2022 年底以来,LLM 大规模语言模型备受瞩目。今年 3 月中旬,智谱 AI 与清华大学强强联合,重磅发布了 ChatGLM-6B 开源模型。截止 6 月 24 日,该模型的下载量超过三百万人次,并在 Hugging Face(HF)全球大模型下载排行榜中连续十二天位居第一,性能优异且极具影响力。
大模型应被广泛应用于各行各业、推动各领域发展。为最大化利用 ChatGLM-6B 助力学术、科研应用工具的开发工作,智谱 AI 与和鲸科技联合国内最具影响力的学术平台 AMiner,推出本次「ChatGLM 实践大赛 · 学术应用篇」(下简称“大赛”)。大赛也得到了 Hugging Face、揽睿星舟与亚马逊云科技的大力支持。

大赛共计三个场景、七个赛道,分别为:论文阅读场景,包含论文学科分类、问答式科研知识库、论文综述和对比分析三个赛道;投稿审核场景,包含投稿期刊会议推荐、审稿回复两个赛道;论文发现场景,包含论文检索、论文推荐和科技情报生成两个赛道——均考验参赛者如何通过微调 ChatGLM-6B 开源模型形成应用型学术工具。
作为国内首个大规模语言模型应用赛,自 5 月 8 日上线以来,获得了广泛关注。截至 6 月 16 日,已有来自北京、河南、上海、广东等全国各地的总计 1647 名 LLM 爱好者结成 1551 支参赛队伍于和鲸社区赛事平台参与报名。参赛选手中有来自百度、阿里、北大方正的产品经理、算法工程师,也有来自清华、北大、复旦、上交、浙大的教师及学生。
大赛进程中,和鲸全力为各参赛选手提供支持。ChatGLM 等 LLM 拥有巨幅的模型规模,参数量庞大,需要极高的计算、存储空间,和鲸发放了数十张 V100 GPU,解决选手在大模型训练过程中的算力问题。
在参赛指导方面,和鲸联合智谱 AI 成功举办两场直播培训,这也是智谱 AI 首次于公开场合针对 ChatGLM 开展培训:首场直播讲解赛题、教授大模型微调,第二场则讲解 ChatGLM + LangChain 的原理及实践,线上会议室场均人数 500+,参与度极高。此外,和鲸在社区赛事页与参赛社群内分赛道为选手提供详尽的参赛指南、赛题指导文件,提升选手参赛体验,社群内学习氛围浓厚。

