Linux环境下载安装ProtoBuf编译器
1. 安装依赖库
Ubuntu用户选择
sudo apt-get install autoconf automake libtool curl make g++ unzip -y
Centos用户选择
sudo yum install -y autoconf automake libtool curl make gcc-c++ unzip
2. 下载ProtoBuf编译器
Github地址:https://github.com/protocolbuffers/protobuf/releases/tag/v21.11
以v21.11为例。
既可以选择针对一门语言的ProtoBuf,也可以选择适用于多种语言的ProtoBuf。
这里以适用于多种语言的ProtoBuf举例,下载all.zip:
wget https://github.com/protocolbuffers/protobuf/releases/download/v21.11/protobuf-all-21.11.zip
解压zip包:
unzip protobuf-all-21.11.zip
3. 安装ProtoBuf编译器
解压zip包后会生成protobuf-21.11目录,进入该目录:
cd protobuf-21.11
如果你选择的是适用于多种语言的ProtoBuf,请执行该步骤:
./autogen.sh
执行configure(有两种方式):
-
方式一:默认方式,安装的bin、include、lib是分散的。
-
./configure
-
-
方式二:bin、include、lib统一安装在/usr/local/protobuf下。
-
./configure --prefix=/usr/local/protobuf
-
依次执行以下命令(前两步执行时间分别为15分钟左右,make check也可以选择不执行)
make
make check
sudo make install
如果之前执行configure选择的是方式二,执行该步骤:
-
第一步:进入profile配置文件
-
sudo vim /etc/profile
-
-
第二步:将以下内容写入该文件,然后保存退出
-
#(动态库搜索路径) 程序加载运⾏期间查找动态链接库时指定除了系统默认路径之外的其他路径 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/ #(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径 export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/ #执⾏程序搜索路径 export PATH=$PATH:/usr/local/protobuf/bin/ #c程序头⽂件搜索路径 export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/ #c++程序头⽂件搜索路径 export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/ #pkg-config 路径 export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/
-
执行/etc/profile,使配置生效
source /etc/profile
4. 检查是否安装成功
protoc --version
能正确显示出版本号,即安装成功!
5. VsCode 插件 Bug ! ! !
如果你的vscode安装了c/c++这款插件,那么你的*.pb.c将会出现大量报错(不影响正常使用,因为这是vscode c/c++插件的bug),目前我尚无解决方法(除了卸载该插件)。
上手ProtoBuf
ProtoBuf的认识
ProtoBuf是Google内部使用的一种序列化结构数据的方法,特点如下:
- 语言无关、平台无关:即ProtoBuf支持多种语言、多种平台;
- 高效:比XML更小、更快、更为简单;
- 拓展性、兼容性好:在更新数据结构之后,不影响旧程序。
创建ProtoBuf文件
touch fileName.proto
编译ProtoBuf文件
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/fileName.protoprotoc 是ProtoBuf提供的命令后编译工具
$SRC_DIR 指定被编译的proto所在目录
--cpp_out 指定生成供cpp使用的文件
$SRC_DIR/fileName.proto 指定被编译的proto文件
熟悉ProtoBuf语法
添加注释
//
或者
/* ... */
指定ProtoBuf语法版本
syntax = "proto3";
用在文件的第一行。如果不指定,默认版本为proto2,但现在主流版本是proto3。
添加命名空间
package name;
该选项是可选项,但一般建议加上(在指定语法的下方,定义消息字段的上方)。效果为:编译.proto生成的cpp文件里的数据字段在namespace name {}里。
定义消息
message name{...
}
定义消息字段
message name{string sex = 1;int32 age = 2;...
