1.3 经典自旋锁
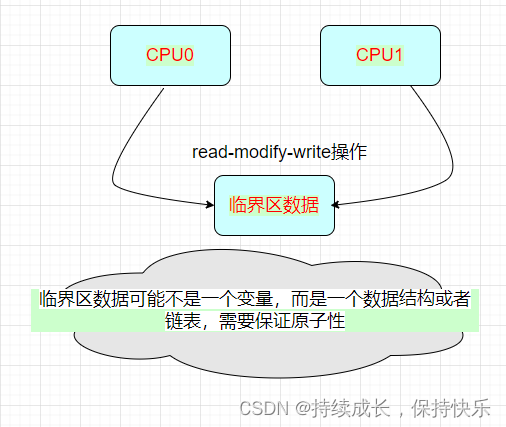
在实际项目中临界区数据有可能会修改一个数据结构或者链表中的数据,在整个过程中要保证原子性,才不会影响数据的有效性,这个过程使用原子变量不合适,需要使用锁机制来完成,自旋锁(spinlock)是linux内核中常见的锁机制。
自旋锁特性:
- 同一时刻只能被一个内核代码路径持有,另外的内核代码路径试图获取该锁需要一直忙等待,直到该自旋锁持有者释放该锁;
- 自旋锁持有者需尽快完成临界区的执行任务,否则会造成等待的CPU浪费,特别是自旋锁临界区里不能睡眠;
- 自旋锁可以在中断上下文中使用;
1.3.1 自旋锁的实现
下面展示的spinlock数据结构的定义。
<linux-5.15.73/include/linux/spinlock_types.h>/* Non PREEMPT_RT kernels map spinlock to raw_spinlock */
typedef struct spinlock {union {struct raw_spinlock rlock;#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))struct {u8 __padding[LOCK_PADSIZE];struct lockdep_map dep_map;};
#endif};
} spinlock_t;typedef struct raw_spinlock {arch_spinlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCKunsigned int magic, owner_cpu;void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} raw_spinlock_t;
早期的linux内核是使用一个简单的无符号类型的变量来表示是否持有锁,这样会带来一个问题,当前持有锁的代码路径刚刚释放,有可能又获取了该锁,这样对别的代码路径不公平,这样会导致整个系统的性能会差很多;
现在的spinlock都是“基于排队的FIFO”算法的自旋锁机制;

自旋锁的原型定义在include/linux/spinlock.h头文件中。
static __always_inline void spin_lock(spinlock_t *lock)
{raw_spin_lock(&lock->rlock);
}static inline void __raw_spin_lock(raw_spinlock_t *lock)
{preempt_disable();spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
看到实现,首先会调用preempt_disable()来关闭内核抢占,这是自旋锁实现的关键点之一。那么为什么自旋锁临界区中不允许发生抢占呢?
如果自旋锁临界区中允许抢占,假设在临界区内发生中断,中断返回时会检查抢占调度,这里将有两个问题:一是抢占调度会导致持有锁的进程睡眠,这违背了自旋锁不能睡眠和快速执行完成的设计语义;二是抢占调度进程也可能会申请自旋锁,这样会导致发生死锁。
<arch/arm/include/asm/spinlock.h>static inline void arch_spin_lock(arch_spinlock_t *lock)
{unsigned long tmp;u32 newval;arch_spinlock_t lockval;prefetchw(&lock->slock); // gcc 内置预取指令,指定读取到最近的缓存以加速执行__asm__ __volatile__(
"1: ldrex %0, [%3]\n" // lockval = &lock->slock
" add %1, %0, %4\n" // newval = lockval + 1 << 16,等于 lockval.tickets.next +1;
" strex %2, %1, [%3]\n" // 将 lock->slock = newval
" teq %2, #0\n" // 测试上一步操作的执行结果
" bne 1b" // 如果执行 lock->slock = newval 失败,则跳到标号 1 处从头执行: "=&r" (lockval), "=&r" (newval), "=&r" (tmp): "r" (&lock->slock), "I" (1 << TICKET_SHIFT): "cc");// 没进行 +1 操作前的 lockval.tickets.next 是否等于 lockval.tickets.owner// 不相等时,调用 wfe 指令进入 idle 状态,等待 CPU event,被唤醒后继续判断锁变量是否相等while (lockval.tickets.next != lockval.tickets.owner) { wfe();lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);}// 内存屏障 smp_mb();
}
从上述的注释中大概可以看出加锁的实现:
1、先将 spinlock 结构体中的 next 变量 + 1,不管是否能够获得锁
2、判断 +1 操作之前,next 是否等于 owner,只有在 next 与 owner 相等时,才能完成加锁,否则就循环等待,从这里也可以看到,自旋锁并不是完全地自旋,而是使用了 wfe 指令。
要完整地理解加锁过程,就必须要提到解锁,因为这两者是相对的,解锁的实现很简单:就是将 spinlock 结构体中的 owner 进行 +1 操作,因此,当一个 spinlock 初始化时,next 和 onwer 都为 0。某个执行流 A 获得锁,next + 1,此时在其它执行流 B 眼中,next != owner,所以 B 等待。当 A 调用 spin_unlock 时,owner + 1。
此时 next == owner,所以 B 可以欢快地继续往下执行,这就是加解锁的逻辑。
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{smp_mb();lock->tickets.owner++;dsb_sev();
}
1.3.2 自旋锁相关的API
觉得有必要先学习下自旋锁相关的有哪些接口可以使用,什么作用?
