文章目录
- 一、消息的堆积问题
- 1.1 什么是消息的堆积问题
- 1.2 消息堆积的解决思路
- 二、惰性队列解决消息堆积问题
- 2.1 惰性队列和普通队列的区别
- 2.2 惰性队列的声明方式
- 2.3 演示惰性队列接收大量消息
- 2.4 惰性队列的优缺点
一、消息的堆积问题
1.1 什么是消息的堆积问题
消息的堆积问题是指在消息队列系统中,当生产者以较快的速度发送消息,而消费者处理消息的速度较慢,导致消息在队列中积累并达到队列的存储上限。在这种情况下,最早被发送的消息可能会在队列中滞留较长时间,直到超过队列的容量上限。当队列已满且没有更多的可用空间来存储新消息时,新的消息可能无法进入队列,从而导致消息丢失。这种情况下的消息通常被称为死信,因为它们无法被正常消费。
例如,下图展示了消息堆积问题的情景,其中消息的堆积超出了队列的容量上限,导致部分消息成为死信并被丢弃:
1.2 消息堆积的解决思路
解决消息堆积问题通常需要采取以下三种主要思路:
-
增加更多消费者,提高消费速度:一种解决方案是增加消费者,以提高消息的处理速度。通过增加并行消费者,系统可以更快地处理消息,减少消息在队列中的滞留时间。这种方式适用于可以水平扩展消费者的情况。
-
在消费者内开启线程池加快消息处理速度:在消费者内部采用线程池的方式,可以有效提高消息的处理速度。通过并发处理消息,消费者能够更有效地消费队列中的消息,缓解堆积问题。
-
扩大队列容积,提高堆积上限:增加队列的容量上限是另一种解决方案。通过扩大队列的容积,系统能够容纳更多的消息,延长消息在队列中的存留时间,从而减少消息堆积的概率。这对于短期高峰消息负载的情况可能有帮助。
根据实际需求和资源,可以选择一种或多种解决思路来应对消息的堆积问题。每种方法都有其适用的场景,选择合适的解决方案对于确保消息队列系统的稳定性和性能至关重要。
下面将演示如何创建惰性队列,来解决消息的堆积问题。
二、惰性队列解决消息堆积问题
2.1 惰性队列和普通队列的区别
在消息队列系统中,存储和管理消息通常依赖于内存,这种方式能够提供快速的消息访问和处理。然而,在高并发场景下,当消息量达到数以百万计时,将所有消息存储在内存中可能会引发性能问题。这时,惰性队列应运而生。
自RabbitMQ的3.6.0版本开始,引入了Lazy Queues的概念,也称为惰性队列。惰性队列与普通队列之间存在以下显著区别:
惰性队列的特征:
-
消息存储在磁盘:惰性队列在接收到消息后会直接将消息存储到磁盘上,而不是保存在内存中。这意味着消息不会立即加载到内存,从而减轻了内存的压力。
-
按需加载到内存:当消费者需要消费消息时,惰性队列才会从磁盘中读取消息并加载到内存中。这种按需加载的方式确保了消息在磁盘上等待消费时不会占用大量内存资源,从而提高了系统的性能和可扩展性。
-
支持大规模消息存储:惰性队列具有出色的存储能力,可以容纳数百万条消息,从而确保消息的可靠存储和高可用性。
普通队列与惰性队列的对比:
