1.排序记录
排序是对数据中的无序记录,按照自然或客观规律,根据关键字段大小递增或递减的次序,对记录重新排列的过程
数据源
2019年11月月考数学成绩(Kettle数据集3).xls![]() https://download.csdn.net/download/Hudas/88521681
https://download.csdn.net/download/Hudas/88521681
需求:为了得出学生的成绩排名,使用【排序记录】组件,对学生的成绩从低到高排序
1.1 建立【排序记录】转换工程
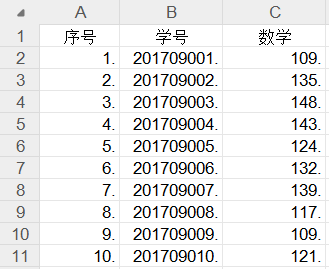
使用Ctrl+N快捷键,创建【排序记录】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"2019年11月月考数学成绩.xls"文件,预览数据,如下图所示
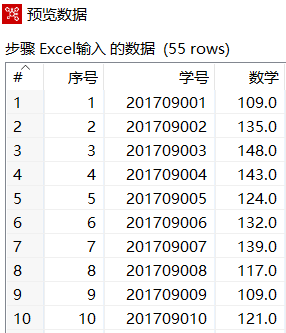
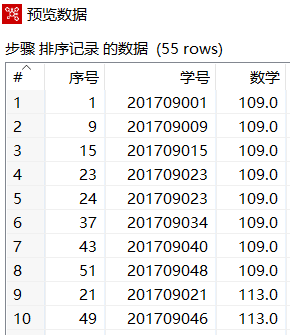
从上图可以看出"数学"字段数据处于无序状态
1.2 设置【排序记录】组件参数
在【排序记录】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【排序记录】组件,并拖曳至右边工作区中

由【Excel输入】组件指向【排序记录】组件,建立节点连接(长按shift键并点击鼠标左键在两者间进行连接),如下图所示
双击【排序记录】组件,弹出【排序记录】对话框,如下图所示
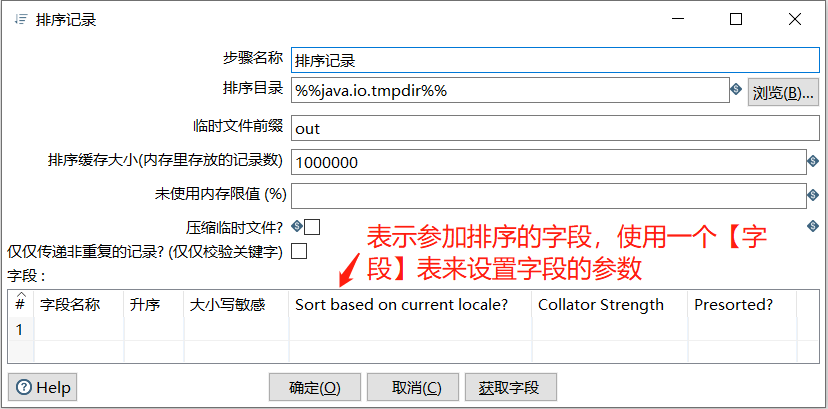
【排序记录】对话框中的参数说明如下表所示
| 字段参数 | 说明 |
| 步骤名称 | 表示排序组件名称,在单个转换工程中,名称必须唯一 默认值是【排序记录】组件名称 |
| 排序目录 | 表示排序时存放临时文件的目录,可以直接键盘设置,也可以单击【浏览(B)…】按钮,设置为计算机上已存在的目录 默认值是当前系统标准临时文件目录%%java.io.tmpdir%% |
| 临时文件前缀 | 表示临时文件前缀名称,排序时使用临时文件,可以加快和方便排序。当行数超过指定的排序大小时候,系统将使用临时文件排序行。默认值为out |
| 排序缓存大小 | 表示存放在内存的记录数,存储在内存中的记录越多,排序过程就越快。默认值为1000000 |
| 未使用内存限值(%) | 表示未使用内存的百分比限值。排序时,如果发现可用的空闲内存少于指定的数字,系统会将数据分页到磁盘。默认值为空 |
| 压缩临时文件 | 表示需要临时文件来完成排序时,是否压缩该临时文件。默认值为空 |
| 仅仅传递非重复的记录 | 表示是否启用仅向输出流传递唯一的记录。默认值为空 |
| 字段名称 | 指定排序的字段名称,可用多个字段进行组合排序。可以直接键盘输入,也可以单击输入框,从下拉框中选中输入流的字段 还可以点击对话框中的【获取字段】按钮,获取所有字段进行编辑,保留需要排序的关键字段,删除不参加排序的字段 |
| 升序 | 对指定的字段制订排序方向(升序/降序),选项有:是、否 |
| 大小写敏感 | 指定的排序时是否区分大小写,选项有:是、否 |
| Sort base on current locale? | 是否根据当前位置排序,选项有:是、否 |
| Collator Strength | 指定排序器强度,选项有:0、1、2、3 |
| Presorted? | 是否进行预排序,选项有:是、否 |
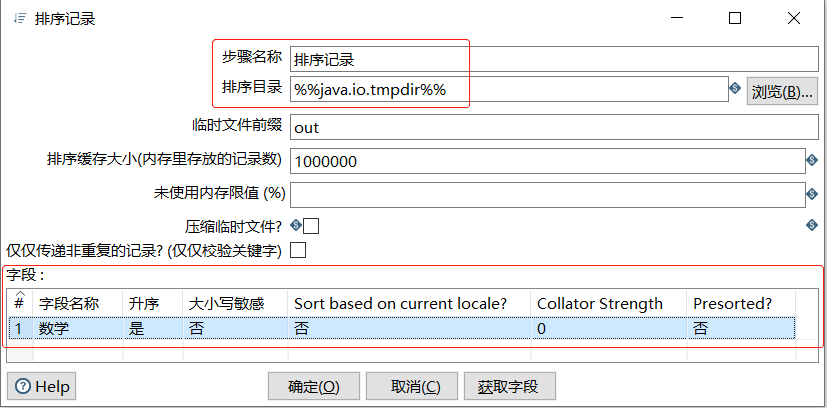
在【排序目录】对话框中,设置参数,将"数学"字段的数据按照从低到高进行排序,步骤如下
(1) 确定组件名称,【步骤名称】参数保留默认值"排序记录"
(2) 确定排序目录,【排序目录】参数保留默认值"%%java.io.tmpdir%%"
(3) 设置排序字段参数,在【字段】表中,对各字段的参数进行设置
此时完成【排序目录】组件参数的设置,如下图所示
1.3 预览结果数据
在【排序记录】排序工程中,单击【排序记录】组件,再单击工作区上方的"预览这个转换"图标
预览数据,展示排序后的数据,如下图所示
2.去除重复记录
由于输入或其他错误的原因,数据文件中可能出现两条或多条数据完全相同的记录,这些相同的记录称为重复记录
