文章目录
- 一、维度模型设计的4步过程
- 1.1 第一步:选择业务过程
- 1.2 第二步:声明粒度
- 1.3 第三步:确定维度
- 1.4 第四步:确定事实
- 二、零售业务案例研究
- 2.1 第一步:选择业务过程
- 2.2 第二步:声明粒度
- 2.3 第三步:确定维度
- 2.4 第四步:确定事实
- 三、维度表设计细节
- 3.1 日期维度
- 3.2 产品维度
- 3.3 商店维度
- 3.4 促销维度
- 3.5 其他零售业维度
- 3.6 事务号码的退化维度
- 四、实际的销售模式(星型模型)
- 五、零售模式的扩展能力
- 六、无事实的事实表
- 七、维度与事实表键(忽略)
- 7.1 维度表代理键
- 7.2 维度中自然和持久的超自然键
- 7.3 退化维度的代理键
- 7.4 日期维度的智能键
- 7.5 事实表的代理键
- 八、抵制规范化的冲动
- 8.1 具有规范化维度的雪花模式
- 8.2 支架表
- 8.3 包含大量维度的蜈蚣事实表
- 九、本章小结
一、维度模型设计的4步过程
业务方目的(分析决策) ========》 星型模型
1.1 第一步:选择业务过程
业务方谈论的往往是抽象的业务战略规划,而不是业务过程,他们也无法回答“业务过程是什么?”这种问题。数仓人员需要做的是深入挖掘理解数据和操作型系统,将业务规划分析分解成为基本的业务过程。
(1)业务过程通常用行为动词表示,因为它们通常表示业务执行的活动。与之相关的维度描述与每个业务过程事件关联的描述性环境。
(2)业务过程通常由某个操作型系统支撑,例如,账单或购买系统。
(3)业务过程建立或获取关键性能度量。有时这些度量是业务过程的直接结果,度量从其他时间获得。分析人员总是想通过过滤器和约束的不同组合,来审查和评估这些度量。
(4)业务过程通常由输入激活,产生输出度量。在许多组织中,包含一些列过程,它们既是某些过程的输出,也是某些过程的输入。用维度建模人员的话来说,一些列过程产生一些列事实表。
1.2 第二步:声明粒度
声明的粒度应该是业务过程的最细粒度。
声明粒度意味着精确定义某个事实表的每一行表示什么。粒度传递的是与事实表度量有关的细节级别。它回答“如何描述事实表中每一行的内容?”这一问题。粒度由获取业务过程事件的操作型系统的物理实现确定。
典型粒度声明如下:
(1)客户销售事务上的每个产品扫描到一行中
(2)医生开具的票据的列表内容项采用一行表示
(3)机场登机口处理的每个登机牌采用一行表示
上述粒度声明以业务术语表示。也许您一直期望粒度由对事实表主键的传统声明描述。尽管最终的粒度与主键是等价的,但将维度集合列出,然后假定这一集合就是粒度声明的方法是不正确的。无论何时,都应该以业务术语表示粒度。
1.3 第三步:确定维度
最细粒度确定了事实表的主要维度
维度要解决的问题是“业务人员如何描述来自业务过程度量事件的数据?”应当使用健壮的维度集合来装饰事实表,这些维度表示承担每个度量环境中所有可能的单值描述符。如果粒度清楚,维度通常易于区分,因为它们表示的是与“谁、什么、何处、何时、为何、如何”关联的事件。常见维度的实例包括日期、产品、客户、雇员、设备等。在选择每个维度时,应该列出所有具体的、文本类型的属性以充实每个维度表。
1.4 第四步:确定事实
分为可加事实、不可加事实(单价、率(以分子、分母存储))
可以通过回答“过程的度量是什么?”这一问题来确定事实。设计中的所有候选事实必须符合第2步的粒度定义。明显属于不同粒度的事实必须放在不同的事实表中。
