文章目录
- 一、背景
- 二、相关工作
- 2.1 唇形同步的 audio-to-motion
- 2.2 真实人像渲染
- 三、方法
- 3.1 对 GeneFace 的继承
- 3.2 GeneFace++ 的结构
- 3.2.1 Pitch-Aware Audio-to-Motion Transform
- 3.2.2 Landmark Locally Linear Embedding
- 3.2.3 Instant Motion-to-Video Rendering
- 四、效果
论文:GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation
代码:https://genefaceplusplus.github.io/ [未开源]
出处:浙大 | 字节
时间:2023.10
论文:GENEFACE: GENERALIZED AND HIGH-FIDELITY AUDIO-DRIVEN 3D TALKING FACE SYNTHESIS
代码:https://github.com/yerfor/GeneFace
出处:ICLR2023 | 浙大、字节
时间:2023.01
一、背景
talking face 生成任务期望能够实现对于任意的输入音频生成高质量高保真的说话视频
最近,NeRF 在这个领域受到了很大的关注,其只需要几分钟的训练视频,就可以渲染出高保真的 3D 说话视频
但是,基于 NeRF 的方法有以下几个挑战:
- 在唇形同步方面,很难生成具有高时间一致性和音频-唇形准确度的长时间面部运动序列。
- 在视频质量方面,由于用于训练渲染器的数据有限,它容易受到域外输入条件的影响,并偶尔产生不良的渲染结果
- 在系统效率方面,原始NeRF(神经辐射场)的慢速训练和推理速度严重阻碍了其在实际应用中的使用。
所以,GeneFace++ 做出了如下改进:
- 利用音调轮廓作为辅助特征,并在面部运动预测过程中引入时间损失
- 提出了一种 landmark locally linear embedding 方法,用于调节预测运动序列中的异常值
- 设计了一种基于NeRF(神经辐射场)的高效运动到视频渲染器,实现快速训练和实时推理。
有了这些改进,GeneFace++ 成为首个实现稳定且实时的具有泛化音频-唇形同步功能的说话脸部生成的基于 NeRF 的方法
二、相关工作
2.1 唇形同步的 audio-to-motion
在唇部同步运动预测中,主要有两个挑战:
-
第一个挑战是所谓的一对多映射问题,这意味着同样的输入音频可能有几个合理的对应面部运动。早期的工作 [49, 47, 6] 直接使用回归损失(例如,L2)学习确定性模型,并因此导致过度平滑的唇部结果。Wav2Lip [30] 第一次利用判别同步专家实现更为清晰和准确的唇部运动,后续工作[48, 45, 22, 19, 34]也采用了这种方法。MemFace[36]引入音频到运动中的记忆检索以缓解一对多问题。
-
第二个挑战是在给定长时间输入音频时生成时间一致且稳定的运动序列。[24]采用自回归结构来模拟时间序列,但受限于慢速推理和误差累积。其他工作[41,12]使用并行结构(如1D卷积)与滑动窗口,这在一定程度上解决了自回归方法的不足。Transformer-s2a [7] 和 GeneFace [42] 使用前馈结构(自我注意力和卷积)来并行处理整个音频序列。这种框架具有高效率和建模长期信息能力,但在保持生成运动序列中时间连贯性和稳定性方面不太好。
2.2 真实人像渲染
动态人像合成的技术可以分为三类:
- 基于2D的方法:[39, 35, 30, 49, 46, 48],他们采用GANs [10]或图像到图像转换[17]作为图像渲染器。虽然这些方法达到了良好的图像质量,但由于缺乏3D几何建模,它们无法生成可控制姿态的视频。
- 基于3D Morphable Model [29] (3DMM)的方法:基于3DMM的方法[41,38,44]通过使用3DMM系数作为辅助条件注入了对三维先验知识,但使用3DMM作为中间处理已知会导致信息丢失,并降低性能。
- 神经渲染法:神经渲染法[3、9、31、15、50] 采用 NeRF [25] 或其变种来对人像进行三维建模。AD-NeRF 是第一个基于NeRF进行面部语音合成的方法,它提出了一种端到端音频至视频 NeRF 渲染器来生成依赖于音频特征的人像,GeneFace[42] 引入 audio-to-motion 模块来改善NeRF基础上渲染器同步效果,AD-NeRF 采用离散可学习网格在 AD-NeRF 中进行训练和推理加速。
因此,GeneFace++ 使用了三部分来实现:
- audio-to-motion 阶段:引入了 pitch information 和时间平滑损失来实现合成的说话头的长时间一致性
- motion 系数鲁棒:引入了一个 projection-based 后处理来提高系统的鲁棒性
- motion-to-video 阶段:使用 grid encoder 和 deformable slicing surfaces 来实现高效和高质量的人像渲染
三、方法
3.1 对 GeneFace 的继承
GeneFace++ 延续了 GeneFace 两阶段的形式,所以,直接引用了 GeneFace 的 audio-to-motion 和 motio-to-video 阶段
1、Audio-to-Motion
在该阶段,首先使用大量的 lip-reading 数据来学习一个条件 VAE 模型,以实现根据给定的语音来生成准确且具有泛化能力的 facial landmark
VAE 的 loss 如下:

为了弥补 lip-reading dataset 和 target person video 之间的 domain gap,还使用了 domain adaptative(DA) Postnet ,主要是为了将预测的 facial motion 映射到 target person domain
DA Postnet 的 loss 如下:

这两步结束后,就可以得到 input audio 的 嘴唇同步且 personalized 的 facial landmark 了
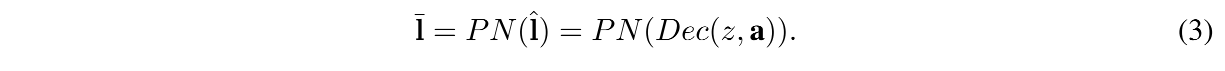
2、Motion-to-Video
在该阶段,使用 landmark-conditioned dynamic NeRF network 来渲染出人像

3.2 GeneFace++ 的结构
GeneFace++ 其实主要是为了提升 GeneFace 的效果,达到更自然的音唇同步,更鲁棒的高质量,更快的训练速度
如图 1a,GeneFace++ 有三个阶段:
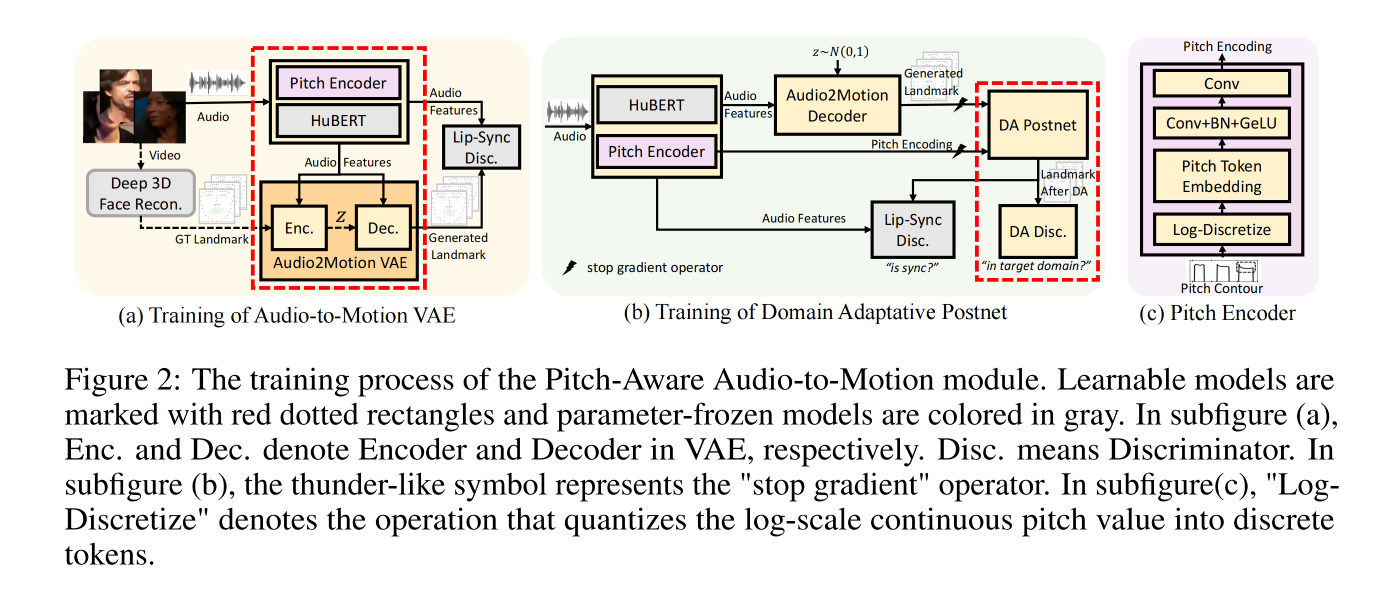
- pitch-aware audio-to-motion module:将 audio feature 转换成 facial motion
- landmark locally linear embedding method:对预测的 motion 进行后处理
- instant motion-to-video module:将预测的 motion 系数渲染成真实人像

