【大家好,我是爱干饭的猿,本文重点介绍python高级篇的事件循环,task取消和协程嵌套、call_soon、call_later、call_at、 call_soon_threadsafe、asyncio模拟http请求、asyncio同步和通信、aiohttp实现高并发实践。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【python高级】多线程、多进程和线程池编程》
1. 事件循环
- 包含各种特定系统实现的模块化事件循环
- 传输和协议抽象
- 对TCP、UDP、SSL、子进程、延时调用以及其他的具体支持
- 模仿futures模块但适用于事件循环使用的Future类
- 基于yield from的协议和任务,可以让你用顺序的方式编写并发代码
- 必须使用一个将产生阻塞IO的调用时,有接口可以把这个事件转移到线程池
- 模仿threading模块中的同步原语、可以用在单线程内的协程之间
1.1 开始一个协程
# 事件循环回调(驱动生成器)+epollIO多路复用)
# asyncio是python用于解决异io编程的一整套解决方案
# tornado, gevent, twisted (scrapy.django channels)
# tornado(实现web服务器) django+flask(uwsgi gunicorn+nginx)
# tornado可以直接部署,nginx+tornadoimport asyncio
import timeasync def get_html(url):print("start get url")# time.sleep(2) 执行此代码是顺序执行await asyncio.sleep(2)print("end get url")if __name__ == '__main__':loop = asyncio.get_event_loop()tasks = [get_html("www.baidu.com") for i in range(10)]start_time = time.time()loop.run_until_complete(asyncio.wait(tasks))end_time = time.time()print("耗时:{}".format(end_time-start_time))
1.2 获取协程返回值和callback逻辑
import asyncio
import time
from functools import partial# 获取协程返回值和callback逻辑
async def get_html(url):print("start get url")await asyncio.sleep(2)return "body"def callback(url, future):print("url:{}".format(url))print("send email to me")if __name__ == '__main__':start_time = time.time()loop = asyncio.get_event_loop()# 方式1# get_future = asyncio.ensure_future(get_html("www.baidu.com"))# loop.run_until_complete(get_future)# print(get_future.result())# print("耗时:{}".format(time.time()-start_time))# 方式2# task = loop.create_task(get_html("www.baidu.com"))# loop.run_until_complete(task)# print(task.result())# print("耗时:{}".format(time.time()-start_time))# 加入callbacktask = loop.create_task(get_html("www.baidu.com"))# task.add_done_callback(callback) callback未传入参数task.add_done_callback(partial(callback, "www.baidu.com"))loop.run_until_complete(task)print(task.result())print("耗时:{}".format(time.time()-start_time))
1.3 await 和 gather
import asyncio
import timeasync def get_html(url):print("start get url")await asyncio.sleep(2)print("end get url")if __name__ == '__main__':loop = asyncio.get_event_loop()start_time = time.time()# gather和wait的区别# gather更加high-leveL# gather可以进行分组# # 方法1# group1 = [get_html("www.baidu.com") for i in range(2)]# group2 = [get_html("www.baidu.com") for i in range(2)]# loop.run_until_complete(asyncio.gather(*group1, *group2))# 方法2group1 = [get_html("www.baidu.com") for i in range(2)]group2 = [get_html("www.baidu.com") for i in range(2)]group1 = asyncio.gather(*group1)group2 = asyncio.gather(*group2)loop.run_until_complete(asyncio.gather(group1, group2))print("耗时:{}".format(time.time()-start_time))
2. task取消和协程嵌套
2.1 task 取消
import asyncio
