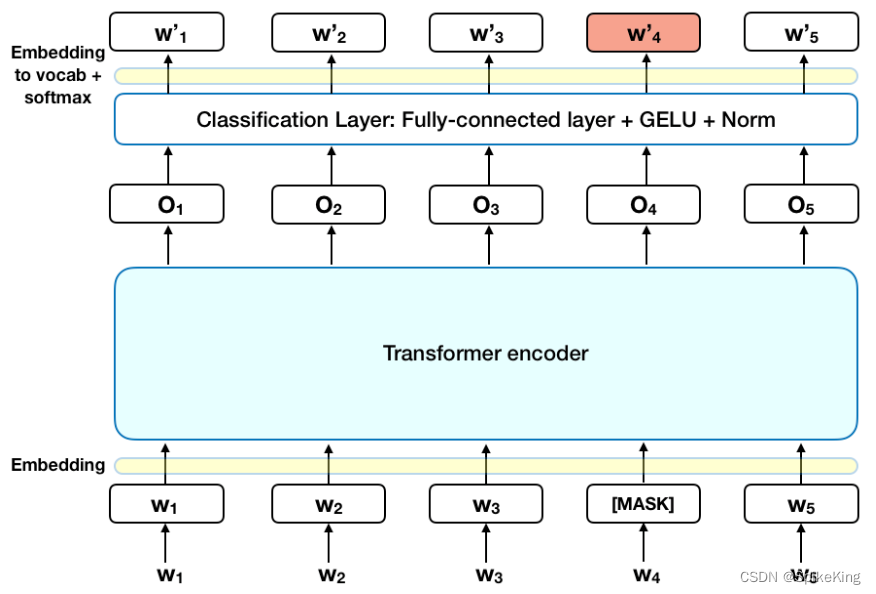
目录
Scrapy是什么
安装
使用
获取更多页面信息
写入数据库
图片下载
文件下载
更改文件名称以及路径
更改图片名称以及路径
循环获取页面信息时,item的数据重复或者对不上
下载文件时获取文件流直接上传到某个地方
Scrapy是什么
Scrapy 是一个基于 Python 的开源网络爬虫框架,用于从网页中提取数据。它提供了一套高效、灵活和可扩展的工具,可以帮助开发者快速构建和部署爬虫程序。
Scrapy 框架具有以下特点:
-
高性能: Scrapy 采用异步的网络请求和处理机制,能够高效地处理大规模的网页抓取任务。
-
可配置性: Scrapy 提供了丰富的配置选项,可以通过配置文件或代码灵活地设置爬虫的行为,包括请求头、请求间隔、并发数等。
-
XPath 和 CSS 选择器: Scrapy 内置了强大的选择器,支持使用 XPath 和 CSS 选择器来定位和提取网页中的数据。
-
中间件和扩展: Scrapy 提供了中间件和扩展机制,开发者可以通过编写中间件和扩展来自定义和扩展框架的功能,例如自定义请求处理、数据处理、错误处理等。
-
分布式支持: Scrapy 可以与分布式任务队列(如 Celery)结合使用,实现分布式爬取和数据处理。
-
数据存储: Scrapy 支持将爬取到的数据存储到各种数据存储系统,包括文件、数据库(如 MySQL、PostgreSQL)和 NoSQL 数据库(如 MongoDB)等。
-
日志和调试: Scrapy 提供了强大的日志和调试功能,可以帮助开发者进行爬虫的调试和错误排查。
英文文档:Scrapy 2.9 documentation — Scrapy 2.9.0 documentation![]() https://docs.scrapy.org/en/latest/
https://docs.scrapy.org/en/latest/
中文文档:
Scrapy 2.5 documentation — Scrapy 2.5.0 文档![]() https://www.osgeo.cn/scrapy/
https://www.osgeo.cn/scrapy/
安装
-
确保你已经安装了Python。Scrapy是一个Python框架,所以你需要先安装Python。你可以从Python官方网站Welcome to Python.orgThe official home of the Python Programming Language
https://www.python.org/
-
打开命令行终端(Windows用户可以使用命令提示符或PowerShell,Mac和Linux用户可以使用终端)。
-
在命令行中运行以下命令来安装Scrapy:
pip install scrapy这将使用pip包管理器下载并安装Scrapy及其依赖项。
-
等待安装完成。这可能需要一些时间,因为Scrapy的安装过程涉及到下载和安装多个组件。
-
安装完成后,你可以通过在命令行中运行以下命令来验证Scrapy是否成功安装:
scrapy如果Scrapy成功安装,你将看到Scrapy的版本信息和可用命令列表。
使用
获取更多页面信息
代码的逻辑思维如下:
-
在
start_requests方法中,构造了多个请求,每个请求对应一个搜索结果页的URL。通过循环生成URL,并使用yield返回一个scrapy.Request对象,该对象包含URL和相关的参数。 -
在
parse方法中,处理搜索结果页的响应。首先解析响应的JSON数据,获取每个应用的相关信息。然后对于符合条件的应用,构造应用详情页面的URL,并使用yield返回一个新的scrapy.Request对象,以及使用cb_kwargs参数传递额外的数据。 -
在
parse_versions方法中,处理应用详情页面的响应。解析响应的JSON数据,获取应用的不同版本信息。根据版本号进行筛选和处理,最终构造每个版本的详情页面URL,并使用yield返回一个新的scrapy.Request对象。 -
在
parse_detail方法中,处理应用详情页面的响应。解析响应的JSON数据,提取应用的详细信息,如名称、版本、作者、简介等。根据需要进行数据处理和清洗。最后将提取的数据组织成一个PackageItem对象,并使用yield返回。 -
在
yield package_item处,将最终的数据对象PackageItem返回给Scrapy框架进行后续处理,例如存储到数据库或导出为文件。
至于如何获取深层页面的内容,这段代码通过构造新的请求对象,使用scrapy.Request来获取深层页面的内容。在每个页面的解析方法中,通过解析响应数据和提取所需的URL,再次构造新的请求对象,从而实现爬取深层页面的数据。这种方式可以实现页面之间的跳转和链式爬取,让爬虫可以深入到不同的页面进行数据提取和处理。
注意⚠️:因为保密工作,博主已将关键字段删除,所以以下代码是不可用状态,大家看看代码逻辑即可。
class HelmchartSpider(scrapy.Spider):name = "helmchart"allowed_domains = ["hello.io"]def start_requests(self):for num in range(10, 16):yield scrapy.Request(url=f"https://hello?offset={num * 60}")#获取列表def parse(self, response, **kwargs):data = response.json()packages_lists = data['packages']for packages_list in packages_lists:packages_list_url = f"https://hello/{package_item['repository_name'].lower()}/{package_item['normalized_name'].lower()}"yield scrapy.Request(url=packages_list_url,callback=self.parse_versions,headers={'Content-Type': 