本文介绍
本篇文章给大家介绍的是,当我们在进行有关时间序列相关的工作或者实验时,需要对数据进行的一些数据分析操作(包括周期性、相关性、滞后性、趋势性、离群值等等分析)的方法。在本篇文章中会以实战的形式进行讲解,同时提供运行代码和运行结果图片,同时如果大家是数据方面的初学者这篇文章不仅会带你学习一些数据分析的相关操作,也会带大家对于数据分析和时间序列的建模有一个理解。
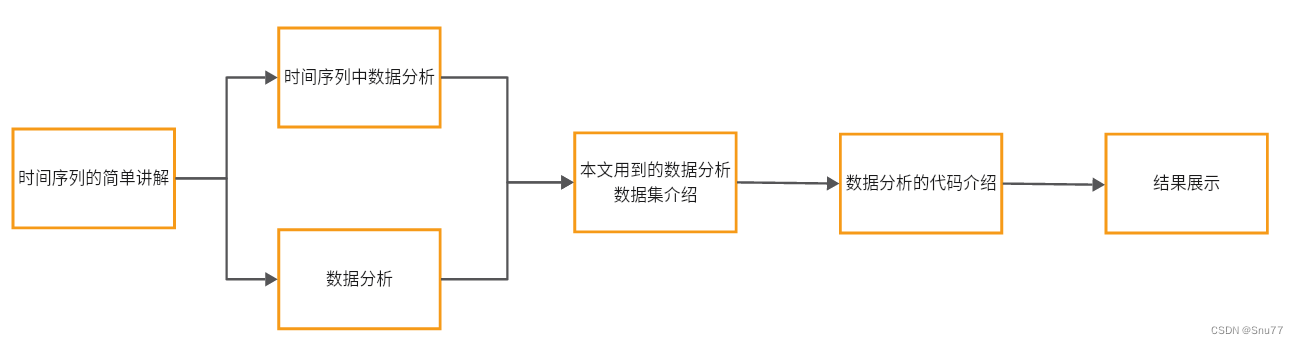
本文的讲解路径如下->
适用对象->数据相关的工作者或学习者
时间序列分析
时间序列分析是一种统计方法,用于研究随时间变化的数据序列。它涉及收集、观察和分析一系列按时间顺序排列的数据点。时间序列是连续的,例如每小时的气温变化,也可以是离散的,例如每月的销售数量。
时间序列分析的主要目标是揭示数据背后的模式、趋势、季节性以及其他有意义的结构。这种分析有助于预测未来的值、理解过去的变化以及对系统的行为进行建模。
具体大家想要了解可以看我的另一篇博客里面详细介绍了时间序列分析的工作原理和方法总结
15种时间序列预测方法总结(包含多种方法代码实现)
数据分析
数据分析概念
数据分析是一种通过收集、清洗、转换和解释数据来获得有用信息的过程。它利用一定的方法和技术,探索数据的模式、趋势和关联,并为其它问题提供支持。数据分析通过统计分析、机器学习、数据可视化等手段,揭示数据背后的关联,并将其转化为实际的解决方案。
总结:其实今天的市场上对于数据分析的岗位需求量真的在增多,因为现在是大数据和人工智能的时代,各行各业都需要对数据进行一定的分析,我本人从事的几份算法工作里和做的项目里都离不开数据分析,所以还是建议大家能够掌握数据分析这项技能就算不完全掌握还是要有一个深入的理解的,这对于未来求职是有很大帮助的(以上仅代表个人简介)。
时间序列预测中的数据分析
大家首先要知道数据分析是一个很大的概念,然后时间序列预测中的数据分析是属于其中的一中的,类似于机器学习和深度学习的关系(深度学习属于机器学习的一种)。时间序列预测中的数据分析涉及到的有以下->
- 周期性分析:周期性分析是在确定时间序列数据是否具有重复出现的模式。常用的周期性分析方法包括自相关函数(ACF)和傅里叶变换等。自相关函数可以显示数据在不同滞后时间下的相关性,如果数据在某个滞后时间点上显示出显著的相关性,那么可能存在周期性。傅里叶变换可以将时间域的数据转换为频域,帮助检测数据中的频率成分。
- 相关性分析:相关性分析用于衡量时间序列数据之间的相关程度。常用的相关性分析方法包括计算皮尔逊相关系数和斯皮尔曼相关系数。皮尔逊相关系数适用于线性关系的测量,而斯皮尔曼相关系数适用于非线性关系的测量。通过分析相关性,你可以了解各个时间序列之间的关联关系。
- 滞后性分析:滞后性指的是数据之间的滞后关系。滞后性分析可以帮助你确定数据之间的滞后时间,即一个数据是否受前一时期或几个时期的影响。常用的滞后性分析方法包括自相关函数(ACF)和偏自相关函数(PACF)。自相关函数显示数据与自身在不同滞后时间下的相关性,而偏自相关函数则显示了在剔除其他滞后影响后的部分相关性。