对于普通的消息队列,如果没有开启消息的持久化,所有进入队列的消息通常都会保存在内存中,以提高消息的处理速度。然而,内存是有限的资源,RabbitMQ 通常会设置内存使用的预警值,通常为内存的40%。在消息堆积的情况下,可能会达到这个内存预警值。
此时,RabbitMQ 将采取一系列措施,通常被称为 “Paged Out”,以防止内存耗尽。这包括将超过内存预警值的消息刷出到磁盘上,从而释放一部分内存。同时,RabbitMQ 还会阻止新的消息进入队列,以避免进一步的内存消耗。这一系列过程会导致 RabbitMQ 进入间歇性的暂停状态,阻止了生产者的写入请求,最终导致消息队列的并发能力出现忽高忽低的情况,性能变得不够稳定。
相比之下,惰性队列将消息直接写入磁盘,难以达到内存预警值,从而提供了更稳定的性能。然而,由于涉及磁盘的读写操作,性能可能会受到一定的限制。在选择队列类型时,需要权衡内存和磁盘的使用情况,根据具体的应用需求和性能要求来做出决策。
2.2 惰性队列的声明方式
- 使用命令行设置惰性队列
要将队列设置为惰性队列,可以通过命令行工具来实现,同时这个方式也可以将运行中的队列设置为惰性队列。以下是在 RabbitMQ 中使用命令设置队列为惰性队列:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
对上面命令的解释:
-
rabbitmqctl:RabbitMQ 的命令行工具,用于执行 RabbitMQ 相关操作。 -
set_policy:命令用于添加一个策略。 -
Lazy:策略的名称,您可以根据需要自定义策略名称。 -
"^lazy-queue$":使用正则表达式来匹配队列的名称。这里的正则表达式匹配队列名为 “lazy-queue” 的队列。 -
'{"queue-mode":"lazy"}':设置队列的模式为 “lazy”,这将使队列成为惰性队列。 -
--apply-to queues:指定策略应用于队列。这表示正在为队列应用 “lazy” 模式。
执行上述命令后,指定的队列将被设置为惰性队列,消息将以惰性队列的方式进行存储和管理。
- 使用
@Bean注解声明惰性队列
要声明一个惰性队列,可以使用Spring的@Bean注解以编程方式创建队列,并将其配置为惰性队列。以下是一个示例,展示如何使用@Bean注解创建惰性队列:
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.QueueBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class RabbitMQConfig {@Beanpublic Queue lazyQueue() {return QueueBuilder.durable("lazy.queue").lazy() // 设置 x-queue-mode 为 lazy.build();}
}