'application/yaml'},cb_kwargs={"item": copy.deepcopy(package_item)},)#获取应用values文件内容def parse_versions(self, response, **kwargs):package_item = kwargs['item']data = response.json()versions = data.get('available_versions', [])grouped_versions = {}for version in versions:major, _, _ = self.get_version_parts(version)if major not in grouped_versions:grouped_versions[major] = []grouped_versions[major].append(version['version'])merged_array = []for values in grouped_versions.values():merged_array.extend(values)ver_rels = {}major_versions = set()for version in merged_array:if len(version.split('.')) < 3:continuemain_version = version.split('.')[0] + '.' + version.split('.')[1]major_versions.add(version.split('.')[0])if not ver_rels.get(main_version):ver_rels[main_version] = versionelif ver_rels[main_version] < version:ver_rels[main_version] = versionfiltered_list = []i = 3int_major_versions = [int(major_version) for major_version in major_versions]major_versions = sorted(int_major_versions, reverse=True)for major_version in major_versions:if i == 0:breakversions = []for version in merged_array:main_version = version.split('.')[0] + '.' + version.split('.')[1]if version.startswith(str(major_version) + '.') and (main_version not in versions):versions.append(main_version)versions.sort(reverse=True,key=lambda x: list(map(int, x.split('.'))))filtered_list.extend(versions[:3])i -= 1results = [ver_rels[version] for version in filtered_list]for version in results:url = f"https://hello?{package_item['repository_name'].lower()}/{package_item['normalized_name'].lower()}/{version}"yield scrapy.Request(url=url,callback=self.parse_detail,cb_kwargs={"item": copy.deepcopy(package_item)},)# 获取应用详情def parse_detail(self, response, **kwargs):package_item = kwargs['item']data = response.json()repository = data.get('repository')if logo == "":logo = 'https://hello.io/static/media/placeholder_pkg_helm.png'else:logo = f"https://hello.io/image/{logo}@2x"# 下载地址请求downloadUrl = data.get('content_url', '')if "github.com" in downloadUrl:downloadUrl = "https://ghproxy.com/" + downloadUrlpackage_item['logo_image_id'] = logopackage_item["readme"] = html_contentpackage_item["file_urls"] = [downloadUrl]package_item["category"] = categorypackage_item['version'] = data.get('version', '')package_item['image_urls'] = [logo]package_item['repository_name'] = repository.get('name', '')# 获取应用的 id、名称、版本、作者名称、简介package_item['package_id'] = data.get('package_id', '')package_item['name'] = data.get('name', '')package_item['normalized_name'] = data.get('normalized_name', '')package_item['display_name'] = repository.get('display_name', 'null')package_item['description'] = data.get('description', '')if data.get('readme', '') and package_item["category"]:yield package_item写入数据库
