目录
静态路由配置方法(基本配置):
静态路由的拓展配置
负载均衡
1.环回接口——测试
2.手工汇总——子网汇总
3.路由黑洞(黑洞路由)
4.缺省路由
5.空接口——NULL 0
6.浮动静态路由
静态路由配置方法(基本配置):
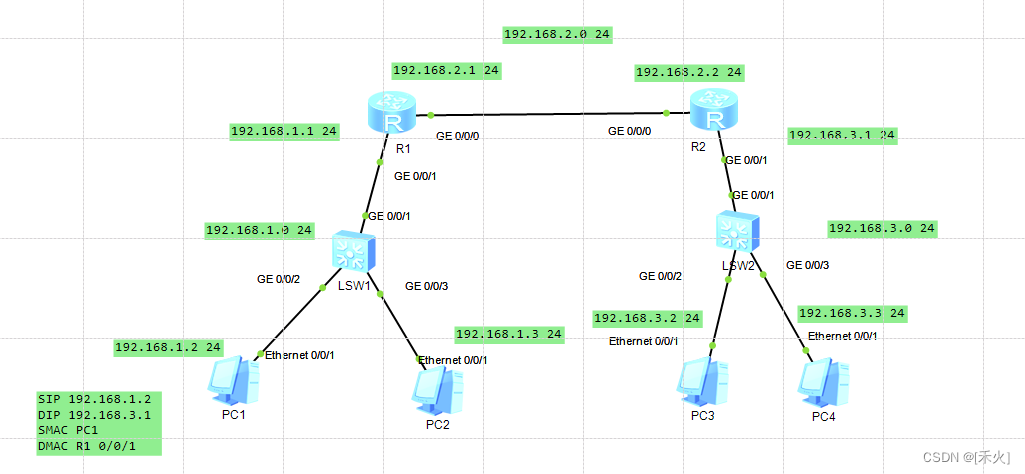
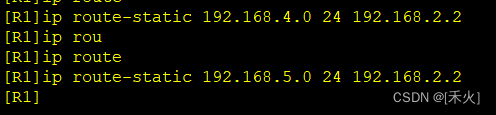
[R1]ip route-static 192.168.3.0 24 192.168.2.2
192.168.3.0 24——目标网段
192.168.2.2——下一跳入接口的IP
![]()
Static——静态路由
[R2]ip route-static 192.168.1.0 24 192.168.2.1
路由要有来有回!!!
拓展
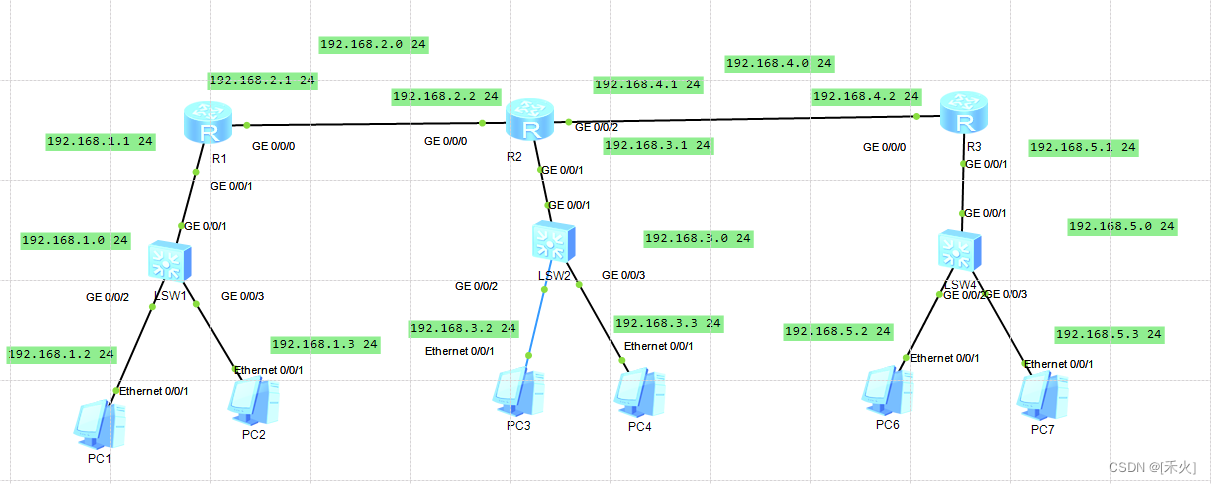
R1
R2
![]()
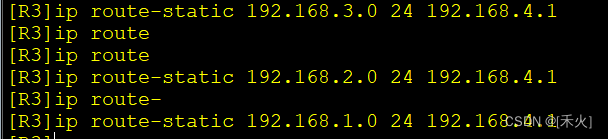
R3
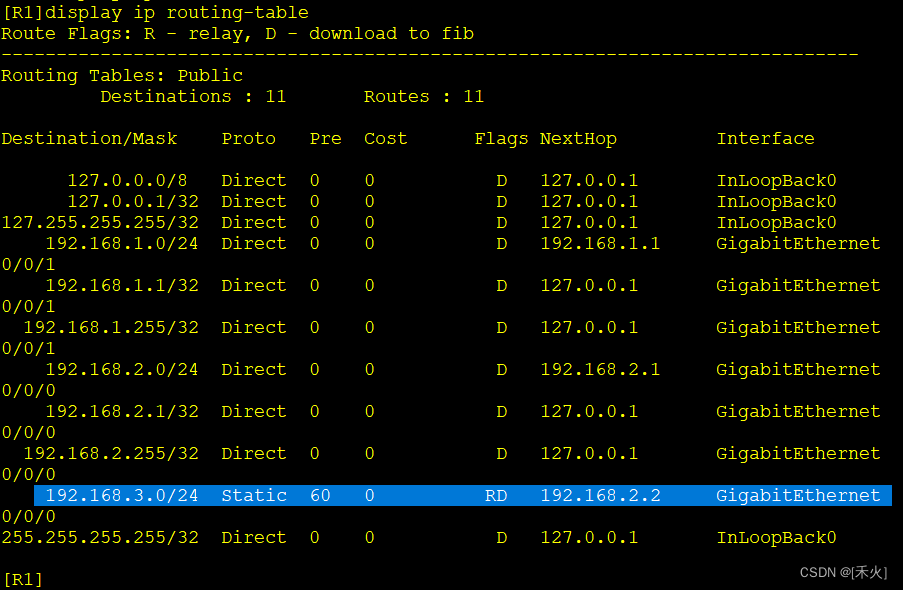
[R1]display ip routing-table protocol static ——查看路由表中通过静态写的路由
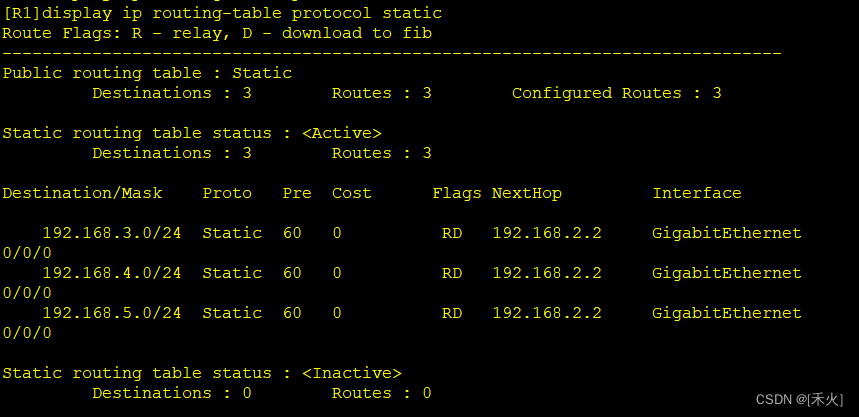
练习
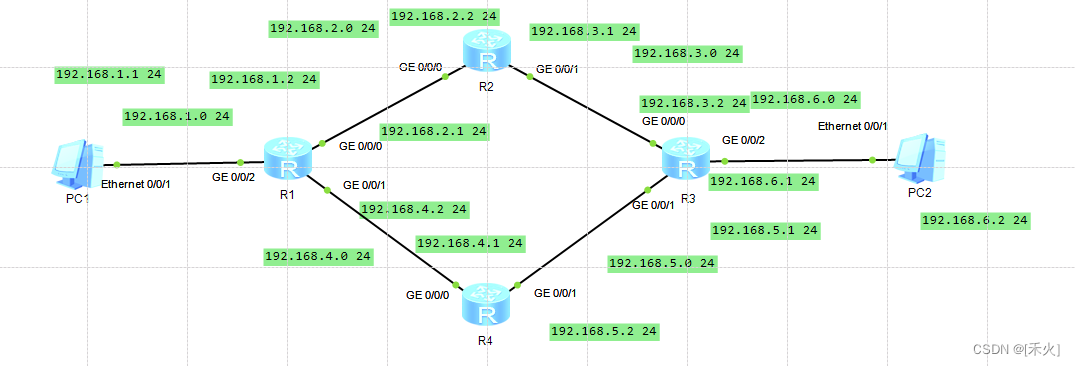
次优路径——环路问题(所以最好走近的)
