作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者!
个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客
当前专栏:Netty应用专栏_Aomsir的博客-CSDN博客
文章目录
- 参考文献
- 前言
- ByteBuffer组织结构
- ByteBuffer的获取方式
- ByteBuffer核心结构
- 结构图例演示
- 1、Buffer初创建
- 2、Buffer写入部分数据后
- 3、调用flip读方法
- 4、调用clear写方法
- 5、调用compact方法
- 6、代码演示
- Buffer有关核心API
- 写数据进Buffer
- 从Buffer读数据
- Channel#write()方法
- Buffer#rewind()方法
- Buffer#mark()&reset()方法
- 字符串操作
- 字符串存储到Buffer中
- 总结
参考文献
- 孙哥suns说Netty
- Netty官方文档
前言
在上一篇文章中,简单介绍了Buffer是什么,怎么获取Buffer,如何使用Buffer的读写操作等,对于我们NIO的两个核心组件:Channel和Buffer,更为重要的是Buffer,Channel只是建立通道的一个管道,Buffer是实际用来存储数据的。
ByteBuffer组织结构
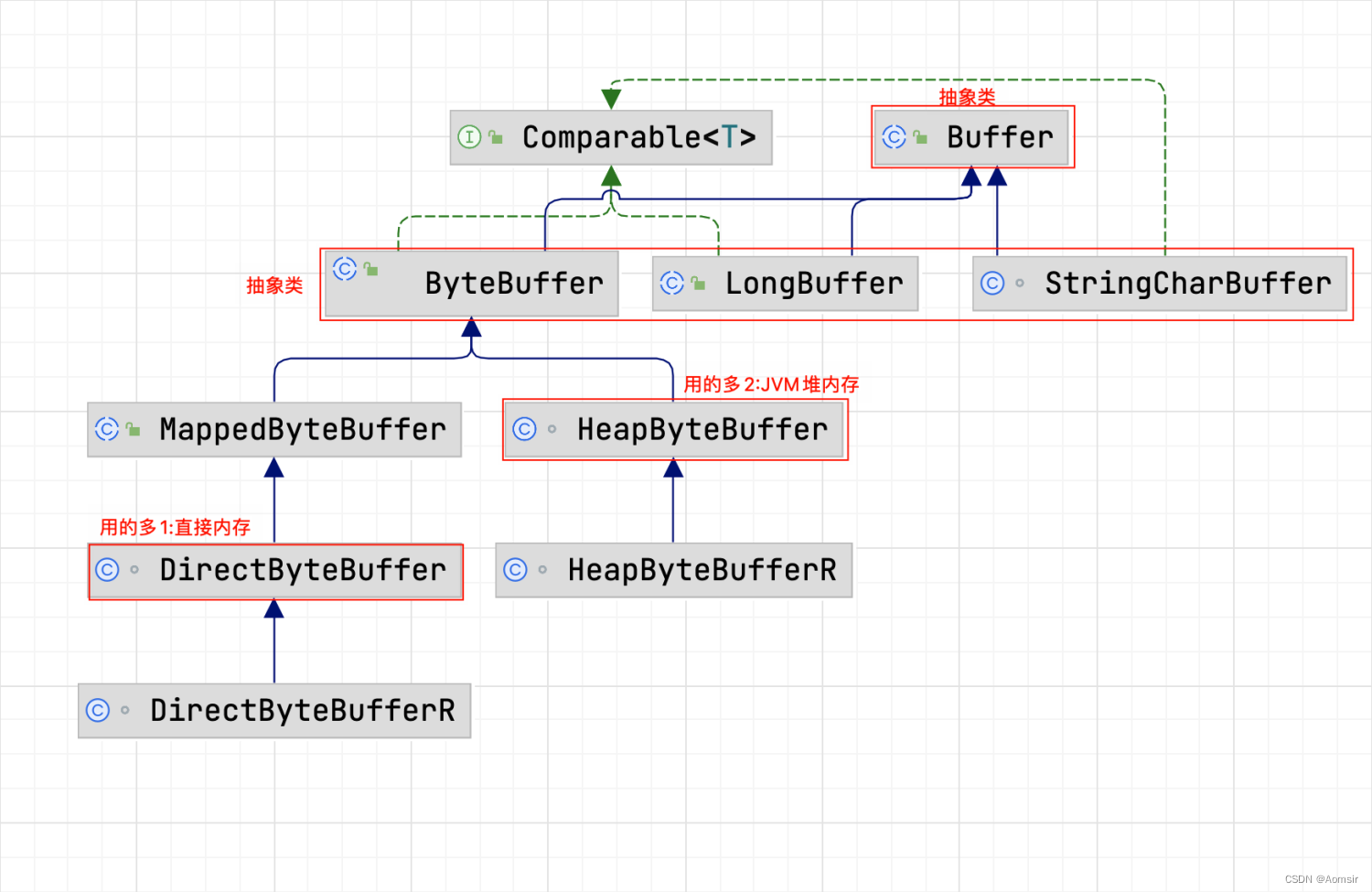
Buffer是一个抽象类,它有多个抽象子类,包括ByteBuffer、LongBuffer、StringCharBuffer等。在这些子类中,我们主要关注ByteBuffer,这是其中一个具体实现的抽象类。ByteBuffer具有两个主要的继承类:MappedByteBuffer和HeapByteBuffer。
MappedByteBuffer类下有一个继承类,名为DirectByteBuffer,代表直接内存,即操作系统内存。而HeapByteBuffer则代表JVM的堆内存。两者之间的区别在于,JVM堆内存上的读写操作效率较低,受垃圾回收的影响,而操作系统的直接内存允许高效的读写操作,但用完不对直接内存进行析构可能会造成内存泄漏。
ByteBuffer的获取方式
