
http.cors.allow-origin: "*"
创建目录并且把用户和组都改为elasticsearch
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
启动elasticsearch.服务并且查看端口
systemctl start elasticsearch.service
netstat -anpt | grep 9200
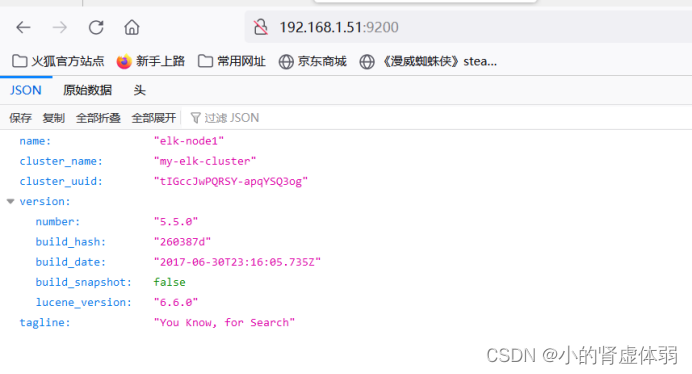
访问节点ip
http://192.168.1.51:9200/
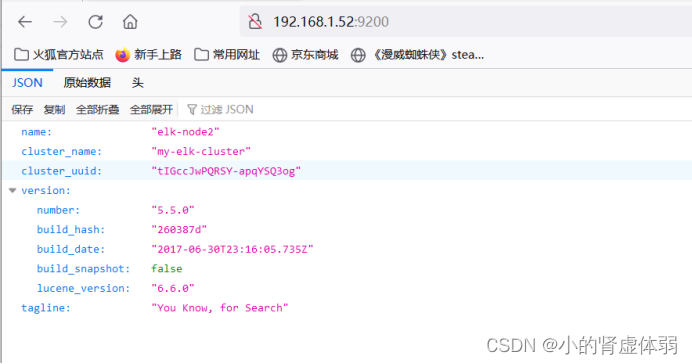
http://192.168.1.52:9200/
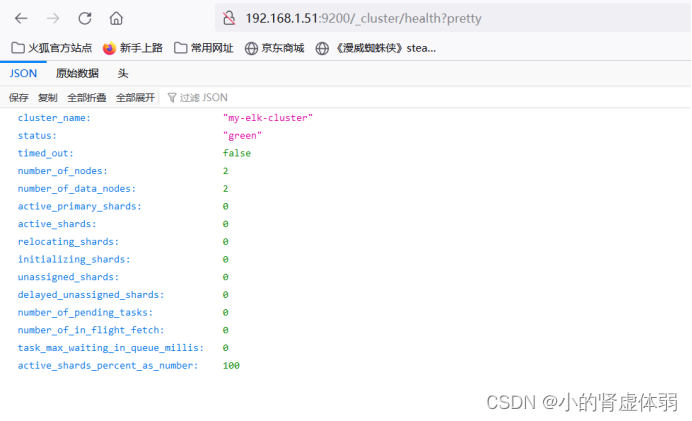
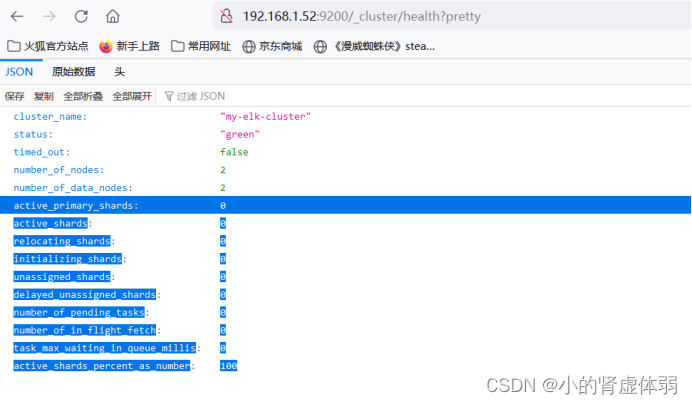
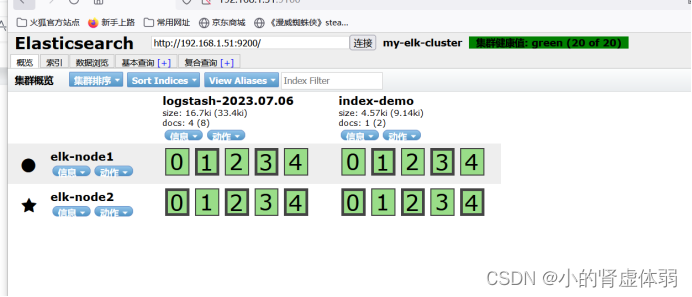
检查集群健康状态为green代表健康
http://192.168.1.51:9200/_cluster/health?pretty
http://192.168.1.52:9200/_cluster/health?pretty
第1台
安装elasticsearch-head插件
解压软件包 (rz node-v8.2.1-linux-x64.tar.gz)
tar xf node-v8.2.1-linux-x64.tar.gz -C /usr/local/
做链接
ln -s /usr/local/node-v8.2.1-linux-x64/bin/node /usr/bin/node
ln -s /usr/local/node-v8.2.1-linux-x64/bin/npm /usr/local/bin/
查看版本
node -v
npm -v
解压head包(rz elasticsearch-head.tar.gz)
tar xf elasticsearch-head.tar.gz -C /data/elk_data/
