笔记整理:李煜,东南大学硕士,研究方向为知识图谱
链接:https://proceedings.neurips.cc/paper_files/paper/2022/hash/df438caa36714f69277daa92d608dd63-Abstract-Conference.html
1. 动机
生成式语言模型(例如 GPT-3)仅经过训练来对子词标记之间的统计相关性进行建模,并且生成事实上准确的文本的能力有限。因此,人们越来越担心关于大规模预训练 LM 的非事实生成。与具有事实信息的大量在线文本相比,结构化知识图仅编码有限数量的知识,因为它们需要昂贵的人工注释来进行高质量的构建。探索了一种无(信息检索) IR 的方法,通过对事实丰富的纯文本语料库的持续训练来增强 LM 的固有事实性。文章探索了一种无 IR 的方法,通过对事实丰富的纯文本语料库的持续训练来增强 LM 的固有事实性。
2. 主要贡献
文章设计了 FACTUALITYPROMPTS 测试集和指标来衡量 LM 生成的真实性。在此基础上,文章研究了参数大小范围从 126M 到 530B 的 LM 的事实准确性。作者发现较大的语言模型比较小的语言模型的回答更符合事实,尽管之前的研究表明较大的语言模型在误解方面可能不太真实。此外,开放式文本生成中流行的采样算法(例如 top-p)可能会由于每个采样步骤引入的“均匀随机性”而损害事实性。因此提出了事实核采样算法,该算法采取动态的适应随机性,以提高生成的真实性,同时保持质量。此外,文章分析了标准训练方法在从事实文本语料库(例如维基百科)中学习实体之间的正确关联方面的低效率。所以作者提出了一种事实增强训练方法,使用 TOPICPREFIX 更好地了解事实和完成句子作为训练目标,可以大大减少事实错误。

图1: 具有贪婪解码和核采样 p = 0.9 的 530B LM 的知识生成示例,以及具有事实核采样的事实增强型 530B LM 的生成。红色代表非事实,绿色代表事实,删除线代表重复。当 LM 生成 <|endoftext|> 或达到最大长度时,它们将停止生成
总之,文章建立了一个基准来衡量和分析开放式文本生成任务中的事实性。文章提出事实核采样,可以在保持质量和多样性的同时提高生成的真实性。并结合“句子完成损失”和 “TOPICPREFIX ”预处理,以通过持续训练提高事实性。
文章发现直接在事实文本数据上继续训练LM并不能保证事实准确性的提高。所以文章提出进行事实增强培训,以解决该基线的潜在低效率问题。方法包括 i) 添加一个 TOPICPREFIX 以提高训练期间对事实的认识,以及 ii) 一个句子完成任务作为持续 LM 训练的新目标。
3. 实验方法