- 趋势性分析:趋势性分析用于确定数据是否存在明显的趋势或变化。常用的趋势性分析方法包括简单移动平均、加权移动平均和趋势线拟合等。简单移动平均可以平滑数据并显示数据的整体趋势,而加权移动平均则给最近的数据点更大的权重。趋势线拟合可以使用线性回归或其他曲线拟合方法来估计数据的趋势。
- 离群值分析:离群值是指在时间序列数据中与其他观测值明显不同的异常值。离群值分析有助于确定数据中的异常观测值,并评估这些值对预测模型的影响。常用的离群值分析方法包括箱线图、Z分数、3σ原则和孤立森林等。
总结:以上是一些常见的时间序列数据分析方法,它们可以帮助你深入了解数据的特性,并为时间序列预测建立合适的模型提供重要的指导。在实际应用中,你可以根据数据的特点选择适合的分析方法,并结合可视化工具进行更全面的分析。
数据集介绍
我们下面分析用到的数据集如下->
数据集的获取方式在我的CSDN上传里面有大家可以自行下载。
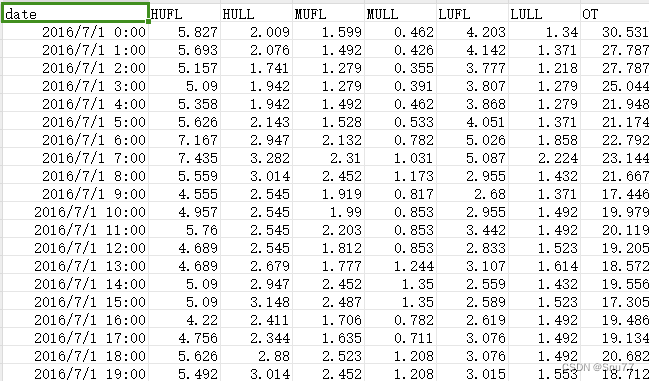
数据分析的代码
首先我先将以下用到的所有库放在这里要不然每一个代码都可能用到重复的库,这里就一次性导入了,到家可以自行分析。
import pandas as pd
from statsmodels.tsa.stattools import acf
import matplotlib.pyplot as plt
import seaborn as sns
我们进行分析的是数据集的OT列我们将其导入。
# 读取数据
df = pd.read_csv('ETTh1.csv') # 替换为您的数据文件路径# 提取OT列数据进行分析操作
column_data = pd.to_datetime(df['OT'])周期性分析
自相关图(ACF)
def acfDataPlot(data):# 计算自相关函数acf_result = acf(column_data, nlags=20)# 设置 seaborn 风格sns.set(style='whitegrid')# 绘制图表plt.figure(figsize=(10, 6))plt.stem(acf_result)plt.xlabel('Lag')plt.ylabel('Autocorrelation')plt.title('Autocorrelation Function')# 保存图像文件plt.savefig('acf_plot.png')
上述代码我们输入某一数据就能绘画出自相关图,我们先来看图片然后教大家如何进行分析自相关图。
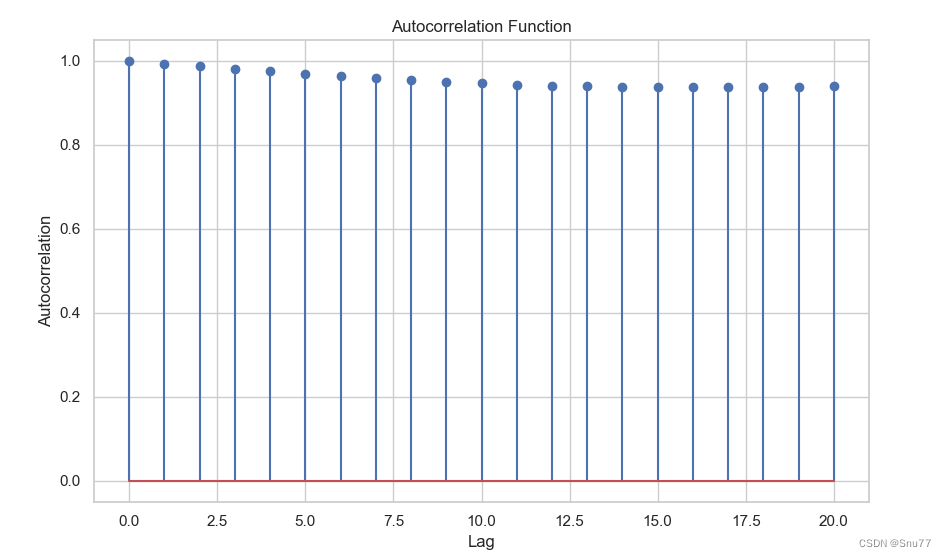
在计算acf的时候大家可以看到设置了nlags=20,其是什么意思呢,就是观测我第21个值和过去20个数值的一个关系,可以判断数据是正相关还是负相关,我们可以持续增大这个值知道模式发生改变那个值可能就是你数据的周期性值。
自相关函数的取值范围通常介于-1和1之间,可以用来度量时间序列数据的相关性。