cd到elk_data
cd /data/elk_data/
修改用户和组
chown -R elasticsearch:elasticsearch elasticsearch-head/
cd到elasticsearch-head/下
cd elasticsearch-head/
安装npm (在/data/elk_data/elasticsearch-head目录下使用该命令安装)
npm install
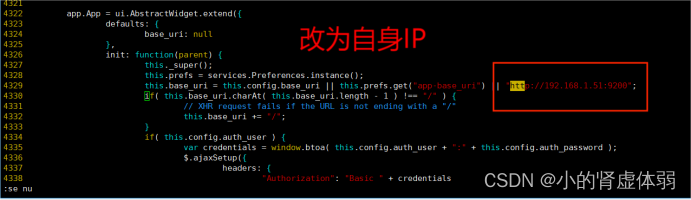
cd到site/下并且把app.js做个备份然后编辑
cd _site/
cp app.js{,.bak}
vim app.js
启动npm并且启动elasticsearch
npm run start &
systemctl start elasticsearch 如果访问后没有发现node2
cd /data/elk_data/
rm -rf nodes/
查看端口是否有9100
netstat -lnpt | grep 9100
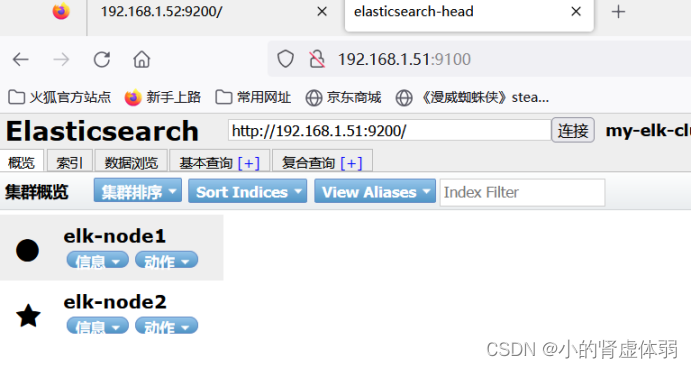
访问ip查看节点
http://192.168.1.51:9100/
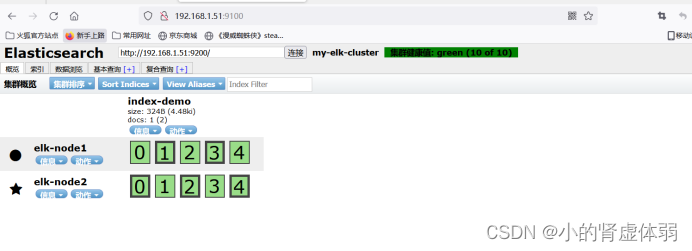
插入数据测试类型为test
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{ "user": "zhangsan","mesg":"hello word" }'
刷新http://192.168.1.51:9100/查看索引是否有变化
安装logstash
第1台也就是node1上安装logstash
rpm -ivh logstash-5.5.1.rpm
启动logstash服务并且做一个软链接
systemctl start logstash
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
logstash 命令行常用的选项
