前端为什么要工程化
文章目录
- 前端为什么要工程化
- 传统开发的弊端
- 一个常见的案例
- 更多问题
- 工程化带来的优势
- 开发层面的优势
- 团队协作的优势
- 统一的项目结构
- 统一的代码风格
- 可复用的模块和组件
- 代码健壮性有保障
- 团队开发效率高
- 求职竞争上的优势
现在前端的工作与以前的前端开发已经完全不同了。
刚接触前端的时候,做一个页面,是先创建 HTML 页面文件写页面结构,再在里面写 CSS 代码美化页面,再根据需要写一些 JavaScript 代码增加交互功能,需要几个页面就创建几个页面,相信大家的前端起步都是从这个模式开始的。
而实际上的前端开发工作,早已进入了前端工程化开发的时代,已经充满了各种现代化框架、预处理器、代码编译…
最终的产物也不再单纯是多个 HTML 页面,经常能看到 SPA / SSR / SSG 等词汇的身影。
传统开发的弊端
在了解什么是前端工程化之前,先回顾一下传统开发存在的一些弊端,这样更能知道为什么需要它。
在传统的前端开发模式下,前端工程师大部分只需要单纯的写写页面,都是在 HTML 文件里直接编写代码,所需要的 JavaScript 代码是通过 script 标签以内联或者文件引用的形式放到 HTML 代码里的,当然 CSS 代码也是一样的处理方式。
例如这样:
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta http-equiv="X-UA-Compatible" content="IE=edge" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title></head><body><!-- 引入 JS 文件 --><script src="./js/lib-1.js"></script><script src="./js/lib-2.js"></script><!-- 引入 JS 文件 --></body>
</html>
如演示代码,虽然可以把代码分成多个文件来维护,这样可以有效降低代码维护成本,但在实际开发过程中,还是会存在代码运行时的一些问题。
一个常见的案例
继续用上面的演示代码,来看一个最简单的一个例子。
先在 lib-1.js 文件里,声明一个变量:
js
var foo = 1
再在 lib-2.js 文件里,也声明一个变量(没错,也是 foo ):
js
var foo = 2
然后在 HTML 代码里追加一个 script ,打印这个值:
html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><!-- 引入 JS 文件 --><script src="./js/lib-1.js"></script><script src="./js/lib-2.js"></script><!-- 引入 JS 文件 --><!-- 假设这里是实际的业务代码 --><script>console.log(foo)</script><!-- 假设这里是实际的业务代码 --></body>
</html>
先猜猜会输出什么? —— 答案是 2 。
如果在开发的过程中,不知道在 lib-2.js 文件里也声明了一个 foo 变量,一旦在后面的代码里预期了 foo + 2 === 3 ,那么这样就得不到想要的结果(因为 lib-1.js 里的 foo 是 1 , 1 + 2 等于 3 ) 。
原因是 JavaScript 的加载顺序是从上到下,当使用 var 声明变量时,如果命名有重复,那么后加载的变量会覆盖掉先加载的变量。
这是使用 var 声明的情况,它允许使用相同的名称来重复声明,那么换成 let 或者 const 呢?