截至 6 月 16 日,和鲸社区共收到 348 份来自大模型研发爱好者们的参赛作品。
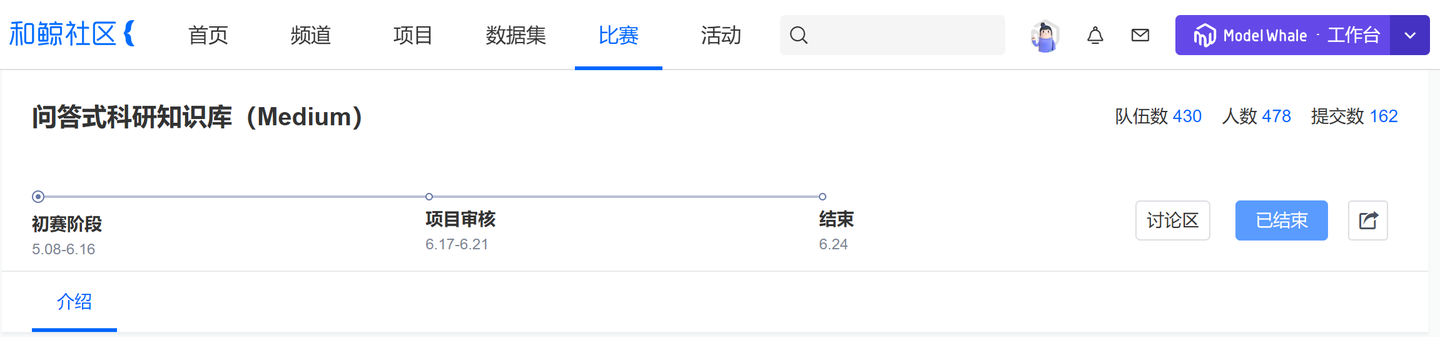
赛道二 478 位参赛者成功提交 162 份参赛作品
评审阶段,由于 ChatGLM 作为一种生成模型,应从文本质量、相关性、多样性及创新性等多角度评估其质量,因此传统的分类、回归等客观指标无法适用于 LLM 大赛;另一方面,若对大模型文件直接进行人工、主观评估,又会出现复杂的环境配置问题,无法在短期内高效完成评审——综上,本次大赛在评审环节还是存在相当大的挑战。
针对评审的复杂性,和鲸协助智谱 AI 采用自动化 + 轻量人工的形式评估选手的参赛成果:选手上传已完成训练的推理模型,并将模型文件部署为模型服务后,通过线上数据调试验证模型可用性,同时在完成调试后提交最终跑出的模型结果;自动化模型评审针对模型服务的客观性能实时出分,随后的真人评委仅需查看参赛者模型运行的最终产物——两者结合不仅相对公平,同时也大幅提升评审效率。
评审进行过程中,和鲸发现,经选手微调后的 ChatGLM-6B 远超预期:
在问答式科研知识库赛道,有队伍提交的参赛模型不仅能够完成赛道基本任务,并且也在推理能力层面得到了大幅优化。作为 6B 量级的模型,清华官方 GitHub 明确指出 ChatGLM-6B 因参数量较小,在推理能力等方面存在很大不足。而该参赛队伍提交的模型不但能够完成推理、返回知识问答的结果,同时也能够返回生成问答结果的依据,且经过测试可以发现,该“依据”与“结果”间确实存在较强关联——有力约束了大模型应用场景下“不懂装懂”、“答非所问”的幻觉(Hallucination)现象。从以上层面来看,该参赛作品的表现完全能够媲美一些参数量较大的 LLM。
在审稿回复赛道,经部分队伍微调后的 ChatGLM-6B 已能输出一些 openreview 的官方审稿样式——模型跑出的结果不单单是能与待审稿文章高度相关,同时也被部分学术领域专家认定为具备基本的审稿能力与一定的专业度。
7 月 7 日,智谱 AI 在 2023 全球数字经济大会闭幕式上为优秀参赛队伍颁发奖项。按照赛道区分难度等级分别颁奖,共计六支参赛队伍获得 ChatGLM 官方认证的优秀证书、价值 2000-5000 元人民币不等的 ChatGLM API 支持及价值 2000-5000 元人民币不等的 GPU 云计算资源。

「ChatGLM 实践大赛 · 学术应用篇」是国内早期的 LLM 应用赛,吸引了数千余人的参与。主办方智谱 AI 更是国内顶级的人工智能科技公司,在全球范围内百亿至千亿参数级大模型领域都有极高的行业地位。和鲸科技十分荣幸能够与智谱 AI 共同承办本赛事,为有意向投身 LLM 大规模语言模型研发的开拓者们提供优质的实践环境。
通过此次大赛,我们可以发现,ChatGLM-6B 开源模型在学术、科研领域、都能发挥比较大的作用,模型使用者能够真正将其在文本识别、总结、预测、生成方面的能力应用于实际,大幅提升科研工作流的效率。而近日升级版 ChatGLM2-6B 已全新发布,在保留了初代模型对话流畅、部署门槛较低等基础之上,引入了更强大的性能、更长的上下文、更高效的推理、更开放的协议等诸多特性。和鲸科技基于旗下和鲸社区约 50 万+的人才储备、ModelWhale 数据科学协同平台的强大算力调度管理、以 ModelOps 理念聚焦大模型全生命周期管理等优势,期待与智谱 AI 在大模型领域共同营造更优质的开发者生态,进一步挖掘 ChatGLM 系列大模型的潜力,推动大模型的应用落地。
未来,和鲸ModelWhale平台也将持续优化,从推理测试、微调训练、应用开发、服务部署的全流程帮助使用者提升研发效率,降低使用门槛,为具有更大参数量的 LLM 提供平台级支撑,同时始终关注中小模型 ModelOps 产品能力的提升,与更多模型领域的开拓者同行!
赛事承办、工具使用,任何相关需求,都欢迎您点击【联系产品顾问(移动端跳转)】与我们展开交流。