重复的记录属于"脏数据",会造成数据统计和分析不正确,必须清洗掉重复记录
数据源
期考成绩(Kettle数据集4).xls![]() https://download.csdn.net/download/Hudas/88527254?spm=1001.2014.3001.5501需求:由于在"期考成绩.xls"文件中,发现存在序号不同,但是学号、各科考试成绩完全相同的记录,所以需要使用【去除重复记录】组件,去除这些重复的数据
https://download.csdn.net/download/Hudas/88527254?spm=1001.2014.3001.5501需求:由于在"期考成绩.xls"文件中,发现存在序号不同,但是学号、各科考试成绩完全相同的记录,所以需要使用【去除重复记录】组件,去除这些重复的数据
2.1 建立【去除重复记录】转换工程
在去除重复记录(去重)之前,必须使用关键字段对数据记录进行排序,确定哪些记录属于重复记录
使用Ctrl+N快捷键,创建【去除重复记录】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"期考成绩.xls"文件,接着创建【排序记录】组件,并由【Excel输入】组件指向【排序记录】组件,建立节点连接,如下图所示
双击【排序记录】组件,对"学号"字段按照升序进行排序后预览数据
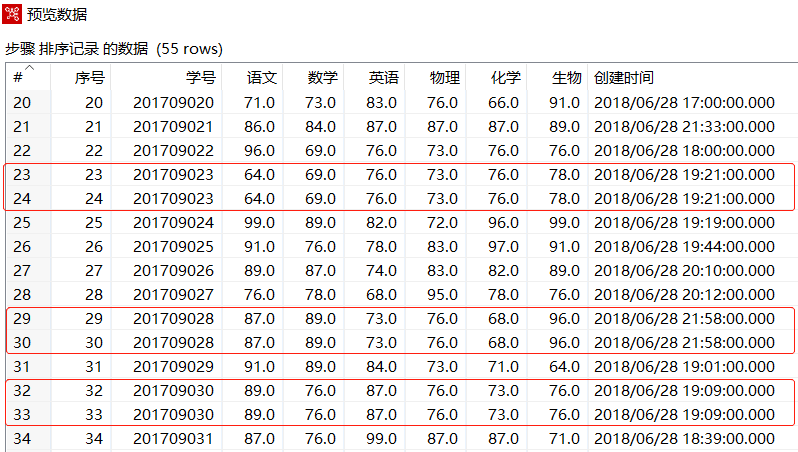
如上图所示,除了"序号"字段数据外,"学号"分别为"201709023","201709028","201709030"的数据各有两条记录,并且对应的"语文""数学"等考试科目和"创建时间"的数据也相同
2.2 设置【去除重复记录】组件参数
在【去除重复记录】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【去除重复记录】组件,并拖曳至右边工作区中,并由【排序记录】组件指向【去除重复记录】组件,建立节点连接,如下图所示
双击【去除重复记录】组件,弹出【去除重复记录】对话框,如下图所示
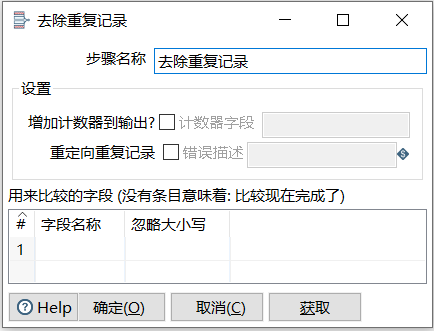
【去除重复记录】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| 步骤名称 | 表示去除重复组件名称,在单个转换工程中,名称必须唯一 默认值是【去除重复记录】的组件名称 |
| 增加计数器到输出 | 表示选择此选项时,计数器计算重复记录的条数,并将计数器字段添加至输出流中 选择后才能设置【计数器字段】参数名称 默认值为空 |
| 计数器字段 | 表示对重复记录计数的计数器字段名称,【增加计数器到输出】勾选时才能设置 默认值为空 |
| 重定向重复记录 | 表示选择此选项时,将重复的记录作为错误处理并将其重定向到组件的错误流。如果不选择,重复的记录将被删除。选择后才能编辑【错误描述】内容,内容是指当组件检测到重复记录时显示的错误处理描述 默认值为空 |
| 错误描述 | 表示对出现重复记录现象的内容描述,【重定向重复记录】为√ 时才能设置。默认值为空 |
| 用来比较的字段 | 表示用来比较是否重复记录的字段,用来比较的字段可以有多个,用一个表来分行设置不同的字段参数,字段参数如下: 字段名称:用来比较的字段,默认值为空 忽略大小写:比较字段是否区分大小写,选项有Y、N,默认值为空 |
在【去除重复记录】对话框中,设置参数,去除学号相同的记录,步骤如下
(1) 确定组件名称,【步骤名称】参数保留默认值"去除重复记录"
(2) 确定计数器字段,【增加计数器到输出】设置为"√",【计数器字段】设置为"重复行数"
(3) 确定错误描述,【重定向重复记录】设置为"√",【错误描述】设置为"重复输入"
(4) 设置用来比较的字段参数,在【用来比较的字段】表中,【字段名称】设置为"学号",【忽略大小写】设置为"N"
此时完成【去除重复记录】组件参数的设置,如下图所示

2.3 预览结果数据
在【去除重复记录】转换工程中,单击【去除重复记录】组件,再单击工作区上方的"预览这个转换"图标,即可预览去除重复记录后的数据,如下图所示
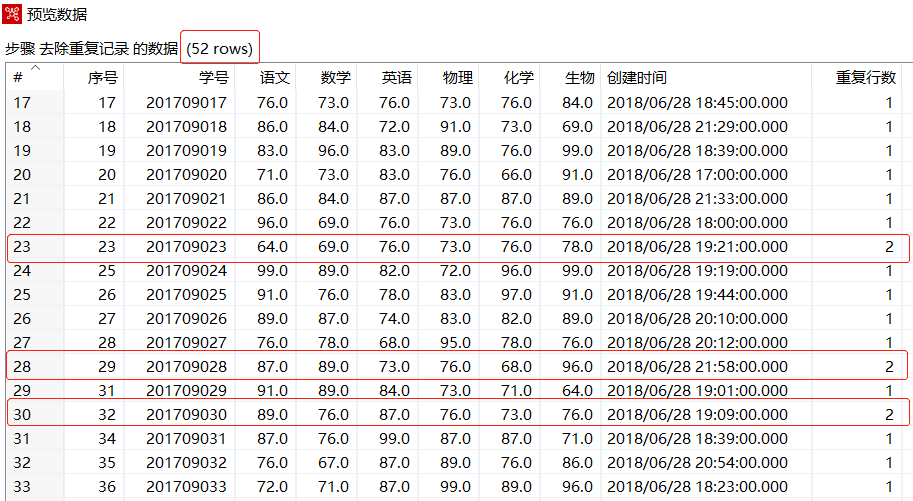
从上图可以看出原先有55行数据记录,删除了重复的3条记录以后,还剩下52条数据记录