}
- 在message里定义的消息字段分为两种:标量数据类型和特殊类型;
- 在定义字段时,需要指定一个唯一字段编号。
标量数据类型表
| .proto Type | Notes | cpp Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码。负数的编码效率低,若字段可能为负值,则推荐使用sint32。 | int32 |
| int64 | 使用变长编码。负数的编码效率低,若字段可能为负值,则推荐使用sint64。 | int64 |
| uint32 | 使用变长编码。 | uint32 |
| uint64 | 使用变长编码。 | uint64 |
| sint32 | 使用变长编码。负数的编码效率高于int32。 | int32 |
| sint64 | 使用变长编码。负数的编码效率高于int64。 | int64 |
| fixed32 | 使用定长编码。若值常⼤于228则会⽐uint32更高效。 | uint32 |
| fixed64 | 使用定长编码。若值常⼤于256则会⽐uint64更高效。 | uint64 |
| sfixed32 | 使用定长编码。 | int32 |
| sfixed64 | 使用定长编码。 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,⻓度不能超过232。 | string |
| bytes | 可包含任意的字节序列但⻓度不能超过232。 | string |
变长编码:经过ProtoBuf编码后,原本4/8字节的数可能会变为其它字节数。
字段编号
总范围:1 ~ 229-1,其中19000 ~ 19999不可用(原因是在ProtoBuf协议的实现中,对这个范围的字段编号进行了预留)。
范围在 1 ~ 15的字段编号使用一个字节编码;范围在16 ~ 2047的字段编号使用两个字节编码。
所以建议用1 ~ 15范围内的字段编号来标记出现较为频繁的字段,也要为将来可能加入的、使用频繁的字段预留一些字段编号。
修饰字段的规则
- singular:消息中可以使用该字段0次或1次。在proto3语法中,字段默认被singular修饰。
- repeated:消息中可以使用该字段多次,重复值按相对顺序保留。(可以理解为数组)
对常用标量数据类型和特殊数据类型字段的分析(以通讯录举例)
syntax = "proto3";
package contacts;message Phone {string number = 1;enum PhoneType {Mobile = 0,LandLine = 1,}PhoneType type = 2;
}message PeopleInfo {string name = 1;int32 age = 2;repeated Phone phone = 3;google.protobuf.Any data = 4;oneof {string qq = 5;string wechat = 6;}map<string, string> remark = 7;
}
上面是contacts.proto, 使用protoc编译它,便会生成contacts.pb.h和contacts.pb.cc。
下面是contacts.pb.h的部分常用代码展示。
int32
// int32 age = 2;void clear_age();int32_t age() const;void set_age(int32_t value);
string
// string name = 1;void clear_name();const std::string& name() const;template <typename ArgT0 = const std::string&, typename... ArgT>void set_name(ArgT0&& arg0, ArgT... args);std::string* mutable_name();PROTOBUF_NODISCARD std::string* release_name();void set_allocated_name(std::string* name);
repeated
repeated的作用类似于定义一个数组。
// repeated .contacts.Phone phone = 3;int phone_size() const;void clear_phone();::contacts::Phone* mutable_phone(int index);::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::contacts::Phone >* mutable_phone();const ::contacts::Phone& phone(int index) const;::contacts::Phone* add_phone();const ::PROTOBUF_NAMESPACE_ID::RepeatedPtrField< ::contacts::Phone >& phone() const;
enum
enum PhoneType : int {Mobile = 0,LandLine = 1,PhoneType_INT_MIN_SENTINEL_DO_NOT_USE_ = std::numeric_limits<int32_t>::min(),PhoneType_INT_MAX_SENTINEL_DO_NOT_USE_ = std::numeric_limits<int32_t>::max()
};
bool PhoneType_IsValid(int value);
constexpr PhoneType PhoneType_MIN = Mobile;
constexpr PhoneType PhoneType_MAX = LandLine;
constexpr int PhoneType_ARRAYSIZE = PhoneType_MAX + 1;const ::PROTOBUF_NAMESPACE_ID::EnumDescriptor* PhoneType_descriptor();
template<typename T>
inline const std::string& PhoneType_Name(T enum_t_value) {static_assert(::std::is_same<T, PhoneType>::value ||::std::is_integral<T>::value,"Incorrect type passed to function PhoneType_Name.");return ::PROTOBUF_NAMESPACE_ID::internal::NameOfEnum(PhoneType_descriptor(), enum_t_value);
}
inline bool PhoneType_Parse(::PROTOBUF_NAMESPACE_ID::ConstStringParam name, PhoneType* value) {return ::PROTOBUF_NAMESPACE_ID::internal::ParseNamedEnum<PhoneType>(PhoneType_descriptor(), name, value);
