目录
1.单机部署
1.1 解压软件
1.2 创建软链接
1.3 修改配置文件
1.4 配置环境变量
1.5 后台启动
2.配置分词器
2.1 安装IK分词器
2.2 ES 扩展词汇
3.常用操作
3.1 索引
3.1.1 创建索引
3.1.2 查看所有索引
3.1.3 查看单个索引
3.1.4 删除索引
3.2.文档
3.2.1 创建文档
3.2.2 查看文档
3.2.3 修改文档
3.2.4 修改字段
3.2.5 删除文档
3.2.6 条件删除文档
3.3.映射
3.3.1.创建索引
4.3.2.创建映射
3.3.3.查看映射
3.4.高级查询
3.4.1 查询所有文档
3.4.2 匹配查询
3.4.3 字段匹配查询
3.4.4 关键字精确查询
3.4.5 多关键字精确查询
4.4.6 指定查询字段
3.4.7 过滤字段
3.4.8 组合查询
3.4.9 范围查询
1.单机部署
1.1 解压软件
tar -zxvf elasticsearch-7.15.2-linux-x86_64.tar.gz
1.2 创建软链接
ln -s /data/opt/elasticsearch-7.15.2 /data/opt/elasticsearch
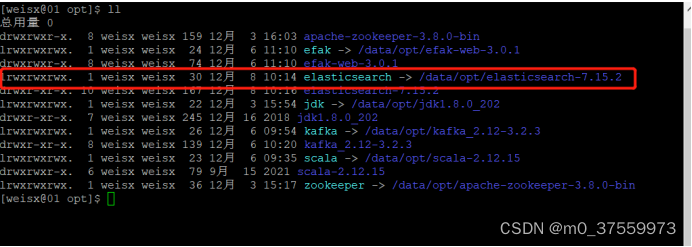
1.3 修改配置文件
修改/data/opt/elasticsearch/config/elasticsearch.yml 文件
# 加入(修改)如下配置
cluster.name: weisx-es
node.name: weisx-01
path.data: /data/opt/elasticsearch/data
path.logs: /data/opt/elasticsearch/logs
network.host: 0.0.0.0
cluster.initial_master_nodes: ["weisx-01"]
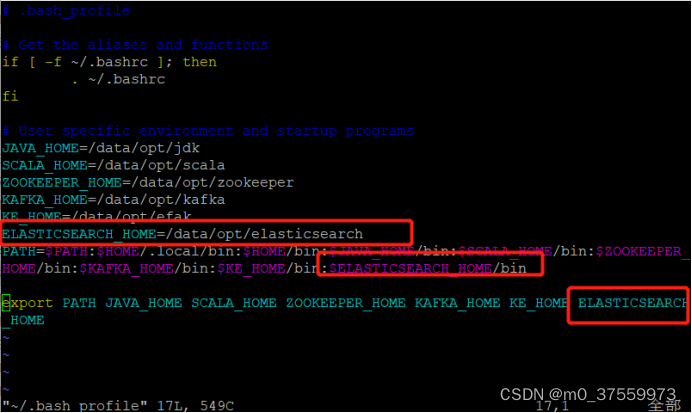
1.4 配置环境变量
vi ~/.base_profile
source ~/.base_profile
1.5 后台启动
bin/elasticsearch -d
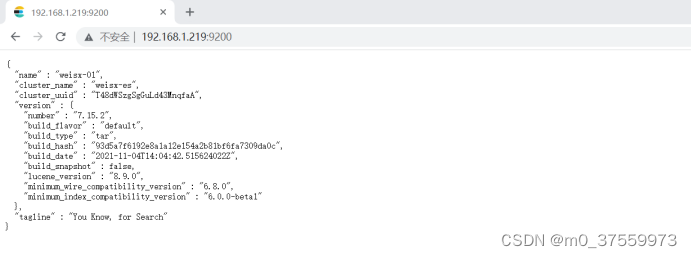