虽然不会出现重复声明的情况,但同样会收到一段报错:
bash
Uncaught SyntaxError: Identifier 'foo' has already been declared (at lib-2.js:1:1)
这次程序直接崩溃了,因为 let 和 const 无法重复声明,从而抛出这个错误,程序依然无法正确运行。
更多问题
以上只是一个最简单的案例,就暴露出了传统开发很大的弊端,然而并不止于此,实际上,存在了诸如以下这些的问题:
- 如本案例,可能存在同名的变量声明,引起变量冲突
- 引入多个资源文件时,比如有多个 JS 文件,在其中一个 JS 文件里面使用了在别处声明的变量,无法快速找到是在哪里声明的,大型项目难以维护
- 类似第 1 、 2 点提到的问题无法轻松预先感知,很依赖开发人员人工定位原因
- 大部分代码缺乏分割,比如一个工具函数库,很多时候需要整包引入到 HTML 里,文件很大,然而实际上只需要用到其中一两个方法
- 由第 4 点大文件延伸出的问题,
script的加载从上到下,容易阻塞页面渲染 - 不同页面的资源引用都需要手动管理,容易造成依赖混乱,难以维护
- 如果要压缩 CSS 、混淆 JS 代码,也是要人力操作使用工具去一个个处理后替换,容易出错
当然,实际上还会有更多的问题会遇到。
工程化带来的优势
为了解决传统开发的弊端,前端也开始引入工程化开发的概念,借助工具来解决人工层面的烦琐事情。
开发层面的优势
在 传统开发的弊端 里,主要列举的是开发层面的问题,工程化首要解决的当然也是在开发层面遇到的问题。
在开发层面,前端工程化有以下这些好处:
- 引入了模块化和包的概念,作用域隔离,解决了代码冲突的问题
- 按需导出和导入机制,让编码过程更容易定位问题
- 自动化的代码检测流程,有问题的代码在开发过程中就可以被发现
- 编译打包机制可以让使用开发效率更高的编码方式,比如 Vue 组件、 CSS 的各种预处理器
- 引入了代码兼容处理的方案( e.g. Babel ),可以让自由使用更先进的 JavaScript 语句,而无需顾忌浏览器兼容性,因为最终会帮转换为浏览器兼容的实现版本
- 引入了 Tree Shaking 机制,清理没有用到的代码,减少项目构建后的体积
还有非常多的体验提升,列举不完。而对应的工具,根据用途也会有非常多的选择,在后面的学习过程中,会一步一步体验到工程化带来的好处。
团队协作的优势
除了对开发者有更好的开发体验和效率提升,对于团队协作,前端工程化也带来了更多的便利,例如下面这些场景:
统一的项目结构
以前的项目结构比较看写代码的人的喜好,虽然一般在研发部门里都有 “团队规范” 这种东西,但靠自觉性去配合的事情,还是比较难做到统一,特别是项目很赶的时候。
工程化后的项目结构非常清晰和统一,以 Vue 项目来说,通过脚手架创建一个新项目之后,它除了提供能直接运行 Hello World 的基础代码之外,还具备了如下的统一目录结构:
src是源码目录src/main.ts是入口文件src/views是路由组件目录src/components是子组件目录src/router是路由目录
虽然也可以自行调整成别的结构,但根据笔者在多年的工作实际接触下来,以及从很多开源项目的代码里看到的,都是沿用脚手架创建的项目结构(不同脚手架创建的结构会有所不同,但基于同一技术栈的项目基本上都具备相同的结构)。
统一的代码风格
不管是接手其他人的代码或者是修改自己不同时期的代码,可能都会遇到这样的情况,例如一个模板语句,上面包含了很多属性,有的人喜欢写成一行,属性多了维护起来很麻烦,需要花费较多时间辨认:
vue
<template><div class="list"><!-- 这个循环模板有很多属性 --><div class="item" :class="{ `top-${index + 1}`: index < 3 }" v-for="(item, index)in list" :key="item.id" @click="handleClick(item.id)"><span>{{ item.text }}</span></div><!-- 这个循环模板有很多属性 --></div>
</template>
而工程化配合统一的代码格式化规范,可以让不同人维护的代码,最终提交到 Git 上的时候,风格都保持一致,并且类似这种很多属性的地方,都会自动帮格式化为一个属性一行,维护起来就很方便:
vue
<template><div class="list"><!-- 这个循环模板有很多属性 --><divclass="item":class="{ `top-${index + 1}`: index < 3 }"v-for="(item, index) in list":key="item.id"@click="handleClick(item.id)"><span>{{ item.text }}</span></div><!-- 这个循环模板有很多属性 --></div>
</template>
同样的,写 JavaScript 时也会有诸如字符串用双引号还是单引号,缩进是 Tab 还是空格,如果用空格到底是要 4 个空格还是 2 个空格等一堆 “没有什么实际意义” 、但是不统一的话协作起来又很难受的问题……
在工程化项目这些问题都可以交给程序去处理,在书写代码的时候,开发者可以先按照自己的习惯书写,然后再执行命令进行格式化,或者是在提交代码的时候配合 Git Hooks 自动格式化,都可以做到统一风格。
可复用的模块和组件
传统项目比较容易被复用的只有 JavaScript 代码和 CSS 代码,会抽离公共函数文件上传到 CDN ,然后在 HTML 页面里引入这些远程资源, HTML 代码部分通常只有由 JS 创建的比较小段的 DOM 结构。
并且通过 CDN 引入的资源,很多时候都是完整引入,可能有时候只需要用到里面的一两个功能,却要把很大的完整文件都引用进来。