import timeasync def get_html(sleep_time):print("waiting")await asyncio.sleep(sleep_time)print("done after {}s".format(sleep_time))if __name__ == '__main__':task1 = get_html(2)task2 = get_html(3)task3 = get_html(3)tasks = [task1, task2, task3]loop = asyncio.get_event_loop()try:loop.run_until_complete(asyncio.wait(tasks))except KeyboardInterrupt as e:# 此报错可以在Linux中运行时按 ctrl+c 复现all_tasks = asyncio.all_tasks()for task in all_tasks:print("task cancel")print(task.cancel())loop.stop()loop.run_forever()finally:loop.close()2.2 协程嵌套
import asyncioasync def compute(x,y):print("Compute %s + %s ..." % (x, y))await asyncio.sleep(1.0)return x + yasync def print_sum(x, y):result = await compute(x, y)print("%s + %s = %s" % (x, y, result))loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()子协程调用原理:
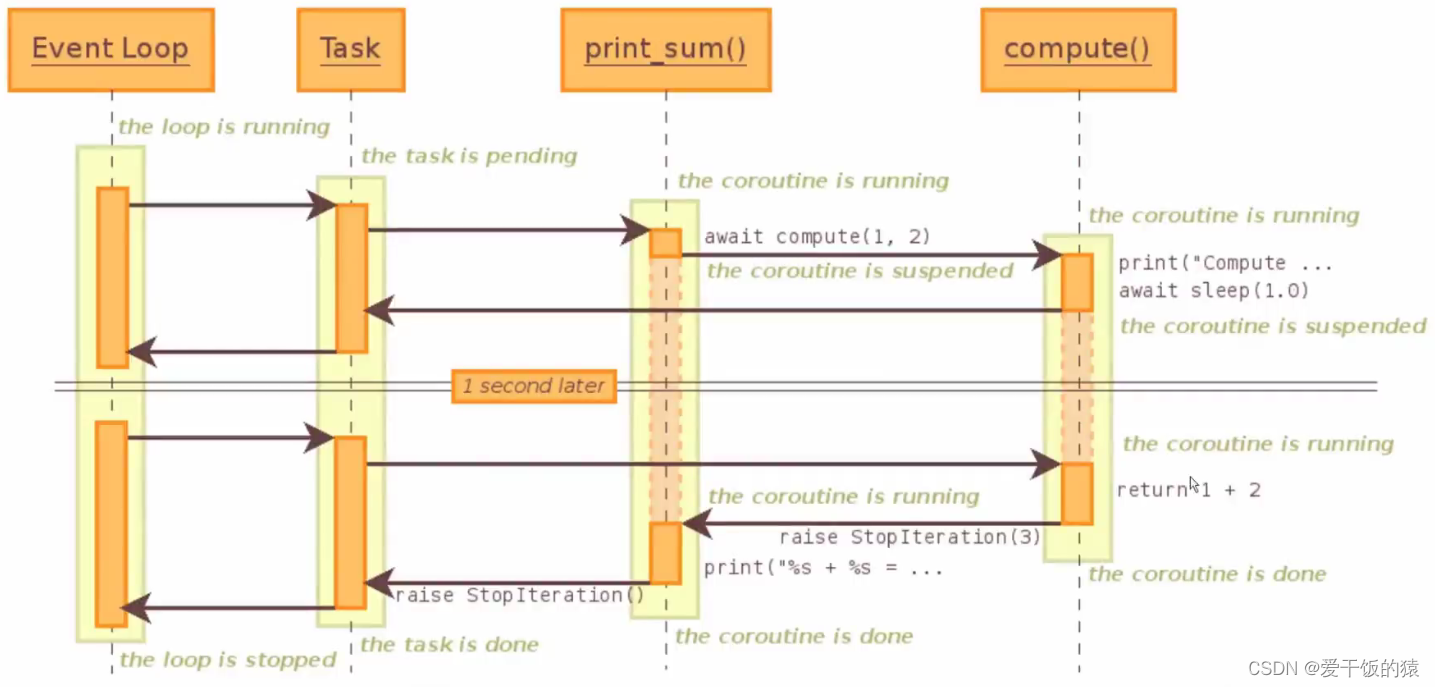
3. call_soon、call_later、call_at、 call_soon_threadsafe
import asynciodef callback(sleep_times):print("sleep {} success".format(sleep_times))def stoploop(loop):loop.stop()if __name__ == '__main__':loop = asyncio.get_event_loop()# 1. call_soon立即执行# loop.call_soon(callback, 2)# loop.call_soon(callback, 1)# 2. call_later 后于call_soon执行,多个call_later按照delay顺序执行# loop.call_later(2, callback, 2)# loop.call_later(1, callback, 1)# loop.call_later(3, callback, 3)# 3. call_at 指定时间执行# cur_time = loop.time()# loop.call_at(cur_time+2, callback, 2)# loop.call_at(cur_time+1, callback, 1)# loop.call_at(cur_time+3, callback, 3)# 4. call_soon_threadsafe和call_soon 使用方法一致,但是是线程安全的loop.call_soon_threadsafe(callback, 1)loop.call_soon(stoploop, loop)loop.run_forever()
4. ThreadPoolExecutor + asyncio
import asyncio
from concurrent.futures import ThreadPoolExecutordef get_url(url):passif __name__ == "__main__ ":import timestart_time = time.time()loop = asyncio.get_event_loop()executor = ThreadPoolExecutor()tasks = []for url in range(20):url = "http://shop.dd.com/goods/{}/".format(url)task = loop.run_in_executor(executor, get_url, url)tasks.append(task)loop.run_until_complete(asyncio.wait(tasks))print("last time:{".format(time.time() - start_time))5. asyncio模拟http请求
#requests -> urlib ->socket
import socket
import asyncio
from urllib.parse import urlparseasync def get_url(url ):# 通过socket请求htmLurl = urlparse(url)host = url.netlocpath = url.pathif path == "":path = "/"# 建立socket连接# client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 建立socket连接reader, writer = await asyncio.open_connection(host, 80)writer.write("GET {HTTP/1.1r\nHost:{}r\nConnection:close\r\n\r\n".format(path, host).encode( "utf-8"))all_lines = []async for raw_line in reader:data = raw_line.decode("utf8")all_lines.append(data)html = "ln".join(all_lines)return htmlif __name__ == '__main__':import timestart_time = time.time()loop = asyncio.get_event_loop()tasks = []for url in range(20):url = "http: // shop.projectsedu.com/goods/{0}/".format(url)tasks.append(asyncio.ensure_future(get_url(url)))loop.run_until_complete(asyncio.wait(tasks))print('last time:{}'.format(time.time()))6. asyncio同步和通信
import asyncio
from asyncio import Lock, Queueimport aiohttpcache = {}
