主业是数据分析专家,副业是数据咨询顾问,过去十年里面利用数据分析发家致富
人生苦短,我学Python!
利用技能可以解决的问题,哪些场景下可以催生出需求,深度剖析数据分析的技能树

由浅入深,一个分析师的副业路线
【易上手】利用Python做数据/信息采集
● 学习python期间,接触到了Spider、站点搭建,提供需求方外部第三方数据
● 譬如图片资源、资讯信息、发布数据,解决需要反复需要人工处理的事情
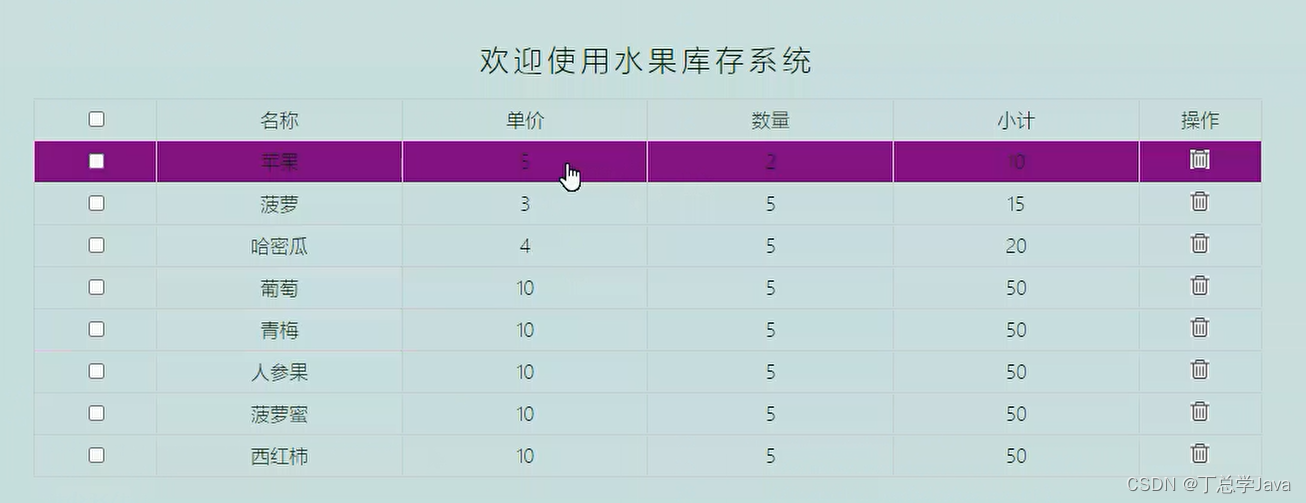
猪八戒网站上关于python小单的一些列表,含任务需求、报价、周期

可以做的一些网站信息解析

利用Python可获取的内容和Coding过程

如果对分析工具、分析方法、分析案例有一定的兴趣,可以参与到知乎知学堂中,跟着业内大佬打好基础,不仅在职场上有所提升,还能在闲暇的时候对接外部的诉求,发展第二曲线来赚钱!
数据分析 3 天实战训练营
¥0.10立即报名
譬如,如果要获取一系列的图片,最终实现的效果
e.g 电影海报

e.g 贴吧壁纸

e.g 公众号配图

【易操作】利用Excel / Python做数据处理
● 早期的时候,接一些零散的小单,譬如Excel模板、自动化统计工具等,帮助雇主解决高效统计的诉求

【要美感】利用BI工具实现大数据可视化
● 进入到互联网,大规模数据处理下催生出来的数据可视化大屏需求



【要实力】通过算法进行各种比赛/竞赛
● Python的应用除了数据处理,最大的优势是在数据建模,和小伙伴参与各大平台的算法比赛,国内的有cff、天池,国外的有kaggle;
行业比赛:高奖金,行业的头部企业,基于业务背景需要对海量的数据进行提炼,集思广益生成方案,业界大佬参与度比较高,;
工具比赛:高奖金,BI厂商主办,利用原厂工具搭建可视化大屏、看板,重在实现思路和路径,通过工具可以实现的内容;
解决方案:高竞争,引入课题,譬如广州交通数据类,如何通过利用数据做整体方案设计;
学校科研:参与为主,各校自己主办的校内比赛,重在培养学生的数据化思维,了解前沿的技术、算法、工具;

【高意识】结合行业中的特性写专利
● 写专利真的可以很赚钱!!!
1、授权后一次性资助不超过人民币2500元。
2、缴纳授权后第三年的年费之后一次性资助不超过人民币1500元。(已享受费减优惠的,没有专利授权资助和年费资助)
3、对小微企业获得的首件授权国内发明专利,一次性资助不超过人民币3000元。
4、对获得中国专利奖的国内发明专利,一次性资助人民币10000元。
5、对权利稳定性好或投入实际运营的国内发明专利,一次性资助人民币3000元。
6、资助申请人申请港澳台授权发明专利资助的,每项专利资助的金额不超过人民币3000元。
7、资助申请人申请国外专利资助的,每项发明专利授权后资助不超过5个国家或地区。其中,通过PCT途径获得授权的每个国家或地区资助不超过人民币5万元;通过巴黎公约途径获得授权的每个国家或地区资助不超过人民币4万元。

【高理解】数据咨询/职业指导
针对各种问题进行1by1的解答,可以围绕职业规划、前沿技术、分析技巧、方法论、算法模型进行开展
● 段位高一点可以,可以提供职业规划的指导,如何写好简历、做好职业发展路径规划、选择工作、行业发展等

● 在接触一段时间R的时候,会接一些社区内的使用咨询,多是学生,如何在R中实现统计分析

【好口才】打造数据分析课程
前提是有积累到一定的受众,输出BI软件使用、分析工具、分析方法论、分析案例、大数据场景、算法实践等内容的培训课程,实现知识付费

【好文采】做垂直领域公众号/视频号
打造个人IP,建立社群,输出系列的知识和文档,做知识星球,后期做品牌合作

【复合型】做数据解决方案
围绕企业当前痛点组织数据进行诊断,提供建设方案、解决办法和执行策略
● AI人工智能时代,数字化转型、业财一体化、产销一体化、降本提效下的数据解决方案咨询诉求
了解更多的数据分析领域知识、行业应用案例,可以强化自己在工作场景中的业务Sense和数据Sense,通过项目可以锤炼自己的解决方案能力,可以点击以下链接,作为一个学习渠道,加强自己的基本功建设!
数据分析 3 天实战训练营
¥0.10立即报名
【附链接】可以关注的一些三方平台
知乎:知乎 - 有问题,就会有答案
猪八戒:https://zbj.com
英选: http://linktion.cn
快码众包: http://kuaima.co
程序员客栈: https://www.proginn.com
CODING 码市: https://mart.coding.net
开源众包: zb.oschina.net/projects
码易众包平台: http://mayigeek.com
一早一晚平台: http://yizaoyiwan.com/
开发邦: http://www.kaifabang.com
人人开发: http://rrkf.com
厘米脚印: http://www.limijiaoyin.com
Sxsoft: https://www.sxsoft.com/
猿急送: https://www.yuanjisong.com/
实现网传送门: http://shixian.com/
智城外包网: http://www.taskcity.com/
【附代码】一个简单的爬虫脚本
import urllib.request
from lxml import etreedef get_request(page):base_url = 'https://www.tupianzj.com/meinv/xiezhen/list_179_'url = base_url + str(page) + '.html'headers = {'user-agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}request = urllib.request.Request(url=url, headers=headers)return requestdef get_data(request):response = urllib.request.urlopen(request)data = response.read().decode('utf8')return datadef download(data):tree = etree.HTML(data)girls_name = tree.xpath('//ul[@class="list_con_box_ul"]//img/@alt')girls_src = tree.xpath('//ul[@class="list_con_box_ul"]//img/@src')for i in range(len(girls_name)):name = girls_name[i]src = girls_src[i]urllib.request.urlretrieve(url=src,filename=('{}.jpg'.format(name))return Trueif __name__ == '__main__':start_page = int(input('输入起始页码:'))end_page = int(input("输入结束页码: "))for page in range(start_page, end_page + 1):request = get_request(page)grils_data = get_data(request)download(grils_dataprint('''It's ok, Successfull!''')