6)验证安装结果
浏览器中输入地址:http://192.168.1.219:9200/
2.配置分词器
2.1 安装IK分词器
将ik分词器下载解压到ES安装目录下的plugins,然后重启ES即可。

默认分词

IK分词

2.2 ES 扩展词汇
首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic 文件,写入自定义词汇。同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中, 重启 ES 服务器。

3.常用操作
3.1 索引
3.1.1 创建索引
对比关系型数据库,创建索引就等同于创建数据库
在 Postman 中,向 ES 服务器发 PUT 请求 :http://192.168.179.121:9200/shopping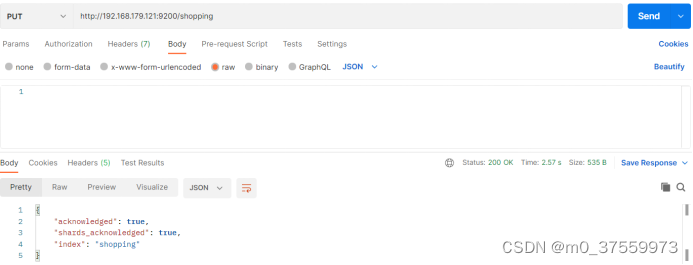
3.1.2 查看所有索引
在Postman中,向ES服务器发GET请求:http://192.168.179.121:9200/_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下
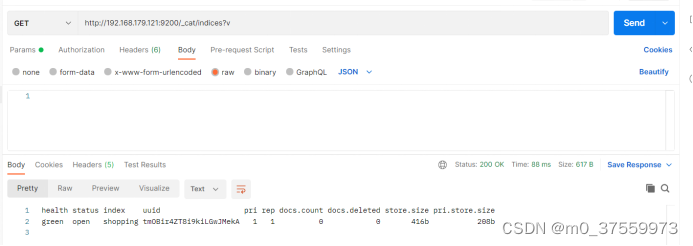
3.1.3 查看单个索引
在 Postman 中,向 ES 服务器发 GET 请求 :http://192.168.179.121:9200/shopping
查看索引向 ES 服务器发送的请求路径和创建索引是一致的。
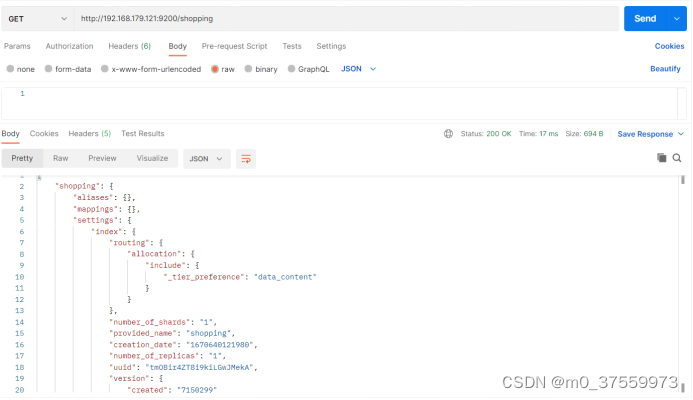
3.1.4 删除索引
在Postman中,向 ES 服务器发 DELETE 请求 :http://192.168.179.121:9200/shopping
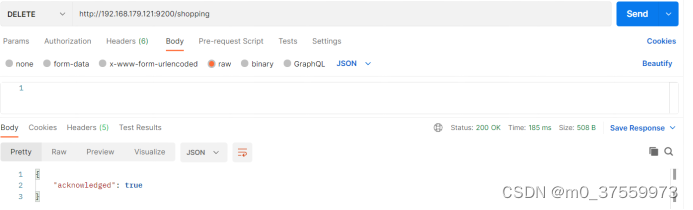
3.2.文档
3.2.1 创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
在Postman中,向ES服务器发 POST 请求 :http://192.168.179.121:9200/shopping/_doc
