一、ELK
1、介绍:
ELK 是一个用于日志管理和数据分析的开源工具栈,它由三个主要组件组成:
① Elasticsearch: Elasticsearch 是一个实时分布式搜索和分析引擎,作用是存储和检索大规模数据,Elasticsearch 支持实时索引更新,并支持高级的搜索和分析操作。
② Logstash: Logstash 是一个用于数据收集、转换和传输的数据管道工具。它能够从各种来源收集数据,对数据进行清洗、转换和标准化,然后将数据发送到 Elasticsearch 或其他存储和分析工具中。
③ Kibana: Kibana 是 ELK 的可视化工具,用于搜索、分析和可视化数据。它提供了用户友好的界面,通过 Kibana,用户可以创建仪表板、图表和可视化工具,以便深入探索和理解存储在 Elasticsearch 中的数据。
2、ELK 架构图:

二、Filebeat
1、介绍:
Filebeat 是一个开源的轻量级数据收集器,Filebeat 主要用于实时收集各种类型的日志数据,然后将其发送到不同目的地,如 Elasticsearch、Logstash、Kafka 等,以便进一步分析、存储和可视化这些数据。
● 收割机(Harvester):
收割机是 Filebeat 中的一个核心组件,负责监视和读取指定文件的内容。每个收割机负责监控一个文件,从文件的开头开始读取数据,然后逐行将数据提取为事件。收割机会不断监视文件,一旦到达文件末尾,收割机就会停止工作,等待文件有新内容写入时,它会继续从新内容开始读取。
● 事件(Event):
事件是 Filebeat 收集的数据的基本单元,通常是一行日志。这些事件包含了日志中的各种字段和元数据,以及其它相关信息。通常情况下,事件的数据以 JSON 格式进行组织,以便进行后续处理和分析。
2、Filebeat 配置:
(1) 安装 Filebeat
tar xzvf filebeat-7.13.2-linux-x86_64.tar.gz -C /usr/local/
mv /usr/local/filebeat-7.13.2-linux-x86_64 /usr/local/filebeat
(2) 编写 Filebeat 管理文件:
vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Wants=network‐online.target
After=network‐online.target
[Service]
ExecStart=/usr/local/filebeat/filebeat ‐c /usr/local/filebeat/filebeat.yml
Restart=always
[Install]
WantedBy=multi‐user.target
重载系统进程:systemctl daemon-reload
3、Filebeat 使用:
(1) Filebeat使用YAML配置文件进行设置和配置。
vim /usr/local/filebeat/filebeat.yml
① filebeat.inputs:
filebeat.inputs 部分通常包含一个或多个输入配置块,每个配置块定义了一个数据源,指示 Filebeat 从哪里收集日志。
● type:指定 Filebeat 收集的数据源的类型(log、json等);
● enabled:布尔值参数,用于控制该 input 是否启用。当设置为true时,表示启用该input,Filebeat 会按照该 input 的配置收集相应的数据 ;如果设置为false,则表示禁用该 input。
● paths:指定要收集的日志文件路径,可以使用通配符来匹配多个文件路径。

② filebeat.config.modules:
指定 Filebeat 要加载的模块配置文件的位置。
path: ${path.config}/modules.d/*.yml
path 指定了一个文件路径模式,表示 Filebeat 将加载 modules.d 目录下的所有 .yml 文件作为模块配置。
reload.enabled:当模块的配置文件有更新时,此程序是否要自动加载,false不加载,true 加载

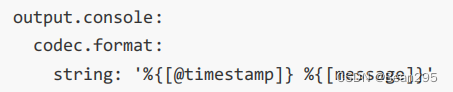
③ output.console
output.console:
pretty: true
output.console 用于指定Filebeat将日志输出到控制台
pretty 设置为 true 表示以更易读的格式输出日志数据。

④ processors:
processors 用于在事件发送之前定义一系列处理步骤对事件进行处理。
‐ add_host_metadata:用于向事件添加有关主机的元数据,例如主机名、IP地址、操作系统、容器ID等

