机器学习算法彻底改变了我们处理和分析数据的方式,在从医疗诊断到自动驾驶汽车等领域取得了突破。然而,为了有效地训练这些模型,需要大量高质量的数据。这可能是一个挑战,尤其是在具有敏感或私人信息或难以获取数据的行业中。
合成数据已成为克服这些障碍的可行解决方案。在这篇博文中,我们将深入探讨合成数据的概念,解释它是什么,为什么它很重要,以及如何生成它以用于机器学习模型。无论您是数据科学家,还是只是对 AI 的内部工作原理感兴趣,本文都将全面概述合成数据及其在机器学习中的作用。
究竟什么是合成数据?
合成数据是指人工生成的数据,用于模拟真实世界的数据。它是通过算法和数学模型创建的,旨在模仿真实数据中的统计属性、模式和关系。合成数据可用于多种用途,包括测试和训练机器学习算法、保护敏感信息以及填补真实世界数据中的空白。
合成数据旨在提供真实世界数据的真实模拟,同时避免使用真实数据带来的道德、隐私和成本问题。通过使用合成数据,组织可以克服数据可用性有限的限制,同时仍能实现准确而强大的机器学习模型。
合成数据在机器学习中的作用以及为什么需要它?
机器学习需要合成数据有几个原因,包括:
- 缺乏真实世界的数据: 在某些情况下,获取真实世界的数据可能很困难、昂贵或不道德。合成数据可以无限量生成,即使在现实世界数据稀缺的情况下,也可以训练机器学习模型。
- 保护敏感信息:真实世界的数据通常包含必须保护的敏感信息。组织可以通过生成合成数据来训练机器学习模型,而不会损害隐私或安全性。
- 克服过拟合的风险:当机器学习模型与训练数据拟合得太近时,就会发生过拟合,从而导致新数据的性能不佳。生成合成数据可以通过为模型提供更多训练数据并增加数据集的多样性来帮助降低过拟合的风险。
- 提高模型精度: 通过使用合成数据,组织可以使用更多数据训练机器学习模型,从而提高准确性和性能。
- 测试和调试:合成数据可用于测试机器学习模型、调试问题并评估模型的性能,然后再将其部署到实际数据上。
简而言之,合成数据是机器学习的重要组成部分,因为它为真实世界数据的局限性提供了解决方案,能够保护敏感信息,并提高模型的准确性和性能。通过使用合成数据,组织可以克服数据稀缺的挑战并实现其机器学习目标。
如何生成用于机器学习模型的合成数据?
可以使用多种方法生成合成数据,包括:
- 从概率分布中抽样:此方法涉及从特定分布(如正态分布)中随机抽取值,以模拟真实数据。分布参数可以从真实世界的数据中估计出来,以确保合成数据尽可能真实。
- 生成对抗网络 (GAN):GAN由两个神经网络组成,一个用于生成合成数据,另一个用于将数据分类为真实或虚假。生成器网络生成合成数据,而鉴别器网络评估数据。随着时间的流逝,生成器网络提高了其数据生成能力,并且两个网络学会了协同工作以生成高质量的合成数据。
- 合成重叠法:这种方法涉及通过将真实数据与随机噪声相结合来创建合成数据。真实数据为合成数据提供了结构,而噪声有助于保护敏感信息并避免过度拟合。
- 决策树和随机森林: 这些算法可用于通过递归分区特征空间并从每个分区生成随机样本来生成合成数据。以这种方式生成的合成数据可以捕获特征和目标变量之间的非线性关系。
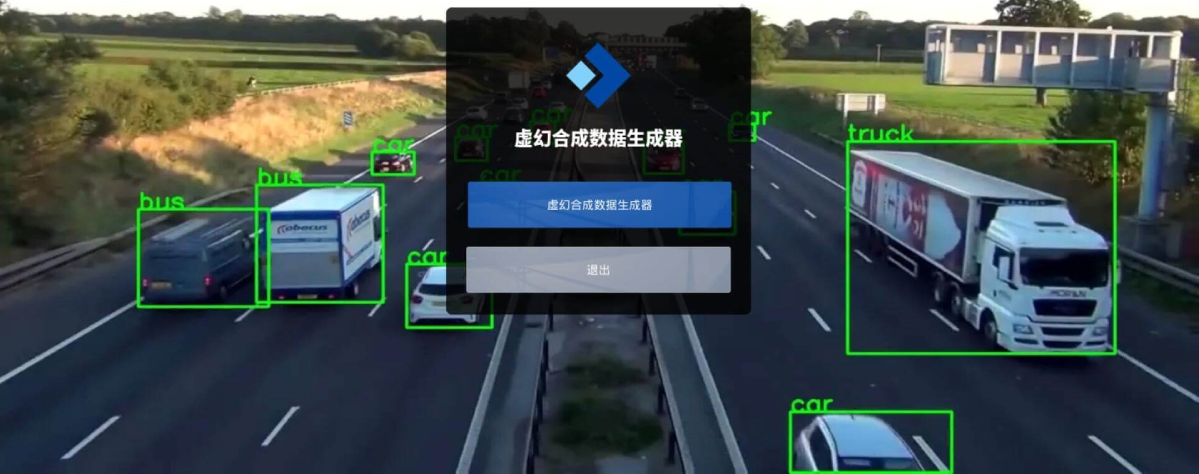
- 合成数据生成工具:UnrealSynth 虚幻合成数据生成器利用虚幻引擎的实时渲染能力搭建逼真的三维场景,为 YOLO 等 AI 模型的训练提供自动生成的图像和标注数据。UnrealSynth 生成的合成数据可用于深度学习模型的训练和验证,可以极大地提高各种行业细分场景中目标识别任务的实施效率,例如:安全帽检测、交通标志检测、施工机械检测、车辆检测、行人检测、船舶检测等。
无论使用哪种方法,合成数据生成都旨在生成尽可能接近真实世界数据的数据,同时避免使用真实数据带来的道德、隐私和成本问题。通过生成合成数据,组织可以使用更多数据训练机器学习模型,并降低过拟合的风险,从而生成更准确、更强大的模型。
结论
合成数据在机器学习中起着至关重要的作用,它为真实世界数据的局限性提供了解决方案。合成数据的生成使组织能够使用无限量的数据训练机器学习模型,保护敏感信息,降低过度拟合的风险,并提高模型的准确性。
凭借其模拟真实世界数据的能力,合成数据对于需要克服数据稀缺挑战的机器学习从业者和组织来说是一个有价值的工具。
转载:合成数据对于机器学习模型至关重要 (mvrlink.com)