我们可以通过两种方式获取ByteBuffer。第一种方式是使用ByteBuffer的allocate方法创建,这种方式需要在创建时指定大小,一旦分配了大小后,无法动态扩容。第二种方式是使用Charset的encode方法
ByteBuffer.allocate(10);CharsetEncoder.encode()
ByteBuffer核心结构
- ByteBuff是一个
类似数组的结构,整个结构中包含有三个主要的状态- Capacity:即Buffer的容量,类似数组的size
- Position:即Buffer当前缓存的下标,在读取操作时记录读到了哪个位置;在写操作时记录写
- Limit:读写限制,在读操作时,设置了你能读多少字节的数据;在写操作时,设置你还能写多少字节的数据
所谓的读写模式,是程序相对Buffer的,本质上就是这几个状态的变化。主要有Position和Limit联合决定了Buffer的读写区域数据
注意:刚创建出来的Buffer默认为写模式,代表程序和Channel可以往里面写数据
结构图例演示
上面,我们通过文字方式详细介绍了Netty中ByteBuffer的核心结构。接下来,我将逐步使用图例来讲解这三个核心组件在读写操作时的变化
1、Buffer初创建
ByteBuffer在初始创建时默认为写模式,允许程序和Channel向其中写入数据。此时,Position指向Buffer的最开头,Capacity指向最末尾,而Limit也指向最末尾。Position与Limit之间的这段区间表示了可用于写入数据的有效空间

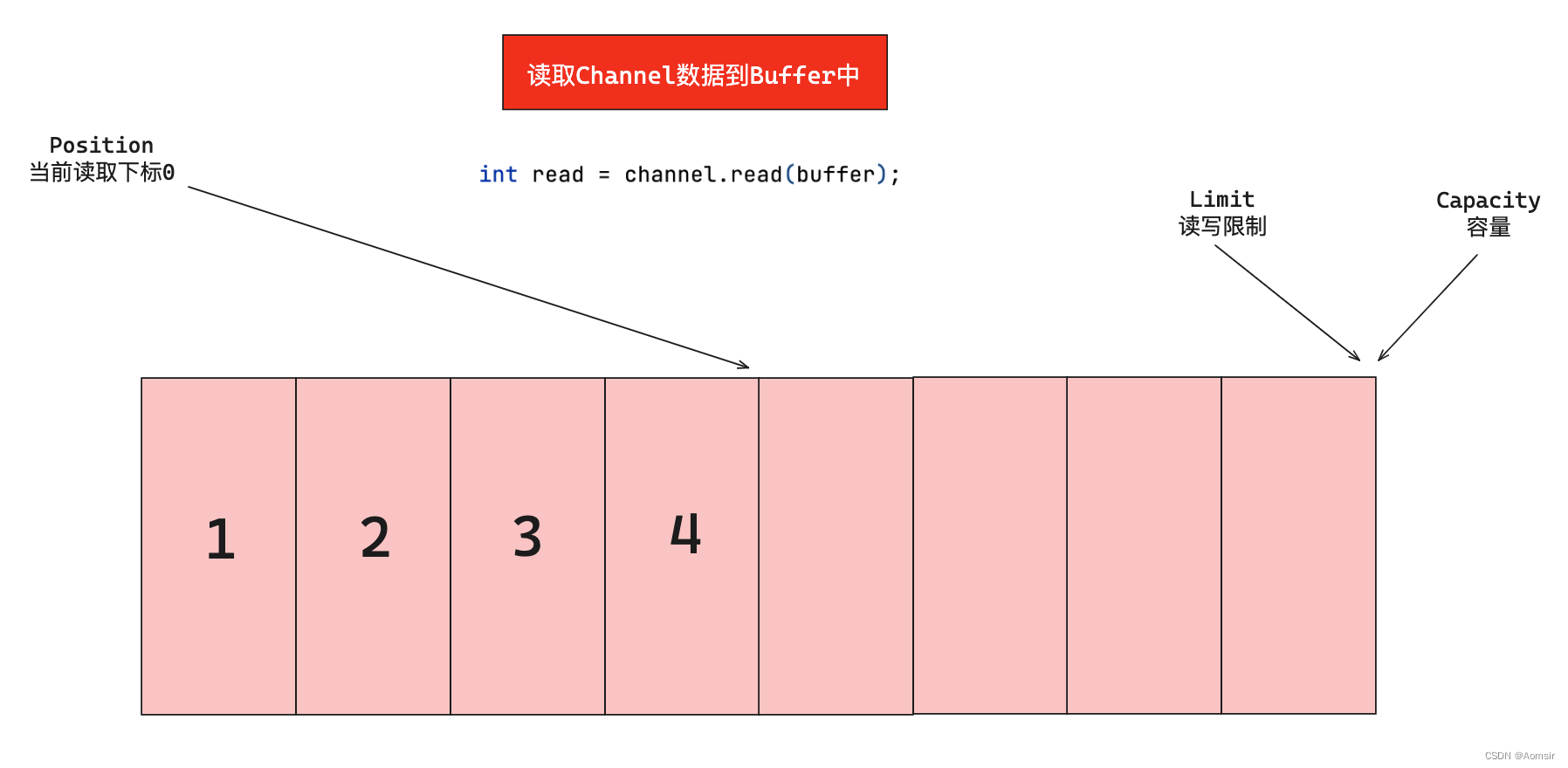
2、Buffer写入部分数据后
当我们通过程序或Channel向Buffer中写入部分数据后,如下图所示:Position指向最后一个数据的索引位置,同时Limit和Capacity都位于数据的最后位置
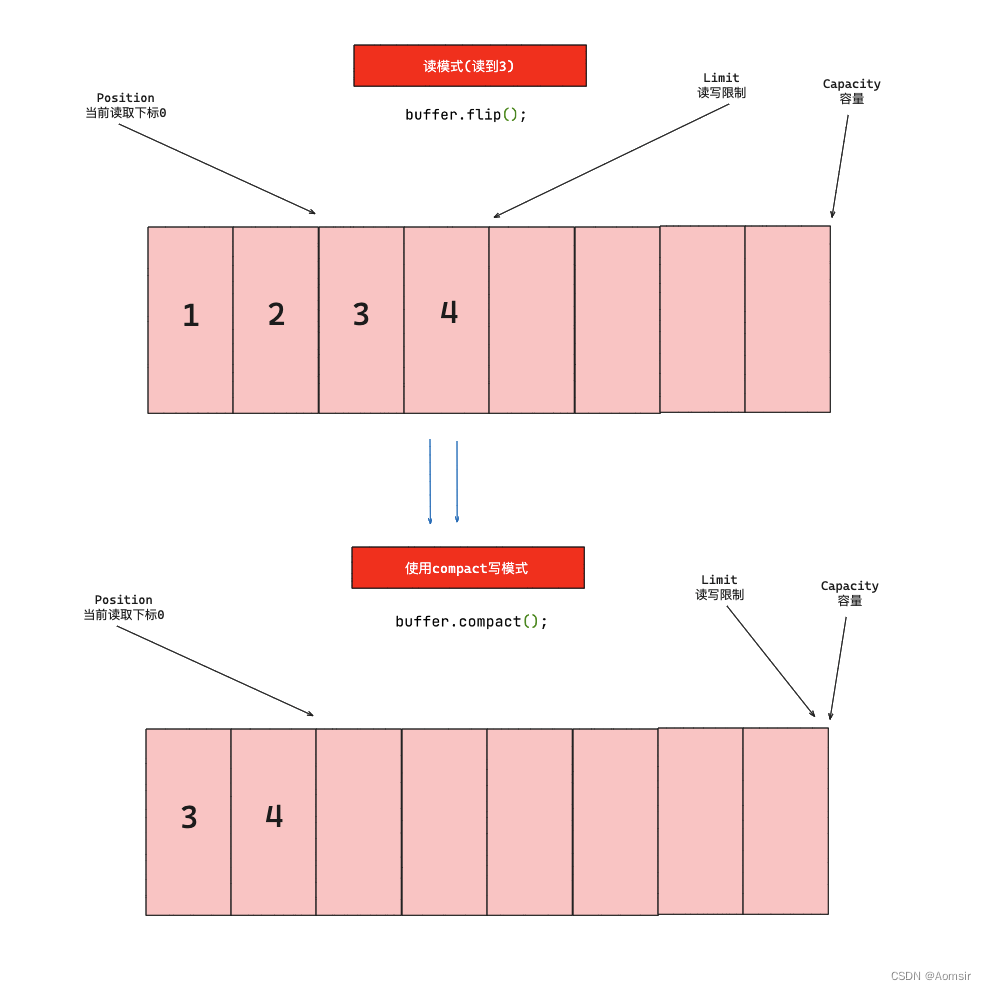
3、调用flip读方法
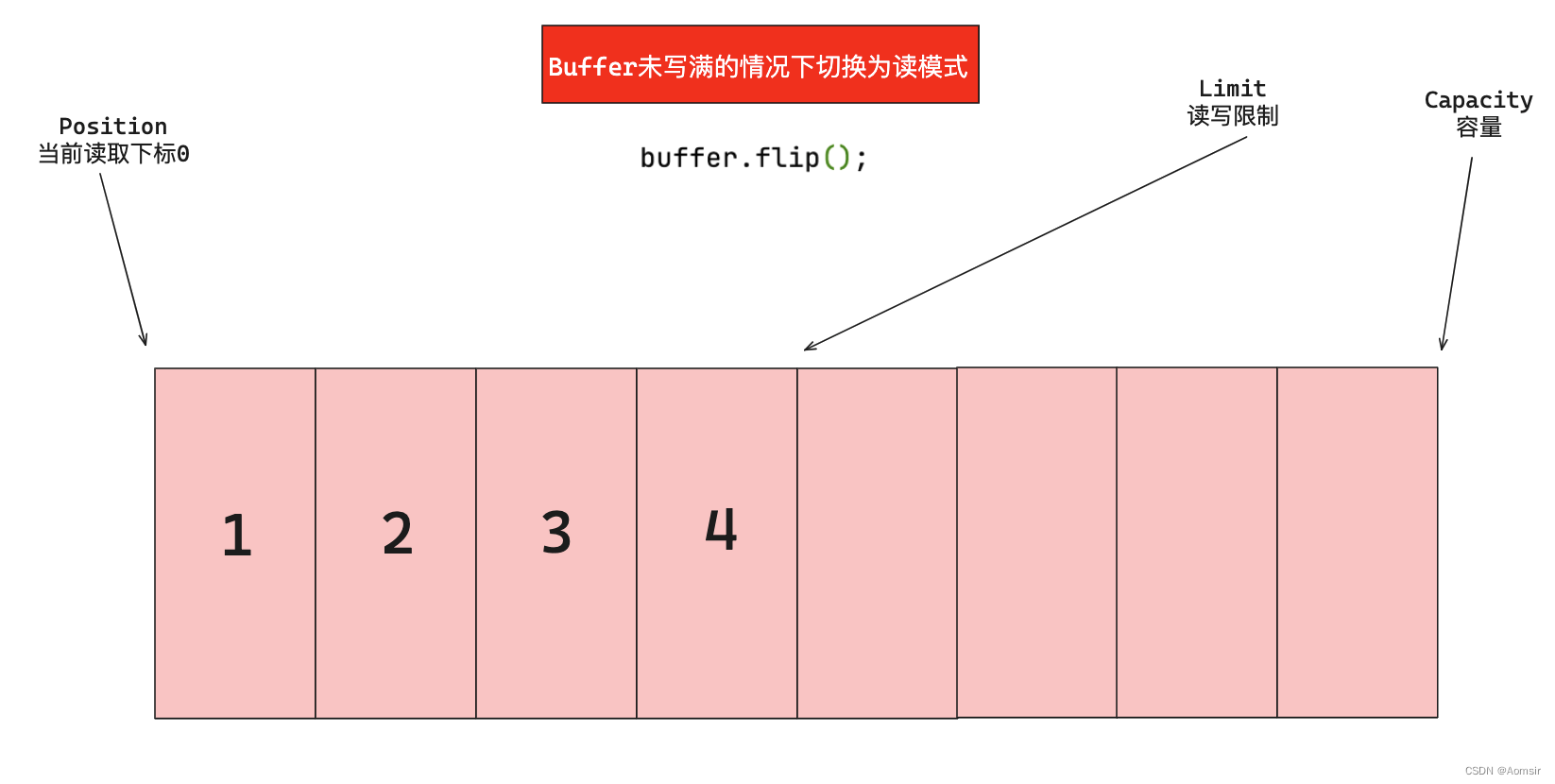
在之前的图中,我们往Buffer中写入了四条数据:1、2、3和4。此时,当我们调用flip方法以切换到读模式时,Position会指向Buffer的最开头,而Limit会指向写模式下Position的位置。接下来,我们可以从Buffer中读取数据了。每读取一个数据,Position就会向后移动一个位置,直到与Limit重合
4、调用clear写方法
