学校机器学习课程的实验课要求实现KNN和K-Means:


(平时没听课)临时去查了一下KNN和K-Means是啥,然后自己用C++写了小例子,想着写都写了那就把代码贴出来吧。
顺便再聊聊自己对于这俩算法的理解。
下面是文心一言的回答。
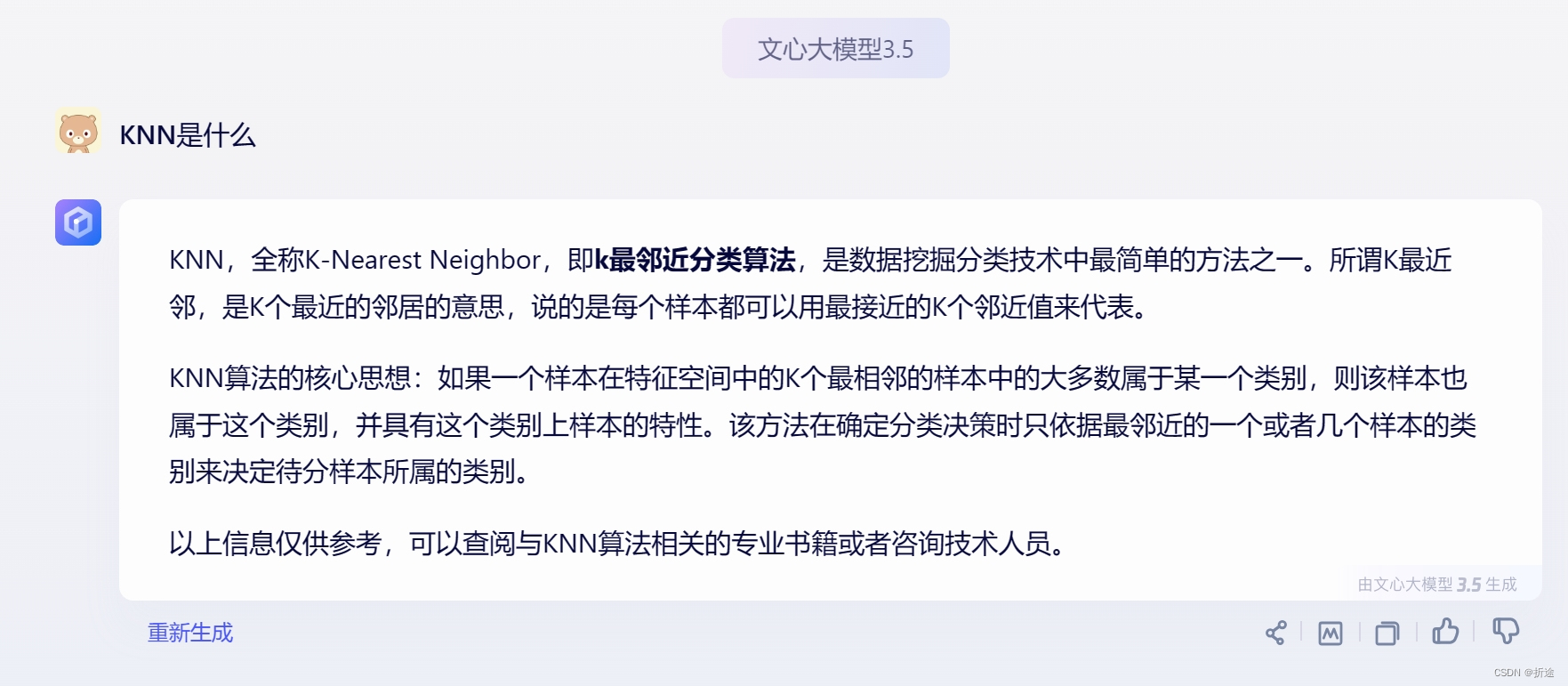
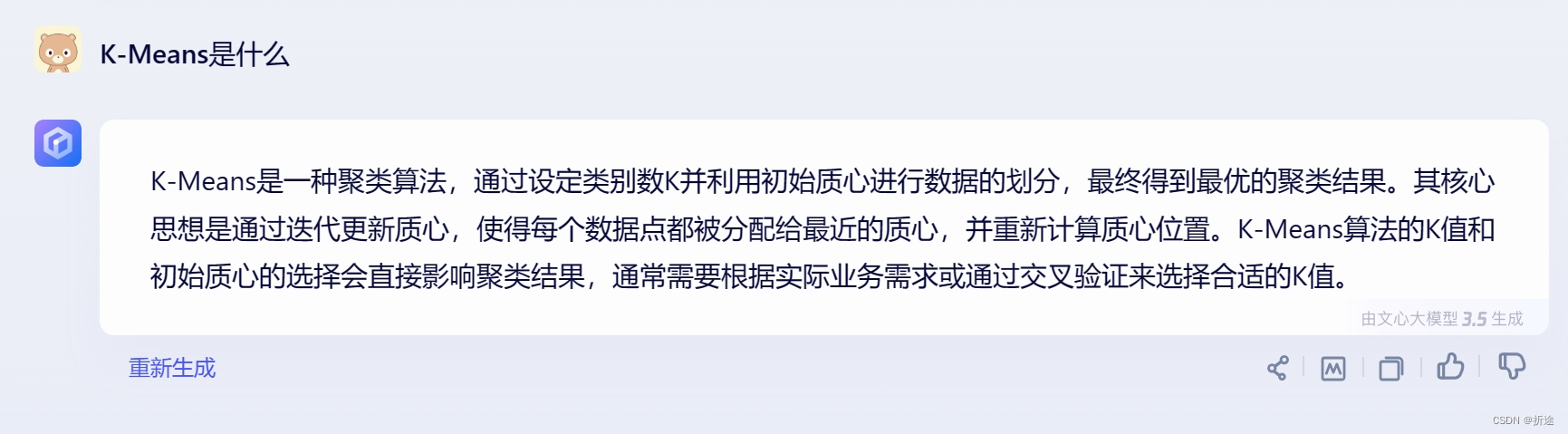
首先这俩都是分类算法,我们需要根据已经拥有的数据来对新数据进行分类。
KNN是把这个新数据扔到已有的数据里,然后找出K个距离这个新数据最近的以后数据,如果K个数据中大部分都是A类,那么我们就认为这个新数据是A类。
代码中我是自己定义了一个类来作为数据,一共有两个元素,可以把数据看作的二维的坐标点,然后要分类新数据的时候就对所有已有数据点来计算距离,然后挑出距离最近的K个点,按照类型的占比来对新数据的类型进行预测。
代码写得比较冗余,但是应该还算是好理解的(毕竟注释都写出来了)。
#include <iostream>
#include <vector>
#include <random>
#include<chrono>using namespace std;//自定义数据类型,共有两个参数
class mydata {
public:int val1;int val2;int type;mydata(int val1=0,int val2=0,int type=0):val1(val1),val2(val2),type(type) {//cout << "type is" << type << "\tval1 is" << val1 << "\tval2 is" << val2 << endl;}
};vector<vector<mydata>>Data_19(3,vector<mydata>(100)); //3分类,每类100个的数据集
vector<vector<mydata>>Validation_19(3, vector<mydata>(10)); //3分类,每类10个的验证集void CreateData() {default_random_engine e; //默认的随机数引擎生成无符号整型e.seed(chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count()); //设置随机数种子uniform_int_distribution<unsigned int> type1_1(0,100); //类型1的val1的随机数范围 uniform_int_distribution<unsigned int> type1_2(100,150); //类型1的val2的随机数范围 uniform_int_distribution<unsigned int> type2_1(30,130); //类型2的val1的随机数范围 uniform_int_distribution<unsigned int> type2_2(130,180); //类型2的val2的随机数范围 uniform_int_distribution<unsigned int> type3_1(50,150); //类型3的val1的随机数范围 uniform_int_distribution<unsigned int> type3_2(160,210); //类型3的val2的随机数范围 for (int i = 0; i < 100; ++i) {//随机生成三个类型的数据Data_19[0][i] = mydata(type1_1(e),type1_2(e),1);Data_19[1][i] = mydata(type2_1(e),type2_2(e),2);Data_19[2][i] = mydata(type3_1(e),type3_2(e),3);if (i < 10) {//随机生成三个类型的验证集Validation_19[0][i] = mydata(type1_1(e), type1_2(e), 1);Validation_19[1][i] = mydata(type2_1(e), type2_2(e), 2);Validation_19[2][i] = mydata(type3_1(e), type3_2(e), 3);}}