需要综合考虑业务用户需求和数据来源的实际情况,并与4个步骤联系起来,如图所示。我们强烈建议坚决抵制仅仅只考虑数据来源来建模。虽然将注意力放在数据上可能不会像与商业用户交流那样复杂,但数据不能代替业务用户的输入(业务描述)。遗憾的是,许多组织仍在采用这种看似最省力的数据驱动的方法,当然这样做基本不能取得成功。

二、零售业务案例研究
2.1 第一步:选择业务过程
设计的第1步是通过对业务需求以及可用数据源的综合考虑,决定对哪个业务过程开展建模工作。
在此零售业务案例中,管理层希望更好的理解通过POS系统获得的客户购买情况。因此需要建模的业务过程是POS零售交易。该数据保证商业用户能够分析被销售的产品,它们是在哪几天、在哪个商店、处于何种促销环境中被销售的。
2.2 第二步:声明粒度
有许多理由要求以最低的原子粒度处理数据。原子粒度具有强大的多维性。事实度量越详细,就越能获得更确定的事实。将您所知的所有确定的事情转换成维度。在这点上,原子数据与多维方法能够实现最佳匹配。
原子数据能够提供最佳的分析灵活性,因为原子数据可以被约束以某种可能的方式上卷。维度模型中的细节数据可以适应商业用户比较随意的查询请求。
在此零售业务案例中,最细粒度的数据是POS交易的单个产品,假设POS系统按照一个购物车中某种产品为单一项而上卷所有销售。尽管用户可能不会对分析与特定POS交易关联的单项感兴趣,但是可能他们希望知道周一与周日的销售差别,或者希望评估是否值得备存大量的某品牌的商品,或者希望知道有多少购物者利用了洗发液50美分的降价促销等。尽管上述查询不需要某一特定交易的数据,但他们提出的查询请求需要以精准的方式对详细数据执行分片操作而获得。如果仅提供汇总数据,则无法获得这些问题的正确答案。
DW/BI系统几乎总是要求数据尽可能最细粒度来表示,不是因为需要查询单独的某行而是因为查询需要以非常精确的方式对细节进行切分。
2.3 第三步:确定维度
详细的粒度说明确定了事实表的主要维度。然后可以将更多维度增加到事实表上,只要这些额外的维度自然的承担主维度合并的某个值。如果附加的维度会产生与粒度不符的其他事实行,则取消该维度或重新考虑粒度声明。
在此零售业务案例中,描述性维度有:日期、产品、门店、促销、收银员、支付方式。此外,POS事务号码作为一个特殊维度(退化维度,即没有对应的维度表)也包含在其中。
在使用描述性属性填充维度表前,需要完成4步过程的最后一步。不希望再设计的这一阶段只见树木不见森林。
2.4 第四步:确定事实
设计的最后一步是确认应该将哪些事实放在事实表中。粒度声明有助于稳定相关的考虑。事实必须与粒度吻合:放入POS交易的单独产品线项(单个产品)。在考虑可能存在的事实时,可能会发现仍然需要调整早期的粒度声明或维度选择。
在此零售业务案例中,POS系统收集的事实包括销售数量(例如,鸡汤面的听数)、单价、折扣、净支付价格、折扣价格、美元销售额等。扩展的美元销售额等于销售数量乘以净单位价格。同样地,扩展的销售折扣额等于销售数量乘以单位折扣额。某些复杂的POS系统也提供茶品的标准美元成本,由供货商发布给商家。假设这些成本事实随时可用且不需要记述详细的基于活动的成本来源,则可以将扩展开销额包含在事实表中。如图展示了事实表雏形。
四类事实,涉及所有维度的销售数量、销售可扩展额、销售额、成本额,均是完全可加的。可以对事实表按照维度属性不受限制地开展切片操作。针对这四类事实展开的汇总工作都是合法正确的。
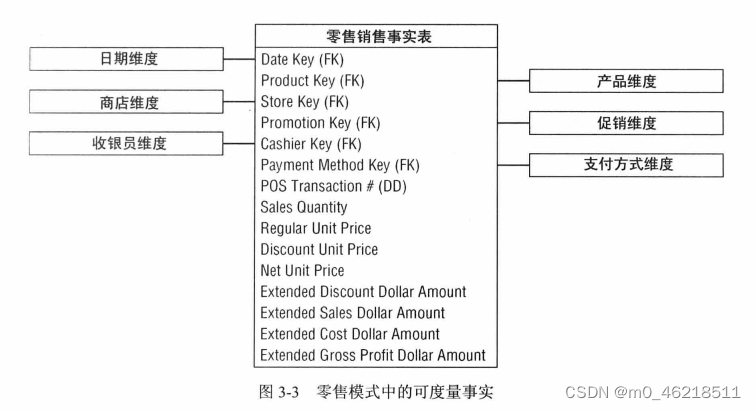
三、维度表设计细节
3.1 日期维度
与多数其他维度不同,可以提前建立日期维度表。可以在表中按行表示10年或20年的不同日期,因此可以涵盖存储的历史,也可以包含未来的几年。