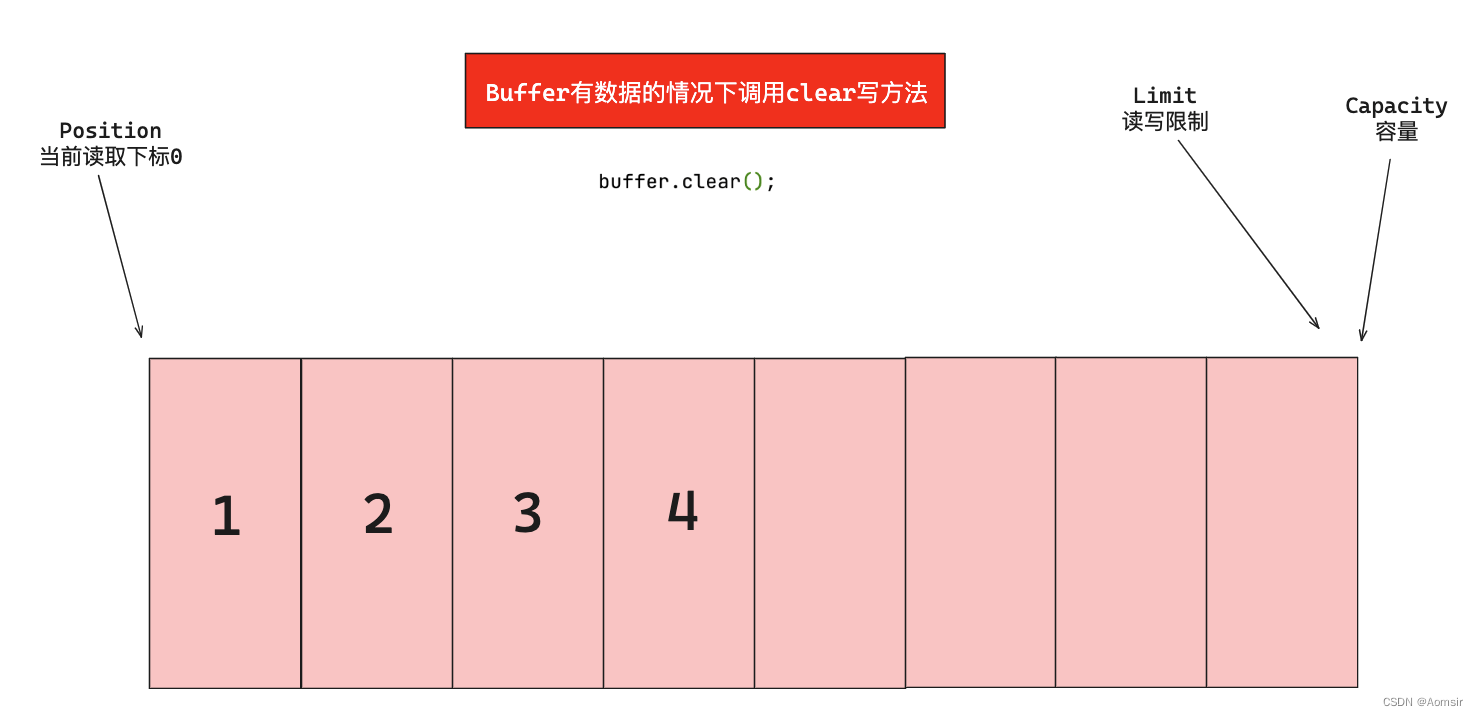
当在读模式下从Buffer中读取数据,但还未读取完全就需要切换为写模式时,如果直接使用clear方法,会导致三个指针恢复到初始状态,且未被读取的数据会被直接覆盖。因此,一般情况下我们避免使用clear方法来切换模式,以免丢失未读完的数据
5、调用compact方法
另一个用于Buffer写模式的方法是compact。当我们从Buffer中读取数据时,如果还未读取到Limit的位置就需要切换为写模式。如果我们使用clear方法切换到写模式,那么Position与Limit之间未被读取的数据将全部丢失,这可能不符合我们的开发需求。因此,我们可以使用compact方法。该方法会将Position与Limit之间未被读取的数据压缩到Buffer的最开始,然后将Position指向未被读取数据的最后索引位置,同时将Limit指向Capacity,以便后续写入操作。
6、代码演示
public class TestNIO4 {@Testpublic void testState1() {ByteBuffer buffer = ByteBuffer.allocate(10);System.out.println("buffer.capacity() = " + buffer.capacity());System.out.println("buffer.position() = " + buffer.position());System.out.println("buffer.limit() = " + buffer.limit());}@Testpublic void testState2() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});System.out.println("buffer.capacity() = " + buffer.capacity());System.out.println("buffer.position() = " + buffer.position());System.out.println("buffer.limit() = " + buffer.limit());}@Testpublic void testState3() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});buffer.flip(); // 