}
PhoneType_IsValid函数用来判断传入的值是否有效。
PhoneType_Name函数用来打印枚举变量值对应的字段名称。
// .contacts.PhoneType type = 2;void clear_type();::contacts::PhoneType type() const;void set_type(::contacts::PhoneType value);
对于枚举类型,有一些定义规则:
- 0值必须存在,且要作为第一个元素;
- 枚举值范围在32位整数范围内。负值无效(跟编码有关)
Any
Any可以理解为泛型,google已经定义好的类型,它就在include/google/protobuf/any.proto中
// .google.protobuf.Any data = 4;bool has_data() const;void clear_data();const ::PROTOBUF_NAMESPACE_ID::Any& data() const;PROTOBUF_NODISCARD ::PROTOBUF_NAMESPACE_ID::Any* release_data();::PROTOBUF_NAMESPACE_ID::Any* mutable_data();void set_allocated_data(::PROTOBUF_NAMESPACE_ID::Any* data);void unsafe_arena_set_allocated_data(::PROTOBUF_NAMESPACE_ID::Any* data);::PROTOBUF_NAMESPACE_ID::Any* unsafe_arena_release_data();
has_data函数用来判断data是否被设置了值。
下面是Any类的一些函数:
bool PackFrom(const ::PROTOBUF_NAMESPACE_ID::Message& message) {GOOGLE_DCHECK_NE(&message, this);return _impl_._any_metadata_.PackFrom(GetArena(), message);}bool PackFrom(const ::PROTOBUF_NAMESPACE_ID::Message& message,::PROTOBUF_NAMESPACE_ID::ConstStringParam type_url_prefix) {GOOGLE_DCHECK_NE(&message, this);return _impl_._any_metadata_.PackFrom(GetArena(), message, type_url_prefix);}bool UnpackTo(::PROTOBUF_NAMESPACE_ID::Message* message) const {return _impl_._any_metadata_.UnpackTo(message);}static bool GetAnyFieldDescriptors(const ::PROTOBUF_NAMESPACE_ID::Message& message,const ::PROTOBUF_NAMESPACE_ID::FieldDescriptor** type_url_field,const ::PROTOBUF_NAMESPACE_ID::FieldDescriptor** value_field);template <typename T, class = typename std::enable_if<!std::is_convertible<T, const ::PROTOBUF_NAMESPACE_ID::Message&>::value>::type>bool PackFrom(const T& message) {return _impl_._any_metadata_.PackFrom<T>(GetArena(), message);}template <typename T, class = typename std::enable_if<!std::is_convertible<T, const ::PROTOBUF_NAMESPACE_ID::Message&>::value>::type>bool PackFrom(const T& message,::PROTOBUF_NAMESPACE_ID::ConstStringParam type_url_prefix) {return _impl_._any_metadata_.PackFrom<T>(GetArena(), message, type_url_prefix);}template <typename T, class = typename std::enable_if<!std::is_convertible<T, const ::PROTOBUF_NAMESPACE_ID::Message&>::value>::type>bool UnpackTo(T* message) const {return _impl_._any_metadata_.UnpackTo<T>(message);}template<typename T> bool Is() const {return _impl_._any_metadata_.Is<T>();}
PackFrom函数就是将传入的值转换成Any里面的值
UnpackTo函数就是将Any里的值转换成传入的值
Is函数就是判断Any里的值的类型是否是T
oneof
// string qq = 5;bool has_qq() const;void clear_qq();const std::string& qq() const;template <typename ArgT0 = const std::string&, typename... ArgT>void set_qq(ArgT0&& arg0, ArgT... args);std::string* mutable_qq();PROTOBUF_NODISCARD std::string* release_qq();void set_allocated_qq(std::string* qq);// string wechat = 6;bool has_wechat() const;void clear_wechat();const std::string& wechat() const;template <typename ArgT0 = const std::string&, typename... ArgT>void set_wechat(ArgT0&& arg0, ArgT... args);std::string* mutable_wechat();PROTOBUF_NODISCARD std::string* release_wechat();void set_allocated_wechat(std::string* wechat);void clear_other_contant();OtherContantCase other_contant_case() const;