}int myKNN(int k,int val1,int val2) {//定义大小为300,元素为pair(可以存放两个元素)的数组,每个元素存放数据集的数据的类型以及与待预测数据的欧式距离vector<pair<int, int>>distance_types(300);//初始化数组存放的类型for (int i = 0; i < 100; ++i) distance_types[i].first = 1;for (int i = 100; i < 200; ++i) distance_types[i].first = 2;for (int i = 200; i < 300; ++i) distance_types[i].first = 3;for (int i = 0; i < 3; ++i) {for (int j = 0; j < 100; ++j) {//计算欧式距离 distance_types[100 * i + j].second = sqrt(pow(Data_19[i][j].val1-val1,2)+pow(Data_19[i][j].val2-val2,2));}}//按照欧式距离排序sort(distance_types.begin(), distance_types.end(), [&](auto& a,auto& b) {return a.second < b.second;});//大小为3的数组,用来记录与待预测数据最近的K个数据是什么类型的vector<int>count(3);for (int i = 0; i < k; ++i) {count[distance_types[i].first - 1]++;}//将接近待预测数据最多的类型返回if (count[0] >= count[1] && count[0] >= count[2]) return 1;if (count[1] >= count[0] && count[1] >= count[2]) return 2;return 3;
}void check(int K) { //KNN算法中的近邻数double right = 0, worry = 0; //用于记录KNN预测的正确数以及错误数for (int n = 0; n < 100; ++n) { //进行一百轮CreateData(); //调用生成数据集以及验证集的函数for (int i = 0; i < 3; ++i) {for (int j = 0; j < 10; ++j) {//如果预测成功则增加正确数,反之增加错误数if (myKNN(K, Validation_19[i][j].val1, Validation_19[i][j].val2) == Validation_19[i][j].type) ++right;else ++worry;}}}cout << "K is " << K << "\t\tright count: " << right << "\tworry count: " << worry << "\taccuracy is: " << right / (right + worry) << endl;
}int main(void) {for (int k = 3; k <= 10; ++k) {check(k);}return 0;
}K-Means的K是指我们需要把已有的数据集划分成K类。
首先我们先初始化K个锚点,随便初始化(当然效果不会好),一个锚点算是单独一个类型,然后计算所有数据点到这K个锚点之间的距离,如果数据点到某个锚点最近,那么就把这个数据点划分为这个锚点的类型。
计算完毕之后,再把每个锚点下的所有数据点取平均值再赋给锚点,这样锚点就被更新到这个类型的数据点集的中心位置了。
接着再重复刚才的过程,直到锚点的坐标不再改变,那么我们就说K-Means收敛了。
完毕之后我们就得到了K个锚点。
来新数据的时候我们只需要计算新数据和这个K个锚点之间的距离,把新数据归类到最近的锚点下就完成了分类。
刚才的KNN是在分类新数据的时候要进行大量计算(计算新数据与所有老数据的距离),而K-Means是在一开始初始化的时候进行大量计算。
代码中没有像KNN那样新建一个类型来表示数据,但是每个数据还是有两个元素,可以看作是二维平面上的坐标点。
#include <iostream>
#include <vector>
#include <random>
#include <chrono>