3.替换NULL值
在Kettle转换过程中,默认情况下,会将空值当作NULL值处理
如果数据类型字段出现NULL值,那么在计算时就会出现错误
数据源
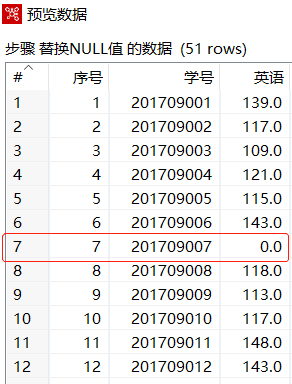
2019年11月月考英语成绩(Kettle数据集6).xls![]() https://download.csdn.net/download/Hudas/88530387?spm=1001.2014.3001.5501需求:学号为"201709007"的同学没有参加考试,根据规定考试分数将按零分处理,需要使用【替换NULL值】组件,使用"0"替换该同学的英语考试分数
https://download.csdn.net/download/Hudas/88530387?spm=1001.2014.3001.5501需求:学号为"201709007"的同学没有参加考试,根据规定考试分数将按零分处理,需要使用【替换NULL值】组件,使用"0"替换该同学的英语考试分数
3.1 建立【替换NULL值】转换工程
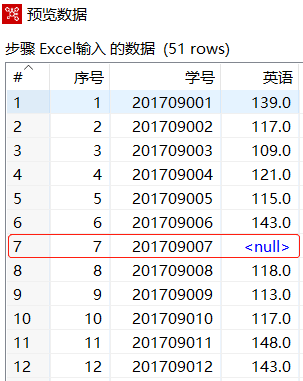
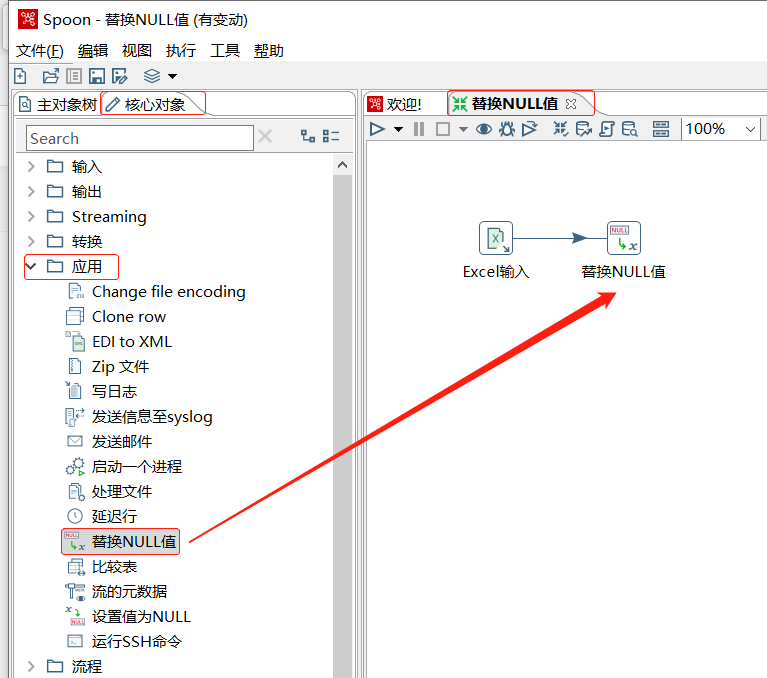
使用Ctrl+N快捷键,创建【替换NULL值】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"2019年11月月考英语成绩.xls"文件,预览数据,"学号"字段数据为"201709007"所对应的"英语"字段数据为<null>,如下图所示
在【替换NULL值】转换工程中,单击【核心对象】选项卡,展开【应用】对象,选中【替换NULL值】组件,并拖曳至右边工作区中,由【Excel输入】组件指向【替换NULL值】组件,建立节点连接,如下图所示
3.2 设置【替换NULL值】组件参数
双击【替换NULL值】组件,弹出【替换NULL值】对话框,如下图所示
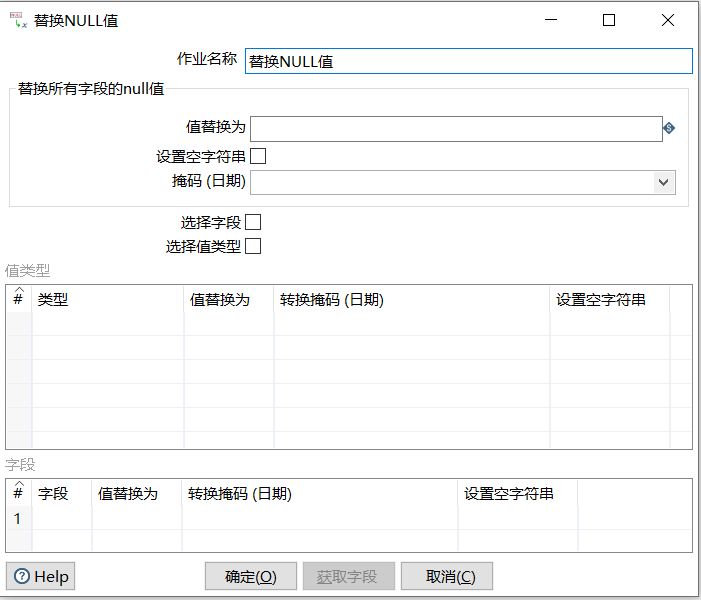
【替换NULL值】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| 作业名称 | 表示【替换NULL值】组件名称,在单个转换工程中,名称必须唯一,默认值是【替换NULL值】组件名称 |
| 选择字段 | 表示对所有记录的、指定字段的NULL值进行值替换的方式,默认值为空 |
| 选择值类型 | 表示对所有记录、指定的数据类型的NULL值进行替换的方式,默认值为空 |
| 替换所有字段的null值 | 表示对所有记录、所有字段的NULL值进行替换方式,默认的替换方式,具体如下 ① 值替换为:表示用来替换NULL的值,默认值为空 ② 设置空字符串:表示是否设置空字符串,默认值为空 ③ 掩码(日期):表示日期字段的掩码格式,默认值为空 |
| 字段 | 表示勾选【选择字段】参数后,使用【字段】表设置参数,具体如下 |
| 值类型 | 表示勾选【选择值类型】参数后,使用【值类型】表设置参数,具体如下 ① 类型:表示选中数据类型,单击下拉框选择设置 ② 值替换为:表示要替换NULL的值 ③ 转换掩码(日期):表示日期字段的掩码格式,默认值为空 ④ 设置空字符串:表示是否设置空字符串,选项有:是、否,默认值为空 |
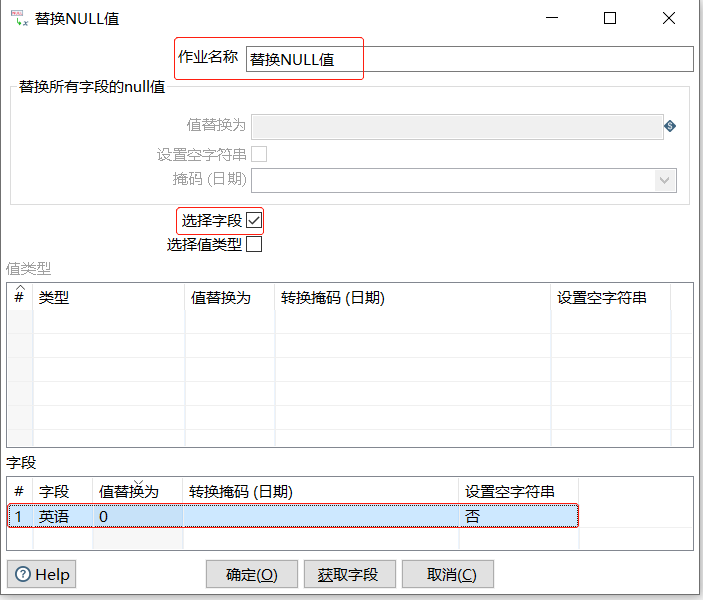
在【替换NULL值】对话框中,设置参数,用"0"替换"英语"字段的数据"null",步骤如下
(1) 确定组件名称,【步骤名称】参数保留默认值"替换NULL值"
(2) 选择【选择字段】方式设置字段参数,【选择字段】设置为"√",并在【字段】表中,对字段的参数进行设置
此时完成【替换NULL值】组件参数的设置,如下图所示
3.3 预览结果数据
在【替换NULL值】转换工程中,单击【替换NULL值】组件,再单击工作区上方的"预览这个转换"图标,预览替换NULL值后的数据,如下图所示
4.过滤记录
在数据处理时,往往要对数据所属类别、区域和时间等进行限制,将限制范围外的数据过滤掉
数据源
2019年10月年级月考数学成绩(Kettle数据集7).xls![]() https://download.csdn.net/download/Hudas/88530845?spm=1001.2014.3001.5501