确保你已经安装了pymysql库。如果没有安装,可以使用以下命令进行安装:
pip install pymysql
定义一个名为DatabasePipeline的自定义Pipeline类。用于将数据存储到数据库中:
需要注意的是,这里的__init__、open_spider、close_spider、process_item都是内置的方法,可以选择在open_spider中进行数据库初始化,在process_item中进行操作,最后在close_spider中提交数据,断开连接。(数据库的基础操作就不多说了,有需要的可以去学学。)
class DbPipelin():def __init__(self):self.conn = Noneself.cursor = Nonedef open_spider(self, spider):self.conn = pymysql.connect(host="localhost",port=3306,user='root',password='gr123465!',database='helmDetail',charset="utf8mb4")self.cursor = self.conn.cursor()def close_spider(self, spider):self.conn.commit()self.conn.close()def process_item(self, item, spider):package_id = item.get("package_id", '')name = item.get("name", '')version = item.get("version", '')description = item.get("description", '')readme = item.get("readme", '')logo_image_id = item.get("logo_image_id", '')category = item.get('category', 0),if not self.check_package_exists(package_id):# package_id 不存在,执行插入操作query = 'INSERT INTO chartDetail (package_id, name, version, description, readme, logo_image_id, category) VALUES (%s, %s, %s, %s, %s, %s, %s)'self.cursor.execute(query, (package_id, name, version, description, readme, logo_image_id, category))else:# 获取相同 package_id 下的所有 versionversions = self.get_versions_by_package_id(package_id)if version not in versions:# 版本号不在相同 package_id 下的所有 version 中,执行插入操作query = 'INSERT INTO chartDetail (package_id, name, version, description, readme, logo_image_id, category) VALUES (%s, %s, %s, %s, %s, %s, %s)'self.cursor.execute(query, (package_id, name, version, description, readme, logo_image_id, category))else:# 版本号在相同 package_id 下的所有 version 中,执行更新操作query = 'UPDATE chartDetail SET description = %s, readme = %s, logo_image_id = %s, category = %s WHERE package_id = %s and version = %s'self.cursor.execute(query, (description, readme, logo_image_id, category, package_id, version))return itemdef check_package_exists(self, package_id):# 查询 package_id 是否存在query = 'SELECT package_id FROM chartDetail WHERE package_id = %s'self.cursor.execute(query, (package_id,))result = self.cursor.fetchone()return bool(result)def get_versions_by_package_id(self, package_id):# 获取相同 package_id 下的所有 versionquery = 'SELECT version FROM chartDetail WHERE package_id = %s'self.cursor.execute(query, (package_id,))versions = [v[0] for v in self.cursor.fetchall()]return versions 在Scrapy项目的settings.py文件中添加管道配置:
ITEM_PIPELINES = {"rainbondSpider.pipelines.DbPipelin": 100,
}图片下载
在Scrapy项目的settings.py文件中添加以下配置:
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1, # 内置的图片下载Pipeline
}IMAGES_STORE = '/path/to/your/image/folder' # 图片保存的目录
在Spider中的Item定义中,添加一个名为image_urls的字段,用于存储需要下载的图片的URL。
import scrapyclass MyItem(scrapy.Item):image_urls = scrapy.Field()# 其他字段...
