目录
简介
框图
DMA请求
DMA通道
DMA优先级
DMA 数据
外设到存储器
存储器到外设
存储器到存储器
传多少,单位是什么
传输完成
hal库代码
标准库代码
简介
CPU根据代码内容执行指令,这些众多指令中,有的用于计算、有的用于控制程序、有的用于转移数据等。 其中转移数据的指令,尤其是转移大量数据,会占用大量CPU。如果是把外设A的数据,传给外设B,这种情况其实不需要CPU一直参与,只需在A、 B之间创建个通道,让它们自己传输即可。DMA(Direct Memory Access)直接内存访问,可以大大减轻CPU工作量。这就DMA设计的目的,减少大量数据转移指令消耗CPU, DMA专注数据转移, CPU专注计算、控制。
DMA主要实现将A处的数据直接搬运到B处,场景如下三种:内存到外设、外设到内存、内存到内存。无论是何种方式,都是先设置好DMA的数据源地址、数据目标地址、数据长度。设置好后,启动DMA就可以自动的把数据从源地址依次传输到目标地址。
框图
STM32F1系列有两个DMA控制器, 其中DMA2仅存在于大容量产品中。 DMA1有7个通道, DMA2有5个通道,总计12个通道。这里的通道可以理解为传输数据的一种管道。

DMA请求

外设想通过DMA传输数据,需要先向DMA控制器发送请求。 外设向DMA控制器发送请求后, DMA控制器根据通道优先级依次处理请求,控制器会给外设一个应答信号,当外设应答后且 DMA 控制器收到应答信号之后,就会启动 DMA 的传输,直到传输完毕
DMA 有 DMA1 和 DMA2 两个控制器, DMA1 有 7 个通道, DMA2 有 5 个通道,不同的 DMA 控制器的通道对应着不同的外设请求
DMA通道