- 自相关函数的取值为0表示没有相关性,即时间序列中的观测值之间没有线性关系。
- 当自相关函数的值为正数时,表示时间序列中的观测值之间存在正相关性,一个较大的值往往伴随着较大的邻近值。
- 当自相关函数的值为负数时,表示时间序列中的值之间存在负相关性,一个较大的值往往伴随着较小的邻近值。
傅里叶变换(FourierTransform)
def FourierDataPlot(column_data):# 计算傅里叶变换及频谱# 计算傅里叶变换及频谱fft = np.fft.fft(column_data)freq = np.fft.fftfreq(len(column_data))plt.plot(freq, np.abs(fft))plt.xlabel('Frequency')plt.ylabel('Amplitude')plt.title('Frequency Spectrum')plt.grid(True)plt.savefig('fourier_plot.png')
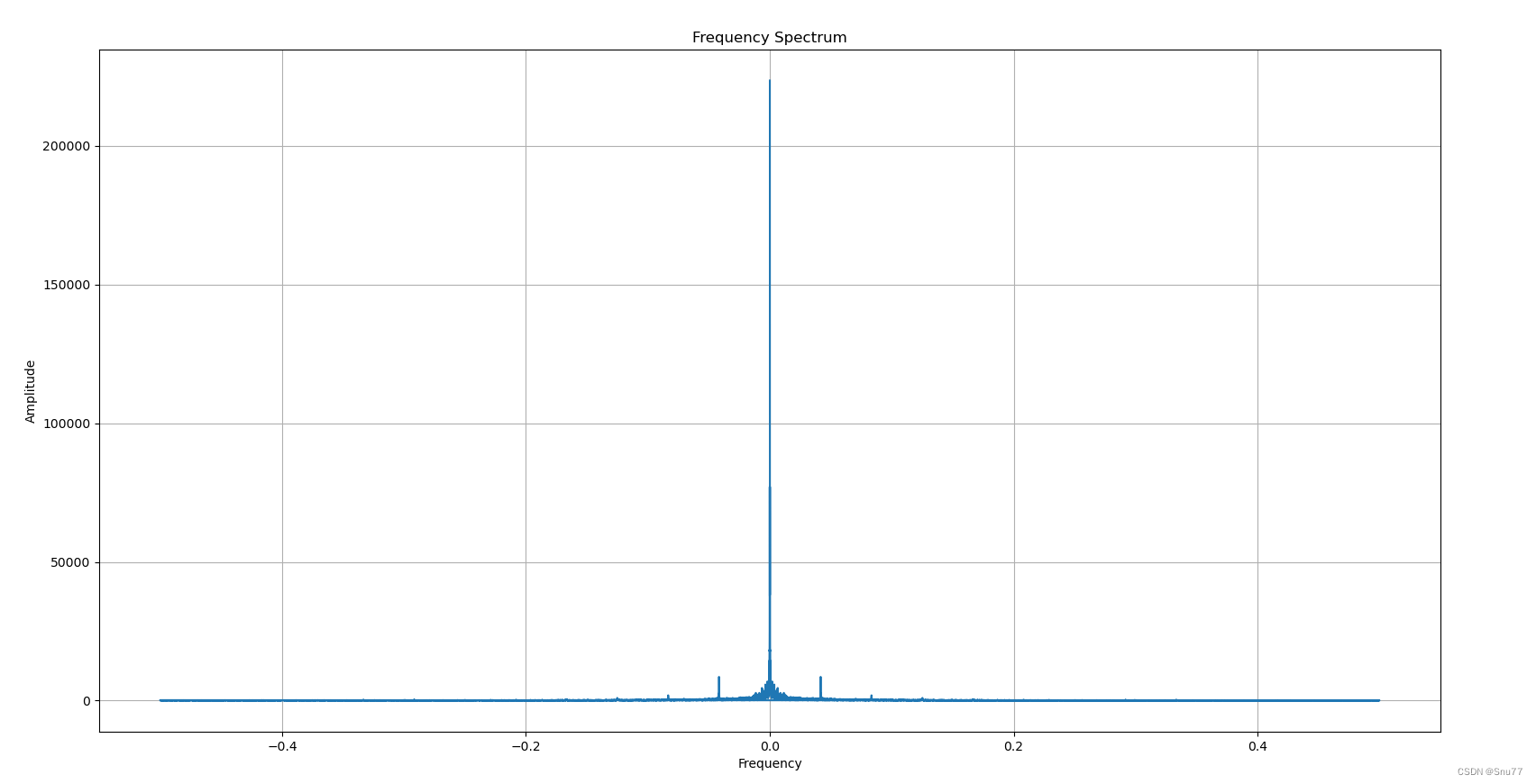
根据傅里叶变换的频谱图来分析数据的周期性,可以关注频谱图中峰值的位置和集中程度。周期性信号会在频谱图中表现为明显的峰值或集中的能量分布。
- 峰值位置:观察频谱图中的峰值,即具有较高幅度的频率成分。根据峰值的位置,你可以粗略估计数据中存在的周期或频率。例如,如果某个峰值出现在频率轴的某个点上,你可以认为数据具有该频率的周期性。
- 集中能量:周期性信号通常会导致能量在频率轴上集中、呈现较窄的频谱峰值。观察频谱图中的能量分布,如果能量较集中,表明数据中存在明显的频率成分,这可能意味着存在周期性信号。
- 多个峰值:如果频谱图中存在多个峰值,而且它们之间的距离相等或接近相等,那么这些峰值可能对应于数据中的周期性组件。通过测量峰值之间的距离,你可以估计数据中的周期。
相关性分析
皮尔逊和斯皮尔曼相关系数
def analyze_correlation(data1, data2):"""分析两列数据的相关性参数:- data1: 第一列数据,可以是一个一维数组或列表- data2: 第二列数据,可以是一个一维数组或列表"""# 将数据转换为NumPy数组data1 = np.array(data1)data2 = np.array(data2)# 计算Pearson相关系数pearson_corr, _ = stats.pearsonr(data1, data2)# 计算Spearman相关系数spearman_corr, _ = stats.spearmanr(data1, data2)# 打印相关系数print("Pearson相关系数: ", pearson_corr)print("Spearman相关系数: ", spearman_corr)上面的代码用于求解两列数据的相关性系数,执行上面的代码,我们的控制台输出如下->
Pearson相关系数: 0.22000371687451462
Spearman相关系数: 0.19464597419325935
我们可以进行如下的分析 :