https://download.csdn.net/download/Hudas/88530845?spm=1001.2014.3001.5501
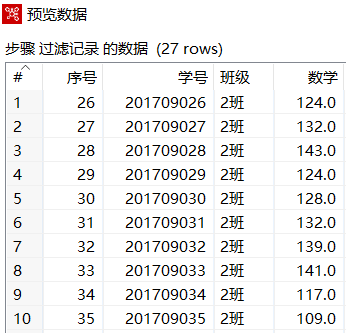
需求:为了统计2班的考试人数和成绩,需要对"2019年10月年级月考数学成绩.xls"文件,使用【过滤记录】组件,过滤掉不是2班的数据
4.1 建立【过滤记录】转换工程
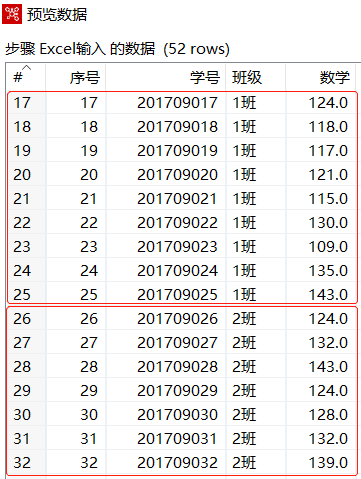
使用Ctrl+N快捷键,创建【过滤记录】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"2019年10月年级月考数学成绩.xls"文件,预览数据,如下图所示,文件包括有1班、2班的数据
在【过滤记录】转换工程中,单击【核心对象】选项卡,展开【流程】对象,选中【过滤记录】组件,并拖曳至右边工作区中,由【Excel输入】组件指向【过滤记录】组件,建立节点连接,如下图所示
4.2 设置【过滤记录】组件参数
双击【过滤记录】组件,弹出【过滤记录】对话框,如下图所示

【过滤记录】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| 步骤名称 | 表示【过滤记录】组件名称,在单个转换工程中,名称必须唯一,默认值为【过滤记录】组件名称 |
| 发送true数据给步骤 | 表示当条件为true时,记录被发送到此组件(步骤)。此参数也可以在与下一个组件(步骤)进行节点连接时设置,默认值为空 |
| 发送false数据给步骤 | 表示当条件为false时,记录被发送到此组件(步骤)。此参数也可以在与下一个组件(步骤)进行节点连接时设置,默认值为空 |
| 条件 | 表示过滤条件的表达式,在【条件】表达式输入框中设置表达式中各个参数,默认值为空 |
条件表达式
条件表达式是由函数(运算符)构成的一个赋值语句
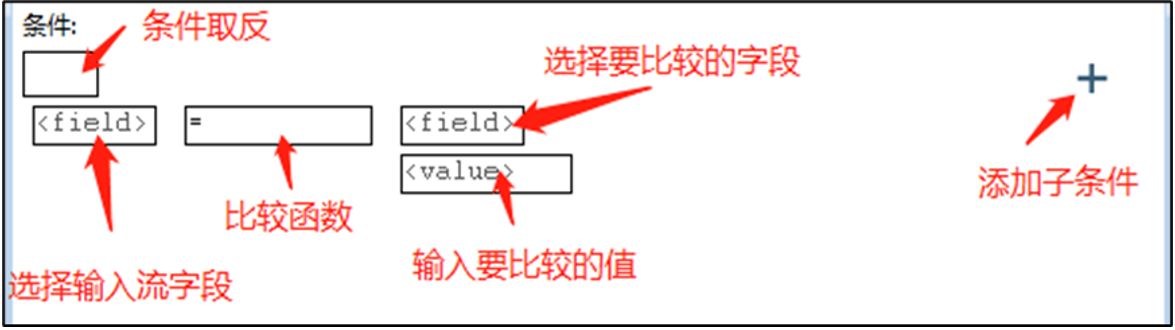
格式:<字段><函数><表达式>
格式的中间为函数,左边为字段,右边是值表达式,如a=5、a>(b+2)、a<=10等
为了方便读者理解,在【条件】表达式输入框中,增加了条件表达式设置的指向说明,如下图所示
增加子条件
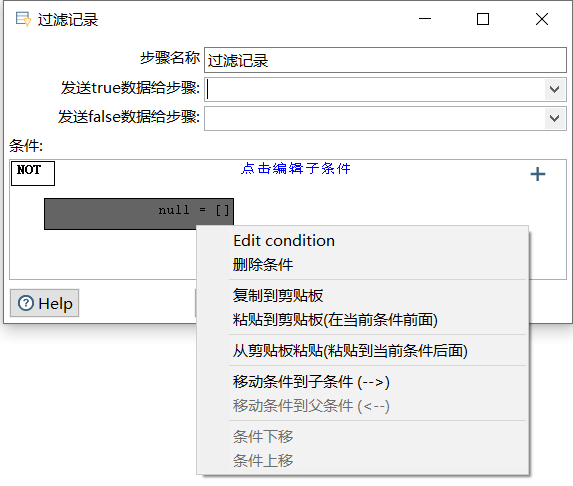
单击+号图标可以增加子条件,这时在【条件】表达式输入框中,显示出增加的条件表达式,初次生成的是一条null=[ ]的空表达式,如下图所示
单击null=[ ]空表达式,可对该表达式进行设置,如下图所示,单击"向上"按钮可以向上切换回条件表达式
右键单击子条件表达式,弹出右键快捷菜单,可以对子条件进行编辑、删除、复制、粘贴、移动位置等操作,如下图所示
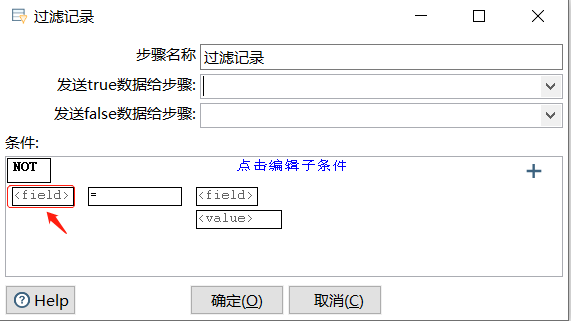
选择输入流的字段
单击"选择输入流字段"指向的【<field>】字段输入框,弹出【字段】对话框,列出输入流字段表,选择需要过滤的字段
选择函数
单击【=】函数输入框,弹出【函数】对话框,并列出过滤比较函数,有关过滤比较函数的说明如表所示
函数名称 说明 = 表示等于,判断表达式字段是否等于右边的值,是比较【函数】默认值 <> 表示不等于,判断表达式字段是否不等于右边的值 < 表示小于,判断表达式字段是否小于右边的值 <= 表示小于等于,判断表达式字段是否小于等于右边的值 > 表示大于,判断表达式字段是否大于右边的值 >= 表示大于等于,判断表达式字段是否大于等于右边的值 REGEXP 表示正则表达式,判断表达式字段是否与模式匹配 IS NULL 表示为空,判断表达式字段是否为空 IS NOT NULL 表示不为空,判断表达式字段是否不为空 IN LIST 表示在列表中,判断表达式字段是否在指定的list列表中 CONTAINS 表示包含,判断表达式字段是否包含右边的值 STARTS WITH 表示以什么开始,判断表达式字段是否以右边的值开始 ENDS WITH 表示以什么结束,判断表达式字段是否以右边的值结束 LIKE 表示包括,判断表达式字段是否包括右边的值 TRUE 表示真,判断表达式字段是否为真
选择比较字段
单击"选择要比较的字段"指向的【<field>】字段输入框,弹出类似的【字段】对话框,选中要比较的字段,单击【确定】按钮,确定要比较的字段