请求体内容如下:
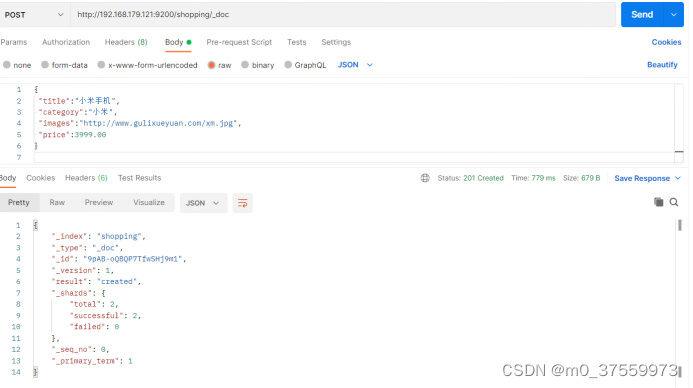
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。如果想要自定义唯一性标识,需要在创建时指定:http://192.168.179.121:9200/shopping/_doc/1
3.2.2 查看文档
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
在Postman中,向ES服务器发GET请求:http://192.168.179.121:9200/shopping/_doc/1

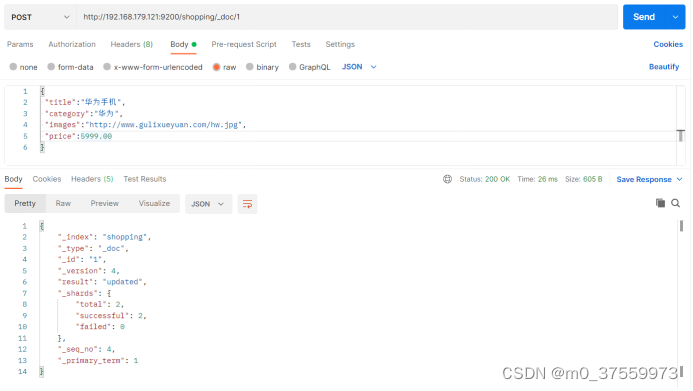
3.2.3 修改文档
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
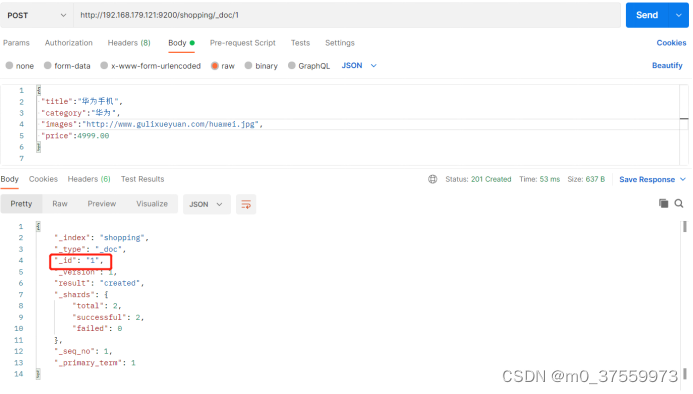
在Postman中,向ES服务器发POST请求:http://192.168.179.121:9200/shopping/_doc/1
请求体内容如下:
3.2.4 修改字段
修改数据时,也可以只修改某一给条数据的局部信息
在Postman中,向ES服务器发POST请求 :http://192.168.179.121:9200/shopping/_update/1
请求体内容如下:

3.2.5 删除文档
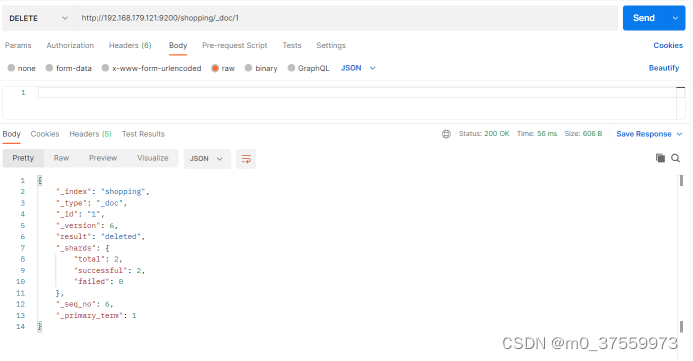
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在 Postman 中,向ES服务器发DELETE请求 :http://192.168.179.121:9200/shopping/_doc/1
删除成功,服务器响应结果:
3.2.6 条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
向ES服务器发POST请求:http://192.168.179.121:9200/shopping/_delete_by_query