-
Pearson相关系数:0.22000371687451462,接近于0,表示两列数据之间的线性关系较弱。如果相关系数的绝对值接近于1,表示两列数据之间的线性关系较强,正相关系数表示正向线性关系,负相关系数表示负向线性关系。
-
Spearman相关系数:0.19464597419325935,接近于0,表示两列数据之间的等级关系较弱。Spearman相关系数是一种非参数的相关系数,用于衡量两个变量之间的等级关系,而不仅仅是线性关系。
上面提到了等级关系大家可能不太理解这里用一个例子帮大家理解一下->
等级关系是指在一组数据中,根据数值的大小对数据进行排序并赋予等级或顺序。在等级关系中,每个数据点根据其数值相对于其他数据点的大小,被分配一个等级或排名。
例如,考虑以下一组数据:[7, 3, 9, 2, 5]。在等级关系中,我们首先对数据进行排序:[2, 3, 5, 7, 9]。然后,我们根据数据在排序后的顺序中的位置,为每个数据点分配一个等级或排名:[4, 2, 5, 1, 3]。在这个例子中,数字2在排序后的数据中排名第1,数字3排名第2,以此类推。
等级关系可以用于描述数据之间的相对大小,而不考虑具体的数值差异。它对于处理非线性关系或不符合线性假设的数据非常有用。Spearman相关系数就是基于等级关系计算的,它衡量的是两个变量之间等级的相似程度,而不仅仅是数值的线性关系。
需要注意的是,等级关系并不是适用于所有类型的数据。例如,对于分类变量或离散变量,等级关系可能没有明确的含义。在使用等级关系进行分析时,要确保数据的类型和性质与等级关系的要求相匹配。
滞后性分析
自相关图和偏相关图
def plot_lag_analysis(data):"""绘制滞后性分析的ACF和PACF图参数:- data: 时间序列数据,可以是一个一维数组或列表"""# 将数据转换为NumPy数组data = np.array(data)# 绘制ACF图plt.figure(figsize=(12, 4))ax1 = plt.subplot(121)plot_acf(data, ax=ax1)ax1.set_title('Autocorrelation Function (ACF)')# 绘制PACF图ax2 = plt.subplot(122)plot_pacf(data, ax=ax2)ax2.set_title('Partial Autocorrelation Function (PACF)')# 显示图形plt.tight_layout()plt.show()
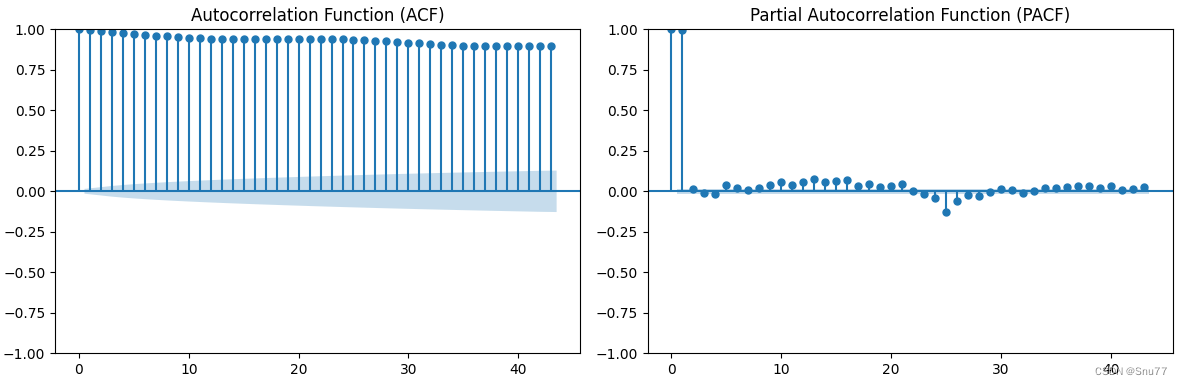
自相关函数(ACF):ACF测量一个变量与其在不同滞后时间点上的过去值之间的相关性。它可以帮助我们确定在给定时间点的观测值与之前的观测值之间的相关程度,这个前面已经讲过了。
偏自相关函数(PACF):PACF测量一个变量与另一个变量在给定滞后时间点上的相关性,同时消除了中间滞后时间点的影响。它可以帮助我们确定在考虑其他滞后期间的影响后,两个变量之间的直接关系。