3.2.1 Pitch-Aware Audio-to-Motion Transform

3.2.2 Landmark Locally Linear Embedding


3.2.3 Instant Motion-to-Video Rendering

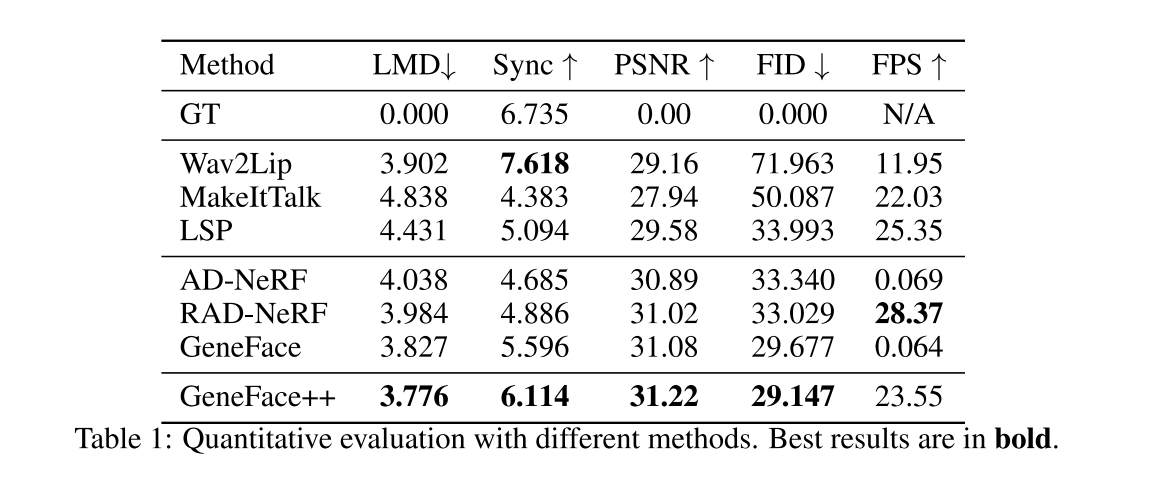
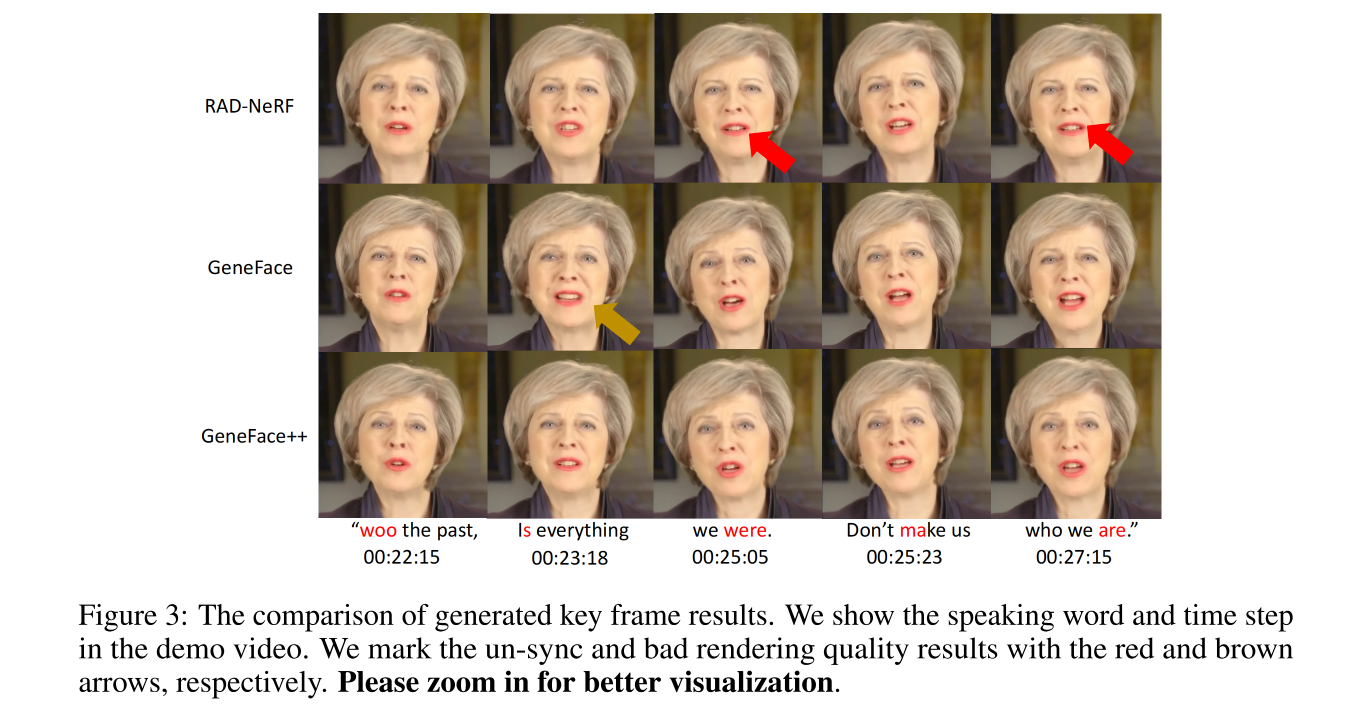
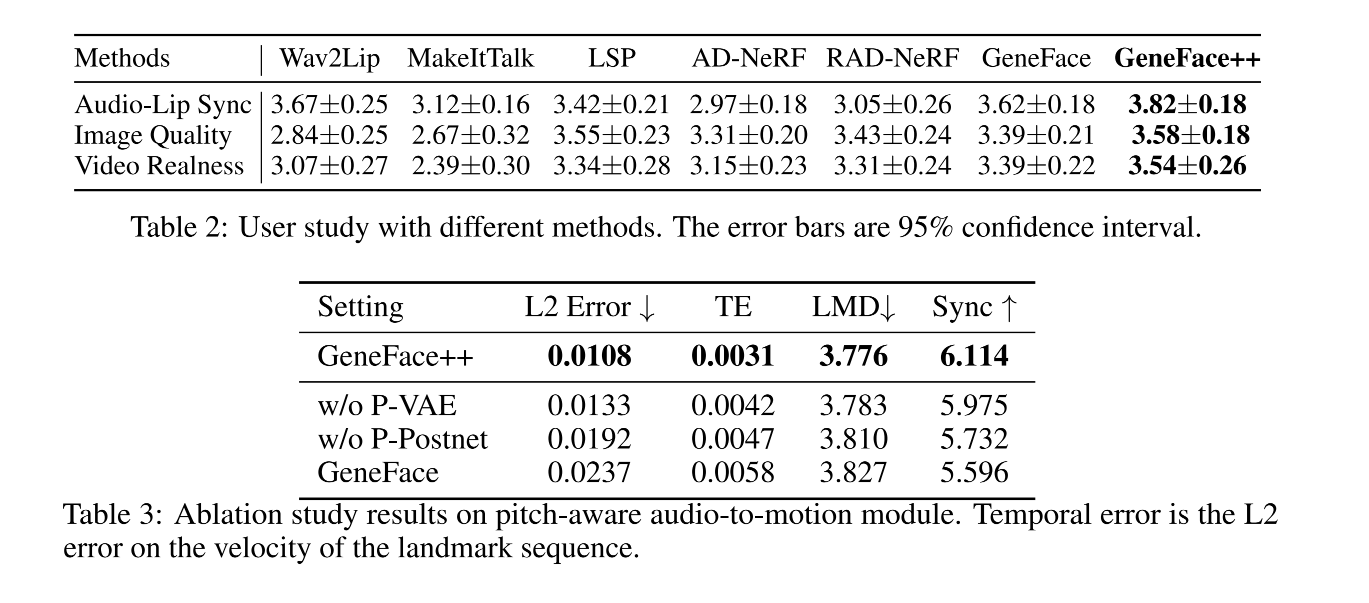
四、效果