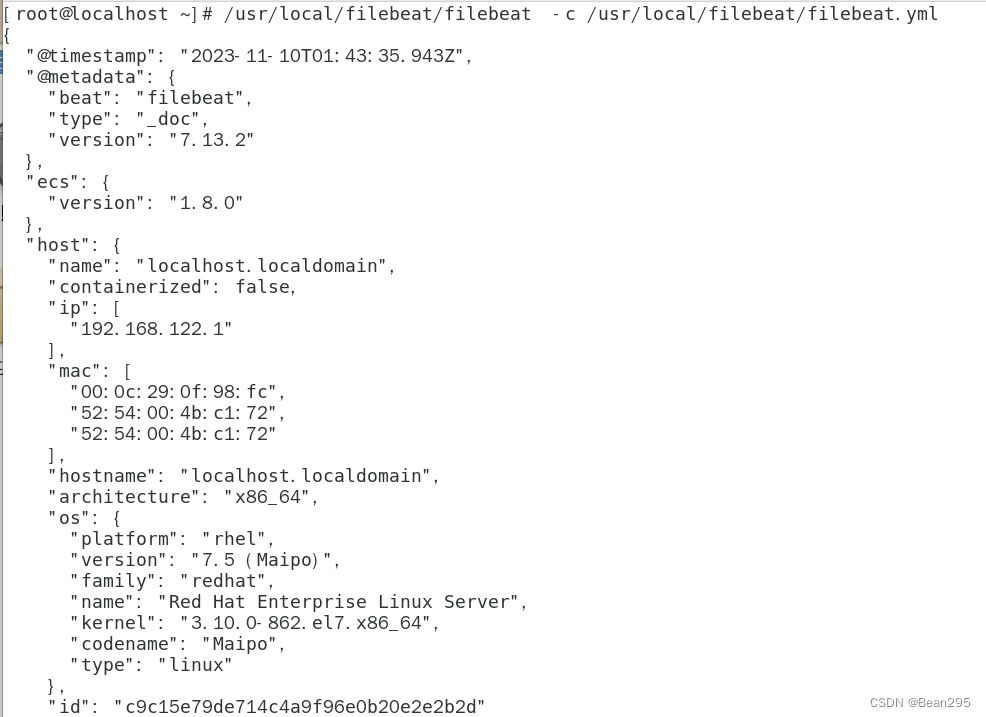
(2) 运行输出:
① 准备测试数据:

② 观察结果:
/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml
Filebeat的主程序文件的路径 ;指定Filebeat的配置文件路径
4、filebeat 专用日志搜集模块
(1) 概念:
Filebeat 专用日志搜集模块是 Filebeat 中的一种预配置选项,包含了关于特定日志源的配置,包括输入源、解析规则以及可选的额外配置,用于简化和加速特定类型日志的搜集和解析。

启用模块:/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml modules enable 模块名
禁用模块:/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml modules disable 模块名
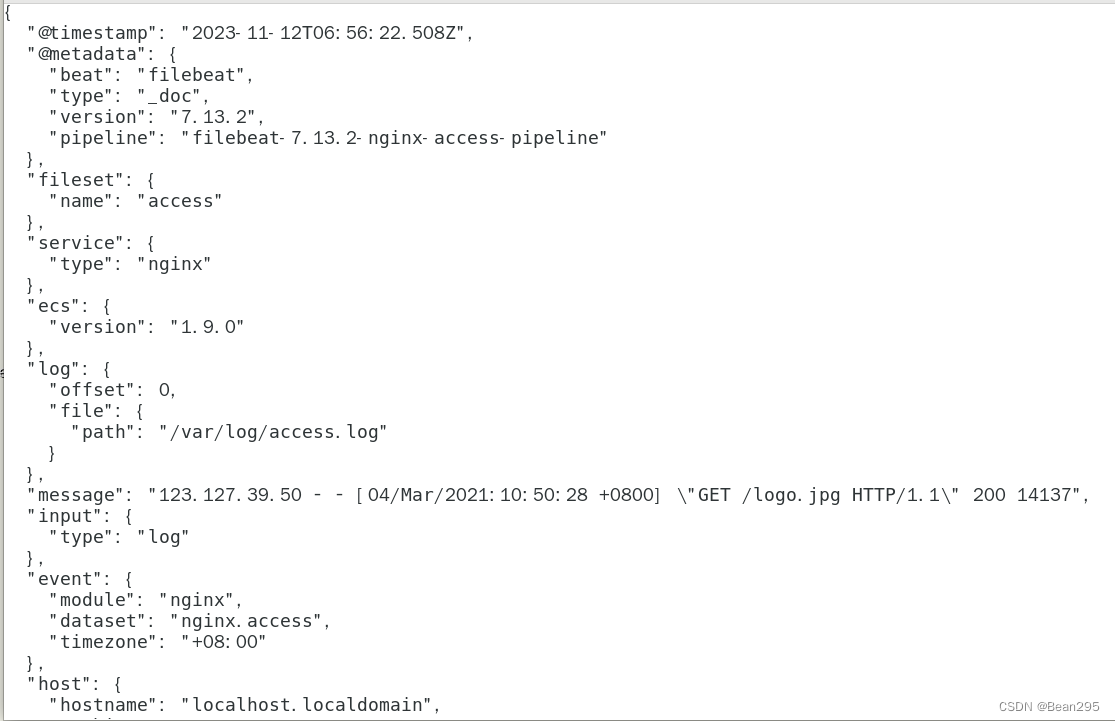
(2) 示例模块 (Nginx) :
vim /usr/local/filebeat/modules.d/nginx.yml

