全Serverless架构新价值
随着Amazon OpenSearch Serverless正式上线“商用”,亚马逊云科技的全栈“Serverless”应用架构也“初见雏形”,这也意味着,未来企业可以在亚马逊云科技之上简单和轻松的搭建完整的无服务器应用架构。

数据也显示,目前亚马逊云科技Serverless服务的活跃用户超过100万,同时每月的调用请求量超过100万亿次,可以说亚马逊云科技在Serverless领域的领导地位获得了客户和行业的广泛认可。

但是,亚马逊云科技的创新步伐“并未止步”,以Amazon Lambda服务为例,八年前发布的Lambda虽然展示了亚马逊云科技对 Serverless 的愿景,但不可否认的是,当时的Serverless技术仍旧不够成熟,直到本次re:Invent 2022,Lambda SnapStart新功能的推出,实现了Serverless 的冷启动速度的大幅优化,再加上其数据分析服务核心产品全面“Serverless化”完成,更真正标志着亚马逊云科技将Serverless架构真正实现了“普惠化”,相信将为更多企业上云带来更多的选择和更好的服务。
那么,Lambda SnapStart为何如此重要呢?这就需要回到用户的实际应用场景之中,Serverless服务虽然能够在需要的时候唤醒并分配虚拟机或者容器,实现了真正意义上的“按需分配”,但在具体的应用实践中,由于网络延迟等因素的出现,很容易让用户在使用这一服务时产生短暂的等待时间,严重影响用户体验。 举个通俗易懂的例子,一个智能门禁的供应商,后台应用采用的是Serverless服务,当有人刷门禁时才启动应用。在早上出门或晚上回家高峰期用户活跃时,虚拟机可能处于常开状态。在夜间或者其它时段用户不活跃时,关闭了虚拟机,这也意味着在这个时段每次启动应用,都会需要花费一定的时间——也就是说,Serverless服务的响应时间会影响到应用响应时间,进而影响用户体检,让用户感觉后台应用响应迟滞。从这个角度来看,缩短无服务器计算服务的冷启动时间对用户体验具有重要意义。

事实上,此前亚马逊云科技已经通过Firecracker microVM等技术改进,让无服务器服务启动的时间缩短到1秒以内,而这次全新发布的Lambda SnapStart功能,再次将启动时间再缩短90%,而这一功能的推出,无疑有利于更多的应用采用Serverless架构,因为它真正让Serverless服务带给企业客户的体验,就像虚拟机24小时开机、全天候服务一样,同时应用性能的一致性也有了更好的保障。
数据显示,2020年全球Serverless服务市场规模达到446.1 亿元,其中中国Serverless服务的市场规模达到63.7亿元,约占全球市场的14.3%,而随着亚马逊云科技全Serverless架构的搭建完成,相信也将会加速中国乃至全球的Serverless化进程。
配置 OpenSearch Serverless 集合
要开始使用 Amazon OpenSearch Serverless,可以通过 AWS 管理控制台、AWS 命令行接口(AWS CLI)或 AWS API 创建一个 Collection(集合)。

在启动 OpenSearch Serverless 之前,需要首先创建一个托管式集群,指定实例类型、数量和存储选项,然后管理该集群内索引的生命周期和分片策略。可以使用 OpenSearch Serverless 创建一个集合来管理一组索引,这些索引协同工作以支持特定的工作负载。不再需要直接指定硬件或管理索引。

要创建 OpenSearch Serverless 集合并保护数据,需要设置 Encryption policies(加密策略)以将 AWS KMS 密钥分配给一个或多个集合,然后将 Network policies(网络策略)附加到集合,以控制来自指定 VPC 和公有 IP 地址的访问。

要创建加密策略,请在左侧导航窗格中选择 Encryption policies(加密策略)和 Create encryption policy(创建加密策略)。静态加密可保护集合中的索引。对于每个集合,AWS KMS 都会生成一个唯一的对称加密密钥。加密策略是跨多个集合管理 AWS KMS 密钥的理想方式。可以定义目标集合名称或前缀,这会自动将此策略中的加密设置应用到集合。

要允许用户访问集合,请在左侧导航窗格中选择 Network policies(网络策略),然后选择 Create network policy(创建网络策略)。网络策略决定了的集合是否可以通过互联网从公共网络访问,还是必须通过 OpenSearch Serverless 托管式 VPC 端点进行访问。
可以为每个集合定义多条规则,Access Type(访问类型)可以是 Public(公有)或 VPC,后者是推荐选项。如果选择公有选项,则可以从 OpenSearch 控制面板访问集合。此外,可以配置 OpenSearch 控制面板和 OpenSearch 端点的访问权限。对于 esource type(资源类型),请同时启用对 OpenSearch 端点的访问和对 OpenSearch 控制面板的访问。在这两个输入框中,选择 Collection Name 属性和的集合名称或前缀。最后,要创建 OpenSearch Serverless 集合,请在主页中选择 Create collection(创建集合),或者在左侧导航窗格中选择 Collections(集合),然后选择 Create collection(创建集合)。