请求体内容如下:

3.3.映射
3.3.1.创建索引
在 Postman 中,向 ES 服务器发 PUT 请求 :http://192.168.179.121:9200/student
4.3.2.创建映射
在Postman中,向ES服务器发PUT请求:http://192.168.179.121:9200/student/_mapping
请求体内容如下:
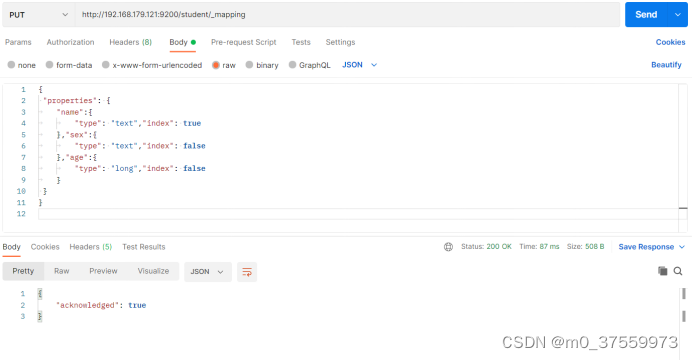
映射数据说明:
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
String 类型,又分两种:text:可分词;keyword:不可分词,数据会作为完整字段进行匹配
Numerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
Date:日期类型
Array:数组类型
Object:对象
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。true:字段会被索引,则可以用来进行搜索;false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为 false;原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
analyzer:分词器
3.3.3.查看映射
在Postman中,向ES服务器发GET请求:http://192.168.179.121:9200/student/_mapping
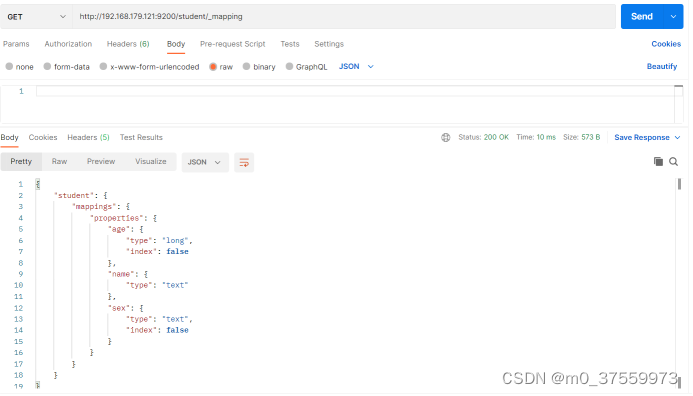
3.4.高级查询
3.4.1 查询所有文档
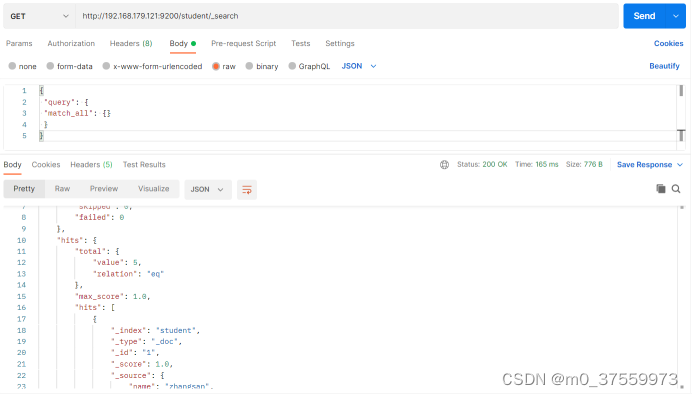
在Postman中,向ES服务器发 GET 请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"match_all": {}
}
}
