性能测试监控关键指标:
1、系统指标:与⽤户场景与需求直接相关的指标
2、服务器资源指标:硬件服务器的资源使⽤情况的指标
3、JAVA应⽤ : JAVA应⽤程序在运⾏时的各项指标
4、数据库:数据库服务器运⾏时需要监控的指标
5、压测机资源指标:测试机在模拟⽤户负载时的资源使⽤情况 ⼀般情况下,测试⼈员执⾏性能测 试时,只需要关注1、2、5就可以,判断系统是否有性能问题 ⽽开发⼈员要定位性能问题时,需要 再次运⾏,并监控所有的性能指标,来进⾏分析并调优
系统指标
- 可以直接用来衡量系统处理能力的指标是(吞吐量)
- 在系统处于请压力区(未饱和)时,用户数上升,平时响应时间(基本不变),系统吞吐量(上升)
- 在系统处于重压⼒区(基本饱和)时,并发⽤户数上升,平均响应时间(上升),系统吞吐量(基 本不变)
- 在系统处于崩溃区(压⼒过载)时,并发⽤户数上升,平均响应时间(上升),系统吞吐量(下 降)
硬件服务器资源指标
硬件的组成:控制器+计算器+输出+输出+存储
控制器+计算器:CPU、GPU
存储:硬盘、内存
输⼊+输出:外接设备,⽹络,⿏标键盘。
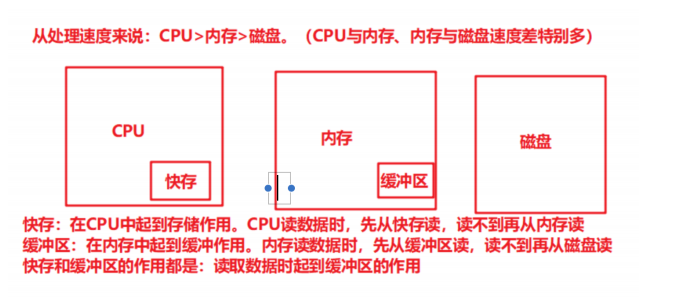
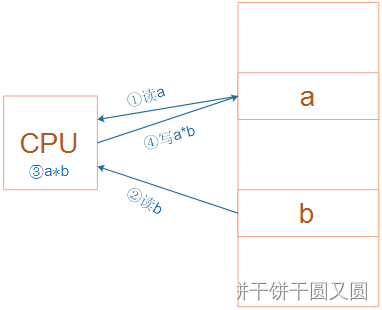
内存和虚拟内存:
1、正常情况下,程序加载到内存中来执⾏
2、当内存不够时,会加载部分⽴即要执⾏的程序到内存中,其他的程序部分放在磁盘中(虚拟内存)
3、当⽴即要执⾏的程序执⾏完成后,从虚拟内存中读取其他的数据内容到实际内存中,再执⾏程序的 处理
4、依次循环第3步完成程序的运⾏ 卡的原因的就是:每次都需要从虚拟内存(磁盘)中读取数据进⾏执⾏,磁盘的读取速度相对CPU和内存⽽ ⾔⾮常,因此感觉内存不⾜程序很卡 闪退的原因就是:在第2步中,需要加载部分⽴即要执⾏的程序到内存中,如果当前的内存空间不满⾜ 最 低要求(⽴即要执⾏的程序所需要的内存)时,就会出现闪退
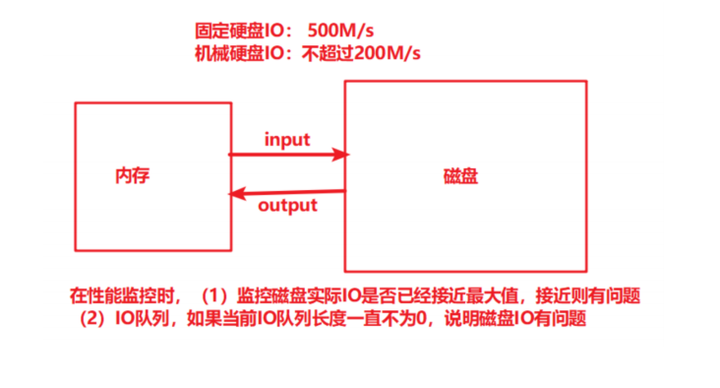
磁盘IO
网络
监控实际的⽹络流量,与⽹络带宽做对⽐,如果实际⽹络流量与⽹络带宽接近,则说明⽹络存在瓶颈, 需要优化。
百兆带宽:100Mbyte/s 实际技术中衡量的宽带的单位:KB/s,因此需要换算:100/8 = 12.5MKB/s
磁盘读取数据方式
寻道时间
寻址时间
读取时间
数据库
mysql数据库原理:
1.mysql主要存储在磁盘盘上
2.磁盘读取数据靠的是机械运动,当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的 控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
3.为了读取这个扇区的数据,需要将磁头放到这个扇区上⽅,为了实现这⼀点,磁头需要移动对准相应 磁道,这个过程叫做寻道,所耗费时间叫做寻道时间。
4.然后磁盘旋转将⽬标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
5.最后便是对读取数据的传输
6.每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分。(ps.各个时间的花费:)
寻道时间是磁臂移动到指定磁道所需要的时间,主流磁盘⼀般在5ms以下。
旋转延迟就是我们经常听说的磁盘转速,⽐如⼀个磁盘7200转,表示每分钟能转7200次,也就是 说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms。
传输时间指的是从磁盘读出或将数据写⼊磁盘的时间,⼀般在零点⼏毫秒,相对于前两个时间可以 忽略不计。
I/O操作问题:
a. 访问⼀次磁盘的时间,即⼀次磁盘IO的时间约等于5+4.17 = 9ms左右.
b.⼀台500 -MIPS的机器每秒可以执⾏5亿条指令.
c.因为指令依靠的是电的性质,换句话说执⾏⼀次IO的时间可以执⾏40万条指令.
d.数据库动辄⼗万百万乃⾄千万级数据,每次9毫秒的时间,显然是个灾难。
磁盘预读
因此为了提⾼效率,要尽量减少磁盘I/O,为了达到这个⽬的,磁盘往往不是严格按需读取,⽽是 每次都会预读。
即使只需要⼀个字节,磁盘也会从这个位置开始,顺序向后读取⼀定⻓度的数据放⼊内存。
这样做的理论依据是计算机科学中著名的局部性原理:当⼀个数据被⽤到时,其附近的数据也通常 会⻢上被使⽤。
预读的⻓度⼀般为⻚(page 4kb⼤⼩的数据 )的整倍数。
⻚是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的⼤⼩相等 的块
每个存储块称为⼀⻚(在许多操作系统中,⻚得⼤⼩通常为4k),主存和磁盘以⻚为单位交换数 据。
当程序要读取的数据不在主存中时,会触发⼀个缺⻚异常,此时系统会向磁盘发出读盘信号 磁盘会找到数据的起始位置并向后连续读取⼀⻚或⼏⻚载⼊内存中,然后异常返回,程序继续运 ⾏。
压测机资源指标
模拟真实场景和服务器尽可能保持⼀致即可
Python接口自动化测试零基础入门到精通(2023最新版)