上传和搜索集合中的数据
以下示例策略为单个用户提供了在的集合中创建索引、为某些数据创建索引以及进行搜索所需的最低权限。请将主体 ARN 替换为将用于登录 OpenSearch 控制面板的账户的 ARN。
[{"Rules": [{"ResourceType": "index","Resource": ["index/books/*"],"Permission": ["aoss:CreateIndex","aoss:ReadDocument","aoss:UpdateIndex","aoss:DeleteIndex","aoss:WriteDocument"]}],"Principal": ["arn:aws:iam::123456789012:user/admin"]}
]现在,可以使用 Postman 或 curl 将数据上传到 OpenSearch Serverless 集合。也可以在 OpenSearch 控制面板控制台中使用开发工具。在集合的详细信息页面上选择 OpenSearch Dashboards(OpenSearch 控制面板)。

使用在数据访问策略中为主体指定的 AWS 访问密钥和秘密密钥登录 OpenSearch 控制面板。在 OpenSearch 控制面板中,打开左侧导航菜单并选择 Dev Tools(开发工具)。要创建一个名为 books-index 的单一索引,请运行 PUT books-index,然后将第一个单一文档索引到 books-index 中。
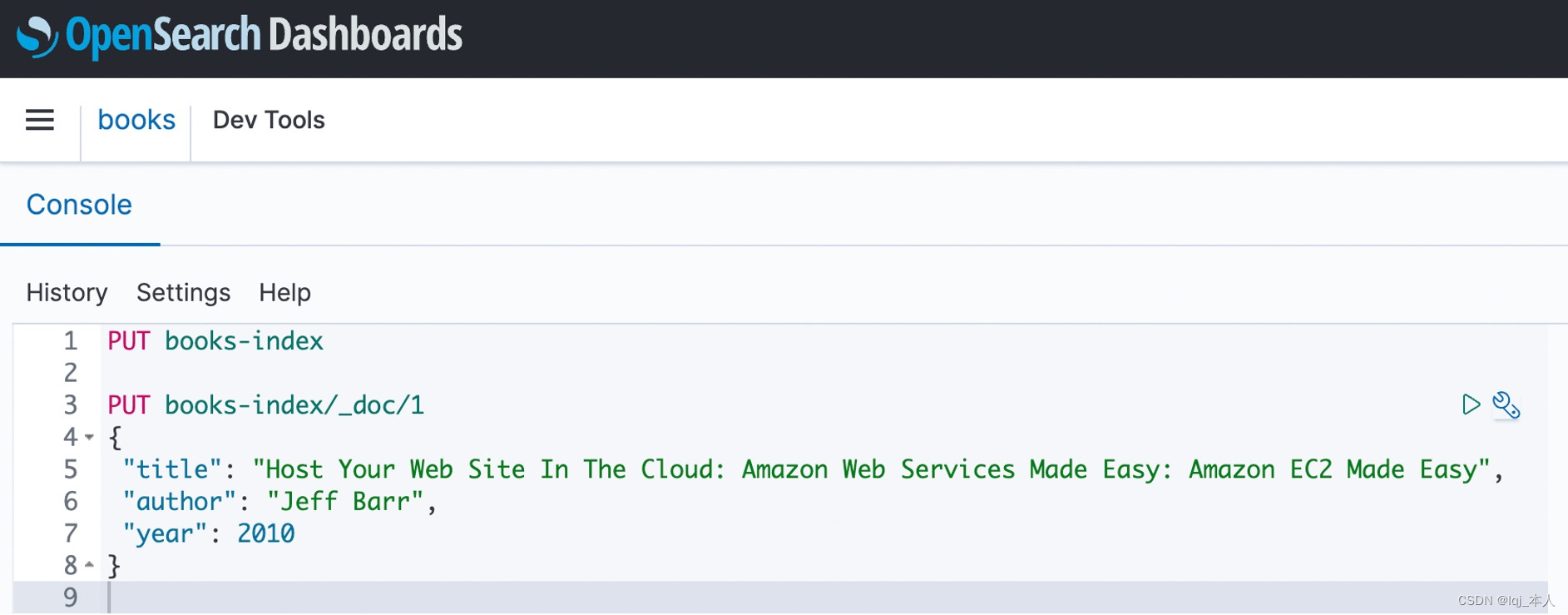
也可以在开发工具中查询搜索数据。
GET books_index/_search
{"query": {"simple_query_string": {"query": "Jeff","fields": ["author"]} }
}对于时间序列数据,可以使用所有串流摄取选项来摄取数据,例如原生的 OpenSearch 串流 API、Amazon Kinesis Data Firehose、AWS Glue 以及各种开源串流摄取管道,例如 Logstash、FluentBit、Fluentd 和 Data Prepper。
此外,可以从 OpenSearch Service 上的托管式集群拍摄数据快照,然后将其还原到集合中,从而轻松迁移工作负载。数据进入集合后,可以使用自己喜欢的 OpenSearch 客户端对其进行查询,并使用 OpenSearch 控制面板以交互方式分析以及实现数据可视化。