这种情况下,在前端工程化里,就可以抽离成一个开箱即用的 npm 组件包,并且很多包都提供了模块化导出,配合构建工具的 Tree Shaking ,可以抽离用到的代码,没有用到的其他功能都会被抛弃,不会一起发布到生产环境。
TIP
在 依赖包和插件 一节可以学习如何查找和使用开箱即用的 npm 包。
代码健壮性有保障
传统的开发模式里,只能够写 JavaScript ,而在工程项目里,可以在开发环境编写带有类型系统的 TypeScript ,然后再编译为浏览器能认识的 JavaScript 。
在开发过程中,编译器会检查代码是否有问题,比如在 TypeScript 里声明了一个布尔值的变量,然后不小心将它赋值为数值:
ts
// 声明一个布尔值变量
let bool: boolean = true// 在 TypeScript ,不允许随意改变类型,这里会报错
bool = 3
编译器检测到这个行为的时候就会抛出错误:
bash
# ...
return new TSError(diagnosticText, diagnosticCodes);^
TSError: ⨯ Unable to compile TypeScript:
src/index.ts:2:1 - error TS2322: Type 'number' is not assignable to type 'boolean'.2 bool = 3~~~~
# ...
从而得以及时发现问题并修复,减少线上事故的发生。
团队开发效率高
在前后端合作环节,可以提前 Mock 接口与后端工程师同步开发,如果遇到跨域等安全限制,也可以进行本地代理,不受跨域困扰。
前端工程在开发过程中,还有很多可以交给程序处理的环节,像前面提到的代码格式化、代码检查,还有在部署上线的时候也可以配合 CI/CD 完成自动化流水线,不像以前改个字都要找服务端工程师去更新,可以把非常多的人力操作剥离出来交给程序。
求职竞争上的优势
近几年前端开发领域的相关岗位,都会在招聘详情里出现类似的描述:
熟悉 Vue / React 等主流框架,对前端组件化和模块化有深入的理解和实践
熟悉面向组件的开发模式,熟悉 Webpack / Vite 等构建工具
熟练掌握微信小程序开发,熟悉 Taro 框架或 uni-app 框架优先
熟悉 Scss / Less / Stylus 等预处理器的使用
熟练掌握 TypeScript 者优先
有良好的代码风格,结构设计与程序架构者优先
了解或熟悉后端开发者优先(如 Java / Go / Node.js )
知名企业对 1-3 年工作经验的初中级工程师,更是明确要求具备前端工程化开发的能力:
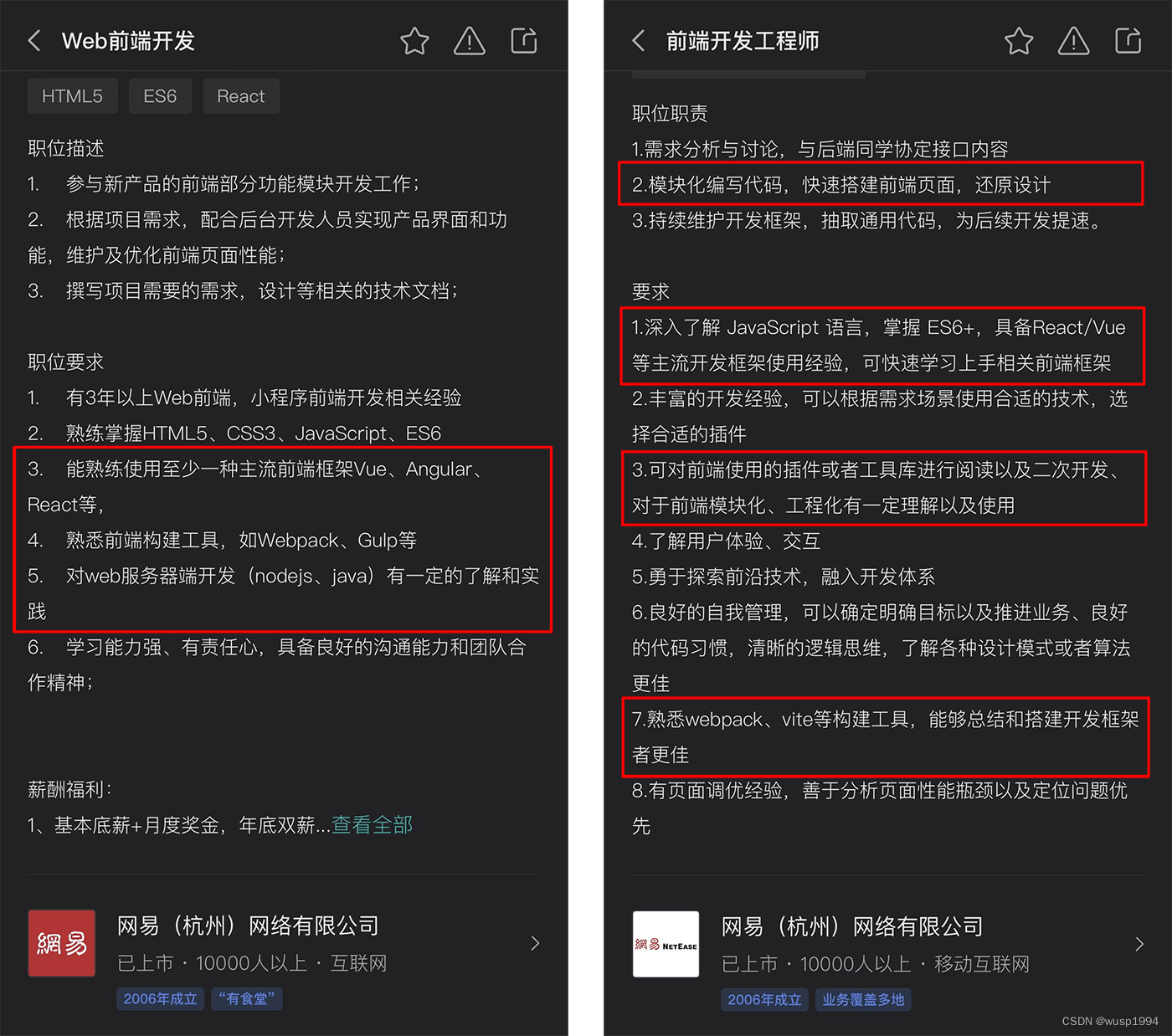
知名企业对 1-3 年经验的前端工程师招聘要求
组件化开发、模块化开发、 Webpack / Vite 构建工具、 Node.js 开发… 这些技能都属于前端工程化开发的知识范畴,不仅在面试的时候会提问,入职后新人接触的项目通常也是直接指派前端工程化项目,如果能够提前掌握相关的知识点,对求职也是非常有帮助的!