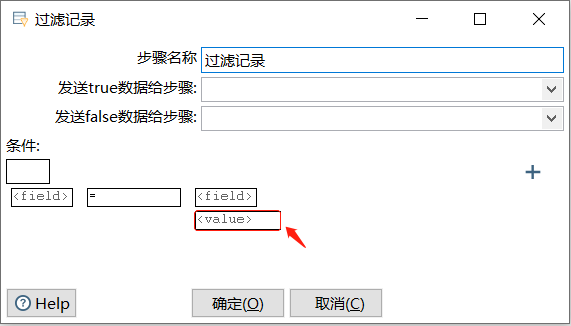
输入比较的值
单击"输入要比较的值"指向的【<value>】值输入框,弹出【E输入一个值】对话框,输入比较的值
有关【E输入一个值】对话框中的参数的说明如下表所示
参数名称 说明 类型 表示值的类型(默认值为String)
类型选项有:BigNumber、Binary、Boolean、Date、Integer、Internet Address、Number、String、Timestamp
值 表示值,可以是具体值或表达式,默认值为1 转换格式 表示值的转换格式,默认值为空 长度 表示值的长度,默认值为-1 精度 表示值的精度,默认值为-1
提示Tips:需要注意,若设置"输入要比较的值"指向的【<value>】值参数,则不能设置"选择要比较的字段"指向的【<field>】字段参数,二者只能选其一
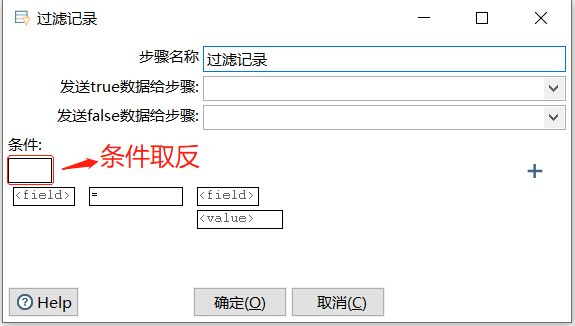
条件取反
鼠标移向 "条件取反"指向的输入框,显示出黑底红字的"NOT",单击该输入框并移开鼠标,此时显示为白底黑字的"NOT",表示条件取反,即若表达式为True,则条件为False
若表达式为False,则条件为True
"条件取反"指向的输入框为一个奇偶输入框,单击取反,再次单击则取正





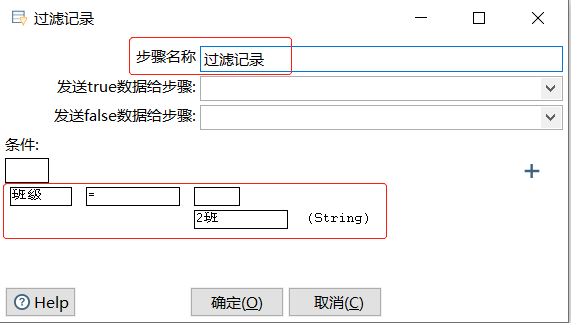
在【过滤记录】对话框中,设置参数,过滤掉不是2班的数据,步骤如下
(1) 确定组件名称,【步骤名称】参数保留默认值"过滤记录"
(2) 在【条件】表达式输入框中设置表达式中各个参数
① 单击左边的【<field>】字段输入框,弹出【字段】对话框,列出输入流字段表,选择需要过滤的字段,选中"班级"字段
② 单击 "比较函数"指向的【=】函数输入框,弹出【函数】对话框,选择"="的过滤比较函数,单击【确定】按钮,确认过滤比较函数
③ 单击【<value>】输入框,弹出【E输入一个值】对话框,对参数进行设置
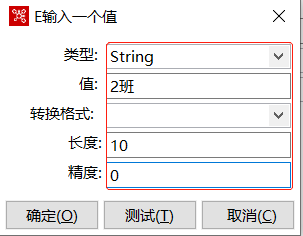
此时完成【过滤记录】组件参数的设置,如下图所示
4.3 预览结果数据
在【过滤记录】转换工程中,单击【过滤记录】组件,再单击工作区上方的"预览这个转换"图标,预览过滤记录后的数据,如下图所示
5.值映射
在数据处理系统中,为了加快处理速度、减少内存和存储空间消耗,往往使用数字、字母,或它们的组合表示真实的数据涵义,例如,用"1"和"0"分别表示性别,难以直接看懂
数据源
学籍信息(Kettle数据集8).xls![]() https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:在某校学生的"学籍信息.xls"文件中,性别字段数据分别用"1"或"0"表示。为了更加直观,一目了然地读懂学生的学籍信息,需要使用【值映射】组件,还原其对应的值"男"或"女"
https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:在某校学生的"学籍信息.xls"文件中,性别字段数据分别用"1"或"0"表示。为了更加直观,一目了然地读懂学生的学籍信息,需要使用【值映射】组件,还原其对应的值"男"或"女"
5.1 建立【值映射】转换工程
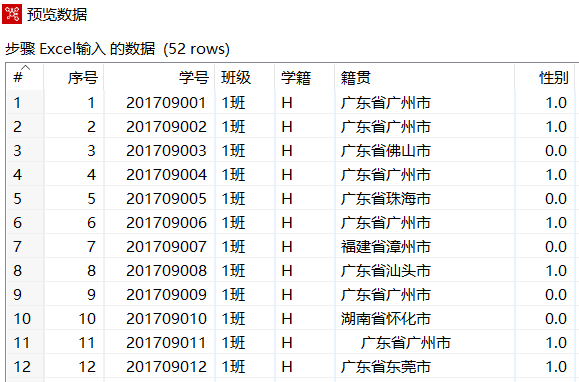
使用Ctrl+N快捷键,创建【值映射】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"学籍信息.xls"文件,预览数据,如下图所示,当前数据中,"性别"字段的数据,以"0.0"或"1.0"表示
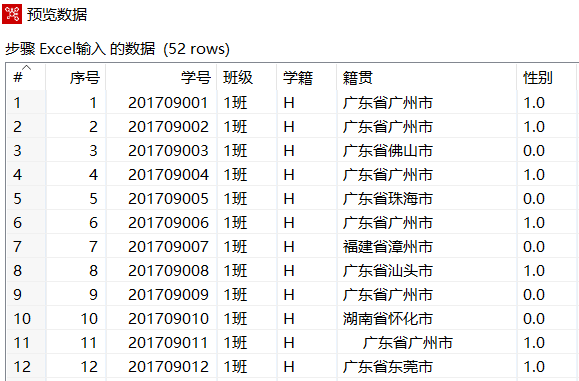
注意:博主在这边将"性别"字段类型设置成String
在【值映射】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【值映射】组件,并拖曳至右边工作区中,由【Excel输入】组件指向【值映射】组件,建立节点连接,如下图所示
5.2 设置【值映射】组件参数
双击【值映射】组件,弹出【值映射】对话框,如下图所示