这里在详细讲讲PACF图如何看->
在 PACF 图中,横坐标表示滞后阶数,纵坐标表示对应的偏相关系数。每个垂直线或标记表示一个滞后阶数的偏相关系数,而其他滞后阶数的影响已经被控制住。
通过观察 PACF 图,你可以得出以下结论:
如果 PACF 图上的滞后阶数的偏相关系数在垂直线之外都接近于零,而在垂直线上有一个显著的峰值,表明该滞后阶数对时间序列具有重要的影响,可能是一个合适的 AR 模型的滞后阶数。
如果 PACF 图上的滞后阶数的偏相关系数都接近于零,没有显示出显著的峰值,表明时间序列不需要考虑该滞后阶数,可以考虑其他模型。
如果 PACF 图上的滞后阶数的偏相关系数在多个滞后阶数上都有显著的峰值,可能存在多个合适的滞后阶数,需要进一步分析和选择。
趋势性分析
线性回归模型检测趋势性
def calculate_trend(data1,data2):# 创建 DataFrame# 提取自变量和因变量x = np.array(data1).reshape(-1, 1)y = np.array(data2).reshape(-1, 1)# 使用线性回归模型拟合数据model = LinearRegression()model.fit(x, y)# 提取斜率和截距slope = model.coef_[0]intercept = model.intercept_# 返回趋势性分析结果result = {'slope': slope,'intercept': intercept,}print(result)运行以上代码我们输出如下结果->
![]()
其中slope为斜率、intercept为截距,我们可以进行如下的分析->
- 如果斜率明显为正且截距为正,表示数据呈现明显的上升趋势,且存在一个正的基准水平。
- 如果斜率明显为负且截距为负,表示数据呈现明显的下降趋势,且存在一个负的基准水平。
- 如果斜率接近零且截距接近零,表示数据呈现平稳趋势,波动在零附近。
离群点分析
箱线图检测离群点
import matplotlib.pyplot as pltdef detect_outliers(data):# 绘制箱线图plt.boxplot(data)# 计算上下须范围q1, q3 = np.percentile(data, [25, 75])iqr = q3 - q1upper_threshold = q3 + 1.5 * iqrlower_threshold = q1 - 1.5 * iqr# 标记离群点outliers = [x for x in data if x > upper_threshold or x < lower_threshold]plt.plot(range(1, len(outliers) + 1), outliers, 'ro', label='Outliers')# 显示图例和标签plt.legend()plt.xlabel('Data')plt.ylabel('Values')plt.title('Box Plot with Outliers')# 显示箱线图plt.show()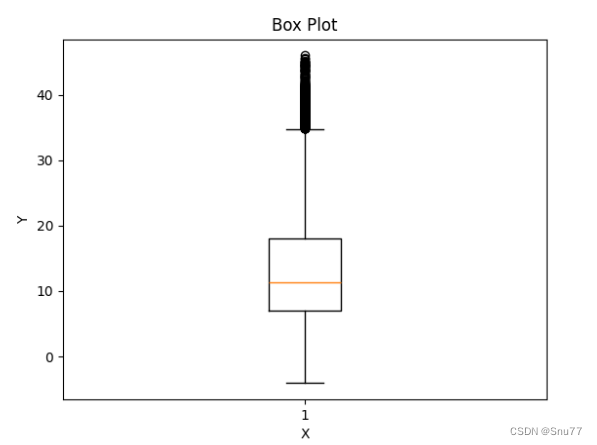
箱线图是传统的检测离群点的方法,其超过的它的箱须都称之为利群点,因为数据集表较大,可能离群点很多,看着不太直观,绘画箱线图的方法有很多,Excel都可以画大家不一定使用上面的方法。
Z分数(Z-score)
def zscore_detect_outlier(data, threshold):q1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1lower_threshold = q1 - threshold * iqrupper_threshold = q3 + threshold * iqrfor i in range(len(data)):if data[i] < lower_threshold or data[i] > upper_threshold:print(i, data[i])
我推荐用这种方法来检测离群点,因为检测出来以后我们可以直接对这些离群点进行处理,可以用平均值、最大值、最小值代替都可以。
运行以上代码输出如下->
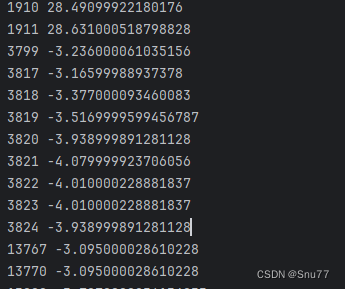
可以看到将我们的离群点全部打印出来了同时还有对应的索引,所以就很方便我们的处理。
执行代码
最后吧执行代码发给大家。
if __name__ == '__main__':# 读取数据框(DataFrame)df = pd.read_csv('ETTh1.csv') # 替换为您的数据文件路径# 提取某一列数据并转化为时间序列数据column_data = df['OT']column_data2 = df['MULL']# 调用方法acfDataPlot(column_data)FourierDataPlot(column_data)plot_boxplot(column_data)calculate_trend(column_data,column_data2)detect_outliers(column_data)zscore_detect_outlier(column_data,0.9)analyze_correlation(data1=column_data,data2=column_data2)总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解。
时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
时间序列预测模型实战案例(七)(TPA-LSTM)结合TPA注意力机制的LSTM实现多元预测
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析
时间序列预测模型实战案例(五)基于双向LSTM横向搭配单向LSTM进行回归问题解决
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!
最后希望大家工作顺利学业有成!