SQL日期函数不支持以属性(例如,工作日与周末、假日、财务周期、季度)进行过滤。假定业务需要按照非标准的日期属性对日期分片,那么建立一个详尽的日期维度就是基本的需求。日历逻辑由维度表解决,而不是由应用代码来解决。
维度模型总是需要详尽的日期维度表。SQL日期函数不支持范围广泛的日期属性,包括周、财务周期、季节、假日、周末等。与其试图将这些非标准日历计算放入查询中,不如放在日期维度表中,通过查询获得。另外,尽量用文字描述代替y/n标识!
CREATE TABLE IF NOT EXISTS `test.dim_com_date_info_ymd` (`date_id` INT COMMENT '日期ID',`date_day` STRING COMMENT '日期',`day_of_week` INT COMMENT '所在周的第几天,每周从周一开始',`day_of_month` INT COMMENT '所在月的第几天,每月从1号开始',`day_of_year` INT COMMENT '日期所在本年第几天',`week_name` STRING COMMENT '星期',`is_weekend` INT COMMENT '是否周末',`week_of_month` INT COMMENT '当月第几周',`week_of_year` INT COMMENT '当年第几周',`week_begin_date` STRING COMMENT '本周第一天',`week_begin_date_id` INT COMMENT '本周第一天id',`week_end_date` STRING COMMENT '本周最后一天',`week_end_date_id` STRING COMMENT '本周最后一天id',`month` INT COMMENT '月份',`month_name` STRING COMMENT '月份名称',`month_begin_date` STRING COMMENT '本月第一天',`month_begin_date_id` STRING COMMENT '本月第一天id',`month_end_date` STRING COMMENT '本月最后一天',`month_end_date_id` STRING COMMENT '本月最后一天id',`quarter` INT COMMENT '季度',`quarter_name` STRING COMMENT '季度名称',`festival_name` STRING COMMENT '法定节假日',`is_festival_day` INT COMMENT '是否法定节假日',`is_work_day` INT COMMENT '是否工作日',`week_from_20100101` INT COMMENT '累计第几周'
) COMMENT '日期维度表'
ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat';
3.2 产品维度
产品维度几乎总是来源于操作型产品主文件。

(1)扁平化多对一层次
产品维度表示每个SKU的大多数描述性属性。商品层次是属性的主要分组之一。单个的SKU上卷到品牌,品牌上卷到类别,类别分类上卷到部门。每一不同层次都存在多对一关系。此类商品层次与其他属性如图所示。虽然高层次属性会存在很多重复数据,但是没必要为了节省空间而规范化,相比于事实表维度表占用空间少很多。
将重复的低粒度值保存在主维度表中是一种基本的维度建模技术。规范化这些值将其放入不同的表将难以实现简单化与高性能的主要目标,正如后面抵制规范化冲动讨论的那样。