lock = Lock()
# queue = Queue() 和 queue = [], 如果需要流量限制就需要使用Queue()async def get_stuff(url) :async with lock:if url in cache:return cache[url]stuff = await aiohttp.request('GET', url)cache[url] = stuffreturn stuffasync def parse_stuff():stuff = await get_stuff()#do some parsingasync def use_stuff():stuff = await get_stuff()#use stuff to do something interesting7. aiohttp实现高并发实践
import re
import asyncio
import aiohttp
import aiomysql
from pyquery import PyQuerystart_url = 'https://developer.aliyun.com/article/698731'waitting_urls = []
seen_urls = set()
stopping = Falseasync def fetch(url, session):async with session.get(url) as response:if response.status != 200:return Nonetry:return await response.text(encoding='ISO-8859-1')except UnicodeDecodeError:return await response.read()async def init_urls(url, session):html = await fetch(url, session)seen_urls.add(url)extract_urls(html)def extract_urls(html):if html is None or not isinstance(html, str):returnif not html.strip(): # 如果html内容为空或者只包含空白字符returntry:urls = []pq = PyQuery(html)# 在这里继续处理pq对象pq = PyQuery(html)for link in pq.items("a"):url = link.attr("href")if url and url.startswith("http") and url not in seen_urls:urls.append(url)waitting_urls.append(url)return urlsexcept Exception as e:print(f"Failed to parse HTML: {e}")async def article_handler(url, session, pool):# 获取文章详情并解析入库html = await fetch(url, session)seen_urls.add(url)extract_urls(html)pq = PyQuery(html)title = pq("article-title").text()if len(title) == 0:print("No valid title found for article: {}".format(url))else:async with pool.acquire() as conn:async with conn.cursor() as cur:await cur.execute("SELECT 42;")insert_sql = "insert into article_test(title) values('{}')".format(title)await cur.execute(insert_sql)async def consumer(pool):async with aiohttp.ClientSession() as session:while not stopping:if len(waitting_urls) == 0:await asyncio.sleep(1)continueurl = waitting_urls.pop()print("start get url: {}".format(url))if re.match('https://world.taobao.com', url):continueif re.match('http://.*?developer.aliyun.com/article/\d+/', url):if url not in seen_urls:asyncio.ensure_future(article_handler(url, session, pool))await asyncio.sleep(2) # 适当的等待时间else:if url not in seen_urls:await init_urls(url, session)async def main(loop):# 等待MySQL建立连接pool = await aiomysql.create_pool(host='127.0.0.1', port=3306,user='root', password='*****',db='aiomysql_test', loop=loop,charset='utf8', autocommit=True)async with aiohttp.ClientSession() as session:html = await fetch(start_url, session)seen_urls.add(start_url)extract_urls(html)asyncio.ensure_future(consumer(pool))if __name__ == '__main__':loop = asyncio.get_event_loop()asyncio.ensure_future(main(loop))try:loop.run_forever()except KeyboardInterrupt:stopping = Trueloop.stop()






![[Mac软件]Adobe Media Encoder 2024 V24.0.2免激活版](https://img-blog.csdnimg.cn/a5c8e3eba92e407493ce50f0664b1ac3.png)