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstashe
-e: 后面跟着字符串,该字符串可以被当做logstash的配置(如果是"”则默认使用stdin作为输入,stdout作为输出)
-t:测试配置文件是否正确,然后退出
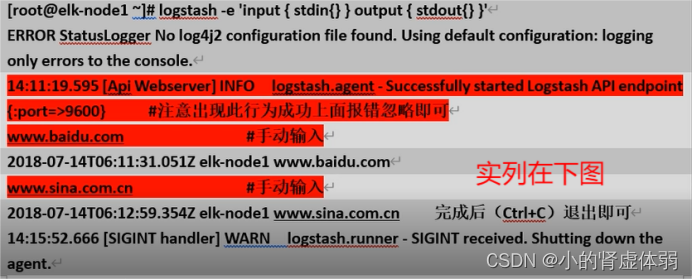
启动一个 logstash -e 在命令行执行 input
logstash -e 'input { stdin{} } output { stdout{} }'
标准输入是靠键盘输入标准输出是直接在屏幕上输出
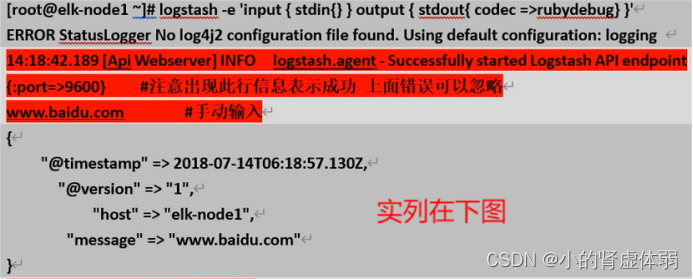
使用rubydebug 显示详细输出 codec
logstash -e 'input { stdin{} } output { stdout{ codec =>rubydebug} }'
 使用logstash将信息写入到elasticsearch中
使用logstash将信息写入到elasticsearch中
logstash -e 'input {stdin{} } output { elasticsearch { hosts=> ["192.168.200.111:9200"]} }'
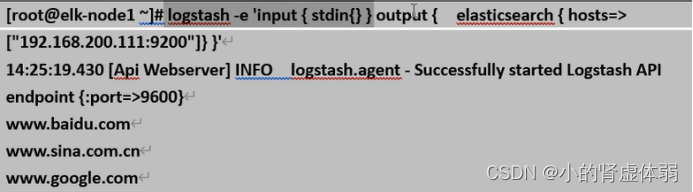
www.baidu.com
www.sina.com.cn
www.gogle.com
配置收集系统日志 第1台
cd到logstash写入配置文件
cd /etc/logstash/conf.d/
vim systemc.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.1.51:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
重启logstash
systemctl restart logstash
加载systemc.conf 文件并且查看是否打入到es当中
logstash -f systemc.conf