切换读模式System.out.println("buffer.capacity() = " + buffer.capacity());System.out.println("buffer.position() = " + buffer.position());System.out.println("buffer.limit() = " + buffer.limit());}@Testpublic void testState4() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});buffer.clear(); // 切换读模式System.out.println("buffer.capacity() = " + buffer.capacity());System.out.println("buffer.position() = " + buffer.position());System.out.println("buffer.limit() = " + buffer.limit());}@Testpublic void testState5() {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});buffer.flip(); // 切换写模式System.out.println("buffer.get() = " + (char) buffer.get()); // aSystem.out.println("buffer.get() = " + (char) buffer.get()); // bSystem.out.println("buffer.capacity() = " + buffer.capacity()); // 10System.out.println("buffer.position() = " + buffer.position()); // 2System.out.println("buffer.limit() = " + buffer.limit()); // 4System.out.println("----------------------------------");buffer.compact(); // 切换写模式System.out.println("buffer.capacity() = " + buffer.capacity()); // 10System.out.println("buffer.position() = " + buffer.position()); // 2System.out.println("buffer.limit() = " + buffer.limit()); // 10buffer.flip();System.out.println("buffer.get() = " + (char) buffer.get()); // c}
}
Buffer有关核心API
写数据进Buffer
- Channel的read方法:
channel.read(buffer) - Buffer的put方法
buffer.put(byte)buffer.put(byte[])
从Buffer读数据
- Buffer的get方法:每调用一次都会影响Position的位置
- Buffer的get(i)方法,用于获取特定Position上的数据,但是不会对Position产生影响
- 如下还有三个文件
Channel#write()方法
在上一篇文章中,我们演示了如何使用FileInputStream和FileOutputStream流来执行文件读取和写入操作,通过输入流从文件中获取数据流,并通过输出流将程序中的字节写回文件。然而,在NIO中,我们使用Channel来进行文件操作,而Channel是无方向性的。这意味着我们可以使用Channel的write()方法,从Buffer中读取数据并将其写入文件中。
public class TestNIO11 {public static void main(String[] args) throws Exception{// 1.获取channelFileChannel channel = new FileOutputStream("data1.txt").getChannel();// 2.获取buffer并填入数据String data = "Aomsir";ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(data.getBytes());// 3.读取buffer中的内容并写入channelchannel.write(buffer);}
}
Buffer#rewind()方法