在上述示例中,首先创建一个Queue对象,名称为 “lazy.queue”,并使用QueueBuilder进行配置。然后,通过调用.lazy()方法来设置队列的模式为 “lazy”,这将使队列成为惰性队列。最后,通过调用.build()方法来构建并返回队列。
- 使用
@RabbitListener注解声明惰性队列
同样可以使用Spring的@RabbitListener注解来声明和监听惰性队列。以下是一个示例,展示如何使用@RabbitListener注解声明和监听惰性队列:
@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg) {log.info("接收到 lazy.queue 的消息:" + msg);
}
在这个示例中,使用 @RabbitListener 注解声明一个监听器方法 listenLazyQueue,该方法监听名为 “lazy.queue” 的队列。以下是代码中的关键部分:
-
@RabbitListener注解用于声明监听器方法,它告诉RabbitMQ监听指定的队列。 -
queuesToDeclare属性用于声明队列的属性,包括队列的名称、是否持久化以及自定义参数。在这里,设置了队列的名称为 “lazy.queue”,并指定了持久化属性和队列模式为 “lazy”。 -
listenLazyQueue方法定义了在接收到消息时要执行的逻辑,您可以在其中编写处理消息的代码。
通过使用 @RabbitListener 注解,可以方便地声明和监听惰性队列,以接收并处理队列中的消息。这简化了消息消费的配置和管理,同时确保了队列的属性和模式的一致性。
2.3 演示惰性队列接收大量消息
下面同时使用 @Bean 声明一个惰性队列和一个普通队列,然后分别向这两个队列写入一百万条消息,观察消息写入队列的情况:
- 声明惰性队列和普通队列
@Bean
public Queue lazyQueue() {return QueueBuilder.durable("lazy.queue").lazy() // 设置 x-queue-mode 为 lazy.build();
}@Bean
public Queue normalQueue() {return QueueBuilder.durable("normal.queue").build();
}
- 发送消息的逻辑
@Test
public void testLazyQueue() {for (int i = 0; i < 1000000; i++) {// 1. 创建消息Message message = MessageBuilder.withBody("hello, lazy queue".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT).build();// 2. 发送消息rabbitTemplate.convertAndSend("lazy.queue", message);}
}@Test