【值映射】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| 步骤名称 | 表示【值映射】组件名称,在单个转换工程中,名称必须唯一。默认值是【值映射】组件名称 |
| 使用的字段名 | 表示需要进行值映射的输入流字段名称。默认值为空 |
| 目标字段名 | 表示进行值映射后输出流新字段名称,为空时覆盖原来字段。默认值为空 |
| 不匹配时默认值 | 表示不匹配字段值数据时的默认值。默认值为空 |
| 字段值 | 表示需要进行值映射的字段值参数表,使用【字段值】表设置参数,有关参数如下 |
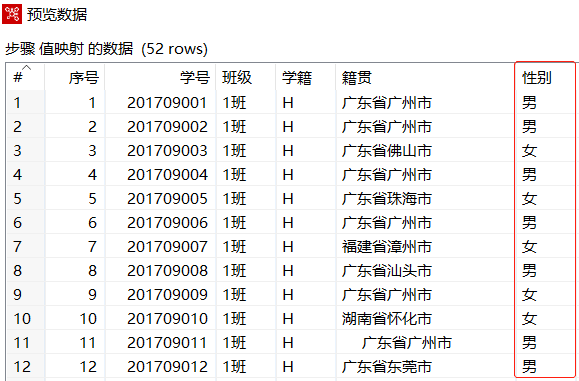
将"性别"字段中"1.0","0.0"数据分别用"男","女"映射替换,对参数进行设置
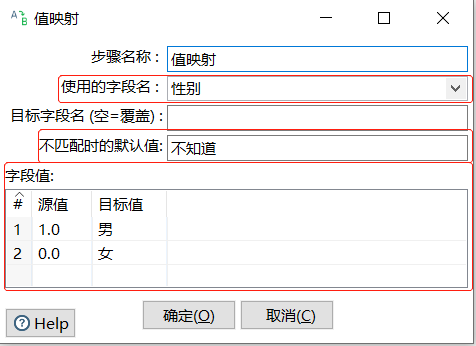
此时完成【值映射】组件参数的设置
5.3 预览结果数据
在【值映射】转换工程中,单击【值映射】组件,再单击工作区上方的"预览这个转换"图标,预览值映射后的数据,如下图所示
6.字符串替换
字符串替换与值映射非常类似,不同之处,字符串替换的字段值是字符串,值映射的字段可以是多种数据类型
数据源
学籍信息(Kettle数据集8).xls![]() https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:由于在"学籍信息.xls"文件中,学籍数据用"H"或"J"表示,需要使用【字符串替换】组件,分别还原其对应的值"户籍生"和"借读生"
https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:由于在"学籍信息.xls"文件中,学籍数据用"H"或"J"表示,需要使用【字符串替换】组件,分别还原其对应的值"户籍生"和"借读生"
6.1 建立【字符串替换】转换工程
使用Ctrl+N快捷键,创建【字符串替换】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"学籍信息.xls"文件,预览数据,如下图所示,当前数据中,"学籍"字段的数据,以"H"或"J"表示
在【字符串替换】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【字符串替换】组件,并拖曳至右边工作区中,由【Excel输入】组件指向【字符串替换】组件,建立节点连接,如下图所示

6.2 设置【字符串替换】组件参数
双击【字符串替换】组件,弹出【字符串替换】对话框,如下图所示

【字符串替换】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| 步骤名称 | 表示【字符串替换】组件名称,在单个转换工程中,名称必须唯一。默认值是【字符串替换】组件名称 |
| 字段 | 表示对将要进行字符串替换的字段参数,使用一个【字段】表对字段参数进行设置 |
| 输入流字段 | 表示要进行字符串替换的输入流字段。默认值为空 |
| 输出流字段 | 表示进行字符串替换后的输出流新字段,为空时覆盖原来要进行替换的输入流字段,默认值为空 |
| 使用正则表达式 | 表示是否使用正则表达式,选项有:Y、N。默认值为空 |
| 搜索 | 表示是否搜索此字符串的匹配值,默认值为空 |
| 使用…替换 | 表示要替换匹配值的字符串数据,默认值为空 |
| 设置为空串? | 表示是否设置空字符串,选项有:Y、N。默认值为空 |
| 使用字段值替换 | 表示使用一个字段值替换字符串,默认值为空 |
| 整个单词匹配 | 表示是否要整个单词都匹配,选项有:Y、N。默认值为空 |
| 大小写敏感 | 表示是否区分大小写,选项有:Y、N。默认值为空 |
| In Unicode | 表示是否设置Unicode,选项有:Y、N。默认值为空 |
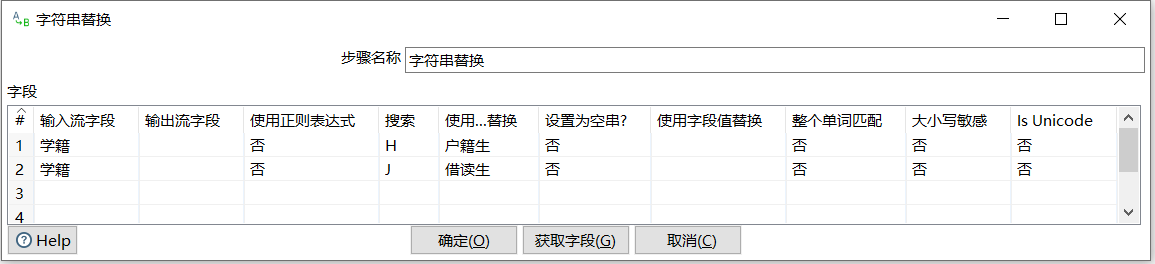
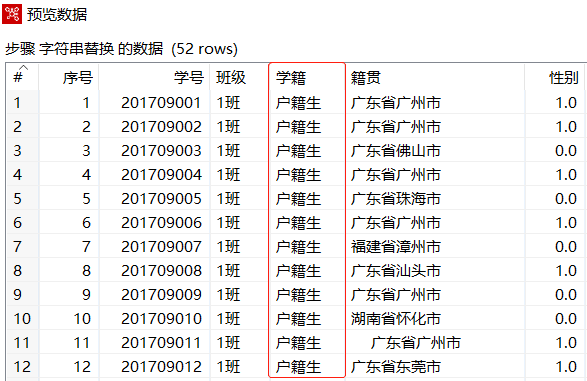
在【字符串替换】对话框中,设置参数,对输入数据中"学籍"字段中数据"H"和"J",分别使用"户籍生"和"借读生"进行替换,步骤如下
(1) 确认组件名称,【步骤名称】保留默认值,设置为"字符串替换"
(2) 确定字段参数,对【字段】表的参数进行设置
此时完成【字符串替换】组件参数的设置,如下图所示
6.3 预览结果数据