#include <unordered_map>using namespace std;vector<vector<int>>Datas;
int N = 100; //随机生成数据的数量
int K = 5; //分成K类
unordered_map<char, vector<vector<int>>> M; //用于划分数据的类
default_random_engine e; //默认的随机数引擎生成无符号整型
uniform_int_distribution<int> u(0,100); //控制随机数生成范围void CreateDatas_09() {//随机生成100个数据 for (int i = 0; i < N; ++i) {Datas.push_back({ u(e),u(e) });}
}void K_Means_09(int K) {vector<vector<int>>K_Sources(K); //存放K个聚点vector<vector<int>>temp_K_Sources(K); //用于比较是否和上次聚点的坐标一致vector<pair<double,char>>cache(K); //临时存放数据与聚点的距离int epoch = 0;CreateDatas_09(); //调用函数生成数据集//随机初始生成K个聚点for (int i = 0; i < K; ++i) K_Sources[i]={ u(e),u(e) };while (1) {temp_K_Sources = K_Sources; //保存当前聚点的数据,用于判断是否收敛M.clear();for (int i = 0; i < N; ++i) {for (int j = 0; j < K; ++j) {//计算欧式距离cache[j] = { sqrt(pow(K_Sources[j][0] - Datas[i][0],2) + pow(K_Sources[j][1] - Datas[i][1],2)) ,'A' + j };}//排序数据与每个聚点的距离sort(cache.begin(), cache.end(), [](auto& a,auto& b){return a.first < b.first;});//如果哈希表中没有此类聚点的键,那么添加if (M.find(cache[0].second) == M.end()) M[cache[0].second] = vector<vector<int>>(0);//分配数据到相应的类M[cache[0].second].push_back(Datas[i]);}cout << "epoch is:" << epoch++ << endl;for (int i = 0; i < K; ++i) {//重新计算聚点数据int x = 0, y = 0;//累加所有数据的值for (auto& a : M['A' + i]) {x += a[0];y += a[1];}//取平均值作为新聚点K_Sources[i][0] = x / M['A' + i].size();K_Sources[i][1] = y / M['A' + i].size();cout << static_cast<char>('A' + i) << "类的聚点:\t" << K_Sources[i][0] << "\t" << K_Sources[i][1] << endl;}//如果聚点与上次的结果相同,那么收敛,结束迭代if (temp_K_Sources == K_Sources) break;}
}int main(void) {//设置时间戳保证每次随机的数据都不同e.seed(chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count());K_Means_09(K);cout << "----------------------------------分割线------------------------------------------" << endl;//打印分类的结果for (int i = 0; i < K; ++i) {cout << static_cast<char>('A' + i) << "类包含的点:" << endl;for (auto& a : M['A' + 1]) cout << a[0] << '\t' << a[1] << endl;}return 0;
}