当我们从ByteBuffer中读取数据时,Position指针会逐步向前移动。但如果我们希望重新读取已读取的数据,可以使用rewind方法。该方法将Position指针重置到Buffer的开头,允许我们重新读取数据,如下是rewind的代码和我们的测试案例。

public class TestNIO5 {public static void main(String[] args) {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});buffer.flip();while (buffer.hasRemaining()) {System.out.println("buffer.get() = " + (char) buffer.get());}System.out.println("-----------------------------");buffer.rewind(); // 重新获取数据(因为读完以后数据没有删除,只是position和limit重合)while (buffer.hasRemaining()) {System.out.println("buffer.get() = " + (char) buffer.get());}}
}
Buffer#mark()&reset()方法
除了rewind()方法可以将position置为最初状态,如果我们想要重复读取某一个区间的内容,Buffer还提供了两个有用的方法:mark()和reset()。mark()方法可以帮助我们记住当前position的位置,而reset()方法则允许我们后续回退到position的位置,以便重复读取特定区间的数据。
public class TestNIO6 {public static void main(String[] args) {ByteBuffer buffer = ByteBuffer.allocate(10);buffer.put(new byte[]{'a','b','c','d'});buffer.flip();System.out.println("buffer.get() = " + (char) buffer.get()); // aSystem.out.println("buffer.get() = " + (char) buffer.get()); // bbuffer.mark(); // 