has_qq函数和has_wechat函数分别是用来判断字段是否被设值了。
clear_other_contant函数使用来清理oneof字段的。
other_contant_case函数用来判断设置了哪个字段,它返回一个枚举值。
enum OtherContantCase {kQq = 5,kWechat = 6,OTHER_CONTANT_NOT_SET = 0,};
oneof的一些规则:
- oneof里的字段会被定义为枚举类型;
- oneof里的字段可能会有很多,但oneof里的值总是只会保留最后一次设置的那个字段的值;
- oneof里的字段不能被repeated修饰。
map
// map<string, string> remark = 7;int remark_size() const;void clear_remark();const ::PROTOBUF_NAMESPACE_ID::Map< std::string, std::string >& remark() const;::PROTOBUF_NAMESPACE_ID::Map< std::string, std::string >* mutable_remark();
map的一些规则:
- key-type必须是除float和bytes之外的标量数据类型;
- value-type可以是任意类型;
- map字段不可以被repeated修饰;
- map中存入的元素是无序的。
ProtoBuf的序列和反序列化方法
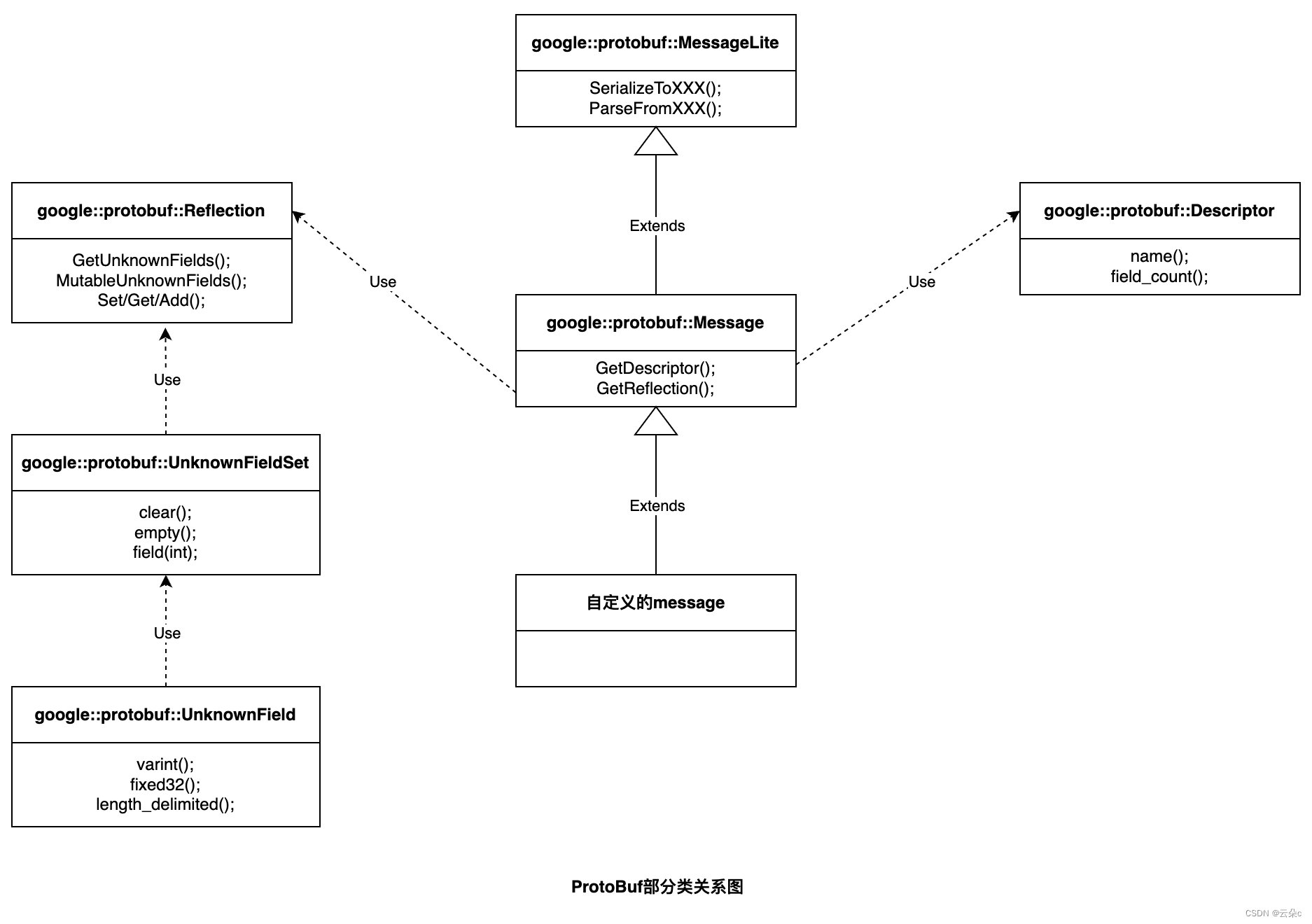
ProtoBuf的序列和反序列化方法就在MessageLite中,其中Parse系列是反序列化函数,Serialize系列是序列化函数。
// Parsing ---------------------------------------------------------// Methods for parsing in protocol buffer format. Most of these are// just simple wrappers around MergeFromCodedStream(). Clear() will be// called before merging the input.// Fill the message with a protocol buffer parsed from the given input// stream. Returns false on a read error or if the input is in the wrong// format. A successful return does not indicate the entire input is// consumed, ensure you call ConsumedEntireMessage() to check that if// applicable.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromCodedStream(io::CodedInputStream* input);// Like ParseFromCodedStream(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromCodedStream(io::CodedInputStream* input);// Read a protocol buffer from the given zero-copy input stream. If// successful, the entire input will be consumed.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromZeroCopyStream(io::ZeroCopyInputStream* input);// Like ParseFromZeroCopyStream(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromZeroCopyStream(io::ZeroCopyInputStream* input);// Parse a protocol buffer from a file descriptor. If successful, the entire// input will be consumed.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromFileDescriptor(int file_descriptor);// Like ParseFromFileDescriptor(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromFileDescriptor(int file_descriptor);// Parse a protocol buffer from a C++ istream. If successful, the entire// input will be consumed.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromIstream(std::istream* input);// Like ParseFromIstream(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromIstream(std::istream* input);// Read a protocol buffer from the given zero-copy input stream, expecting// the message to be exactly "size" bytes long. If successful, exactly// this many bytes will have been consumed from the input.bool MergePartialFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input,int size);// Like ParseFromBoundedZeroCopyStream(), but accepts messages that are// missing required fields.bool MergeFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input, int size);PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input, int size);// Like ParseFromBoundedZeroCopyStream(), but accepts messages that are// missing required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromBoundedZeroCopyStream(io::ZeroCopyInputStream* input, int size);// Parses a protocol buffer contained in a string. Returns true on success.