# "query":这里的 query 代表一个查询对象,里面可以有不同的查询属性
# "match_all":查询类型,例如:match_all(代表查询所有), match,term , range 等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异
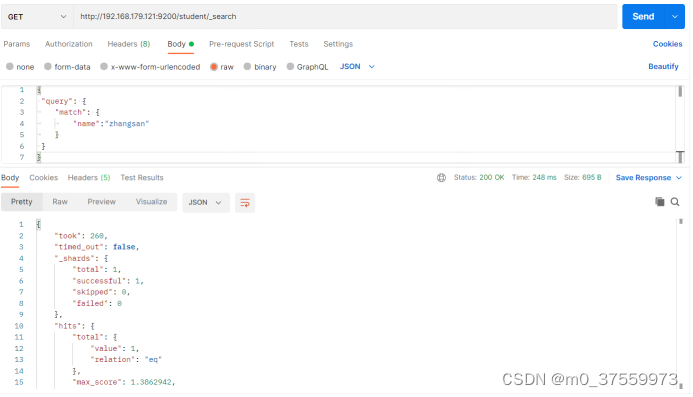
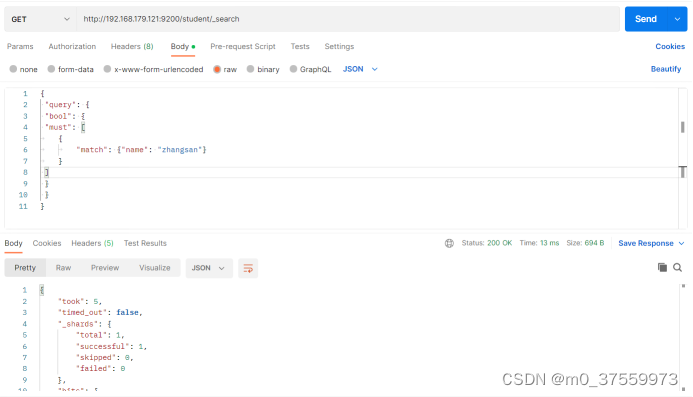
3.4.2 匹配查询
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系
在Postman中,向ES服务器发 GET 请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"match": {
"name":"zhangsan"
}
}
}
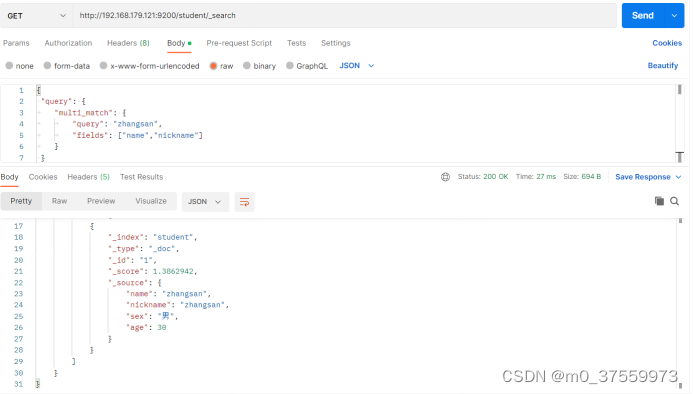
3.4.3 字段匹配查询
multi_match 与 match 类似,不同的是它可以在多个字段中查询。
在Postman中,向ES服务器发 GET 请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name","nickname"]
}
}
}
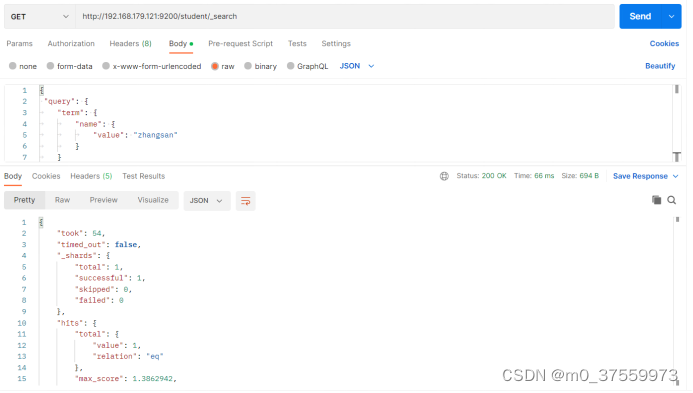
3.4.4 关键字精确查询
term 查询,精确的关键词匹配查询,不对查询条件进行分词。
在Postman中,向ES服务器发 GET 请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
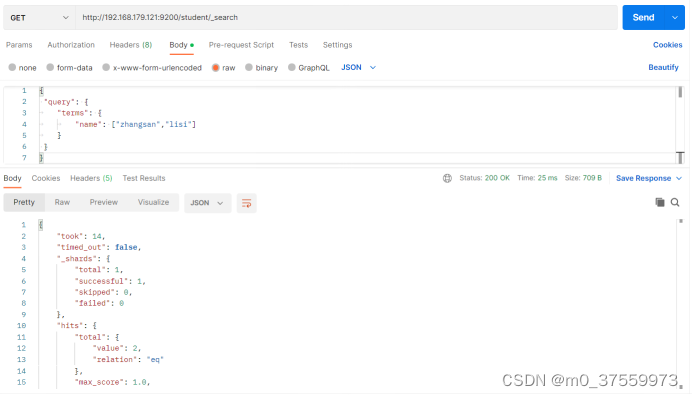
3.4.5 多关键字精确查询
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in。
在Postman中,向ES服务器发GET请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"terms": {
"name": ["zhangsan","lisi"]
}
}
}
4.4.6 指定查询字段
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