不同的外设,向不同DMA的不同通道发送请求。比如ADC1想使用DMA,应向DMA1的通道1发送请求。 DMA1的通道1,可以接收多个外设的请求( ADC1、 TIM2_CH3、TIM4_CH1),但同一时间只能接收一个
DMA优先级
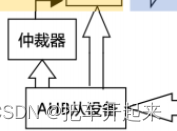
当多个DMA通道,同时发来请求时,这个就由仲裁器管理。仲裁器管理 DMA 通道请求分为两个阶段。第一阶段属于软件阶段,获取软件配置DMA_CCRx寄存器设置的优先级,有 4 个等级:非常高,高,中和低四个优先级依次响应。第二阶段属于硬件阶段,当软件配置优先级相同时,硬件优先级高的(通道编号小的)优先响应。DMA1 控制器拥有高于 DMA2 控制器的优先级。
DMA 数据
外设到存储器
比如ADC 采集配置,DMA 外设寄存器的地址对应的就是 ADC数据寄存器的地址, DMA 存储器的地址就是我们自定义的变量(用来接收存储 AD 采集的数据)的地址。方向设置外设为源地址。
存储器到外设
比如串口向电脑端发送数据,DMA 外设寄存器的地址对应的就是串口数据寄存器的地址, DMA 存储器的地址就是我们自定义的变量(相当于一个缓冲区,用来存储通过串口发送到电脑的数据)的地址。方向设置外设为目标地址。
存储器到存储器
比如内部 FLASH 向内部 SRAM 复制数据,DMA 外设寄存器的地址对应的就是内部 FLASH(把内部 FALSH 当作外设来看)的地址, DMA存储器的地址就是我们自定义的变量(相当于一个缓冲区,用来存储来自内部 FLASH 的数据)的地址。方向我们设置外设(即内部FLASH)为源地址。跟上面不一样的是,这里需要把DMA_CCR 位 14: MEM2MEM:存储器到存储器模式配置为 1,启动 M2M 模式
传多少,单位是什么
一个 32 位的寄存器,DMA一次可传输的最多65536个数据, 要想数据传输正确,源和目标地址存储的数据宽度还必须一致,如串口数据寄存器是 8 位的,所以要发送的数据也必须是 8 位。
数据要想有条不紊的从一个地方搬到另外一个地方,还必须正确设置两边数据指针的增量模式。以串口向电脑发送数据为例,要发送的数据很多,每发送完一个,那么存储器的地址指针就应该加 1,而串口数据寄存器只有一个,那么外设的地址指针就固定不变。具体的数据指针的增量模式由实际情况决定
传输完成
DMA在传输过程中会产生3个传输标志:半完成标志( Half Transfer, HT) 、完成标志( Transfer Complete, TC) 和错误标志( Transfer Error, TE) 。数据什么时候传输完成,可以通过查询标志位或者通过中断的方式来鉴别
每个标志会产生对应的中断信号,如果使能了三种类型的中断后,则会产生中断。假如有N个数据待DMA传输,设置到原地址和目的地址后,当收到一个传输请求DMA就会从原地址取出一个数据传输到目的地址,如果地址是外设则地址保持不变,若地址是内存则传输完一个数据之后地址自增一个数据单位。在传输过程中如果发生意外错误则会产生一个错误中断信号,当传输完成一半则会产生半传输完成中断,当全部数据都传输完成则会产生一个传输完成中断。
hal库代码
DMA_HandleTypeDef hdma;
/*标志位*/
__IO uint32_t transferErrorDetected;
__IO uint32_t transferCompleteDetected;/*发送缓冲区*/
uint32_t src_buffer[20] ={0x1234, 0x5678, 0x9876, 0x4586, 0xABCD,0x5678, 0xABCD, 0x4586, 0x4586, 0xABCD,0xABCD, 0x5678, 0x4586, 0x9876, 0x1234,0x1234, 0xABCD, 0x9876, 0x5678, 0xABCD,};
/*接收*/
uint32_t dst_buffer[20] = {0};#if 1
/*如果DMA传输完成且不发生错误,则在此函数将传输完成标志置一*/
static void tranfer_complete(DMA_HandleTypeDef *dma)
{transferCompleteDetected=1;
}
/*如果DMA传输过程中发生错误,则在此函数中将传输错误标志置一*/
static void tranfer_error(DMA_HandleTypeDef *dma)
{transferErrorDetected=1;
}
#endifvoid dma_init(void)
{/*使能DMA1时钟*/__HAL_RCC_DMA1_CLK_ENABLE();hdma.Init.Direction = DMA_MEMORY_TO_MEMORY;/*内存到内存模式*/hdma.Init.PeriphInc = DMA_PINC_ENABLE;/*外设地址递增*/hdma.Init.MemInc = DMA_MINC_ENABLE;/*内存地址递增*/hdma.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD;/*外设数据以字对齐*/hdma.Init.MemDataAlignment = DMA_MDATAALIGN_WORD;/*内存数据以字对齐*/hdma.Init.Mode = DMA_NORMAL;/*正常传输模式,传输一次*/hdma.Init.Priority = DMA_PRIORITY_VERY_HIGH;/*传输优先级非常高*/hdma.Instance = DMA1_Channel1;/*选择DMA通道1*//*初始化配置*/HAL_DMA_Init(&hdma);
#if 1/*注册传输完成和传输错误回调函数*/HAL_DMA_RegisterCallback(&hdma, HAL_DMA_XFER_CPLT_CB_ID,tranfer_complete);/*传输完成的回调函数 ID*/HAL_DMA_RegisterCallback(&hdma, HAL_DMA_XFER_ERROR_CB_ID, tranfer_error);/*DMA中断优先级*/HAL_NVIC_SetPriority(DMA1_Channel1_IRQn , 0 , 0);HAL_NVIC_EnableIRQ(DMA1_Channel1_IRQn);
#endif}#if 1
/*DMA1通道1中断的中断处理函数*/
void DMA1_Channel1_IRQHandler(void)
{HAL_DMA_IRQHandler(&hdma);
}/*初始化 DMA_Channel1,配置为内存-内存模式,每次搬移一个 word 即 4bytes*/
void dma_start(uint32_t *SrcAddress, uint32_t *DstAddress, uint16_t DataLength)
{HAL_DMA_Start_IT(&hdma,(uint32_t)SrcAddress,(uint32_t)DstAddress,DataLength);
}
#endif标准库代码
/*时钟使能的dma*/
#define CLK_DMAx RCC_AHBPeriph_DMA1
/*串口对应的DMA请求通道*/
#define USART_TX_DMA_CHANNEL DMA1_Channel4
/*外设接收数据寄存器地址*/
#define USART_DR_ADDRESS (USART1_BASE+0x04)
/*一次发送的数据量 <65535*/
#define SIZE 5000static uint32_t i;
uint8_t send_buf[SIZE];void uart_dma_init(void)
{DMA_InitTypeDef DMA_InitStruct;/*开启时钟*/RCC_AHBPeriphClockCmd(CLK_DMAx,ENABLE);/*设置DMA源地址:串口数据寄存器地址*/DMA_InitStruct.DMA_PeripheralBaseAddr = USART_DR_ADDRESS;/*内存地址,使DMA传输的数据从`send_buf`所指向的内存开始*/DMA_InitStruct.DMA_MemoryBaseAddr = (uint32_t)send_buf;/*方向:内存到外设*/DMA_InitStruct.DMA_DIR = DMA_DIR_PeripheralDST;/*传输大小*/DMA_InitStruct.DMA_BufferSize = SIZE;/*外设地址不增*/DMA_InitStruct.DMA_PeripheralInc = DMA_PeripheralInc_Disable;/*内存地址只增*/DMA_InitStruct.DMA_MemoryInc = DMA_MemoryInc_Enable;/*外设数据单位*/DMA_InitStruct.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;/*内存数据单位,每次传输的数据大小为1字节*/DMA_InitStruct.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;/*dma模式,一次或循环*/DMA_InitStruct.DMA_Mode = DMA_Mode_Normal;/*一次*///DMA_InitStruct.DMA_Mode = DMA_Mode_Circular;/*循环*//*优先级:中*/DMA_InitStruct.DMA_Priority = DMA_Priority_Medium;/*内存到内存的传输*/DMA_InitStruct.DMA_M2M = DMA_M2M_Disable;/*配置DMA通道*/DMA_Init(USART_TX_DMA_CHANNEL,&DMA_InitStruct);/*使能DMA*/DMA_Cmd(USART_TX_DMA_CHANNEL,ENABLE);/*使能USART的DMA传输功能,具体传输方向为USART的发送(Tx)方向。*///USART_DMACmd(USARTx,USART_DMAReq_Tx,ENABLE);
}/*发送*/
void dma_send(void)
{/*填充要发送的数据*/for(i=0;i<SIZE;i++){send_buf[i] = 'p';}
/*开启传输,USARTx表示要配置的USART接口,USART_DMAReq_Tx表示启用发送数据的DMA请求*/USART_DMACmd(USARTx,USART_DMAReq_Tx,ENABLE);}