文章的目标是自动测量和评估用于开放式文本生成的大规模预训练语言模型 (LM) 的真实性。事实性是指与 NLP 中提供的真实知识源保持一致。评估开放式文本生成的真实性的最大挑战与从无数的世界知识中定位真实知识有关。由于缺乏生成的真实参考资料,评估开放式文本生成可能具有挑战性。在本研究中,作者的真实知识源的范围设置为维基百科,因为这有助于简化评估设置。
文章的评估框架由以下阶段组成(如图2所示)。在第 1 阶段,LM 根据提供的测试提示生成文本。在第二阶段,首先识别值得检查的生成文本,这是指具有需要事实性评估的内容。此步骤是必要的,因为开放式文本生成可能会生成不包含个人观点或闲聊式文本等事实的文本(例如,“我喜欢吃苹果!”)。然后,对值得检查的延续进行事实验证所需的相关事实知识。最后计算事实性和质量指标。
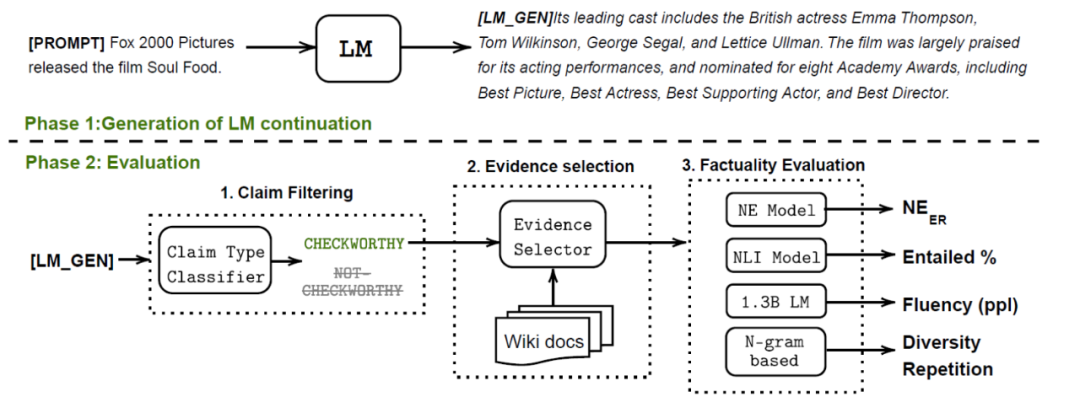
图2:整体评估框架
提示和评估:
文章设计了一个测试提示test prompts,它具有toxic和nontoxic提示来评估 LM 生成的内容。由事实提示和非事实提示组成,能够研究提示的真实性对于LM生成内容的影响。
准备相关的基本事实知识:
文档级别的真实知识,用wiki百科的文档,句子级别的真实知识,采用两种方法,一种是采用文本和维基百科句子视为候选池C,将生成的文本视为查询 q,通过获取 q 和 C 的 TF-IDF 向量表示并选择与 q 具有最高余弦相似度的 ci 来检索一个真实句子,另一种是采用SentenceTransformer获取 q 和 C 的上下文表示并选择具有最高余弦相似度的 cj 来检索。
评估指标:
采用基于命名实体 (NE) 的度量和基于文本蕴含的度量,每个指标都反映了事实的不同方面:
幻觉 NE 错误:如果语言模型生成的NE 未出现在真实知识源中,它就会产生幻觉(造成事实错误),基于 NE 的指标定义为:NEER = |HALLUNE| / |ALLNE|其中 ALLNE 是 LM 生成中检测到的所有 NE 的集合,HALLUNE 是 NEAll 的子集,它没有出现在真实的维基百科文档中。需要注意的是,评估 NEER 需要文档级的基本事实。
蕴含比例:基于蕴含的指标基于以下基本原理:事实生成将由真实知识所蕴含。
生成质量:流畅性,多样性,减少重复。
与人类判断的相关性:实验表明人类对事实的判断与所提出的自动度量 NEER 和 EntailR 之间存在很强的相关性。
4. 评估结果
文章从三个方面对 LM 进行事实分析:i)模型大小,ii)提示类型和 iii)解码算法。
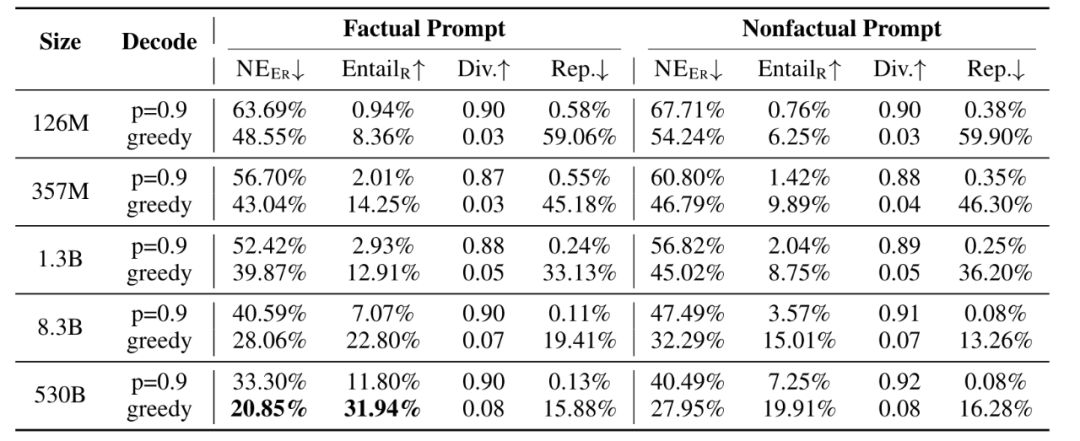