安装kibana第1台(rz kibana-5.5.1-x86_64.rpm)
rpm -ivh kibana-5.5.1-x86_64.rpm
设置为开机自启动
systemctl enable kibana.service
修改配置文件并启动服务
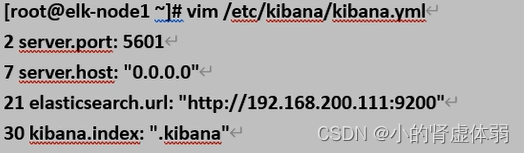
vim /etc/kibana/kibana.yml
启动服务并且查看端口
systemctl restart kibana.service
netstat -lnpt | grep 5601
logstash -f /etc/logstash/conf.d/system.conf
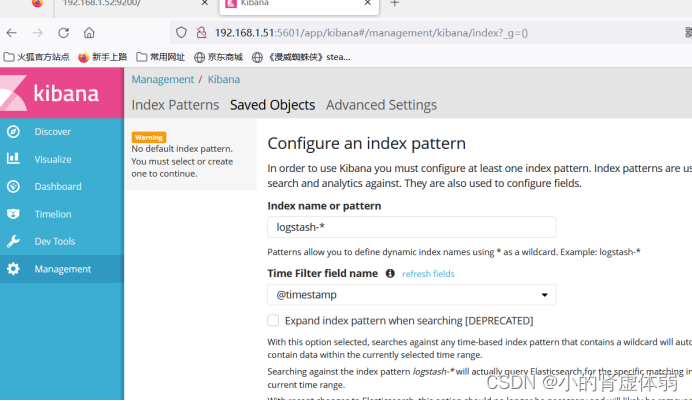
访问 http://192.168.1.51:5601/
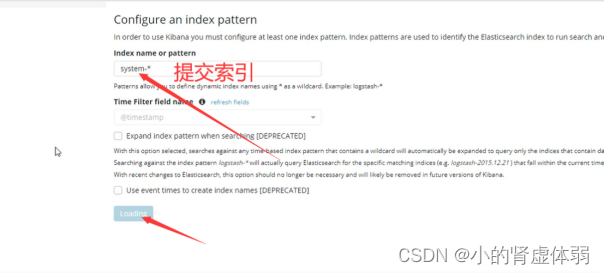
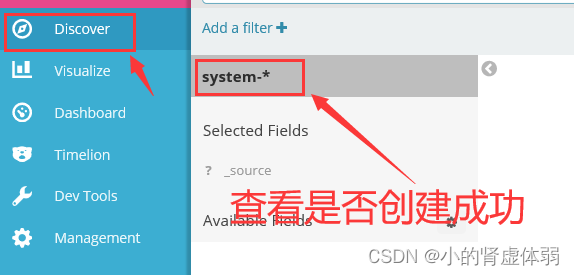
第3台
开启第3台起名:apache
hostname apache
bash
关闭防护机制
iptables -F
systemctl stop firewalld
setenforce 0
启动httpd(yum -y install httpd)
systemctl start httpd
查看java版本
java -version
rz上传软件包
![]()
rpm安装并且设置为开机自启动
rpm -ivh logstash-5.5.1.rpm
systemctl enable logstash.service
cd到logstash下
cd /etc/logstash/conf.d/
vim编辑配置文件
vim apache_log.conf
input {
file {
path => "/var/log/httpd/access_log"
type => "access"
start_position => "beginning"
}
file {