(2)具有内嵌含义的属性
例如:如果业务系统中的某个字段值的第5到第9个字符表示制造商,则应当截取出来作为维度表中的一个字段。
(3)作为属性或事实的数字值
有时可能会遇到某些数字值,很难判断应该将其归入维度属性分类,还是归入事实分类。经典的例子是产品的价格标准列表。产品价格很显然是一个数字值,因此初始的想法可能是将其当成事实来对待。但是通常标准价格变化缓慢,不像其他事实表中的数量值,对不同的度量事件产生不同的值。
如果某个数字主要用于计算目的,则属于事实。虽然标准价格是非可加的,但是可用它乘以数量获得扩展总额,这个值是可加的。另外,如果标准价格主要用于价格变化分析,也许变化度量应该被存储于事实表中。如果能预先定义稳定的数字值,用于过滤和分组,则它应该被当成产品维度属性对待。
有时,数字值可同时用于计算以及过滤/分组功能。在此情况下,应当在事实表和维度表中同时存储该值。事实表中的标准价格表示销售事务的价格,而维度属性则标记为指示其当前情况的标准价格。
(4)下钻维度属性
下钻只不过是从维度表中请求行头指针以提供更多信息。假定有一个简单报表需求,用于按部门汇总销售额。如图3-9,如果需要下钻,可以从产品维度中拖拽任何属性,如品牌,放入报表,紧靠部门之后,可以自动下钻下一个层次的细节情况。可以根据脂肪含量属性下钻,即使该属性并不在需要上卷的商品层次上。
在维度模型上下钻只不过从维度表中增加移除了行头指针属性。上卷是移除,下钻是增加。可以根据属性从多个层次上卷或下钻,其中部分属性不是层次的组成部分。
3.3 商店维度
与产品主文件在每个大型食品杂货连锁业都已经存在不同,一般没有一个全面完整的商店主文件。POS系统可能仅仅支交易记录上的商店号。在此情况下,项目组必须从多个操作型源汇集构建商店维度所需的各种元素。通常在总部都会存在一个商店的房产部门,利用该部门的信息可定义详细的商店主文件。

(1)多层次维度表
商店维度是本案例中主要的地理维度,可以按照任何地理属性对商店进行上卷操作,例如,邮编、国家、各个州等。按照一般观点城市和州不在一个层次上。但是许多州包含名称相同的城市,因此可能需要在商店维度中包含一个城市-州(city-state)属性。
(2)维度表中的日期
商店维度中的首次开店日期与最后改建日期是日期类型的列。如果用户希望按照非标准的日期属性(如开店日的财务周期)分组和约束,则需要连接键以复制到日期维度表中。这些日期维度拷贝可通过视图结构用SQL描述,并与主要日期维度存在语义上的差别。视图定义如下:
create view first_open_date(first_open_day_number,first_open_month,...)
as select day_number,month,...
from date
建立的视图是商店维度允许的支架。
3.4 促销维度
促销维度可能是零售业模式中最有趣的维度。促销维度描述了销售商品的促销条件。促销条件包括临时降价、终端通道展示、报纸广告、礼券等。促销维度通常被认为是一种因果维度,因为它描述了认为可能导致产品销售发生改变的因素。某个促销是否有效,通常基于以下一个或多个因素来判断:
-
促销产品的销售是否在促销期间获得大幅提升。提升多少的度量可以根据未进行促销活动时,该产品的基本销售情况来定。基本销售情况可以从先前历史销售情况估计出来。
-
促销产品在促销前或促销后的销售,与促销期间的销售比较,是否有降低,这种降低是否抵消了促销期间的销售增益。换句话说,是否将常规价格产品的销售转换到降价销售产品上?
