目录
预写式日志(WAL)
WAL概念
WAL的作用
WAL日志存放路径
WAL日志文件数量
WAL日志文件存储形式
WAL日志文件命名
WAL内容
检查点(checkpoint)
1 检查点概念
2 检查点作用
触发检查点
触发检查点之后数据库操作
设置合理的检查点参数
查看检查点
监控检查点参数设置是否合理
优化检查点后的磁盘IO
LSN
参考
预写式日志(WAL)
WAL概念
预写式日志(WAL)是保证数据完整性的一种标准方法。简单来说,WAL的中心概念是数据文件(存储着表和索引)的修改必须在这些动作被日志记录之后才被写入,即在描述这些改变的日志记录被刷到持久存储以后。如果我们遵循这种过程,我们不需要在每个事务提交时刷写数据页面到磁盘,因为我们知道在发生崩溃时可以使用日志来恢复数据库:任何还没有被应用到数据页面的改变可以根据其日志记录重做(这是前滚恢复,也被称为REDO)。
简单理解: 数据持久化磁盘之前先写日志,先写的日志就位WAL
WAL的作用
使用WAL可以显著降低磁盘的写次数,因为只有日志文件需要被刷出到磁盘以保证事务被提交,而被事务改变的每一个数据文件则不必被刷出。日志文件被按照顺序写入,因此同步日志的代价要远低于刷写数据页面的代价。在处理很多影响数据存储不同部分的小事务的服务器上这一点尤其明显。此外,当服务器在处理很多小的并行事务时,日志文件的一个fsync可以提交很多事务。
WAL也使得在线备份和时间点恢复能被支持,如第 25.3 节所述。通过归档WAL数据,我们可以支持回转到被可用WAL数据覆盖的任何时间:我们简单地安装数据库的一个较早的物理备份,并且重放WAL日志一直到所期望的时间。另外,该物理备份不需要是数据库状态的一个一致的快照 — 如果它的制作经过了一段时间,则重放这一段时间的WAL日志将会修复任何内部不一致性。
简单理解
WAL的用处
1 将数据文件的随机写,日志文件的顺序写。 先写日志可以减少磁盘的IO次数
2 WAL的引入也支持了在线备份,基于时间的恢复。
3 崩溃恢复(crash-sate)
WAL日志存放路径
WAL日志被存放在数据目录(参数data_directory)的pg_wal目录里,
路径优化:
日志被放置在和数据库数据文件不同的另外一个磁盘上会比较好。你可以通过把pg_wal目录移动到另外一个位置(当然在此期间服务器应当被关闭),然后在原来的位置上创建一个指向新位置的符号链接来实现重定位日志。
WAL日志文件数量
pg_wal目录中的 WAL 段文件数量取决于min_wal_size、max_wal_size以及在之前的检查点周期中产生的 WAL 数量
WAL日志文件存储形式
它是作为一个文件段的集合存储的,通常每个段16MB大小(不过这个大小可以通过initdb配置选项--with-wal-segsize来修改)。每个段分割成多个页,通常每个页为8K(该尺寸可以通过--with-wal-blocksize配置选项来修改)。日志记录头部在access/xlogrecord.h里描述;日志内容取决于它记录的事件类型。
WAL日志文件命名
段文件的名字是不断增长的数字,从000000010000000000000001开始。目前这些数字不能复用,不过要把所有可用的数字都用光也需要非常非常长的时间。
00000001 00000000 0000000B
前8位: 00000001表示timeline
中间8位:00000000表示logid
最后8位:0000000B表示logseg
WAL内容
pg_waldump — 以人类可读的形式显示一个PostgreSQL 数据库集簇的预写式日志
pg_waldump 000000010000000000000001 > 000000010000000000000001.dump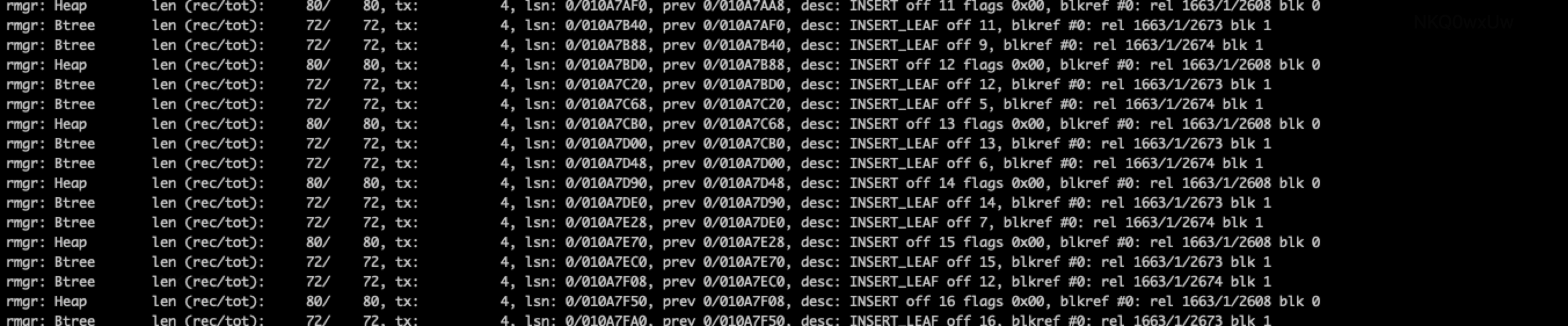
检查点(checkpoint)
1 检查点概念