在【字符串替换】转换工程中,单击【字符串替换】组件,再单击工作区上方的"预览这个转换"图标,预览字符串替换后的数据,如下图所示
7.字符串操作
在数据输入过程中,有时候不小心输入的多余的空格、错误的字符等,字符串操作是指将数据中不需要的字符处理掉
数据源
学籍信息(Kettle数据集8).xls ![]() https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:在“学籍信息.xls”文件中,学生学籍信息的籍贯字段数据前后有多余的空格,需要使用【字符串操作】,去除这些空格,规范学籍信息
https://download.csdn.net/download/Hudas/88533475?spm=1001.2014.3001.5501需求:在“学籍信息.xls”文件中,学生学籍信息的籍贯字段数据前后有多余的空格,需要使用【字符串操作】,去除这些空格,规范学籍信息
7.1 建立【字符串操作】转换工程
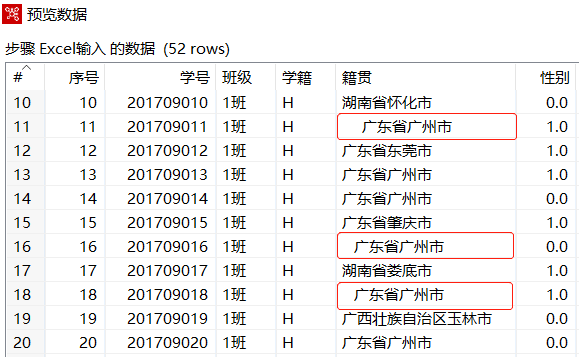
使用Ctrl+N快捷键,创建【字符串操作】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"学籍信息.xls"文件,预览数据,如下图所示,当前数据中,"籍贯"字段有一些数据前面存在空格
在【字符串操作】转换工程中,单击【核心对象】选项卡,展开【转换】对象,选中【字符串操作】组件,并拖曳至右边工作区中,由【Excel输入】组件指向【字符串操作】组件,建立节点连接,如下图所示
7.2 设置【字符串操作】组件参数
双击【字符串操作】组件,弹出【String operations】对话框,如下图所示

【字符串操作】组件的有关参数说明如下表所示
| 参数名称 | 说明 |
| Step name | 表示【字符串操作】组件名称,在单个转换工程中,名称必须唯一 默认值是【字符串操作】组件名称 |
| In stream field | 表示输入流中要进行字符串操作字段名称,可以单击【Get fields】按钮,获取字段名称 默认值为空 |
| Out stream field | 表示输出流目标字段,进行字符串操作后的目标字段,当为空时,覆盖原字段 默认值为空 |
| Trim type | 表示修剪处理的类型,选项有none、left、right、both 默认值为空 |
| Lower/Upper | 表示进行字母大小写处理,选项有none、lower、upper 默认值为空 |
| Padding | 表示填充处理,选项有none、left、right 默认值为空 |
| Pad char | 表示使用填充字符处理,输入要填充的字符 默认值为空 |
| Pad Length | 表示填充的长度,输入要填充的长度 默认值为空 |
| InitCap | 表示是否初始化,选项有是、否 默认值为空 |
| Escape | 表示转义或取消XML、HTML、CDATA和SQL等转义 默认值为空 |
| Digits | 表示对数字是返回删除,还是什么都不做,选项有none、only、remove 默认值为空 |
| Remove Special character | 表示删除特殊字符 默认值为空 |
在【String operations】对话框中,设置参数,删除"籍贯"字段数据中的空格,步骤如下
(1) 确定组件名称,【Step name】参数保留默认值"字符串操作"
(2) 设置字符串操作的字段参数,在【The fields to process】表中设置字段参数,在表第1行,单击【In stream field】输入框,在输入流字段中选中"籍贯"字段,单击【Trim type】输入框,在选项中选中"both",其他参数使用默认值
此时完成【字符串操作】组件参数的设置,如下图所示

7.3 预览结果数据
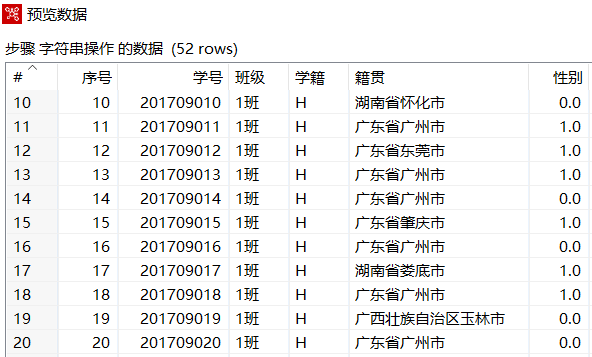
在【字符串操作】转换工程中,单击【字符串操作】组件,再单击工作区上方的"预览这个转换"图标,预览字符串操作后的数据,如下图所示
8.分组
在进行数据统计中,往往要对类别、区域、型号等范围进行统计,分组是对指定的字段或字段集合的数据进行分组统计
数据源