在Postman中,向ES服务器发GET请求 :http://192.168.179.121:9200/student/_search
{
"_source": ["name","nickname"],
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}

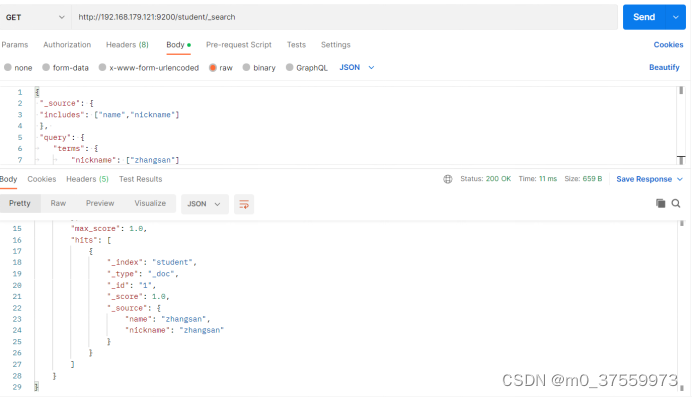
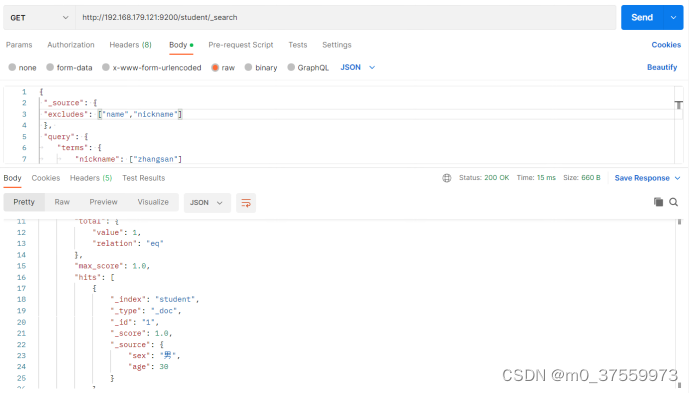
3.4.7 过滤字段
我们也可以通过:
includes:来指定想要显示的字段
excludes:来指定不想要显示的字段
在Postman中,向ES服务器发GET请求 :http://192.168.179.121:9200/student/_search
{
"_source": {
"includes": ["name","nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
3.4.8 组合查询
`bool`把各种其它查询通过`must`(必须 )、`must_not`(必须不)、`should`(应该)的方式进行组合
在Postman中,向ES服务器发GET请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"match": {"name": "zhangsan"}
}
],
"must_not": [
{
"match": {"age": "40"}
}
],
"should": [
{
"match": {"sex": "男"}
}
]
}
}
}
3.4.9 范围查询
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符
gt:大于>
gte:大于等于>=
lt:小于<
lte:小于等于<=
在Postman中,向ES服务器发GET请求 :http://192.168.179.121:9200/student/_search
{
"query": {
"range": {
"age": {
"gte": 30,"lte": 35
}
}
}
}