-
促销产品在销售方面表现良好,但是其他与其相邻的产品的销售却显著降低了(销售侵蚀)。
-
促销分类中的所有产品是否都获得了销售方面的净总增益,将考虑促销前、促销期间、促销后的时间段(市场增大)。
-
促销是否有利可图。通常促销的利润考虑整个促销分类的利润与基本销售利润之比,当然需要考虑促销期间和销售侵蚀,以及促销开销的影响。

纯粹从逻辑上考虑,通常将4个不同的因果机制(降价、广告、展示、礼券)区分开,建立不同的维度而不是将它们合并在一个维度中,这一方法将会记录与促销信息相似的信息。当然,最终如何选择是设计者的权利。
赞成4个维度放一起的理由: -
如果4个因果机制高度关联,合并而成的单一维度不会比任一个单个维度大很多。
-
合并成单一维度方便浏览,观察降价、广告、展示、礼券的相互影响关系。然而,这样的浏览仅展示了可能的促销组合。对维度表的浏览无法揭示促销对哪个商店或哪个产品有影响,此类信息显然需要浏览事实表方能获得。
赞成4个维度划分到4个不同的维度中的理由:
- 对业务群体来说,当分别考虑不同的机制时,不同的维度可能更易于理解。在业务需求访谈期间,这一问题就会显露出来。
- 对不同维度的管理可能比对合并维度的管理更直接。
3.5 其他零售业维度
出纳员维度、支付方式维度
3.6 事务号码的退化维度
事实表中的没有对应维度表的维度键
四、实际的销售模式(星型模型)
星型模型
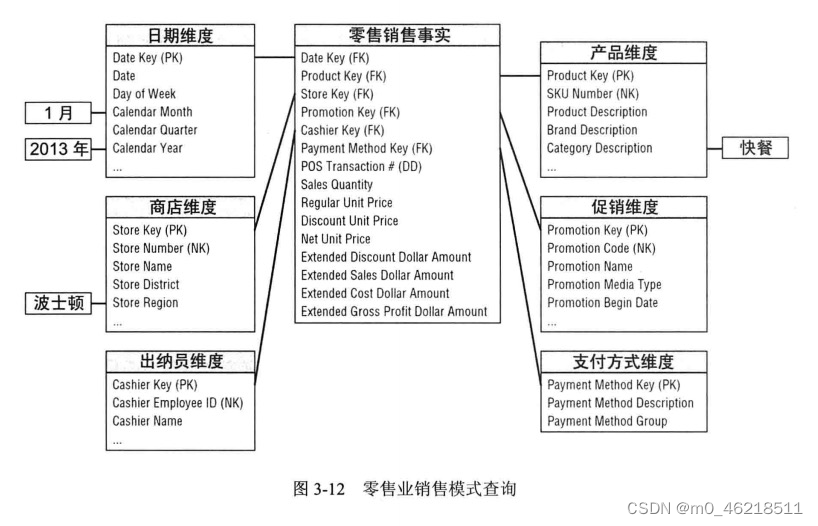
查询(维度+指标)
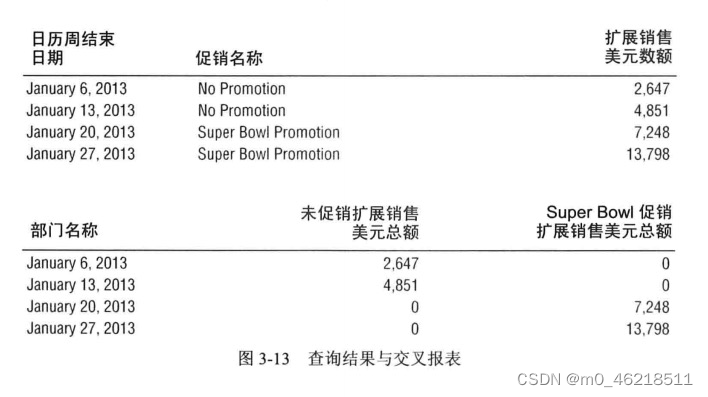
五、零售模式的扩展能力