2019年10月月考英语成绩(Kettle数据集5).xls![]() https://download.csdn.net/download/Hudas/88529906?spm=1001.2014.3001.5501需求:为了解各班级和学生的学业情况,需要对"2019年10月月考英语成绩.xls"文件,使用【分组】组件,统计各班的人数和平均分数
https://download.csdn.net/download/Hudas/88529906?spm=1001.2014.3001.5501需求:为了解各班级和学生的学业情况,需要对"2019年10月月考英语成绩.xls"文件,使用【分组】组件,统计各班的人数和平均分数
8.1 建立【分组】转换工程
在分组之前,必须使用关键字段对数据记录进行排序,确定哪些记录分组在一起
使用Ctrl+N快捷键,创建【分组】转换工程,单击【核心对象】选项卡,展开【输入】对象,选中【Excel输入】组件,并拖曳到右边工作区中,设置参数,导入"2019年10月月考英语成绩.xls"文件,接着创建【排序记录】组件,并由【Excel输入】组件指向【排序记录】组件,建立节点连接,如下图所示
双击【排序记录】组件,对"班级"字段按照升序进行排序后预览数据

在【分组】转换工程中,单击【核心对象】选项卡,展开【统计】对象,找到【分组】组件,并拖曳到右边工作区中,并由【排序记录】组件指向【分组】组件,建立节点连接,如下图所示

8.2 设置【分组】组件参数
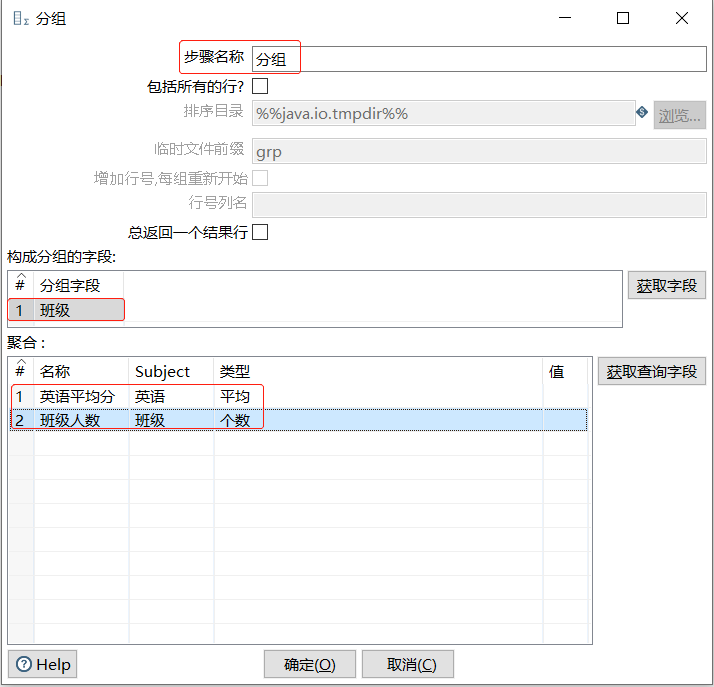
双击【分组】组件,弹出【分组】对话框,如下图所示

【分组】组件有关参数说明如下表所示
| 参数名称 | 说明 |
| 步骤名称 | 表示分组的组件名称,在单个转换工程中,名称必须唯一 默认值是【分组】的组件名称 |
| 包括所有的行 | 表示是否包括所有记录。使用勾选框设置参数,希望在输出中包含所有记录,则勾选,只想输出聚合记录,则不勾选 默认值为空 |
| 排序目录 | 表示指定存储临时文件的目录。分组的记录数超过5000个时,必须指定一个目录。此参数只有勾选【包括所有的行】参数后才能设置 默认值是系统的标准临时目录%%java.io.tmpdir%% |
| 临时文件前缀 | 表示命名临时文件的文件前缀,只有勾选【包括所有的行】参数后才能设置 默认值为grp |
| 添加行号,在每个组中重新启动 | 表示是否添加一个记录号,在每个组中从1重新启动。勾选此参数时所有记录都包含在输出中,且每个记录都有一个记录号。此参数终于勾选【包括所有的行】参数后才有效默认值为空 |
| 行号列名 | 表示要为每个新组添加记录的字段名称 默认值为空 |
| 总返回一个结果行 | 表示是否即使没有输入记录,也返回结果记录。当没有输入记录时,返回计数0。如果只想有输入时才输出结果记录,则此参数不勾选,默认值为空 |
| 构成分组的字段 | 表示分组的字段参数。分组的字段可以有多个,使用一个【构成分组的字段】表设置【分组字段】参数,可以设置多个分组字段。需要注意的是,如果没有分组的字段,那么该表留空来计算整个数据集的聚合函数 默认值为空 |
| 聚合 | 表示聚合字段的参数,使用一个【聚合】表来设置聚合字段名称、聚合方法和输出结果新字段名称 |
| 名称 | 表示聚合字段的名称,输出结果的新字段名称,默认值为空 |
| Subject | 表示对其使用聚合方法的对象字段,默认值为空 |
| 类型 | 表示聚合方法。在下拉框中选取聚合方法,默认值为空。聚合方法如下 11. 第一个值(包括null)) |
| 值 | 表示聚合的值,默认值为空 |
在【分组】对话框中,设置参数,分组统计各班的人数和平均分数,步骤如下
(1) 设置组件名称,【步骤名称】参数采用默认值"分组"
(2) 确定分组字段,在【构成分组字段】表的第1行,【分组字段】设置为"班级"
(3) 确定聚合字段并设置参数,对【聚合】表的参数进行设置
此时完成【分组】组件参数的设置,如下图所示
8.3 预览结果数据
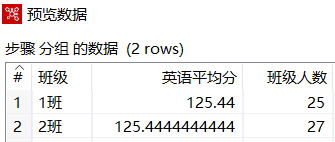
在【分组】转换工程中,单击【分组】组件,再单击工作区上方的"预览这个转换"图标,预览数据分组后的数据,如下图所示


![[修改Linux下ssh端口号]解决无法修改sshd_config无法修改](https://img-blog.csdnimg.cn/483de4d212464ea3bf227305857948bb.png)