了解完了独立表空间的基本结构,系统表空间的结构也就好理解多了,系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页面,所以会比独立表空间多出一些记录这些信息的页面。因为这个系统表空间最牛逼,相当于是表空间之首,所以它的 表空间 ID (Space ID)是 0 。
9.3.1 系统表空间的整体结构
系统表空间与独立表空间的一个非常明显的不同之处就是在表空间开头有许多记录整个系统属性的页面,如图:
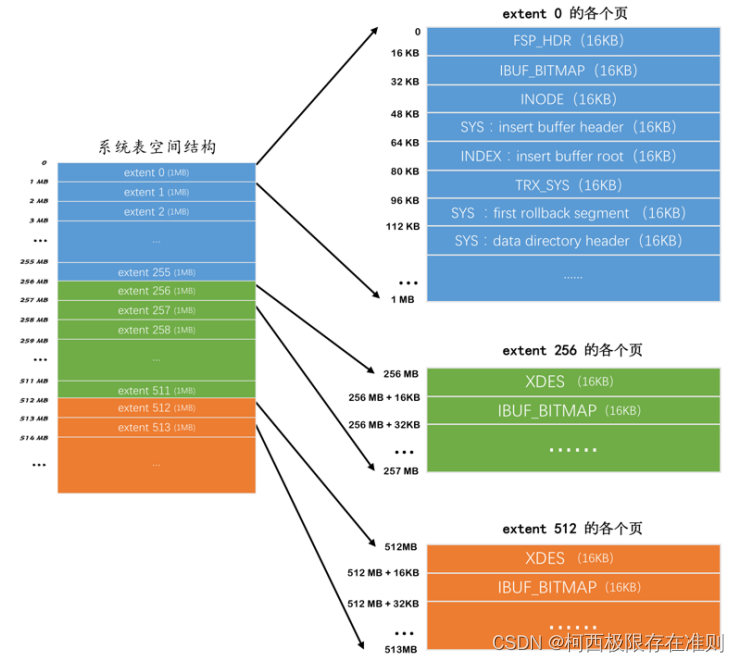
可以看到,系统表空间和独立表空间的前三个页面(页号分别为 0 、 1 、 2 ,类型分别是 FSP_HDR 、IBUF_BITMAP 、 INODE )的类型是一致的,只是页号为 3 ~ 7 的页面是系统表空间特有的,我们来看一下这些多出来的页面都是干啥使的:
| 页号 | 页面类型 | 英文描述 | 描述 |
| 3 | SYS | Insert Buffer Header | 存储Insert Buffer的头部信息 |
| 4 | INDEX | Insert Buffer Root | 存储Insert Buffer的根页面 |
| 5 | TRX_SYS | Transction System | 事务系统的相关信息 |
| 6 | SYS | First Rollback Segment | 第一个回滚段的页面 |
| 7 | SYS | Data Dictionary Header | 数据字典头部信息 |
除了这几个记录系统属性的页面之外,系统表空间的 extent 1 和 extent 2 这两个区,也就是页号从 64 ~ 191这128个页面被称为 Doublewrite buffer ,也就是双写缓冲区。
9.3.1.1 InnoDB数据字典
我们平时使用 INSERT 语句向表中插入的那些记录称之为用户数据,MySQL只是作为一个软件来为我们来保管这些数据,提供方便的增删改查接口而已。但是每当我们向一个表中插入一条记录的时候,MySQL先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要知道该表的聚簇索引和所有二级索引对应的根页面是哪个表空间的哪个页面,然后把记录插入对应索引的 B+ 树中。所以说,MySQL除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:
某个表属于哪个表空间,表里边有多少列
表对应的每一个列的类型是什么
该表有多少索引,每个索引对应哪几个字段,该索引对应的根页面在哪个表空间的哪个页面
该表有哪些外键,外键对应哪个表的哪些列
某个表空间对应文件系统上文件路径是什么
InnoDB存储引擎特意定义了一些列的内部系统表(internalsystem table)来记录这些元数据 :

这些系统表也被称为 数据字典 ,它们都是以 B+ 树的形式保存在系统表空间的某些页面中,其中SYS_TABLES 、 SYS_COLUMNS 、 SYS_INDEXES 、 SYS_FIELDS 这四个表尤其重要,称之为基本系统表(basicsystem tables),我们先看看这4个表的结构:
| SYS_TABLES表的列 | |
| 列名 | 描述 |
| NAME | 表的名称 |
| ID | InnoDB存储引擎中每个表都有一个唯一的ID |
| N_COLS | 该表拥有列的个数 |
| TYPE | 表的类型,记录了一些文件格式、行格式、压缩等信息 |
| MIX_ID | 已过时,忽略 |
| MIX_LEN | 表的一些额外的属性 |
| CLUSTER_ID | 未使用,忽略 |
| SPACE | 该表所属表空间的ID |
这个 SYS_TABLES 表有两个索引:
- 以 NAME 列为主键的聚簇索引
- 以 ID 列建立的二级索引
| SYS_COLUMNS表的列 | |
| 列名 | 描述 |
| TABLE_ID | 该列所属表对应的ID |
| POS | 该列在表中是第几列 |
| NAME | 该列的名称 |
| MTYPE | main data type,主数据类型,就是那堆INT、CHAR、VARCHAR、FLOAT、DOUBLE之类的 |
| PRTYPE | precise type,精确数据类型,就是修饰主数据类型的那堆东东,比如是否允许NULL值,是否允许负数啥的 |
| LEN | 该列最多占用存储空间的字节数 |
| PREC | 该列的精度,不过这列貌似都没有使用,默认值都是0 |
SYS_FIELDS表
| SYS_FIELDS表的列 | |