以最细级别声明粒度是保障扩展能力的前提,当最初建模时是以最细粒度级别构建的,增加的维度可以方便的应用细粒度,如果最初定义的粒度时日零售销售(按天、商店、产品和促销汇总的事务),而不是事务列表细节数据,则无法合并到原有事实表上。过早聚集和汇总限制了增加补充维度的能力,因为增加的维度通常无法在更高粒度级别上应用。
- 新维度属性(新枚举值)。可以把新属性值作为新列增加进去,所有现存应用不受影响。如果新属性仅在特定时间点可用,则老的维度行中将插入不可用或类似的描述。
- 新维度。可在事实表上增加新维度的主键,作为新的维度外键。
- 新事实。如果新事实在原有的度量事件中可用,并与已经存在的事实粒度相同时,增加新列即可。如果新事实仅在某个时间点可用,则将空值填充到旧的事实表行中。当新的可度量事实与原有粒度不同时,需要新建一个新粒度的事实表。
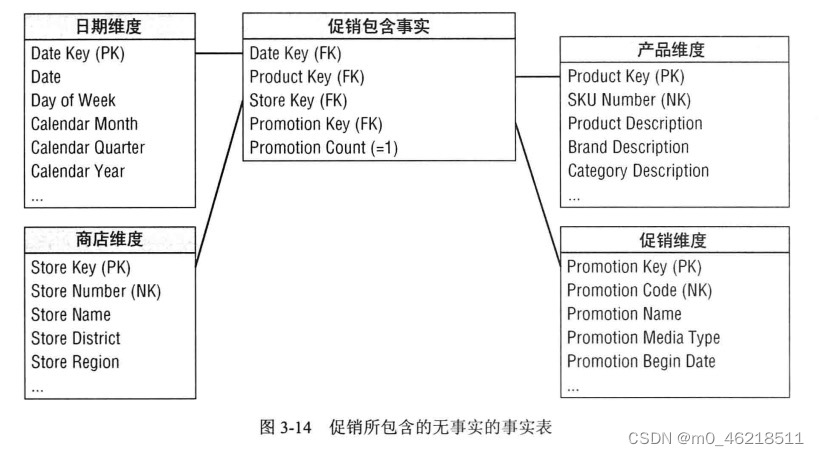
六、无事实的事实表
关系表,仅描述键之间的关系
前面介绍的零售模式无法回答一个问题是:处于促销状态但尚未销售的产品包括哪些?销售事实表所记录的仅仅是实际卖出的SKU。事实表行中不包括由于没有销售而SKU为零值的行,因为如果包含,事实表将变的非常巨大。
回答上述问题,需要促销事实表,此表与刚刚的销售事实表粒度虽然看起来相似,但是存在显著差别。在促销事实表中,将为每天每个商店中促销的产品加载一行,无论产品是否卖出。事实表能够确保看到SKU与促销键之间的关系。
七、维度与事实表键(忽略)
7.1 维度表代理键
7.2 维度中自然和持久的超自然键
7.3 退化维度的代理键
7.4 日期维度的智能键
7.5 事实表的代理键
八、抵制规范化的冲动