// This function takes a string in the (non-human-readable) binary wire// format, matching the encoding output by MessageLite::SerializeToString().// If you'd like to convert a human-readable string into a protocol buffer// object, see google::protobuf::TextFormat::ParseFromString().PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromString(ConstStringParam data);// Like ParseFromString(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromString(ConstStringParam data);// Parse a protocol buffer contained in an array of bytes.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParseFromArray(const void* data,int size);// Like ParseFromArray(), but accepts messages that are missing// required fields.PROTOBUF_ATTRIBUTE_REINITIALIZES bool ParsePartialFromArray(const void* data,int size);// Reads a protocol buffer from the stream and merges it into this// Message. Singular fields read from the what is// already in the Message and repeated fields are appended to those// already present.//// It is the responsibility of the caller to call input->LastTagWas()// (for groups) or input->ConsumedEntireMessage() (for non-groups) after// this returns to verify that the message's end was delimited correctly.//// ParseFromCodedStream() is implemented as Clear() followed by// MergeFromCodedStream().bool MergeFromCodedStream(io::CodedInputStream* input);// Like MergeFromCodedStream(), but succeeds even if required fields are// missing in the input.//// MergeFromCodedStream() is just implemented as MergePartialFromCodedStream()// followed by IsInitialized().bool MergePartialFromCodedStream(io::CodedInputStream* input);// Merge a protocol buffer contained in a string.bool MergeFromString(ConstStringParam data);// Serialization ---------------------------------------------------// Methods for serializing in protocol buffer format. Most of these// are just simple wrappers around ByteSize() and SerializeWithCachedSizes().// Write a protocol buffer of this message to the given output. Returns// false on a write error. If the message is missing required fields,// this may GOOGLE_CHECK-fail.bool SerializeToCodedStream(io::CodedOutputStream* output) const;// Like SerializeToCodedStream(), but allows missing required fields.bool SerializePartialToCodedStream(io::CodedOutputStream* output) const;// Write the message to the given zero-copy output stream. All required// fields must be set.bool SerializeToZeroCopyStream(io::ZeroCopyOutputStream* output) const;// Like SerializeToZeroCopyStream(), but allows missing required fields.bool SerializePartialToZeroCopyStream(io::ZeroCopyOutputStream* output) const;// Serialize the message and store it in the given string. All required// fields must be set.bool SerializeToString(std::string* output) const;// Like SerializeToString(), but