path => "/var/log/httpd/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.1.51:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.1.51:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
[root@apache conf.d]# logstash -f apache_log.conf //加载文件
systemctl start logstash
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/(找不到命令试下这两个命令)

这里输入信息后退出回出现apache_access索引
访问 192.168.1.53也就是第3台连续刷新然后查看 http://192.168.1.51:9100/
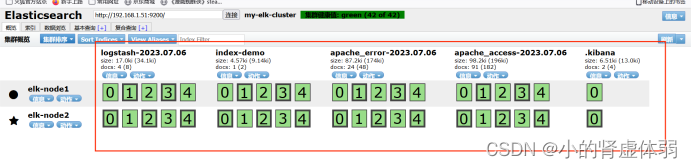
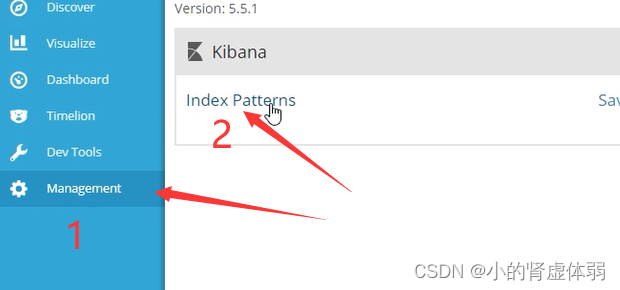
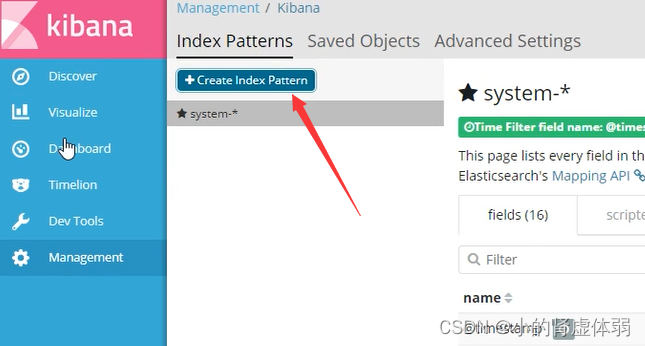
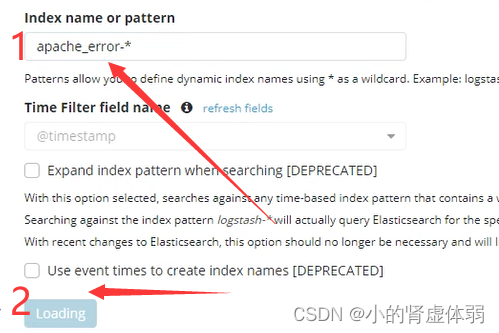
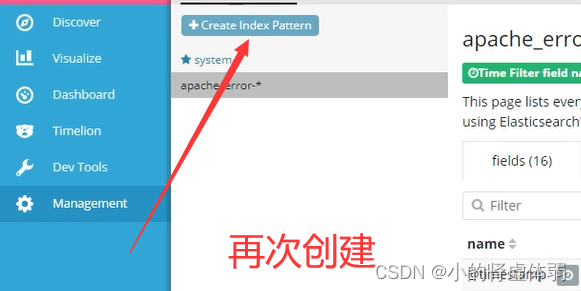
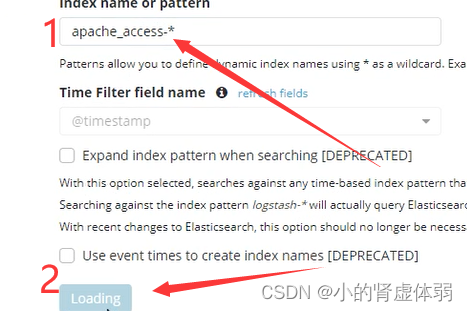
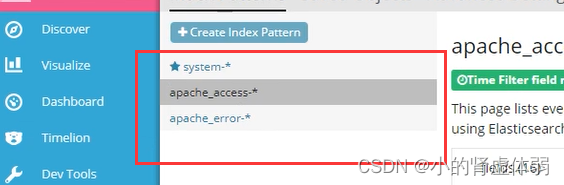
选择查看
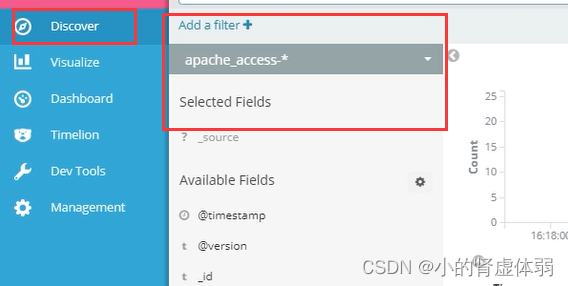
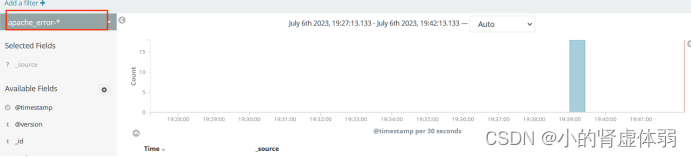
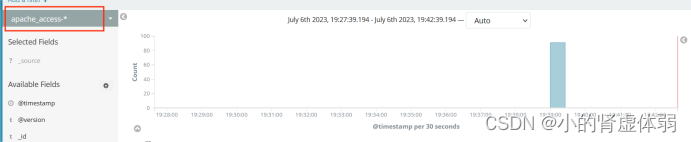
ELK端口号:
elasticsearch:9200
elasticsearch-head:9100
logstash:9600 input:4560
Logstash agent:9601
kibana:5601