【动手学习深度学习】逐行代码解析合集
08模型选择、欠拟合和过拟合
视频链接:动手学习深度学习–模型选择、欠拟合和过拟合
课程主页:https://courses.d2l.ai/zh-v2/
教材:https://zh-v2.d2l.ai/
1、生成数据集

import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2limport os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE""====================1、生成数据集===================="
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6]) # 多项式前四项系数# 随机生成200个样本:均值为0,方差为0.01,形状(200,1)的特征样本
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features) # 打乱"计算出每个样本的所有输入特征(包括阶乘)"
# np.power(a,b),求a的b次方
# poly_features:200个数组,每组20个值
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):# poly_features:(200,20)poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!"计算每个样本的真实标签,加上噪声"
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w) # 点乘运算,形成200个多项式
# 噪声项服从均值为0且标准差为0.1的正态分布
labels += np.random.normal(scale=0.1, size=labels.shape)"NumPy ndarray转换为tensor"
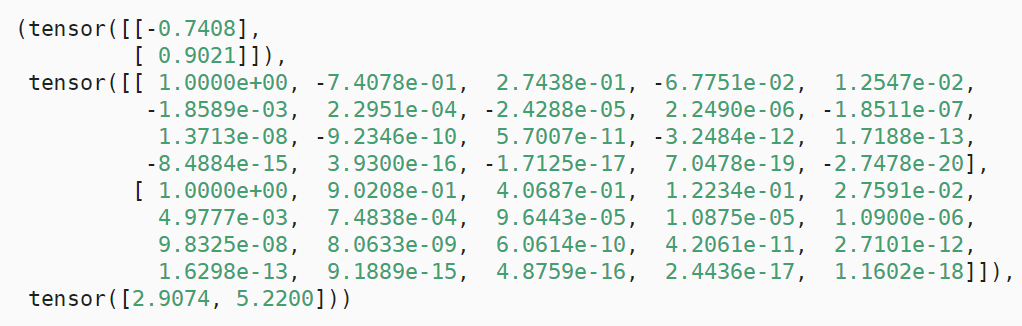
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]print(features[:2], poly_features[:2, :], labels[:2])
运行结果
2、对模型进行训练和测试
"====================2、对模型进行训练和测试===================="
# 计算网络模型在训练集或数据集上的损失均值
# net:定义的网络模型
# data_iter:打乱的并且根据批量大小切割好的训练集或测试集
# loss:损失函数
def evaluate_loss(net, data_iter, loss): #@save"""评估给定数据集上模型的损失"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:# 计算一个批量的预测值out = net(X)y = y.reshape(out.shape)# 计算一个批量的损失l = loss(out, y)# 将损失总和和样本数量 两个值累加metric.add(l.sum(), l.numel())# 返回损失均值return metric[0] / metric[1]# 定义训练函数
def train(train_features, test_features, train_labels, test_labels,num_epochs=400):loss = nn.MSELoss(reduction='none') # 均方误差损失函数input_shape = train_features.shape[-1]# 不设置偏置,因为我们已经在多项式中实现了它# 网络模型:input_shape个输入,1个输出,没有偏置项net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))batch_size = min(10, train_labels.shape[0]) # 设置批量大小为10# 按批量大小取出训练集(特征 + 对应的标签)train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),batch_size)# 按批量大小取出测试集(特征 + 对应的标签)test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),batch_size, is_train=False)# 定义优化器trainer = torch.optim.SGD(net.parameters(), lr=0.01)# 定义动画,显示训练结果animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',xlim=[1, num_epochs], ylim=[1e-3, 1e2],legend=['train', 'test'])# 训练400轮for epoch in range(num_epochs):# 训练一轮d2l.train_epoch_ch3(net, train_iter, loss, trainer)# 每隔20轮,将训练得到的模型在训练集和测试集上分别计算一次损失(训练损失、泛化损失)if epoch == 0 or (epoch + 1) % 20 == 0:animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))# 输出训练得到的模型权重print('weight:', net[0].weight.data.numpy())
3、三阶多项式函数拟合(正常)
"====================3、三阶多项式函数拟合(正常)===================="
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
# poly_features[:n_train, :4] :前100个样本,前4个维度 作为训练集
# poly_features[n_train:, :4] :后100个样本,前4个维度 作为训练集
# labels[:n_train]:将前100个样本的输出值作为训练集标签
# labels[n_train:]:将后100个样本的输出值作为测试集标签
train(poly_features[:n_train, :4], poly_features[n_train:, :4],labels[:n_train], labels[n_train:])
d2l.plt.show()
"输出 weight: [[ 4.9942217 1.1960176 -3.4083142 5.5780005]]"运行结果

4. 线性函数拟合(欠拟合)
"====================4、线性函数拟合(欠拟合)===================="
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],labels[:n_train], labels[n_train:])
d2l.plt.show()
"输出 weight: [[3.214788 4.6012254]]"
运行结果

5. 高阶多项式函数拟合(过拟合)
"====================5、高阶多项式函数拟合(过拟合)===================="
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:], num_epochs=1500)
d2l.plt.show()
'''
输出:
weight: [[ 4.95916700e+00 1.27137506e+00 -3.25717926e+00 5.24726105e+00-3.11582983e-01 1.13641846e+00 2.20295087e-01 -8.79566371e-024.93251672e-03 -1.06145725e-01 7.90703818e-02 1.64333731e-028.57480839e-02 -1.81607231e-01 1.93943262e-01 -1.26601264e-012.00300813e-01 -1.24204971e-01 1.35094225e-01 -3.30150127e-03]]
'''
运行结果