配置路径:
● nginx 模块搜集日志的默认路径:
/var/log/nginx/access.log* ;/var/log/nginx/error.log*
● 若搜集的日志真实路径和日志收集模块默认的路径不一致,可以对 var.paths: 进行配置。
示例:

或

注意:var.paths 指定的路径,会和模块默认路径合并到一起,即默认路径和指定路径都会进行日志收集。
调用模块进行测试:./filebeat -e
5、output 配置:
output 用于接收 Filebeat 所推送的日志。
① output 类型 (filebeat 运行时,output 只可配置其中一种):
console 终端屏幕
elasticsearch 存放日志,并提供查询
logstash 进一步对日志数据进行处理
kafka 消息队列
② 示例:输出完整Json数据中的某些字段
6、Processors 过滤和增强数据:
(1) 去除事件:
用正则表达式匹配以“DBG”开头的消息,匹配中去除此日志记录。

(2) 向输出的数据中添加某些自定义字段
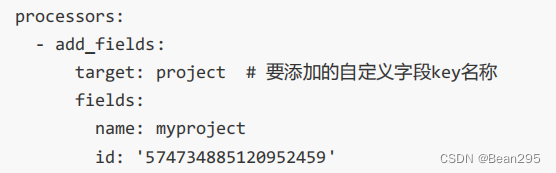
(3) 从事件中删除某些字段

三、Logstash
1、简介:
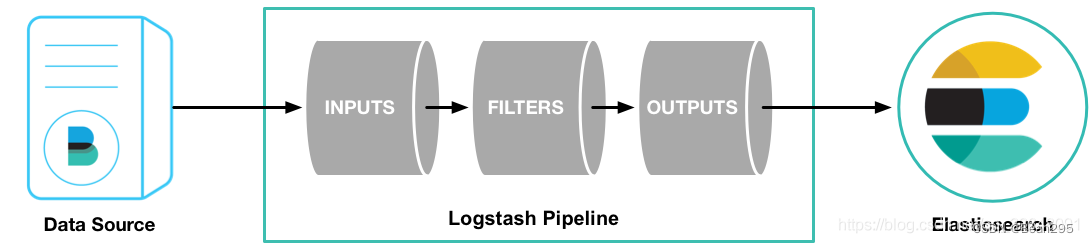
Logstash 是 Elastic Stack 中的一个组件,用于数据收集、转换和传输。它提供了一个灵活的数据流管道,可以从各种源头收集数据,对数据进行处理和转换,最终将数据发送到指定的目的地。
2、测试运行:
(1) Logstash 的主要特性和组成部分:
① 输入(Input): Logstash 可以从多种来源接收数据。内置的输入插件支持从文件、标准输入、网络流、数据库等各种源头收集数据。
② 过滤器(Filter): 过滤器用于对输入的数据进行处理、过滤和转换。Logstash 提供了多种内置过滤器插件,可以用于解析、标准化和丰富数据。
③ 输出(Output): 输出定义了 Logstash 处理后的数据的目的地。Logstash 支持将数据发送到各种存储和分析系统,如 Elasticsearch、Kafka 等。通过配置输出插件,用户可以将数据路由到一个或多个目标。
(2) 语法:
bin/logstash ‐e ' ' -e 选项用于设置 Logstash 处理数据的输入和输出
● 示例:
./logstash -e 'input { stdin { type => stdin } } output { stdout { codec => rubydebug } }'
这个 Logstash 配置的作用是从标准输入读取数据,通过标准输出以 Ruby 调试格式显示处理后的数据。
输入 hello 可得到输出配格式化后的数据信息:

3、配置输入和输出:
在配置文件中创建一个 Logstash 管道,该管道使用标准输入来获取日志作为输入,解析这些日志然后将解析的数据输出到标准输出(屏幕上)。
(1) 创建一个文件,作为 Logstash 的管道配置文件,并写入配置内容:
vim /usr/local/logstash/config/first-pipeline.conf

(2) 配置文件语法测试:
bin/logstash -f config/first-pipeline.conf --config.test_and_exit

(3) 启动 Logstash
bin/logstash ‐f config/first‐pipeline.conf
输入日志内容,查看输出:

4、Grok过滤器插件解析Web日志
使用grok过滤器插件,可以将非结构化日志数据解析为结构化和可查询的内容。
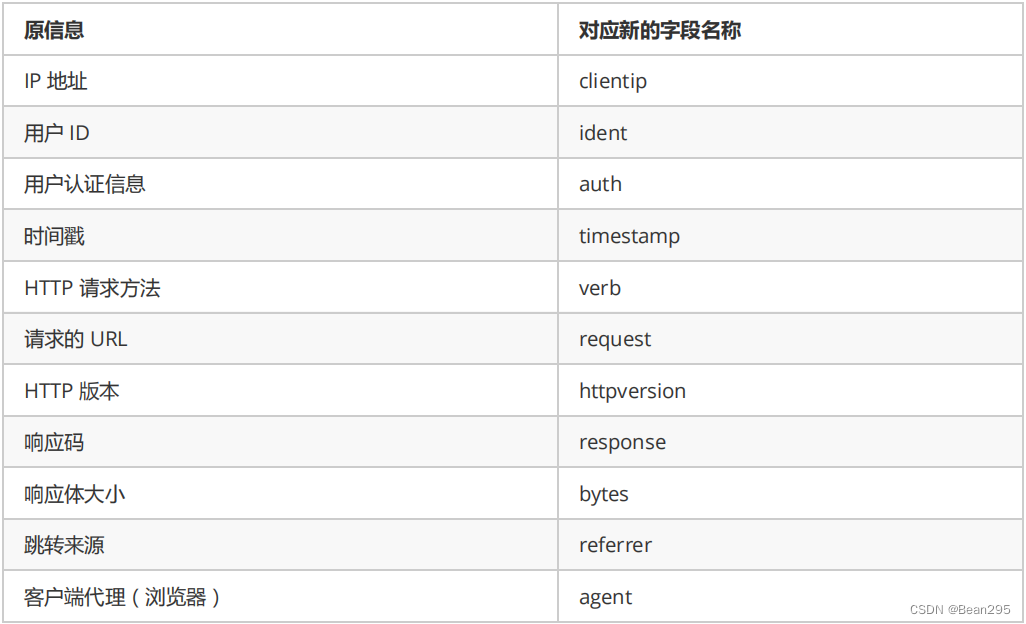
(1) Grok编写:
编辑管道配置文件:grok filter 用于匹配日志中的特定模式,并从中提取字段。

查看输出效果:

(2) grok 常用选项:
remove_field 移除任意的字段 ;rename 重命名字段

查看输出效果:
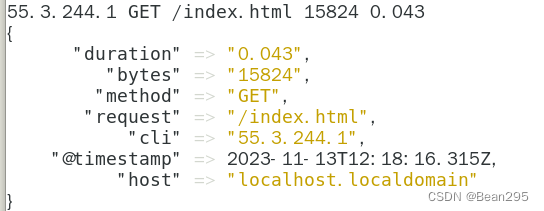
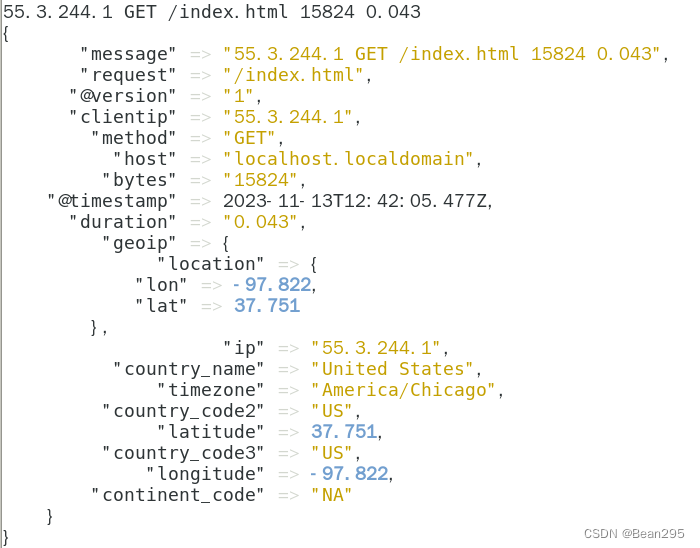
(3) groip 插件:
geoip 插件可以通过查找到IP地址,并从自己自带的数据库中找到地址对应的地理位置信息,然后将该位置信息添加到日志中。

查看输出效果:
5、Logstash 接收 FileBeats 的输入:
(1) FileBeats 配置:

(2) Logstash 配置: