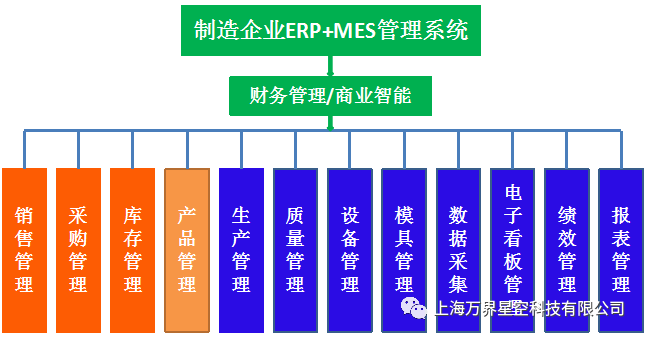
模板层
一. 模版语法
{{ }}: 变量相关
{% %}: 逻辑相关
1. 注释是代码的母亲
{# ... #}
2. 基本数据类型传值
int1 = 123
float1 = 11.11
str1 = '我也想奔现'
bool1 = True
list1 = ['小红', '姗姗', '花花', '茹茹']
tuple1 = (111, 222, 333, 444)
dict1 = {'username': 'jason', 'age': 18, 'info': '这个人有点意思'}
set1 = {'晶晶', '洋洋', '嘤嘤'}# 基本数据类型都支持
{{ int1 }}
{{ float1 }}
{{ str1 }}
{{ bool1 }}
{{ list1 }}
{{ tuple1 }}
{{ dict1 }}
{{ set1 }}3. 函数和类传值
def func():print('我被执行了')return '你的另一半在等你'class MyClass(object):def get_self(self):return 'self'@staticmethoddef get_func():return 'func'@classmethoddef get_class(cls):return 'cls'# 对象被展示到html页面上 就类似于执行了打印操作也会触发__str__方法def __str__(self):return 'cls'obj = MyClass()# 传递函数名会自动加括号调用 但是模版语法不支持给函数传额外的参数
{{ func }}# 传类名的时候也会自动加括号调用(实例化)
{{ MyClass }}# 内部能够自动判断出当前的变量名是否可以加括号调用 如果可以就会自动执行 针对的是函数名和类名
{{ obj }}
{{ obj.get_self }}
{{ obj.get_func }}
{{ obj.get_class }}# 总结
'''
1. 如果计算结果的值是可调用的,它将被无参数的调用。 调用的结果将成为模版的值。
2. 如果使用的变量不存在, 它被默认设置为'' (空字符串) 。
'''4. 模版语法的取值
django模版语法的取值 是固定的格式 只能采用“句点符”
{{ dict1.username }}
{{ list1.0 }}</p>
{{ dict1.hobby3.info }}5. 模板语法的优先级
点.在模板语言中有特殊的含义。当模版系统遇到点.,它将以这样的顺序查询:
'''
1. 字典查询(Dictionary lookup)
2. 属性或方法查询(Attribute or method lookup)
3. 数字索引查询(Numeric index lookup)
'''二. Filters过滤器(注意: 过滤器只能最多有两个参数)
过滤器就类似于是模版语法内置的 内置方法.
django内置有60多个过滤器我们这里了解一部分即可
过滤器语法: {{数据|过滤器:可选参数}}
注意事项:
'''
1. 过滤器支持“链式”操作。即一个过滤器的输出作为另一个过滤器的输入。
2. 过滤器可以接受参数,例如:{{ sss|truncatewords:30 }},这将显示sss的前30个词。
3. 过滤器参数包含空格的话,必须用引号包裹起来。比如使用逗号和空格去连接一个列表中的元素,如:{{ list|join:', ' }}
4. '|'左右没有空格没有空格没有空格
'''
Django的模板语言中提供了大约六十个内置过滤器我们这里介绍14种:
# 统计长度: 作用于字符串和列表。{{ str1|length }}# 默认值: 第一个参数布尔值是True就展示第一个参数的值否则就展示冒号后面的值{{ bool1|default:'谁的布尔值为True谁就展示' }}# 文件大小:{{ file_size|filesizeformat }} # 9.8 KB # 日期格式化: 将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等{{ current_time|date }} # May 29, 2020{{ current_time|date:'Y-m-d' }} # 2020-05-29{{ current_time|date:'Y-m-d H:i:s' }} # 2020-05-29 01:31:09# 切片操作: 支持步长{{ list1|slice:'0:4:2' }}# 切取字符: 如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾 (注意: 包含这三个点){{ info|truncatechars:9 }} # 切取单词: 不包含三个点 按照空格切取, 不是识别单词语法{{ msg|truncatewords:3 }} # 移除特定的字符:{{ msg|cut:' '}} # 拼接操作: # join{{ info|join:'$' }}# 加法: 数字就相加 字符就拼接{{ int1|add:float1 }}{{ str1|add:str1 }} # 转义!!!!:# 后端的转义from django.utils.safestring import mark_safehtml_safe = mark_safe('<h1>哈哈哈</h1>'){{ html }} # 普通的标签使用模板, 任然是模板{{ html_safe }} # 后端的转义传值{{ html|safe }} # 前端的转义 date参数介绍:
| 格式化字符 | 描述 | 示例输出 |
|---|---|---|
| a | 'a.m.'或'p.m.'(请注意,这与PHP的输出略有不同,因为这包括符合Associated Press风格的期间) | 'a.m.' |
| A | 'AM'或'PM'。 | 'AM' |
| b | 月,文字,3个字母,小写。 | 'jan' |
| B | 未实现。 | |
| c | ISO 8601格式。 (注意:与其他格式化程序不同,例如“Z”,“O”或“r”,如果值为naive datetime,则“c”格式化程序不会添加时区偏移量(请参阅datetime.tzinfo) 。 | 2008-01-02T10:30:00.000123+02:00或2008-01-02T10:30:00.000123如果datetime是天真的 |
| d | 月的日子,带前导零的2位数字。 | '01'到'31' |
| D | 一周中的文字,3个字母。 | “星期五” |
| e | 时区名称 可能是任何格式,或者可能返回一个空字符串,具体取决于datetime。 | ''、'GMT'、'-500'、'US/Eastern'等 |
| E | 月份,特定地区的替代表示通常用于长日期表示。 | 'listopada'(对于波兰语区域,而不是'Listopad') |
| f | 时间,在12小时的小时和分钟内,如果它们为零,则分钟停留。 专有扩展。 | '1','1:30' |
| F | 月,文,长。 | '一月' |
| g | 小时,12小时格式,无前导零。 | '1'到'12' |
| G | 小时,24小时格式,无前导零。 | '0'到'23' |
| h | 小时,12小时格式。 | '01'到'12' |
| H | 小时,24小时格式。 | '00'到'23' |
| i | 分钟。 | '00'到'59' |
| I | 夏令时间,无论是否生效。 | '1'或'0' |
| j | 没有前导零的月份的日子。 | '1'到'31' |
| l | 星期几,文字长。 | '星期五' |
| L | 布尔值是否是一个闰年。 | True或False |
| m | 月,2位数字带前导零。 | '01'到'12' |
| M | 月,文字,3个字母。 | “扬” |
| n | 月无前导零。 | '1'到'12' |
| N | 美联社风格的月份缩写。 专有扩展。 | 'Jan.','Feb.','March','May' |
| o | ISO-8601周编号,对应于使用闰年的ISO-8601周数(W)。 对于更常见的年份格式,请参见Y。 | '1999年' |
| O | 与格林威治时间的差异在几小时内。 | '+0200' |
| P | 时间为12小时,分钟和'a.m。'/'p.m。',如果为零,分钟停留,特殊情况下的字符串“午夜”和“中午”。 专有扩展。 | '1 am','1:30 pm' / t3>,'midnight','noon','12:30 pm' / T10> |
| r | RFC 5322格式化日期。 | 'Thu, 21 Dec 2000 16:01:07 +0200' |
| s | 秒,带前导零的2位数字。 | '00'到'59' |
| S | 一个月的英文序数后缀,2个字符。 | 'st','nd','rd'或'th' |
| t | 给定月份的天数。 | 28 to 31 |
| T | 本机的时区。 | 'EST','MDT' |
| u | 微秒。 | 000000 to 999999 |
| U | 自Unix Epoch以来的二分之一(1970年1月1日00:00:00 UTC)。 | |
| w | 星期几,数字无前导零。 | '0'(星期日)至'6'(星期六) |
| W | ISO-8601周数,周数从星期一开始。 | 1,53 |
| y | 年份,2位数字。 | '99' |
| Y | 年,4位数。 | '1999年' |
| z | 一年中的日子 | 0到365 |
| Z | 时区偏移量,单位为秒。 UTC以西时区的偏移量总是为负数,对于UTC以东时,它们总是为正。 | -43200到43200 |
三. 标签
1. for循环
| forloop.first | 第一次循环返回True, 其余返回False |
|---|---|
| forloop.last | 最后一次循环返回False, 其余返回True |
| forloop.counter | 当前循环次数. 从1开始 |
| forloop.counter0 | 当前循环索引. 从0开始 |
| forloop.revcounter | 当前循环次数取反 |
| forloop.revcounter0 | 当前循环索引取反 |
| forloop.parentloop | 本层循环的外层循环 |
展示格式:
{'parentloop': {}, 'counter0': 0, 'counter': 1, 'revcounter': 4, 'revcounter0': 3, 'first': True, 'last': False}
{'parentloop': {}, 'counter0': 1, 'counter': 2, 'revcounter': 3, 'revcounter0': 2, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 2, 'counter': 3, 'revcounter': 2, 'revcounter0': 1, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 3, 'counter': 4, 'revcounter': 1, 'revcounter0': 0, 'first': False, 'last': True}{% for foo in list1 %}<p>{{ forloop }}</p><p>{{ foo }}</p> # 一个个元素
{% endfor %}2. if判断
# if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断
{% if bool1 %}<p>1111</p>
{% elif int1 %}<p>2222</p>
{% else %}<p>3333</p>
{% endif %}3. for与if混合使用
{% for foo in list1 %}{% if forloop.first %}<p>这是我的第一次</p>{% elif forloop.last %}<p>这是最后一次啊</p>{% else %}<p>上面都不是才轮到我</p>{% endif %}{% empty %}<p>for循环的可迭代对象内部没有元素 根本没法循环</p>
{% endfor %}4. 处理字典values,keys,items方法
{% for foo in dict1.values %}<p>{{foo}}</p>
{% endfor %}{% for foo in dict1.keys %}<p>{{foo}}</p>
{% endfor %}{% for foo in dict1.items %}<p>{{foo}}</p>
{% endfor %}5. with起别名
在with语法内就可以通过as后面的别名快速的使用到前面非常复杂获取数据的方式
dict1 = {'username': 'egon', 'hobby': ['吃', '喝', '玩', {'info': '他喜欢吃生蚝!!!'}]}# 书写方式一: as语句
{% with dict1.hobby.3.info as nb %}<p>{{ nb }}</p>{# 与上面等同, 但是长语句, 还是使用with赋值来进行 #}<p>{{ dict1.hobby.3.info }}</p>
{% endwith %}# 书写方式二: 赋值
{% with nb=dict1.hobby.3.info %}<p>{{ nb }}</p>{# 与上面等同, 但是长语句, 还是使用with赋值来进行 #}<p>{{ dict1.hobby.3.info }}</p>
{% endwith %}四. 自定义过滤器、标签、inclusion_tag
1. 准备步骤
1. 在应用下创建一个名字”必须“叫templatetags文件夹
2. 在该文件夹内创建“任意”名称的py文件
3. 在该py文件内"必须"先书写下面两句话(单词一个都不能错)from django import templateregister = template.Library()
2. 自定义过滤器
强调: 自定义过滤器函数, 最大只能设有2个形参
from .templatetags.mytag import register
@register.filter(name='my_sum')
def abc(v1, v2): # abc函数名任意. 导入自定义过滤器使用的是上面指定的name的值return v1 + v2# 使用: (注意: 先导入我们自定义filter那个文件mytag)
{% load mytag %}
<p>{{ int1|my_sum:100 }}</p>3. 自定义标签
# 自定义标签: 数可以有多个 类似于自定义函数
from .templatetags.mytag import register
@register.simple_tag(name='my_join')
def abc(a, b, c, d): # abc函数名任意. 导入自定义标签使用的是上面指定的name的值return f'{a}-{b}-{c}-{d}'# 使用: 标签多个参数彼此之间空格隔开(注意: 先导入我们自定义filter那个文件mytag)
{% load mytag %}
p>{% my_join 'json' 123 123 123 %}</p>4. 自定义inclusion_tag
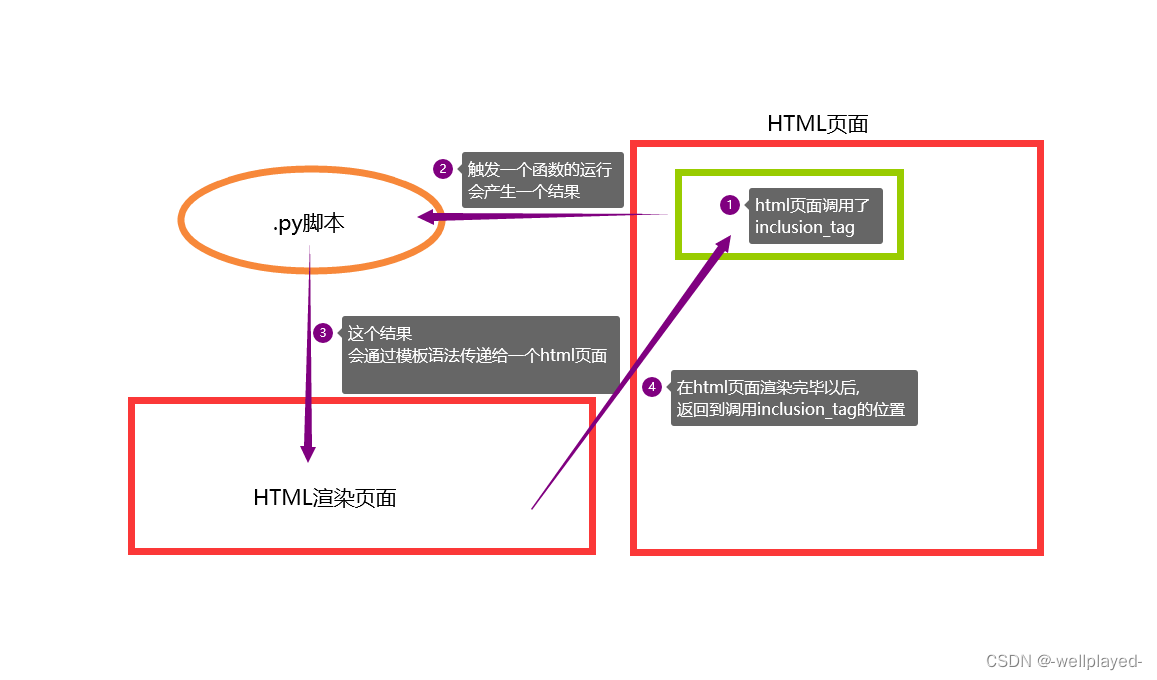
'''
内部原理:先定义一个方法 在页面上调用该方法 并且可以传值该方法会生成一些数据然后传递给一个html页面之后将渲染好的结果放到调用的位置
'''
from .templatetags.mytag import register
@register.inclusion_tag('left_memu.html') # 注意: 这里传的是渲染的HTML文件, 不需要指定关键字name
def left(n):data = ['第{}项'.format(i) for i in range(n)]# 第一种: 将data传递给left_menu.html# return {'data':data}# 第二种: 将data传递给left_menu.htmlreturn locals()# left_memu.html
{% for foo in data %}{% if forloop.first %}<p>{{foo}}</p>{% elif forloop.last %}<p>{{ foo }}</p>{% endif %}
{% endfor %}# index使用(注意: 先导入我们自定义filter那个文件mytag)
{% load mytag %}
{% left 5 %}
五. 模板的继承
# 模版的继承 你自己先选好一个你要想继承的模版页面
{% extends 'home.html' %}# 继承了之后子页面跟模版页面长的是一模一样的 你需要在模版页面上提前划定可以被修改的区域
{% block content %}模版内容
{% endblock %}# 子页面就可以声明想要修改哪块划定了的区域
{% block content %}子页面内容
{% endblock %}# 一般情况下模版页面上应该至少有三块可以被修改的区域, 这样每一个子页面就都可以有自己独有的css代码 html代码 js代码
{% block css %}1.css区域
{% endblock %}{% block content %}2.html区域
{% endblock %}{% block js %}3.js区域
{% endblock %}"""
一般情况下 模版的页面上划定的区域越多 那么该模版的扩展性就越高
但是如果太多 那还不如自己直接写
"""六. 模版的导入
"""
将页面的某一个局部当成模块的形式
哪个地方需要就可以直接导入使用即可
"""
'''静态导入'''
{% include 'wasai.html' %}'''动态导入'''
# 被导入的text.html
<p>{{ name }}</p> {# 这里的name就是"egon"#}# 导入html的文件
{% include 'text.html' with name='"egon"' %}# 不过上面的导入的参数是写死的. 如果你想动态的通过模板语法传参, 你可以这样
{% include 'text.html' with name=username %} {#注意哦! 这里的username是视图层传过来的哦!#}
# 被导入文件中如果想{{ name }}模板以后是字符串的格式你可以这也指定即可!
<p>'{{ name }}'</p> {#注意: 如果不加引号, 这种字符串的格式的话, 那么name模板传值以后就是一个变量.#}模型层
一. 配置测试脚本
当你只是想测试django中的某一个py文件内容 那么你可以不用书写前后端交互的形式, 而是直接写一个测试脚本即可:
# 测试环境的准备 去manage.py中拷贝前四行代码 然后自己写两行
import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()# 在这个代码块的下面就可以测试django里面的单个py文件了(注意: 导模块也要写在这下面)二. ORM常用字段类型和参数
1. 常用字段
| 常用字段 | 描述 | 与MySQL字段对应关系 |
|---|---|---|
| AutoField | 必须指定参数primary_key=True指定主键. 如果没有设置主键, 默认创建并以id名作为主键 | integer auto_increment |
| IntegerField | 整型字段. 存储宽度4Bytes. 无符号: 0~2^32 有符号: -232/2~232-1 | int 或 integer |
| BigIntegerField | 整型字段. 存储宽度8Bytes. 无符号: 0~2^64 有符号: -264/2~264-1 | bigint |
| DeciamlField | 浮点字段. 必须指定参数max_digits设置总长度. decimal_places设置小数位长度 | numeric(%(max_digits)s, %(decimal_places)s) |
| EmailField | 字符字段. Django Admin以及ModelForm中提供验证机制 | |
| CharField | 字符字段. 必须指定参数max_length参数设置字符存储个数. Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,但是Django允许我们自定义新的字段. | varchar(%(max_length)s) |
| DateField | 日期字段. 格式: 年-月-日. 一般指定参数auto_now=Ture更新记录的时间, 或者auto_now_add=True插入记录的时间 | date |
| DateTimeField | 日期字段. 格式: 年-月-日 时:分:秒 一般指定参数auto_now=Ture更新记录的时间, 或者auto_now_add=True插入记录的时间 | datetime |
2. 字段类型(联想记忆: 与MySQL字段对应关系)
2-1. 自增长字段
models.AutoField(primary_key=True) # 必须填入参数 primary_key=True
models.BigAutoField(primary_key=True) # 必须填入参数 primary_key=True# 与MySQL字段对应关系
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',注:当model中如果没有自增列,则自动会创建一个列名为id的列
2-2. 二进制字段
models.BinaryField()# 与MySQL字段对应关系
'BinaryField': 'longblob',2-3. 布尔型字段
models.BooleanField() # 该字段传布尔值(False/True) 数据库里面存0/1
models.NullBooleanField()# 与MySQL字段对应关系
'BooleanField': 'bool',Django提供了两种布尔类型的字段,上面这种不能为空,下面这种的字段值可以为空。
2-4. 整型字段
掌握
models.IntegerField() # 整数列(有符号的) -2147483648 ~ 2147483647
models.BigIntegerField() # 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807# 与MySQL字段对应关系
'IntegerField': 'integer',
'BigIntegerField': 'bigint', 了解
models.PositiveSmallIntegerField() # 正小整数 0 ~ 327672147483647
models.PositiveIntegerField() # 正整数 0 ~ 2147483647models.SmallIntegerField() # 小整数 -32768 ~ 32767# 与MySQL字段对应关系
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SmallIntegerField': 'smallint', 2-5. 字符串类型
models.CharField(max_length) # 以varchar类型存储 注: 必须提供max_length参数, max_length表示字符长度
models.TextField() # longtext 文本类型 该字段可以用来存大段内容(文章、博客...) 没有字数限制# 与MySQL字段对应关系
'CharField': 'varchar(%(max_length)s)'
'TextField': 'longtext',
Django Admin以及ModelForm中提供:
邮箱
EmailField() # Django Admin以及ModelForm中提供验证机制. 以varchar(254)形式存储地址
IPAddressField() # Django Admin以及ModelForm中提供验证 IPV4 机制GenericIPAddressField() # Django Admin以及ModelForm中提供验证 Ipv4和Ipv6# 参数:protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both"# 与MySQL字段对应关系
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',URL
URLField() # Django Admin以及ModelForm中提供验证 URL 文件
FileField() # 给该字段传一个文件对象,会自动将文件保存到/data目录下然后将文件路径保存到数据库中 /data/a.txt# 参数:upload_to = "" 上传文件的保存路径storage = None 存储组件,默认django.core.files.storage.FileSystemStorageFilePathField() # Django Admin以及ModelForm中提供读取文件夹下文件的功能# 参数:path, 文件夹路径match=None, 正则匹配recursive=False, 递归下面的文件夹allow_files=True, 允许文件allow_folders=False, 允许文件夹 # 与MySQL字段对应关系
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)', 图片
ImageField() # 路径保存在数据库,文件上传到指定目录# 参数:upload_to = "" 上传文件的保存路径storage = None 存储组件,默认django.core.files.storage.FileSystemStoragewidth_field=None, 上传图片的高度保存的数据库字段名(字符串)height_field=None 上传图片的宽度保存的数据库字段名(字符串)xxxxxxxxxx6 1ImageField() # 路径保存在数据库,文件上传到指定目录2 # 参数:3 upload_to = "" 上传文件的保存路径4 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage5 width_field=None, 上传图片的高度保存的数据库字段名(字符串)6 height_field=None 上传图片的宽度保存的数据库字段名(字符串)python其他
SlugField() # Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField() # 格式必须为逗号分割的数字
UUIDField() # Django Admin以及ModelForm中提供对UUID格式的验证 # 与MySQL字段对应关系
'SlugField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)'
'UUIDField': 'char(32)', 2-6. 时间类型
models.DateField() # 年-月-日
models.DateTimeField() # 年-月-日 时:分:秒
models.DurationField() # 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型# 与MySQL字段对应关系
'DateField': 'date'
'TextField': 'longtext'
'DateTimeField': 'datetime'
'DurationField': 'bigint'2-7. 浮点型
models.FloatField()
models.DecimalField() # 10进制小数# 参数:max_digits,小数总长度decimal_places,小数位长度# 与MySQL字段对应关系
'FloatField': 'double precision'
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)'2-8. 关系型字段
# 前提: 先建立基表 再建立外键关系 无序同mysql中操作需要考虑外键关系的创建以及记录的插入顺序# 一对多关系建表: 建立在多的一方publish = models.ForeignKey(to='Publish)# 多对多关系建表: 建立在查询频率高的一方提示: 无序在mysql中操作需要建立中间表, models会默认帮你创建虚拟中间表表authors = models.ManToManyField(to='Book')# 一对一关系建表: 建立在查询频率高的一方author_detail = models.OneToOneField(to='AuthorDetail')# 补充: 建立一对多, 一对一关系的外键关联表, 关联表中默认会在建立的外键字段之后拼接_id, 我们无序指定.3. 字段参数
3-1. 所有字段都具有的参数
# 更改字段名 db_colum=''# 设置主键 primary_key=True,默认为False# 给字段设置别名(备注) verbose_name=''# 为字段设置默认值default# 字段的唯一键属性 unique=True,设置之后,这个字段的没一条记录的每个值是唯一的# 允许字段为空 null=True(数据库中字段可以为空),blank=True(网页表单提交内容可以为空),切记不可以将null设置为Fasle的同时还把blank设置为True。会报错的。# 给字段建立索引 db_index=True# 在表单中显示说明 help_text=''# 字段值不允许更改editable=False,默认是True,可以更改。3-2. 个别字段才有的参数
# CharField(max_length=100)字段长度为utf8编码的100个字符串# DateField(unique_for_date=True)这个字段的时间必须唯一# DecimalField(max_digits=4, decimal_places=2)前者表示整数和小数总共多少数,后者表示小数点的位数
3-3. auto_now 和 auto_now_add
# 提示: 一般作为DateField和DateTimeField参数
# auto_now=True对这条记录内容更新的时间# auto_now_add=True 插入这条记录的时间3-4. 关系型字段的参数
# to设置要关联的表 unique=TrueForeignKey(unique=True) === OneToOneField()# 你在用前面字段创建一对一 orm会有一个提示信息 orm推荐你使用后者但是前者也能用# to_field 置要关联的表的字段 默认不写关联的就是另外一张的主键字段.# on_delete=models.CASECADE 和 on_update=models.CASECADE设置级联更新级联删除. 同等与SQL语言中的ON DELETE CASCADE等约束 (提示: 该操作为Django1.X版本的默认操作, 2.X和3.X需要手动指定)# db_index如果db_index=True 则代表着为此字段设置索引# db_constraint: 注意:db_constraint参数只适用于一对一, 或者一对多的关系. 至于多对多也是由双向的一对多关系组合而成, 是在一对多的关系上使用是否在数据库中创建外键约束,默认为True。其余字段参数
models.DO_NOTHING
删除关联数据,引发错误IntegrityErrormodels.PROTECT
删除关联数据,引发错误ProtectedErrormodels.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)models.SET
删除关联数据,a. 与之关联的值设置为指定值,设置:models.SET(值)b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)# on_dalete实际应用
on_delete参数:1、表之间没有外键关联,但是有外键逻辑关联(有充当外键的字段)2、断关联后不会影响数据库查询效率,但是会极大提高数据库增删改效率(不影响增删改查操作)3、断关联一定要通过逻辑保证表之间数据的安全,不要出现脏数据,代码控制4、断关联5、级联关系作者没了,详情也没:on_delete=models.CASCADE出版社没了,书还是那个出版社出版:on_delete=models.DO_NOTHING部门没了,员工没有部门(空不能):null=True, on_delete=models.SET_NULL部门没了,员工进入默认部门(默认值):default=0, on_delete=models.SET_DEFAULT 3-5. 自关联字段参数
需要在第一个参数中添加‘self’字符串,或写上它自己的表名(模型类名)
parent = ForeignKey(to='self')3–6. related_name 和 related_query_name
related_name
# related_name 子查询反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。
# 例如:
class Classes(models.Model):name = models.CharField(max_length=32)class Student(models.Model):name = models.CharField(max_length=32)theclass = models.ForeignKey(to="Classes")# 当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().student_set.all()# 当我们在ForeignKey字段中添加了参数 related_name 后
class Student(models.Model):name = models.CharField(max_length=32)theclass = models.ForeignKey(to="Classes", related_name="students")# 当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
models.Classes.objects.first().students.all()related_query_name
# related_query_name连表查询时, 反向查询操作时,使用的连接前缀,用于替换表4. 自定义字段
class MyCharField(models.Field):# 1. 自定义独有参数def __init__(self, max_length, *args, **kwargs):self.max_length = max_lengthsuper().__init__(max_length=max_length, *args, **kwargs) # max_length一定要是关键字的形式传入# 2. 定义存储的类型及约束条件def db_type(self, connection):return 'Char(%s)' % self.max_length# 自定义字段使用
class Text(models.Model):myfield = MyCharField(max_length=32, null=True)二. 准备表和基本数据
1. 准备表
from django.db import models# Create your models here.
class User(models.Model):name = models.CharField(max_length=32, verbose_name='用户名')age = models.IntegerField(verbose_name='年龄')# register_time = models.DateField(verbose_name='年月日')register_time = models.DateTimeField(auto_now_add=True, verbose_name='年月日时分秒')"""提示: django自带的sqlite3数据库对日期格式不是很敏感 处理的时候容易出错DateFieldDateTimeField两个重要参数auto_now: 每次操作数据的时候 该字段会自动将当前时间更新auto_now_add:在创建数据的时候会自动将当前创建时间记录下来 之后只要不认为的修改 那么就一直不变"""def __str__(self):return self.nameclass Book(models.Model):title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8, decimal_places=2)publish_time = models.DateTimeField(auto_now_add=True)authors = models.ManyToManyField(to='Author')publish = models.ForeignKey(to='Publish')def __str__(self):return self.titleclass Author(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()author_detail = models.OneToOneField(to='AuthorDetail')def __str__(self):return self.nameclass Publish(models.Model):name = models.CharField(max_length=32)addr = models.CharField(max_length=64)email = models.EmailField() # varchar(254) 该字段类型不是给models看的 而是给的校验性组件看的def __str__(self):return self.nameclass AuthorDetail(models.Model):phone = models.BigIntegerField()addr = models.CharField(max_length=64)def __str__(self):return f'{self.phone}'2. 基本数据
先往出版社表,作者表, 作者详情表准备一些数据。
因为一对一关系外键和一对多差不多,我们用一对多来操作,把一对一的表先建立好,不做操作。
出版社表是一个被图书表关联的表我们先建立这个被关联表。
| publish | ||
|---|---|---|
| id | addr | |
| 1 | 东方出版社 | 东方 |
| 2 | 北方出版社 | 北方 |
| author | |||
|---|---|---|---|
| id | name | age | author_detail_id |
| 1 | jason | 18 | 1 |
| 2 | egon | 84 | 2 |
| 3 | tank | 50 | 3 |
| author_detail | ||
|---|---|---|
| id | phone | addr |
| 1 | 110 | 芜湖 |
| 2 | 120 | 山东 |
| 3 | 130 | 惠州 |
三. 单表操作: 增删改
1. 增
# 1. 方式一: 自动增 .create
models.User.objects.create(name='jason', age=73, register_time='2020-11-11 11:11:11')from datetime import datetime
models.User.objects.create(name='jason', age=73, register_time=datetime.now().strftime('%Y-%m-%d %X'))import time
models.User.objects.create(name='jason', age=73, register_time=time.strftime('%Y-%m-%d %X'))# 2. 方式二: 手动增 .save()
user_obj = models.User(name='alex', age=84, register_time='2020-11-11 11:11:11')
user_obj.save()2. 删
# 1. 拿到QuerySet对象: 统一的删除
res = models.User.objects.filter(pk=9).delete()
print(res) # (1, {'app01.User': 1}) 第一个参数是被影响的行数
models.User.objects.all().delete()
"""
pk会自动查找到当前表的主键字段 指代的就是当前表的主键字段
用了pk之后 你就不需要指代当前表的主键字段到底叫什么了uidpidsid...
"""# 2. 拿到用户对象: 单一针对性的删除
user_obj = models.User.objects.filter(pk=11).first()
user_obj.delete()3. 改
# 1. 方式一: .update
user_obj = models.User.objects.filter(pk=100).update(name='EGON_DSB')
print(user_obj) # 0
user_queryset = models.User.objects.filter(pk=100)
print(user_queryset, bool(user_queryset)) # <QuerySet []> False# 2. 方式二: .get + 赋值 + .save()
user_obj = models.User.objects.get(pk=100) # app01.models.DoesNotExist: User matching query does not exist.
user_obj.name = 'EGON_DSB1'
user_obj.save()
"""
get方法返回的直接就是当前数据对象
但是该方法不推荐使用一旦数据不存在该方法会直接报错而filter则不会所以我们还是用filter
"""四. 必知必会13条 (ORM提供的13条API)
1. all() 查询所有
'''
返回QuerySet对象. QuerySet对象内部包含所有数据对象
'''
user_queryset = models.User.objects.all()
print(user_queryset) # <QuerySet [<User: User object>, <User: User object>,,...]>2. filter(**kwargs) 过滤
'''
返回QuerySet对象. 内部包含与所给筛选条件相匹配的数据对象
不指定参数默认查询所有
带有过滤条件的查询, 当结果不存在返回空的QuerySet对象, 布尔值为False
'''
user_queryset = models.User.objects.filter(name='alex')
print(user_queryset) # <QuerySet [<User: User object>, <User: User object>]>user_queryset = models.User.objects.filter()
print(user_queryset) # <QuerySet [<User: User object>, <User: User object>,,...]>user_queryset = models.User.objects.filter(pk=9999)
print(user_queryset, bool(user_queryset)) # <QuerySet []> False3. get(**kwargs)
'''
直接获取数据对象
只能指定一个筛选条件. 如果指定的筛选条件返回的结果不唯一 或者 不存在 抛出异常
'''
user_queryset = models.User.objects.get(pk=1)
print(user_queryset) # User object# models.User.objects.get(name='alex') # get() returned more than one User -- it returned 2!.# models.User.objects.get(pk=9999999) # User matching query does not exist.4. last()
'''
获取QuerySet列表中最后一个数据对象.
用在QuerySet对象之后, 如果QuerySet对象为空, 再使用它返回None
'''
user_queryset = models.User.objects.filter(age=73)
print(user_queryset) # <QuerySet [..., <User: rrr>, <User: qwe>]>user_obj = models.User.objects.filter(age=73).last()
print(user_obj) # qweuser_obj = models.User.objects.filter(pk=99999).last()
print(user_obj) # None5. first()
'''
直接获取QuerySet列表中第一个数据对象.
用在QuerySet对象之后, 如果QuerySet对象为空, 再使用它返回None
'''
user_queryset = models.User.objects.filter(age=73)
print(user_queryset) # <QuerySet [<User: EGON_DSB1>, <User: egon>,...]>user_obj = models.User.objects.filter(age=73).first()
print(user_obj) # EGON_DSB1user_obj = models.User.objects.filter(pk=99999).first()
print(user_obj) # None6. values(*field)
'''
返回QuerySet对象. 内部是一种列表套字典的格式. 字典的key就是指定的字段名
'''
user_queryset = models.User.objects.values('name', 'age')
print(user_queryset) # <QuerySet [{'name': 'EGON_DSB1', 'age': 73}, ..., {'name': 'alex', 'age': 84}]># 注意!!!: 指定字段不存在抛出异常.
# django.core.exceptions.FieldError: Cannot resolve keyword 'xxxxxxxxxx' into field. Choices are: age, id, name, register_time
user_queryset = models.User.objects.values('xxxxxxxxxx')
print(user_queryset) # <Query7. values_list(*field)
'''
返回QuerySet对象.
内部是一种列表套元组的格式. 元组的第一个值就是指定的第一个字段对应的数据, 依此类推.
'''
user_queryset = models.User.objects.values_list('name', 'age')
print(user_queryset) # <QuerySet [('EGON_DSB1', 73), ..., ('alex', 84)]># 注意!!!: 指定字段不存在抛出异常.