图3: 具有从 12M 到 530B 不同参数大小的 LM 的真实性。NEER 指命名实体错误,EntailR 指蕴涵比,Div.指的是不同的 4-gram,Rep. 指的是重复
模型大小:生成的准确性确实随着模型规模的增加而提高,
提示类型:事实提示和非事实提示都可以导致非事实生成,尽管事实提示总是导致较少的非事实生成。随着模型大小的增加,事实提示和非事实提示之间的性能差距变得更加突出。
解码算法:文章介绍了两种解码算法,贪婪解码和核采样,核采样top-p解决了贪婪解码算法的退化问题(例如重复),尽管top-p解码获得了更高的生成多样性和更少的重复,但在事实性方面,top-p解码的性能不如贪婪解码。因为 top-p 可以被视为添加“随机性”以鼓励多样性,从而可能导致事实错误。因为它选择概率最高的单词的方式最大限度地减少了随机性,并最大限度地利用了 LM 的参数知识。然而,贪婪解码牺牲了生成多样性和质量。
错误类型:两种典型错误类型,分别是命名实体混合,捏造事实。
5. 事实核采样
文章在实验结束以后提出了一种新的采样算法,与现有的解码算法相比,它可以在生成质量和真实性之间实现更好的权衡。
文章假设当采样的随机性用于生成句子的后半部分时,比用于生成句子的开头时,对事实性的危害更大。句子开头没有前面的文本,因此只要符合语法和上下文,LM 就可以随意地生成任何内容。然而,随着迭代的进行,前提变得更加确定,并且更少的单词选择可以使句子成为事实。因此,我们引入了事实核采样算法。
采样算法即在每个句子的生成过程中动态调整“核”p,随着时间的推移减少“随机性”。并且在每句话的开头重置p,减轻了重复的问题并提高了多样性。并且设置了最低限度ω。
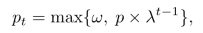
λ -decay: 在每个生成步骤中用衰减因子逐渐衰减 p 值,以随着时间的推移减少“随机性”。
p-reset:在生成过程中每个新句子的开头将 p 值重置为默认值(我们通过检查上一步是否生成了句号来识别新句子的开头)。p-reset 减轻了重复问题并提高了多样性指标,而不会损失太多事实性指标。
ω-bound:p 值可能会变得太小而无法等同于贪婪解码并损害多样性。为了克服这个问题,文章引入了下界ω限制 p 值可以衰减的程度。
文章通过消融研究来展示每个部分的重要性。
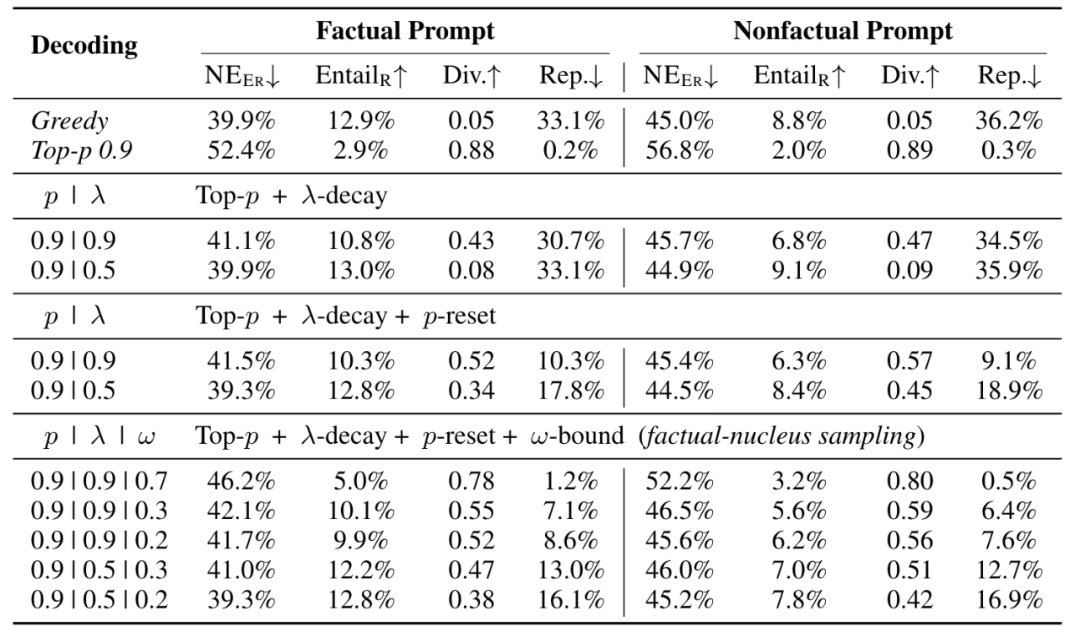
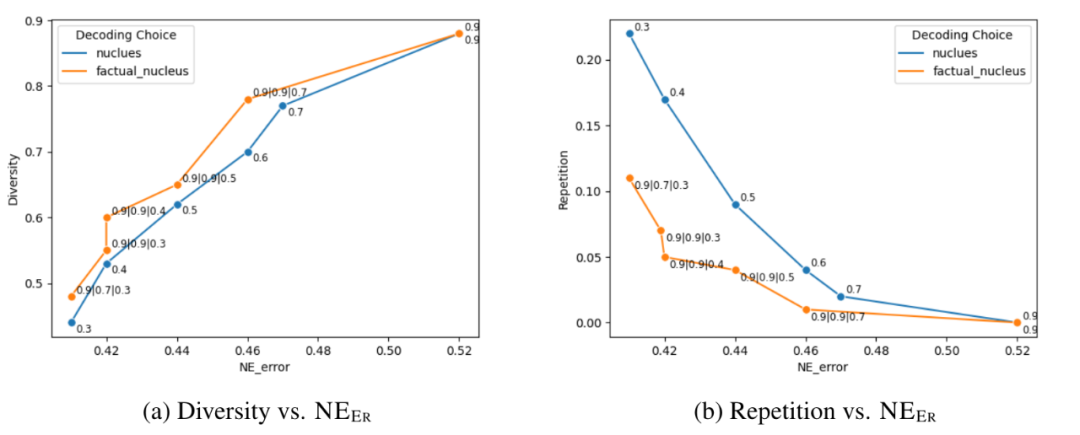
图4: 核采样(蓝线)和事实核采样(橙线)之间的比较。x 轴被命名为实体误差 NEER。y 轴分别是(a)和(b)中的多样性和重复性。重复次数越低越好。显然,事实核心抽样在事实性和多样性/重复性之间具有更好的权衡