所以如过R1想到达192.168.3.0走192.168.2.2不可以走192.168.4.1。
[R1]undo ip route-static 192.168.3.0 255.255.255.0 192.168.2.2—删除静态路由指令
TTL——生存时间——防止出现环路,导致数据包一直循环
负载均衡
当去往一个目标网段存在多条路径,并且路径开销一致,那么就可以配置负载均衡(两个下一跳),起到流量分流,降低链路带宽压力的作用
静态路由的拓展配置
负载均衡
1.环回接口——测试
逻辑接口,并不真实存在
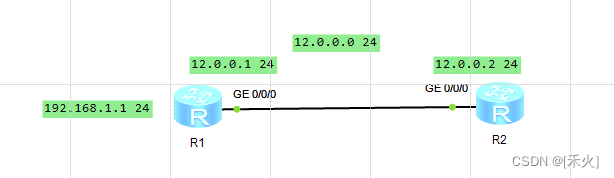
[R1]interface LoopBack 0——进入环回接口

[R1-LoopBack0]ip address 192.168.1.1 24——给环回接口一个IP
![]()
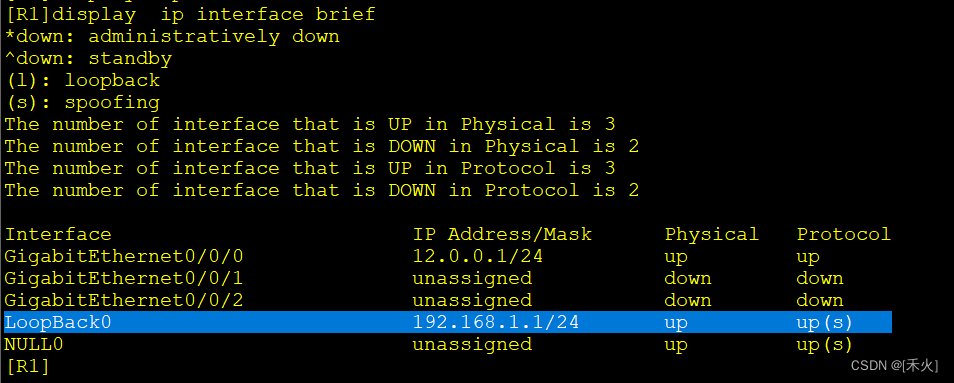
环回接口的IP代表的是一个网段
环回接口作用:模拟一个网段
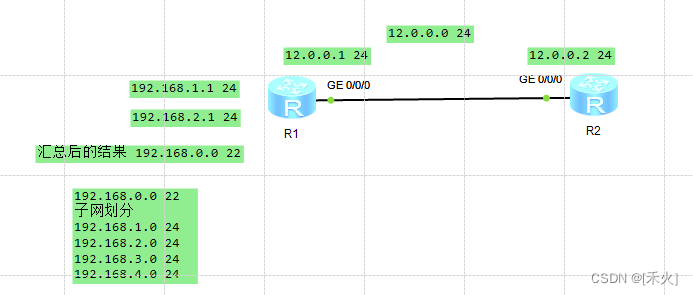
2.手工汇总——子网汇总
子网汇总:当路由器去访问多个连续的子网,并且这些子网具备相同的下一跳,则可以进行汇总
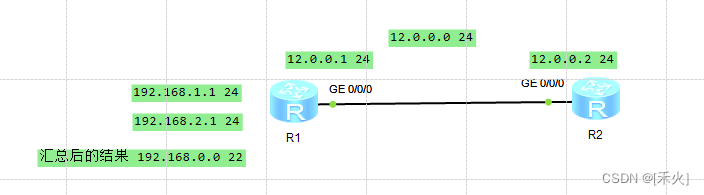
配置两个环回接口

![]()

让R2下一跳
![]()
汇总可以加快网络的收敛同时加快网络配置
合理的地址规划,可以尽量减少黑洞的产生
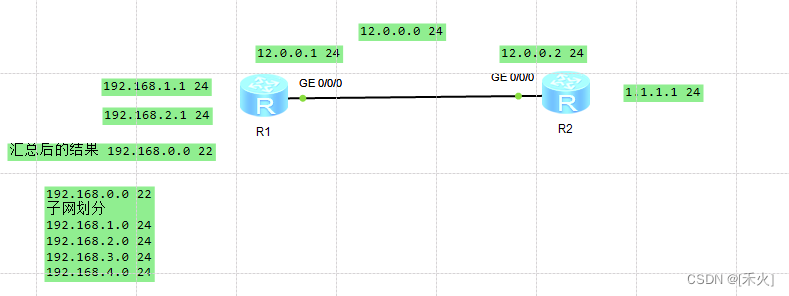
3.路由黑洞(黑洞路由)
如果网络中包含实际不存在的网段,并且我们做了手工汇总,就会导致某些流量有去无回,浪费链路资源
4.缺省路由
缺省和黑洞相遇100%成环

![]() 缺省
缺省
[R1]ip route-static 0.0.0.0 0 12.0.0.2——代表所有IP,访问互联网
![]()
0.0.0.0——所有IP
成环
如果这时R2ping192.168.3.1
则会在R2和R1之间往复
5.空接口——NULL 0
空接口可以解决成环
黑洞路由器
[R1]ip route-static 192.168.0.0 22 NULL 0——做法,在黑洞路由器上配置一条去往汇总网段的路由去往空接口
![]()
最长掩码匹配原则:先走掩码长的路径(路由器最优先的规则)
192.168.0.0 22 的掩码比0.0.0.0的掩码长当192.168.3.1来了之后进入空接口而不匹配缺省
在没有指定IP的情况下从那个接口发出那么源IP就是那个接口的IP
[R2]ping -a 1.1.1.1 192.168.3.1——指定源和目标IP
![]()
源IP 1.1.1.1
目标IP 192.168.3.1
6.浮动静态路由
[R4]ip route-static 0.0.0.0 0 192.168.1.22 preference 61——更改路由优先级,优先级数值越大,优先级的级别反而越低,数值范围0-255
![]()
shutdown——关闭接口
undo shutdown——打开接口