# django.core.exceptions.FieldError: Cannot resolve keyword 'xxxxxxxxxx' into field. Choices are: age, id, name, register_time
user_queryset = models.User.objects.values_list('xxxxxxxxxx')
print(user_queryset) # <Query8. distinct() 去重
'''
注意!!!: 必须排除主键字段 或 唯一字段才会有意义
要排除使用filter无法筛选. 一般用在.values() 或 .value_list()后面
'''
user_queryset = models.User.objects.values('age')
print(user_queryset) # <QuerySet [{'age': 73}, {'age': 73}, {'age': 73}, {'age': 84}, {'age': 84}]>
dis_user_queryset = user_queryset.distinct()
print(dis_user_queryset) # <QuerySet [{'age': 73}, {'age': 84}]>9. order_by(*field) 排序
'''
对查询结果排序. 默认升序. 如果想要降序在对应要查询的字段前指定`-`号
'''
user_queryset = models.User.objects.values('age')
print(user_queryset) # <QuerySet [{'age': 73}, {'age': 84}]>user_queryset_asc = user_queryset.order_by('age')
print(user_queryset_asc) # <QuerySet [{'age': 73}, {'age': 84}]>user_queryset_desc = user_queryset.order_by('-age')
print(user_queryset_desc) # <QuerySet [{'age': 84}, {'age': 73}]>10. reverse()
'''
注意!!!: 反转的前提是数据已经排过序. 没排过序reverse将不起作用.
'''
user_queryset_desc = models.User.objects.values('age').reverse()
print(user_queryset_desc) # <QuerySet [{'age': 73}, {'age': 84}]>user_queryset_desc = models.User.objects.values('age').order_by('-age')
print(user_queryset_desc) # <QuerySet [{'age': 84}, {'age': 73}]>user_queryset_desc_rev = user_queryset_desc.reverse()
print(user_queryset_desc_rev) # <QuerySet [{'age': 73}, {'age': 84}]>11. count()
'''
查询QuerySet内部所包含的数据对象的个数
'''
user_queryset = models.User.objects.all()
print(user_queryset) # <QuerySet [<User: EGON_DSB1>, <User: alex>]>
all_user_queryset = models.User.objects.count()
print(all_user_queryset) # 2user_queryset = models.User.objects.filter(name='EGON_DSB1')
print(user_queryset) # <QuerySet [<User: EGON_DSB1>]>
all_user_queryset = models.User.objects.filter(name='EGON_DSB1').count()
print(all_user_queryset) # 112. exclude(**kwargs):
'''
排除. 查询与所给筛选条件不匹配的
'''
user_queryset = models.User.objects.exclude(age=73)
print(user_queryset) # <QuerySet [<User: alex>, <User: alex>]>
print(user_queryset.values('age')) # <QuerySet [{'age': 84}, {'age': 84}]# 注意!!!: 排除不存在的返回空的QuerySet对象
user_queryset = models.User.objects.exclude(age=11111111111111)
print(user_queryset) # <QuerySet []>13. exists()
'''
查找所返回的QuerySet结果包含数据,就返回True,否则返回False
'''
user_queryset = models.User.objects.filter(pk=999999).exists()
print(user_queryset) # Falseuser_queryset = models.User.objects.all().exists()
print(user_queryset) # True五. 查看内部封装的sql语句的2种形式
# 第一种: QuerySet.query
user_queryset = models.User.objects.values_list('name', 'age')
print(user_queryset.query) # SELECT `app01_user`.`name`, `app01_user`.`age` FROM `app01_user`# 第二种: 执行脚本时打印日志显示到终端. 复制以下日志内容到settings.py中
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},}
}六. 神奇的双下划线查询
1. 参数介绍
'''
field__gt=value field__lt=value
field__gte=value field__lte=value
field__in=[value1, value2, ...]
field__range=[value1, value2]
field__contains='substring' field__icontains='substring'
field__startswith='substring' field__endswith='substring'
field__istartswith='substring' field__iendswith='substring'
field__year='2020' field__month='1' field__day='30'
field__year=2020 field__month=1' field__day=30
'''2. 实例操作
# 查询年龄大于35岁的数据
models.User.objects.filter(age__gt=35)# 查询年龄小于35岁的数据
models.User.objects.filter(age__lt=35)# 查询年龄大于等于33岁 查询年龄小于等于30岁
models.User.objects.filter(age__gte=30)
models.User.objects.filter(age__lte=30)# 查询年龄是22 或者 30 或者 73
models.User.objects.filter(age__in=[22, 30, 73])# 查询年龄在18到40岁之间的 首尾都要
models.User.objects.filter(age__range=[18, 40])# 模糊查询: 查询出名字里面含有`s`的数据(区分大小写) 查询出名字里面含有`s`的数据(忽略大小写)
models.User.objects.filter(name__contains='s')
models.User.objects.filter(name__icontains='s')# 以`j`开头(区分大小写) 以`j`开头(不区分大小写) 以`5`结尾(区分大小写)
models.User.objects.filter(name__startswith='j')
models.User.objects.filter(name__istartswith='j')
models.User.objects.filter(name__endswith='5')# 查询出注册时间是 2020 1月的
models.User.objects.filter(register_time__year=2020)3. 总结
# 注意: 争对字段使用. 如: field__gt
__gt __lt __gte __glt
__in=[] __range=[start, stop]
__contains __icontains i全称忽略ignore
__startswith __istartswith
__endswith __iendswith
__year='2020' __year=2020
__month='1' __month=1
__day='20' __day=20