打标记System.out.println("buffer.get() = " + (char) buffer.get()); // cSystem.out.println("buffer.get() = " + (char) buffer.get()); // dbuffer.reset(); // 跳回标记点System.out.println("buffer.get() = " + (char) buffer.get()); // cSystem.out.println("buffer.get() = " + (char) buffer.get()); // d}
}
字符串操作
字符串存储到Buffer中
将字符串存入ByteBuffer是一项相对简单的任务,可以使用buffer.put(“Aomsir”.getBytes())。然而,这种方式受当前Java文件的字符编码类型影响。如果当前Java文件使用UTF-8字符集,但我们要存入的字符串包含汉字,可能在读取时会出现问题。因此,通常会选择另一种方式创建ByteBuffer,即使用Charset的encode()方法,这种方法允许我们明确指定字符编码集。需要注意的是,encode方法会自动调用flip读方法,不像之前的ByteBuffer.allocate()方法默认是写模式,所以这里无需显式调用flip方法,否则limit和position都会被重置为0。
public class TestNIO8 {public static void main(String[] args) {// 使用指定字符集直接创建Buffer并填入数据ByteBuffer buffer = Charset.forName("UTF-8").encode("aomsir");// 不用切换为读模式,因为上面的encode方法已经调用了,再调用一次就会导致position=0,limit=0// buffer.flip();while (buffer.hasRemaining()) {System.out.println("buffer.get() = " + (char) buffer.get());}buffer.clear();}
}
总结
ByteBuffer是整个NIO体系中的核心组件,今天我们花了一篇文章的时间来深入学习它的结构、读写模式以及常见API等内容。这将为我们未来学习Netty奠定坚实的基础