修改Spider中的parse方法,在解析每个项目时,通过yield语句将包含图片URL的Item传递给Pipeline进行处理。
import scrapyclass MySpider(scrapy.Spider):name = 'my_spider'def start_requests(self):urls = ['http://example.com/image1.jpg','http://example.com/image2.jpg',# 更多图片URL...]for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):item = MyItem()item['image_urls'] = [response.url] # 将图片URL添加到item中# 解析其他字段...yield item
运行Scrapy爬虫,当解析到包含image_urls字段的Item时,scrapy.pipelines.images.ImagesPipeline会自动下载图片并将下载后的结果保存到配置的图片保存目录中。
文件下载
和上面下载图片的方式一样这里只需要进行一些基本的配置。
在Scrapy项目的settings.py文件中添加以下配置:
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1, # 内置的文件下载Pipeline
}FILES_STORE = '/path/to/your/file/folder' # 文件保存的目录在Spider中的Item定义中,添加一个名为file_urls的字段,用于存储需要下载的文件的URL。
import scrapyclass MyItem(scrapy.Item):file_urls = scrapy.Field()# 其他字段...
修改Spider中的parse方法,在解析每个项目时,通过yield语句将包含文件URL的Item传递给Pipeline进行处理
import scrapyclass MySpider(scrapy.Spider):name = 'my_spider'def start_requests(self):urls = ['http://example.com/file1.pdf','http://example.com/file2.txt',# 更多文件URL...]for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):item = MyItem()item['file_urls'] = [response.url] # 将文件URL添加到item中# 解析其他字段...yield item
更改文件名称以及路径
注意这里是重写了 file_path、get_media_requests这两个方法,通过get_media_requests将下载地址进行分解后得到版本信息,应用名称等关键信息,然后通过request的meta将文件传递到下一层,在file_path方法中将文件名称与保存地址重新赋值。这样就可以得到完整的地址了。
from scrapy.pipelines.files import FilesPipeline
class FileDownloadPipeline(FilesPipeline):def file_path(self, request, response=None, info=None):tgz = request.meta["tgz"]file_name = tgzreturn r'/rainchart/%s' % (file_name)def get_media_requests(self, item, info):if item["file_urls"]:for url in item["file_urls"]:tgz = url.split("/")[-1]name = tgz.split("-")[0]temp_version = tgz.split("-")[1]version = temp_version.rstrip(".tgz")mete = {"tgz": tgz,"name": name,"version": version,}yield Request(url, meta=mete)更改图片名称以及路径
这里的思路和文件的更改方向一致。不再做过多赘述。附上代码。
class ImagesDownloadPipeline(ImagesPipeline):def get_media_requests(self, item, info):if item["image_urls"]:for url in item["image_urls"]:mete = {"name": item["name"],}yield Request(url, meta=mete)def file_path(self, request, response=None, info=None):name = request.meta["name"]image_guid = namereturn f'/rainchart/{image_guid}.jpg'循环获取页面信息时,item的数据重复或者对不上
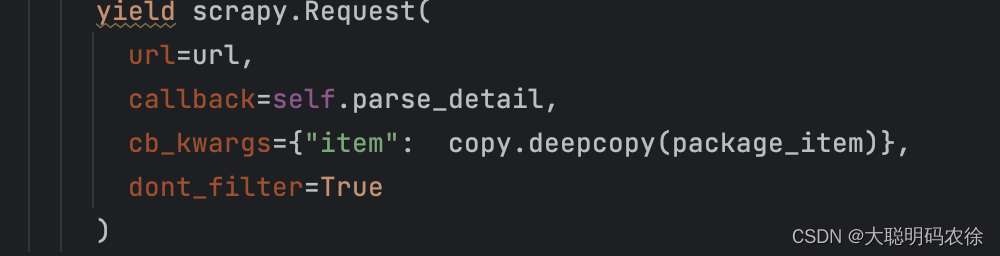
这里我的代码应该是循环了两次,一次获得应用名,一次获得版本信息,按照理想状态,最后的item数据每个都是唯一的,但是实际情况是最后的item很多数据都是重复和错乱的,要么导致不同应用的下载地址与版本一样或者错乱。
查找原因后,发现是因为使用 Request 函数传递 item 时,使用的是浅复制(对象的字段值被复制时,字段引用的对象不会被复制
解决方法就是添加一个copy.deepcopy()将数据深拷贝一下就行了。
下载文件时获取文件流直接上传到某个地方
如题所示,老板总能让你在意想不到的地方干意想不到的事,Scrapy本来只是抓取保存处理数据的地方,但是却让人在这里发请求,上传文件,头像,信息等等。信息什么的倒还好,存数据库时顺带发一下就行,但是,文件头像的下载是异步执行,所有程序完成以后才会保存到对应的文件夹下。在普通的item里是能拿到files列表里的信息的,但是会有问题,指向的路径此时为空,因为异步的原因。所以这里有两种方法。
第一种单独写个脚本,在爬虫程序执行完以后,将固定文件夹下的所有文件按次序上传。以下是一个脚本示例。
import os
import requestsdef get_all_files_in_folder(folder_path):file_list = []for root, dirs, files in os.walk(folder_path):for file_name in files:file_path = os.path.join(root, file_name)file_list.append(file_path)return file_list# 指定文件夹路径
folder_path = 'rainbond_images/rainchart'# 获取该文件夹下的所有文件
files = get_all_files_in_folder(folder_path)
headers={'Content-Type': 'image/jpeg'}
# 打印文件列表
for file_path in files:with open(file_path, 'rb') as file:file_data = file.read()file_name_with_ext = os.path.basename(file_path)file_name = os.path.splitext(file_name_with_ext)[0]print(file_name)market_id = "859a51f9bb3b48b5bfd222e3bef56425"url = "https://hello.com/app-server/markets/{}/helm/{}/icon".format(market_id, file_name)resp = requests.post(url=url, data=file_data, headers=headers)第二种是 直接改Scrapy的源码。直接将buf(二进制文件流)传过去。
源码:def file_downloaded(self, response, request, info, *, item=None):path = self.file_path(request, response=response, info=info, item=item)buf = BytesIO(response.body)checksum = md5sum(buf)buf.seek(0)self.store.persist_file(path, buf, info)return checksum
修改后:def file_downloaded(self, response, request, info, *, item=None):buf = BytesIO(response.body)checksum = md5sum(buf)buf.seek(0)url = "https://hello/api/charts"headers = {"Content-Type": "application/octet-stream"}chart_resp = requests.post(url, headers=headers, data=buf).json()博主是个前端小菜鸡,这也是被老板硬忽悠着去干了爬虫,走了太多太多的坑,循环,深浅拷贝,异步,数据库存储等等等等,python,数据库,scrapy都是现学现用,确实给累好了这两周,简单记录一下,希望对各位有所帮助。唉😮💨难受死了