检查点是在事务序列中的点,这种点保证被更新的堆和索引数据文件的所有信息在该检查点之前已被写入
检查点之前的数据都被持久化了
2 检查点作用
1 在检查点时刻,所有脏数据页被刷写到磁盘,并且一个特殊的检查点记录将被写入到日志文件(修改记录之前已经被刷写到WAL文件)。
2 在崩溃时,崩溃恢复过程检查最新的检查点记录用来决定从日志中的哪一点(称为重做记录)开始REDO操作。
3 在这一点之前对数据文件所做的任何修改都已经被保证位于磁盘之上。因此,完成一个检查点后位于包含重做记录的日志段之前的日志段就不再需要了,可以将其回收或删除(当WAL归档工作时,日志段在被回收或删除之前必须被归档)。
1 检查点之前的数据都被持久化了
2 崩溃恢复时,从检查点开始进行REDO恢复
3 从检查点之前的WAL日志可以被删除
触发检查点
- 每 checkpoint_timeout秒(默认5分钟,300秒)
- 自上次检查点之后WAL增长到的最大尺寸超过max_wal_size时 (默认1GB)
- 超级用户也可以使用SQL命令
CHECKPOINT来强制一个检查点。 - 在smart或fast模式下关闭实例 ,pg_ctl stop -m
- online backup开始的时候
- 在进行数据库配置时(例如CREATE DATABASE / DROP DATABASE语句)
- 执行pg_start_backup函数时
触发检查点之后数据库操作
- 识别shared buffers中所有的脏页
- 将脏页写入相应的数据文件
- 确保修改后的文件通过fsync()写入到磁盘
设置合理的检查点参数
降低checkpoint_timeout和/或max_wal_size会导致检查点更频繁地发生。这使得崩溃后恢复更快,因为需要重做的工作更少。但是,我们必须在这一点和增多的刷写脏数据页开销之间做出平衡。如果full_page_writes 被设置(默认情况),则还有一个因素需要考虑。为了确保数据页一致性,在每个检查点之后对一个数据页的第一次修改将导致整个页面内容被日志记录。在这情况下,一个较小的检查点间隔会增加输出到WAL日志的容量,这让使用较小间隔的效果打了折扣并且将导致更多的磁盘I/O。
频繁的
checkpoint可以在崩溃后恢复更快,但是如果设置full_page_writes参数后监控检查点参数设置是否合理
查看检查点
在完成一个检查点并且刷写了日志文件之后,检查点的位置被保存在文件pg_control里。因此在恢复的开始, 服务器首先读取pg_control,然后读取检查点记录; 接着它通过从检查点记录里标识的日志位置开始向前扫描执行 REDO操作。 因为数据页的所有内容都保存在检查点之后的第一个页面修改的日志里(假设full_page_writes没有被禁用), 所以自检查点以来的所有变化的页都将被恢复到一个一致的状态。
$ pg_controldata |grep checkpoint
Latest checkpoint location: 0/B000308
Latest checkpoint's REDO location: 0/B0002D0
Latest checkpoint's REDO WAL file: 00000001000000000000000B
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:646
Latest checkpoint's NextOID: 24722
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 478
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 646
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Wed 08 Nov 2023 10:52:09 AM CST监控检查点参数设置是否合理