我们一直在有意识的打破传统建模规则,因为我们主要的关注点是易用性和查询性能,而不是事务处理的效率。
8.1 具有规范化维度的雪花模式
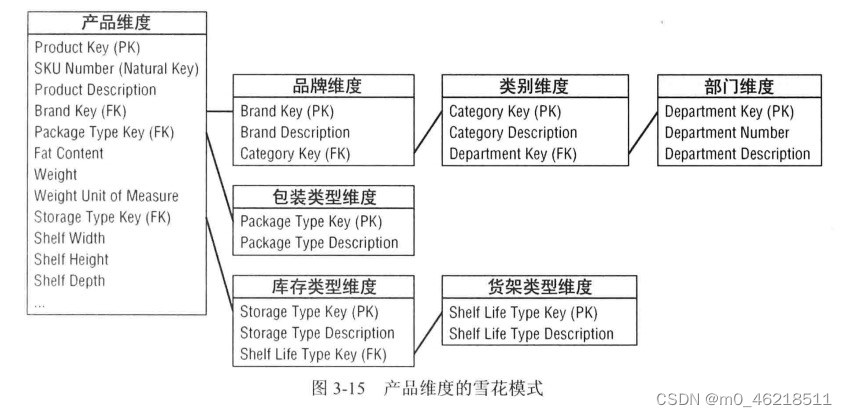
缺点:
- 雪花模型看起来更复杂,不易理解。
- 大量的表关联操作会影响数据库优化器选择优化策略的准确性,影响查询性能。
- 与事实表相比,维度表行数少的多,并不能节省多少空间。
- 浏览维度的能力差。
- 如果想要查分类中的所有品牌,则需要遍历品牌和分类维度。如果还希望获得分类中每个品牌的包装类型,则需要遍历更多表。简单的查询,SQL相当复杂。
- 无法实现位图索引。
8.2 支架表
受限的雪花模型。当一个属性集合(例如日期、地点)在某个维度或多个维度表中反复出现时,就可以考虑使用支架表。

8.3 包含大量维度的蜈蚣事实表
维度模型中的事实表天然具有高度规范化和紧凑的特性,即使有紧凑的格式,事实表也是维度模型中的巨兽。包含太多维度的事实表设计,将导致事实表需要更多磁盘空间。尽管非规范化维度表需要额外的空间,但是事实表仍是最大的问题,因为事实表是最大的表,和维度表不是一个数量级的。
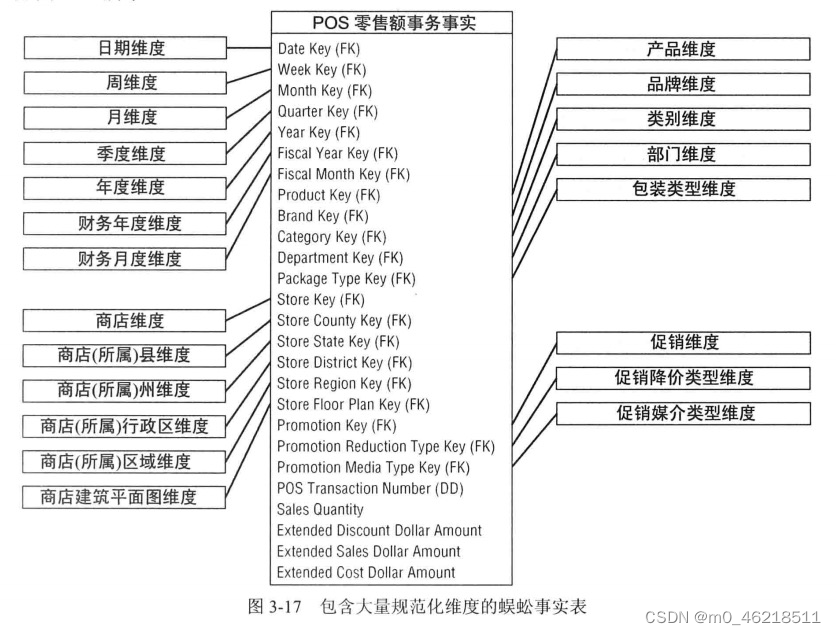
多数业务过程可以用不超过20个维度的事实表表示。如果某个设计超过25个或更多维度,应该考虑采取措施合并关联的维度。具有良好关联的属性,例如,层次级别,以及具有统计相关性的属性,都应该放入一个维度中。在产生的新维度比不同维度的笛卡尔积小很多的情况下,可以考虑合并这些维度。
九、本章小结
选择业务过程 -> 声明粒度 -> 确定维度 -> 确定事实