allows missing required fields.bool SerializePartialToString(std::string* output) const;// Serialize the message and store it in the given byte array. All required// fields must be set.bool SerializeToArray(void* data, int size) const;// Like SerializeToArray(), but allows missing required fields.bool SerializePartialToArray(void* data, int size) const;// Make a string encoding the message. Is equivalent to calling// SerializeToString() on a string and using that. Returns the empty// string if SerializeToString() would have returned an error.// Note: If you intend to generate many such strings, you may// reduce heap fragmentation by instead re-using the same string// object with calls to SerializeToString().std::string SerializeAsString() const;// Like SerializeAsString(), but allows missing required fields.std::string SerializePartialAsString() const;// Serialize the message and write it to the given file descriptor. All// required fields must be set.bool SerializeToFileDescriptor(int file_descriptor) const;// Like SerializeToFileDescriptor(), but allows missing required fields.bool SerializePartialToFileDescriptor(int file_descriptor) const;// Serialize the message and write it to the given C++ ostream. All// required fields must be set.bool SerializeToOstream(std::ostream* output) const;// Like SerializeToOstream(), but allows missing required fields.bool SerializePartialToOstream(std::ostream* output) const;
默认值
若某些字段未设置值时就被序列化和反序列化,此时该字段将被设置成默认值。
| 类型 | 默认值 |
|---|---|
| 字符串 | 空字符串 |
| 字节 | 空字节 |
| 布尔值 | false |
| 数值类型 | 0 |
| 枚举 | 第一个枚举 |
| 设置了repeated的字段 | 一般为相应语言的空列表 |
| message字段、oneof字段、Any字段 | 无默认值,可用has方法检测该字段是否被设置 |
更新消息
在实际开发中,有可能会出现这样的情况:一端的消息是用旧版本pb序列化的,而另一段用新版本pb(字段或者字段编号发生变化)反序列化该消息。而这会导致反序列化消息时出现数据损坏、隐私错误等问题。
解决办法就是,遵循如下规则:
- 禁止修改任何已经存在的字段编号;
- 如果移除字段编号,要保证以后不再使用此字段编号(正确做法应该保留该字段编号);
- int32、uint32、int64、uint64、bool是完全兼容的,如果类型不匹配,则采用截断做法;
- sint32和sint64相互兼容;
- string和bytes在UTF-8下相互兼容;
- fixed32和sfixed32相互兼容,fixed64和sfixed64相互兼容;
- enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序
列化消息时会根据语⾔采⽤不同的处理⽅案:例如,未识别的proto3枚举类型会被保存在消息
中,但是当消息反序列化时如何表⽰是依赖于编程语⾔的。整型字段总是会保持其的值。- oneof:
- 将⼀个单独的值更改为新oneof类型成员之⼀是安全和⼆进制兼容的。
- 若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新oneof类型也是可⾏的。
- 将任何字段移⼊已存在的oneof类型是不安全的。
使用reserved关键字可以更加有效的解决使用字段编号错误的问题。
message Message {reserved 3, 4, 200 to 300;// 保留字段编号3和4和200至300reserved field3, field4;// 保留字段名称field3和field4// 当设置了上述保留字段后,若使用下面代码,则会报错string field1 = 3;string field2 = 250;string field3 = 5;
}
未知字段
在实际开发中,有可能会出现这样的情况:一端在用旧版本pb反序列化消息,而另一段在用新版本pb(引入新字段)序列化消息。而这就会导致在反序列化消息时,无法识别引入的新字段从而无法正常操作相关字段,而在3.5版本以后的pb引入了一个机制:在反序列化时,将无法识别的字段放入未知字段中,并且提供了一堆方法去操作相关字段。
ProtoBuf部分类关系图中的Reflection类提供了一些读写字段的方法,而其中的GetUnknownFields方法就是获取未知字段的Set,也就是获取了一个UnknownFieldSet类,该类通过调用field_count方法得到每个未知字段的下标再调用field(int)方法就能够获取相应下标的未知字段,也就是获取了一个UnknownField类,该类提供了一些方法操作该未知字段,比如想获取该未知字段的值:调用number方法获取字段编号,调用type方法获取字段类型,然后根据字段类型去调用相应类型的一个函数就能够得到值(比如调用type获取到了TYPE_VARINT,那么就调用varint函数)。