linux-5.15.73/include/linux/spinlock.h //可以看下该路径中包含所有的API
spin_lock_irqsave() 和 spin_unlock_irqrestore():类似于 spin_lock() 和 spin_unlock(),但同时会在获取锁时禁用本地中断,并在释放锁时恢复中断状态。这对于确保在关键区域内禁用中断以防止并发问题非常有用。spin_lock_bh() 和 spin_unlock_bh():类似于 spin_lock() 和 spin_unlock(),但同时会在获取锁时禁用软中断(bottom half),并在释放锁时恢复软中断状态。这对于确保在关键区域内禁用软中断以防止并发问题非常有用。spin_trylock_irqsave(), spin_trylock_bh() 等:类似于 spin_trylock(),但同时会在尝试获取锁时禁用中断或软中断。
注:软中断(bottom half)是一种处理机制,用于执行一些延迟敏感的任务,例如网络数据包处理、定时器处理等。软中断在适当的时机被触发,并在内核上下文中执行。由于软中断的执行可能与进程的执行并发进行,因此可能会引发并发访问的互斥问题。(比如中断下半部的softirq和tasklet)
spin_lock_irq 和spin_lock_irqsave区别?
答:spin_lock_irq 和 spin_lock_irqsave 都是用于在 Linux 内核中处理中断上半部的自旋锁函数,它们的区别在于对中断状态的处理方式:
spin_lock_irq 获取自旋锁的同时禁用本地CPU的中断响应。它不会保存当前的中断状态,因此在释放自旋锁后会恢复先前未知的中断状态。
spin_lock_irqsave 也会获取自旋锁并禁用本地CPU的中断响应,但它会在获取自旋锁之前保存当前的中断状态,并在释放自旋锁时根据保存的状态来恢复中断。这样可以确保在释放锁后,系统的中断状态与获取锁时一致。
1.3.3 自旋锁的变体spin_lock_irq()场景使用

假设如上图场景,CPU0正在通过ioctl或者read去处理链表来获取数据,突然中断来了,中断中也有获取锁及对链表数据的处理,就会导致死锁,这个时候就需要spin_lock_irq()或者spin_lock_irqsave()出场了。
spin_lock_irq()拿到锁时会禁止本地cpu中断,从而保证ioctl或者read的操作的原子性,因此也印证了spin_lock拿锁之后的临界区要尽可能的短和快(男人不喜欢,哈哈)。
可能有的读者会有疑问,既然关闭了本地CPU的中断,那么别的CPU依然可以响应外部中断,这会不会也可能导致死锁呢?
答:自旋锁持有者在CPU0上,CPU1响应了外部中断且中断处理程序同样试图去获取该锁,因为CPU0上的自旋锁持有者也在继续执行,所以它很快会离开临界区并释放锁,这样CPU1上的中断处理程序可以很快获得该锁。
在上述场景中,如果CPU0在临界区中发生了进程切换,会是什么情况?注意,进入自旋锁之前已经显式地调用preempt_disable()函数关闭了抢占,因此内核不会主动发生抢占。但令人担心的是,驱动编写者主动调用睡眠函数,从而发生了调度。使用自旋锁的重要原则是拥有自旋锁的临界区代码必须原子地执行,不能休眠和主动调度。但在实际项目中,驱动代码编写者常常容易犯错误。如调用分配内存函数kmalloc()时,可能因为系统空闲内存不足而进入睡眠模式,除非显式地使用GFP_ATOMIC分配掩码。
1.3.4 spin_lock()和raw_spin_lock()函数
若在一个项目中有的代码中使用spin_lock()函数,而有的代码使用raw_spin_lock()函数,并且spin_lock()函数直接调用raw_spin_lock()函数,这样可能会给读者造成困惑。
这要从Linux内核的实时补丁(RT-patch)说起。实时补丁旨在提升Linux内核的实时性,它允许在自旋锁的临界区内抢占锁,且在临界区内允许进程睡眠,这样会导致自旋锁语义被修改。当时内核中大约有10 000处使用了自旋锁,直接修改自旋锁的工作量巨大,但是可以修改那些真正不允许抢占和睡眠的地方,大概有100处,因此改为使用raw_spin_lock()函数。spin_lock()和raw_spin_lock()函数的区别如下。
在绝对不允许抢占和睡眠的临界区,应该使用raw_spin_lock()函数,否则使用spin_lock()。
因此对于没有更新实时补丁的Linux内核来说,spin_lock()函数可以直接调用raw_spin_lock(),对于更新实时补丁的Linux内核来说,spin_lock()会变成可抢占和睡眠的锁,这一点需要特别注意。
感谢学习,有疑问欢迎评论区交流。