一、CIFAR-100数据集介绍
CIFAR-100(Canadian Institute for Advanced Research - 100 classes)是一个经典的图像分类数据集,用于计算机视觉领域的研究和算法测试。它是CIFAR-10数据集的扩展版本,包含了更多的类别,用于更具挑战性的任务。
CIFAR-100包含了100个不同的类别,每个类别都包含600张32x32像素的彩色图像。
这100个类别被划分为20个大类别,每个大类别包含5个小类别。这个层次结构使得数据集更加丰富,包含了各种各样的对象和场景。每张图像的大小是32x32像素,包含RGB三个通道。

用途: CIFAR-100常被用于评估图像分类算法的性能。由于图像分辨率相对较低,它在实际中可能不太适用于一些复杂的计算机视觉任务,但对于学术研究和算法开发而言是一个常见的基准数据集。
二、下载并加载CIFAR-100数据集
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision
import torchvision.transforms as transformsdef get_train_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_training = torchvision.datasets.CIFAR100(root='./data', train=True, download=True,transform=transform_train)cifar100_training_loader = DataLoader(cifar100_training, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_training_loaderdef get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_test = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform_test)cifar100_test_loader = DataLoader(cifar100_test, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_test_loader
这里我们采用的是torchvision下载CIFAR-100数据集并将其保存到指定的路径,定义这两个函数 get_train_loader 和 get_val_loader 分别用于获取训练集和验证集的数据加载器,并进行了预处理和增强的操作。
三、检测数据加载情况
博主曾经在这上面吃过很多的亏,一般我们遇到维度不匹配的情况,通常会认为是网络的问题,但我会告诉你也有可能是数据加载的部分,这种开源数据集还好,我们项目上用的是自制的数据集,它的图片可能真的就是有些问题,比如你明明是用PIL加载图片,按理来说应该就是三通道无疑才对,但事实是就是存在通道为1的情况。
所以,为了让我们具备严谨的工程能力,为将来自己的项目打下基础,哪怕是开源数据集,我们也要进行测试。
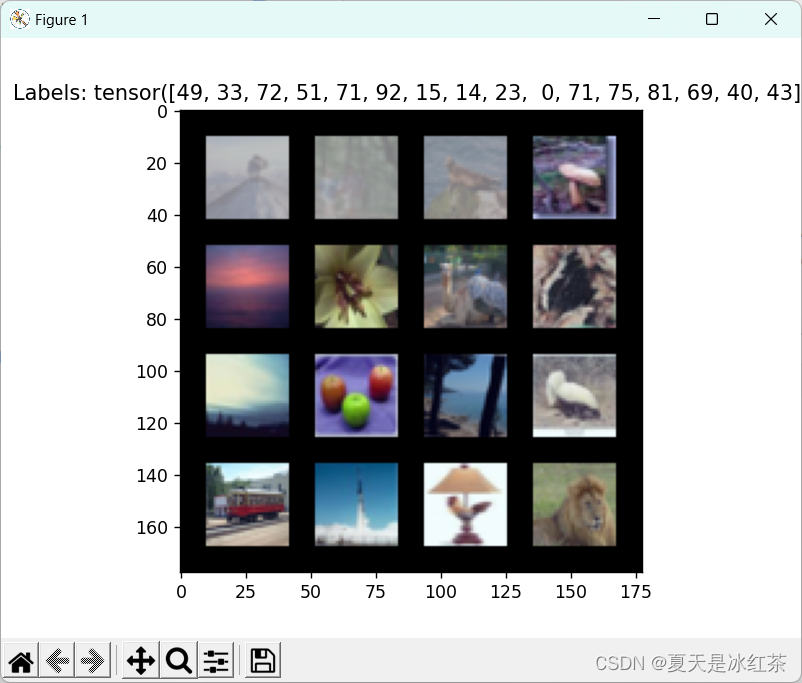
一般来说,主要看到就是它的维度是否是正确的,还有它是否能够正确的显示。
在上面我们进行预处理操作,所以应该先进行反归一化:
def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensor而要看如何正常的显示,我们当然不希望单张的显示,这样似乎太慢了,所以这里我们按照批量大小进行显示:
def show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, mean, std)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()测试代码:
if __name__=="__main__":import matplotlib.pyplot as pltfrom torchvision.utils import make_gridCIFAR100_TRAIN_MEAN = (0.5070751592371323, 0.48654887331495095, 0.4409178433670343)CIFAR100_TRAIN_STD = (0.2673342858792401, 0.2564384629170883, 0.27615047132568404)def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensormean = CIFAR100_TRAIN_MEANstd = CIFAR100_TRAIN_STDtest_loader = get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=False)def show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, mean, std)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()for images, labels in test_loader:show_batch(images, labels)# print(images.size(), labels)最后两行就是图片批量显示与维度检测的测试,这里最好是单独的测试,即两行中一行注释,一行正常运行。
四、自定义CIFAR-100的dataset类
dataset类的以下几个要点:
- dataset类需要继承import torch.utils.data.dataset。
- dataset的作用是将任意格式的数据,通过读取、预处理或数据增强后以tensor的形式输出。其中任意格式的数据指可能是以文件夹名作为类别的形式、或以txt文件存储图片地址的形式。而输出则指的是经过处理后的一个 batch的tensor格式数据和对应标签。
- dataset类需要重写的主要有三个函数要完成:__init__函数、__len__函数和__getitem__函数。
__init__(self, ...) 函数:初始化数据集。在这里,你通常会加载数据,设置转换(transformations)等。这个函数在数据集创建时调用。
__len__(self)函数:返回数据集的大小,即数据集中样本的数量。这个函数在调用len(dataset) 时调用。
__getitem__(self,index)函数:根据给定的索引返回数据集中的一个样本。这个函数允许你通过索引访问数据集中的单个样本,以便用于模型的训练和评估。
import os
import pickle
import numpy as npfrom torch.utils.data import Dataset,DataLoaderclass CIFAR100Dataset(Dataset):def __init__(self, path, transform=None, train=False):if train:sub_path = 'train'else:sub_path = 'test'with open(os.path.join(path, sub_path), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['fine_labels'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, label测试代码:
if __name__=="__main__":mean = CIFAR100_TRAIN_MEANstd = CIFAR100_TRAIN_STDtransform_train = transforms.Compose([transforms.ToPILImage(),transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])train_dataset = CIFAR100Dataset(path='./data/cifar-100-python', transform=transform_train)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)for images, labels in train_loader:show_batch(images, labels)# print(images.size(), labels)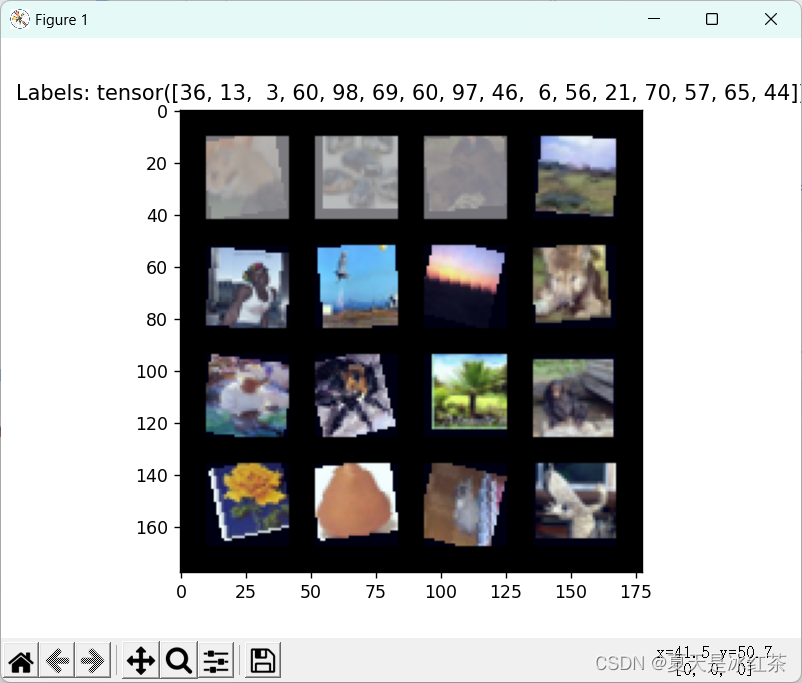
附录
本章节源码
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision.utils import make_grid
import os
import pickle
import numpy as npCIFAR100_TRAIN_MEAN = (0.5070751592371323, 0.48654887331495095, 0.4409178433670343)
CIFAR100_TRAIN_STD = (0.2673342858792401, 0.2564384629170883, 0.27615047132568404)__all__ = ["get_train_loader", "get_val_loader", "CIFAR100Dataset"]class CIFAR100Dataset(Dataset):def __init__(self, path, transform=None, train=False):if train:sub_path = 'train'else:sub_path = 'test'with open(os.path.join(path, sub_path), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['fine_labels'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, labelclass CIFAR100Test(Dataset):def __init__(self, path, transform=None):with open(os.path.join(path, 'test'), 'rb') as cifar100:self.data = pickle.load(cifar100, encoding='bytes')self.transform = transformdef __len__(self):return len(self.data['data'.encode()])def __getitem__(self, index):label = self.data['fine_labels'.encode()][index]r = self.data['data'.encode()][index, :1024].reshape(32, 32)g = self.data['data'.encode()][index, 1024:2048].reshape(32, 32)b = self.data['data'.encode()][index, 2048:].reshape(32, 32)image = np.dstack((r, g, b))if self.transform:image = self.transform(image)return image, labeldef get_train_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_training = torchvision.datasets.CIFAR100(root='./data', train=True, download=True,transform=transform_train)cifar100_training_loader = DataLoader(cifar100_training, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_training_loaderdef get_val_loader(mean, std, batch_size=16, num_workers=2, shuffle=True):transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_test = torchvision.datasets.CIFAR100(root='./data', train=False, download=True, transform=transform_test)cifar100_test_loader = DataLoader(cifar100_test, shuffle=shuffle, num_workers=num_workers, batch_size=batch_size)return cifar100_test_loaderdef show_batch(images, labels):import matplotlibmatplotlib.use('TkAgg')images = denormalize(images, CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)img_grid = make_grid(images, nrow=4, padding=10, normalize=True)plt.imshow(img_grid.permute(1, 2, 0))plt.title(f"Labels: {labels}")plt.show()def denormalize(tensor, mean, std):"""反归一化操作,将归一化后的张量转换回原始范围."""if not torch.is_tensor(tensor):raise TypeError("Input should be a torch tensor.")for t, m, s in zip(tensor, mean, std):t.mul_(s).add_(m)return tensordef main1():test_loader = get_val_loader(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD, batch_size=16, num_workers=2, shuffle=False)for images, labels in test_loader:show_batch(images, labels)# print(images.size(), labels)if __name__=="__main__":transform_train = transforms.Compose([transforms.ToPILImage(),transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)])train_dataset = CIFAR100Dataset(path='./data/cifar-100-python', transform=transform_train)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)for images, labels in train_loader:show_batch(images, labels)# print(images.size(), labels)
![[PHP]Kodexplorer可道云 v4.47](https://img-blog.csdnimg.cn/532b538062ec407b85784c9884eef039.png)