检查点的代价相对比较昂贵,首先是因为它们要求写出所有当前为脏的缓冲区,正如以上讨论的,第二个原因是它们会导致额外的WAL流量。因此比较明智的做法是将检查点参数设置得足够高,这样检查点就不会过于频繁地发生。你可以设置checkpoint_warning参数作为对于你的检查点参数的一种简单完整性检查。如果检查点的发生时间间隔比checkpoint_warning秒还要接近,一个消息将会被发送到服务器日志来推荐你增加max_wal_size。偶尔出现的这样的消息并不会导致警报,但是如果它出现得太频繁,那么就应该增加检查点控制参数。 如果你没有把max_wal_size设置得足够高, 那么在进行如大型COPY传输等批量操作的时候可能会导致出现大量类似的警告消息。
设置参数checkpoint_warning ,如果checkpoint之间的间隔频繁小于这个该参数设置的时间,则会像服务器日志中发送告警。
优化检查点后的磁盘IO
为了避免大批页面写入对I/O系统产生的冲击,一个检查点中对脏缓冲区的写出操作被散布到一段时间上。这个时间段由checkpoint_completion_target控制,它用检查点间隔的一个分数表示。I/O率将被调整,以便能按照要求完成检查点:当checkpoint_timeout给定的秒数已经过去,或者max_wal_size被超过之前会发生检查点,以先达到的为准。默认值为0.5,PostgreSQL被期望能够在下一个检查点启动之前的大约一半时间内完成每个检查点。在一个接近于正常操作期间最大I/O的系统上,你可能希望增加checkpoint_completion_target来降低检查点的I/O负载。但这种做法的缺点是被延长的检查点将会影响恢复时间,因为需要保留更多WAL段来用于可能的恢复操作。尽管checkpoint_completion_target可以被设置为高于1.0,但最好还是让它小于1.0(也许最多0.9),因为检查点还包含除了写出脏缓冲区之外的其他一些动作。1.0的设置极有可能导致检查点不能按时被完成,这可能由于所需的WAL段数量意外变化导致性能损失。
在 Linux 和 POSIX 平台上,checkpoint_flush_after允许强制 OS 超过一个可配置的字节数后将检查点写入的页面刷入磁盘。否则,这些页面可能会被保留在 OS 的页面缓存中,当检查点结束发出fsync时就会导致大量刷写形成延迟。这个设置通常有助于减小事务延迟,但是它也可能对性能带来负面影响,尤其是对于超过shared_buffers但小于 OS 页面缓存的负载来说更是如此。
checkpoint_completion_target 用于将checkpoint之后的刷脏样的磁盘IO操作分散在一个时间段,用于避免对IO系统的冲击。是一个系数 ,基数为
checkpoint_timeout设定的时间。checkpoint_completion_target*
checkpoint_timeout 为
LSN
当每个新记录被写入时,WAL记录被追加到WAL日志中。 插入位置由日志序列号(LSN)描述,该日志序列号是日志中的字节偏移量, 随每个新记录单调递增。LSN值作为数据类型 pg_lsn返回。 值可以进行比较以计算分离它们的WAL数据量,因此它们用于衡量复制和恢复的进度。
pg_lsn数据类型可以被用来存储 LSN(日志序列号)数据,LSN 是一个指向WAL中的位置的指针。这个类型是XLogRecPtr的一种表达并且是 PostgreSQL的一种内部系统类型。
在内部,一个 LSN 是一个 64 位整数,表示在预写式日志流中的一个字节位置。它被打印成 两个最高 8 位的十六进制数,中间用斜线分隔,例如16/B374D848。 pg_lsn类型支持标准的比较操作符,如=和 >。两个 LSN 可以用-操作符做减法, 结果将是分隔两个预写式日志位置的字节数。