class PROTOBUF_EXPORT UnknownFieldSet {inline void Clear();void ClearAndFreeMemory();inline bool empty() const;inline int field_count() const; inline const UnknownField& field(int index) const;inline UnknownField* mutable_field(int index);// Adding fields ---------------------------------------------------void AddVarint(int number, uint64_t value);void AddFixed32(int number, uint32_t value);void AddFixed64(int number, uint64_t value);void AddLengthDelimited(int number, const std::string& value);std::string* AddLengthDelimited(int number);UnknownFieldSet* AddGroup(int number);// Parsing helpers ------------------------------------------------- // These work exactly like the similarly-named methods of Message.bool MergeFromCodedStream(io::CodedInputStream* input);bool ParseFromCodedStream(io::CodedInputStream* input);bool ParseFromZeroCopyStream(io::ZeroCopyInputStream* input);bool ParseFromArray(const void* data, int size);inline bool ParseFromString(const std::string& data) { return ParseFromArray(data.data(), static_cast<int>(data.size()));}// Serialization.bool SerializeToString(std::string* output) const; bool SerializeToCodedStream(io::CodedOutputStream* output) const;static const UnknownFieldSet& default_instance();
};class PROTOBUF_EXPORT UnknownField {public:enum Type {TYPE_VARINT,TYPE_FIXED32,TYPE_FIXED64,TYPE_LENGTH_DELIMITED,TYPE_GROUP};inline int number() const;inline Type type() const;// Accessors -------------------------------------------------------// Each method works only for UnknownFields of the corresponding type.inline uint64_t varint() const;inline uint32_t fixed32() const;inline uint64_t fixed64() const;inline const std::string& length_delimited() const;inline const UnknownFieldSet& group() const;inline void set_varint(uint64_t value);inline void set_fixed32(uint32_t value);inline void set_fixed64(uint64_t value); inline void set_length_delimited(const std::string& value);inline std::string* mutable_length_delimited();inline UnknownFieldSet* mutable_group();
};
举例输出未知字段值:
const Reflection* reflection = PeopleInfo::GetReflection();
const UnknownFieldSet& set = reflection->GetUnknownFields(people);
for (int i = 0; i < set.field_count(); ++i) {const UnknownField& unknown_field = set.field(i);std::cout << "未知字段" << i + 1 << ": "<< "编号" << unknown_field.number();switch(unknown_set.type()) {case UnknownField::Type::TYPE_VARINT:std::cout << " 值:" << unknown_field.varint() << std::endl;break;case UnknownField::Type::TYPE_LENGTH_DELIMITED:std::cout << " 值:" << unknown_field.length_delimited() << std::endl;break;// case ...}
}
选项option
optimize_for:该选项为⽂件选项,可以设置protoc编译器的优化级别,分别为SPEED 、CODE_SIZE 、LITE_RUNTIME 。
受该选项影响,设置不同的优化级别,编译.proto⽂件后⽣成的代码内容不同。
- SPEED:protoc编译器将⽣成的代码是⾼度优化的,代码运⾏效率⾼,但是由此⽣成的代码编译后会占⽤更多的空间。SPEED 是默认选项。
- CODE_SIZE:proto编译器将⽣成最少的类,会占⽤更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和SPEED 恰恰相反,它的代码运⾏效率较低。这种⽅式适合⽤在包含⼤量的.proto⽂件,但并不盲⽬追求速度的应⽤中。
- LITE_RUNTIME:⽣成的代码执⾏效率⾼,同时⽣成代码编译后的所占⽤的空间也是⾮常少。这是以牺牲ProtocolBuffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,所以我们在链接BP库时仅需链接libprotobuf-lite,⽽⾮libprotobuf。这种模式常⽤于资源有限的平台,例如移动⼿机平台中。
option optimize_for = LITE_RUNTIME;
基于ProtoBuf制作的网络通讯录以及ProtoBuf和Json性能的比较源码
https://github.com/bytenan/ProtoBuf