public void testNormalQueue() {for (int i = 0; i < 1000000; i++) {// 1. 创建消息Message message = MessageBuilder.withBody("hello, normal queue".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT).build();// 2. 发送消息rabbitTemplate.convertAndSend("normal.queue", message);}
}
- 观察消息的写入情况
运行上面两个测试代码,分别向惰性队列和普通队列发送一百万条消息。
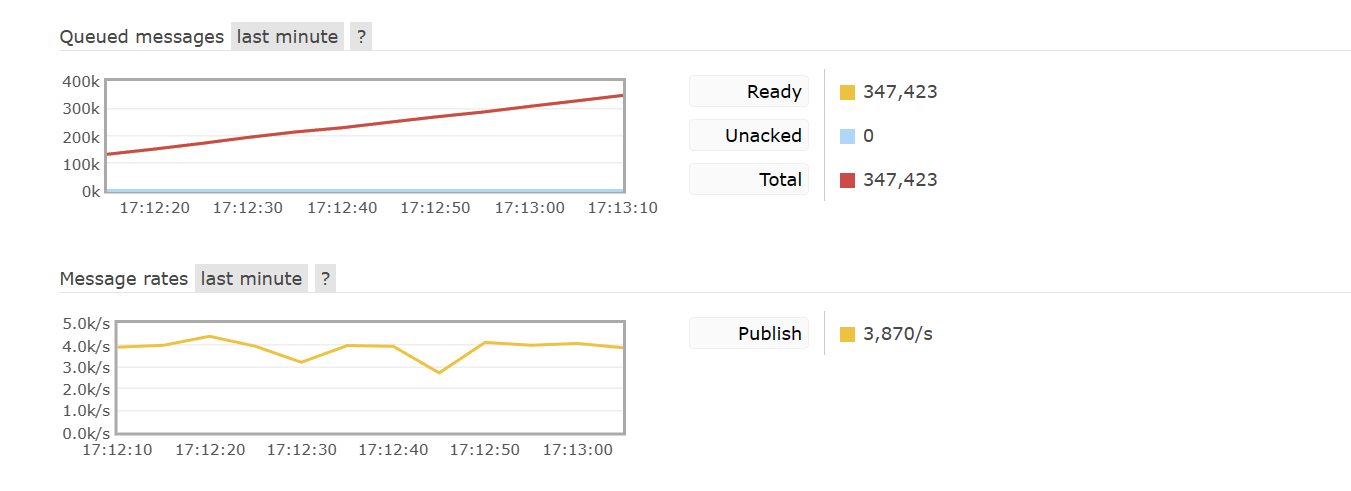
首先来看惰性队列,可以发现 “Queued messages” 消息累计是逐渐增多的,并且曲线却是接近直线,并且 “Message rates”消息的入队速度也是在一个范围内上下浮动:
 然后可以发现所有的消息全部都是 “Paged Out” 到了磁盘中:
然后可以发现所有的消息全部都是 “Paged Out” 到了磁盘中:

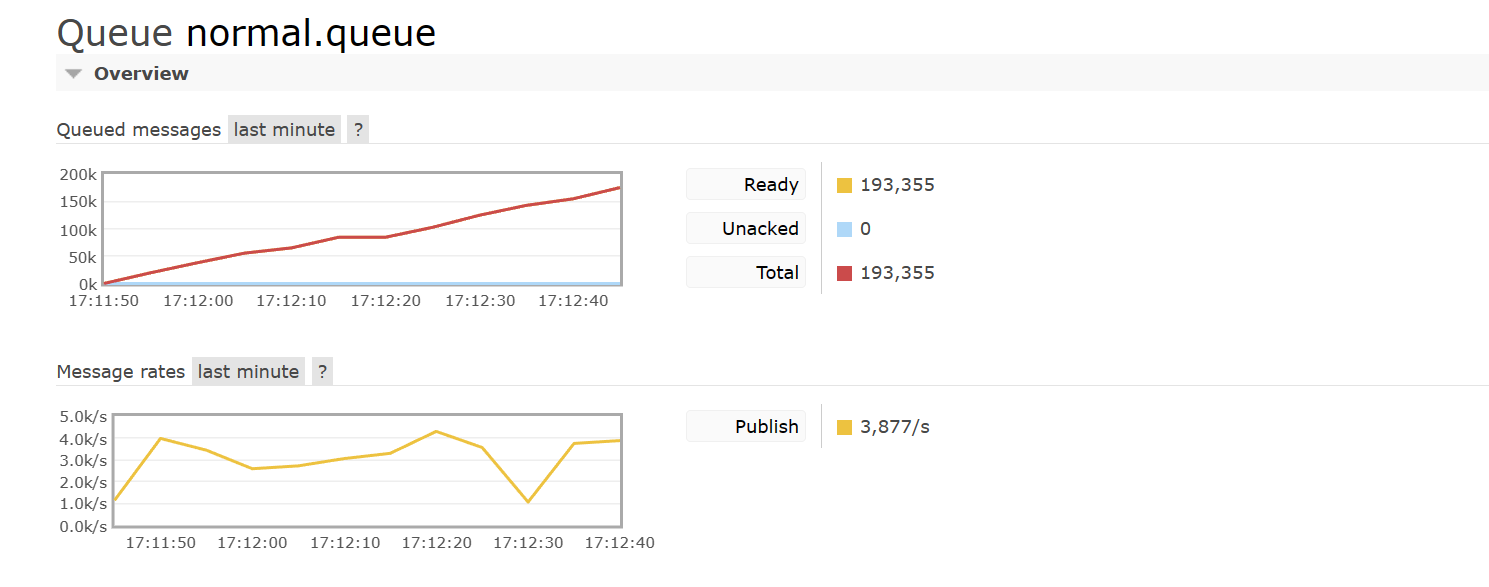
然后再来看普通队列,可以发现 “Queued messages” 消息累计也是逐渐增多的,并且曲线却是出现了弯折的情况,并且 “Message rates”消息的入队速度曲线上下浮动差距非常大:
 然后可以发现有一部分数据再内存中,其他大部分数据 “Paged Out” 到了磁盘上:
然后可以发现有一部分数据再内存中,其他大部分数据 “Paged Out” 到了磁盘上:

2.4 惰性队列的优缺点
惰性队列的优点:
-
基于磁盘存储,消息上限高:惰性队列将消息直接存储到磁盘中,而不是内存,因此它具有更高的消息存储上限。这意味着惰性队列能够容纳数以百万计的消息,而不会因内存限制而出现堆积问题。
-
没有间歇性的 page-out,性能比较稳定:惰性队列的消息存储方式避免了间歇性的 “page-out” 操作。在普通队列中,当内存预警值达到时,RabbitMQ会执行 “page-out” 操作,将消息从内存刷出到磁盘,这可能导致队列的性能出现间歇性波动。惰性队列不受此问题影响,因此性能较为稳定。
惰性队列的缺点:
-
基于磁盘存储,消息时效性会降低:由于惰性队列将消息存储到磁盘中,相比于存储在内存中,消息的访问速度较慢。这可能导致消息的时效性降低,即消息的传递速度会减缓。在某些实时性要求较高的应用中,这可能不是最佳选择。
-
性能受限于磁盘的 IO:惰性队列的性能受限于磁盘的读写速度,因为消息需要从磁盘加载到内存以进行处理。如果磁盘的IO性能不足,可能会影响消息的传递速度和队列的响应时间。
总之,惰性队列在处理大量消息且不要求实时性的场景中具有明显的优势,因为它可以有效避免消息堆积问题,并提供较高的消息存储上限。然而,对于需要更高时效性和更快响应时间的应用,可能需要考虑其他存储方式或性能优化策略。