添加 λ-decay 有助于提高 top-p 0.9 事实性结果,例如,当衰减率 λ= 0.5 时,NEER 下降 12.5%,EntailR 增益 10.1%。然而,这会影响多样性和重复性,使其变得类似于贪婪解码。p-reset 减轻了重复问题并提高了多样性指标,而不会损失太多事实性指标。λ= 0.5 选项的效果更为显着,它在多样性指标上实现了 0.26 的增益,而事实分数的变化可以忽略不计。通过添加ω-bound,与贪婪解码相比,生成质量有了很大的提高;当 p=0.9, λ=0.9, ω=0.3 时,在多样性方面实现了x11的改进,在重复方面比贪婪实现了x4.6 的改进。尽管这种事实核采样在多样性方面仍然低于 top-p 0.9,但这是一个可以接受的权衡,可以提高 LM 对于事实敏感的开放式生成任务的事实性。
6. 事实强化训练
句子可以包含代词(例如,她、他、它),使得这些句子实际上独立时毫无用处,作为补救措施,作者建议在事实文档中的句子前面添加 TOPICPREFIX,使每个句子都充当独立的事实。文章中将维基百科文档名称作为 TOPICPREFIX。
句子完成损失:一种通过更多地关注句子的末尾部分(通常存在关键细节)来提高语言模型生成的事实准确性的方法。通过引入一种称为句子完成损失的新损失函数来实现此目的。在句子中建立一个枢轴点“t”,该点之前的所有子词预测损失在模型的优化过程中都会被赋予较小的权重(通过零掩蔽实现)。这将模型的注意力转移到确保对枢轴点之后出现的子词进行更准确的预测。理由是句子的后半部分通常对事实性更为关键,这种方法可以帮助确保生成更准确和上下文相关的信息。比如“Samuel Witwer’s father is a Lutheran minister”,找到的枢纽点是is,后半部分明显更为重要。
对于训练阶段,为每个句子确定合适的枢轴点至关重要,而在推理阶段不需要枢轴点,从而保证了模型的可用性和效率。
在文章中探索了三种策略(从简单到复杂)来确定枢轴 t:

文章实验表明:最简单的 SCHALF 与复杂的 SCROOT(例如 SCROOT)性能相当,因此建议未来的工作选择 SCHALF 策略。
7. 总结
文章建立了一个基准来衡量和分析开放式文本生成任务中的事实性。同时提出了事实核心采样算法,可以提高推理时生成事实知识的准确性,并结合句子完成损失和 TOPICPREFIX 预处理,通过增强知识进行强化训练来提高事实性。实验结果表明该方法可以有效地提高生成知识的事实性,同时也揭示了该方法在多样性和事实性之间存在的权衡。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。