| 列名 | 描述 |
| INDEX_ID | 该索引列所属的索引的ID |
| POS | 该索引列在某个索引中是第几列 |
| COL_NAME | 该索引列的名称 |
这个 SYS_INEXES 表只有一个聚集索引:
以 (INDEX_ID, POS) 列为主键的聚簇索引
Data Dictionary Header页面
只要有了上述4个基本系统表,也就意味着可以获取其他系统表以及用户定义的表的所有元数据。比方说我们想看看 SYS_TABLESPACES 这个系统表里存储了哪些表空间以及表空间对应的属性,那就可以:
到 SYS_TABLES 表中根据表名定位到具体的记录,就可以获取到 SYS_TABLESPACES 表的 TABLE_ID
使用这个 TABLE_ID 到 SYS_COLUMNS 表中就可以获取到属于该表的所有列的信息。
使用这个 TABLE_ID 还可以到 SYS_INDEXES 表中获取所有的索引的信息,索引的信息中包括对应的INDEX_ID ,还记录着该索引对应的 B+ 数根页面是哪个表空间的哪个页面。
使用 INDEX_ID 就可以到 SYS_FIELDS 表中获取所有索引列的信息。
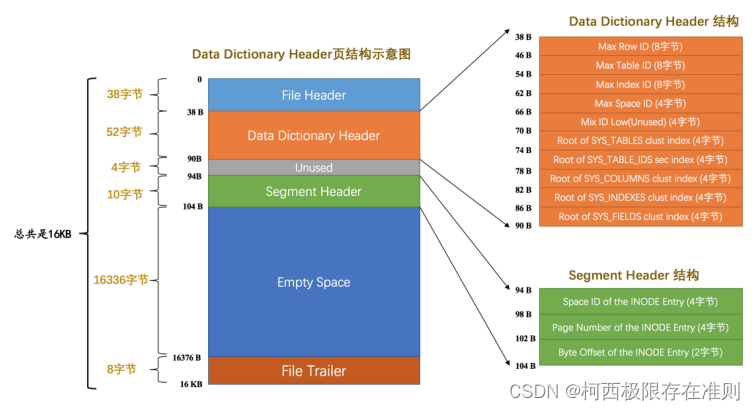
可以看到这个页面由下边几个部分组成:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Data Dictionary Header | 数据字典头部信息 | 56字节 | 记录一些基本系统表的根页面位置以及InnoDB存储引擎的一些全局信息 |
| Segment Header | 段头部信息 | 10字节 | 记录本页面所在段对应的INODE Entry位置信息 |
| Empty Space | 尚未使用空间 | 16272字节 | 用于页结构的填充,没啥实际意义 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
可以看到这个页面里竟然有 Segment Header 部分,意味着设计InnoDB的大叔把这些有关数据字典的信息当成一个段来分配存储空间,我们就姑且称之为 数据字典段 吧。由于目前我们需要记录的数据字典信息非常少(可以看到 Data Dictionary Header 部分仅占用了56字节),所以该段只有一个碎片页,也就是页号为 7 的这个页。
Max Row ID :我们说过如果我们不显式的为表定义主键,而且表中也没有 UNIQUE 索引,那么 InnoDB 存储引擎会默认为我们生成一个名为 row_id 的列作为主键。因为它是主键,所以每条记录的 row_id 列的值不能重复。原则上只要一个表中的 row_id 列不重复就可以了,也就是说表a和表b拥有一样的 row_id 列也没啥关系,不过设计InnoDB的大叔只提供了这个 Max Row ID 字段,不论哪个拥有 row_id 列的表插入一条记录时,该记录的 row_id 列的值就是 Max Row ID 对应的值,然后再把 Max Row ID 对应的值加1,也就是说这个 Max Row ID 是全局共享的。
Max Table ID :InnoDB存储引擎中的所有的表都对应一个唯一的ID,每次新建一个表时,就会把本字段的值作为该表的ID,然后自增本字段的值。
Max Index ID :InnoDB存储引擎中的所有的索引都对应一个唯一的ID,每次新建一个索引时,就会把本字段的值作为该索引的ID,然后自增本字段的值。
Max Space ID :InnoDB存储引擎中的所有的表空间都对应一个唯一的ID,每次新建一个表空间时,就会把本字段的值作为该表空间的ID,然后自增本字段的值。
Root of SYS_TABLES clust index :本字段代表 SYS_TABLES 表聚簇索引的根页面的页号。
Root of SYS_TABLE_IDS sec index :本字段代表 SYS_TABLES 表为 ID 列建立的二级索引的根页面的页号。
Root of SYS_COLUMNS clust index :本字段代表 SYS_COLUMNS 表聚簇索引的根页面的页号。
Root of SYS_INDEXES clust index 本字段代表 SYS_INDEXES 表聚簇索引的根页面的页号。
Root of SYS_FIELDS clust index :本字段代表 SYS_FIELDS 表聚簇索引的根页面的页号。
information_schema系统数据库需要注意一点的是,用户是不能直接访问 InnoDB 的这些内部系统表的,除非你直接去解析系统表空间对应文件系统上的文件。