Natural Language Processing
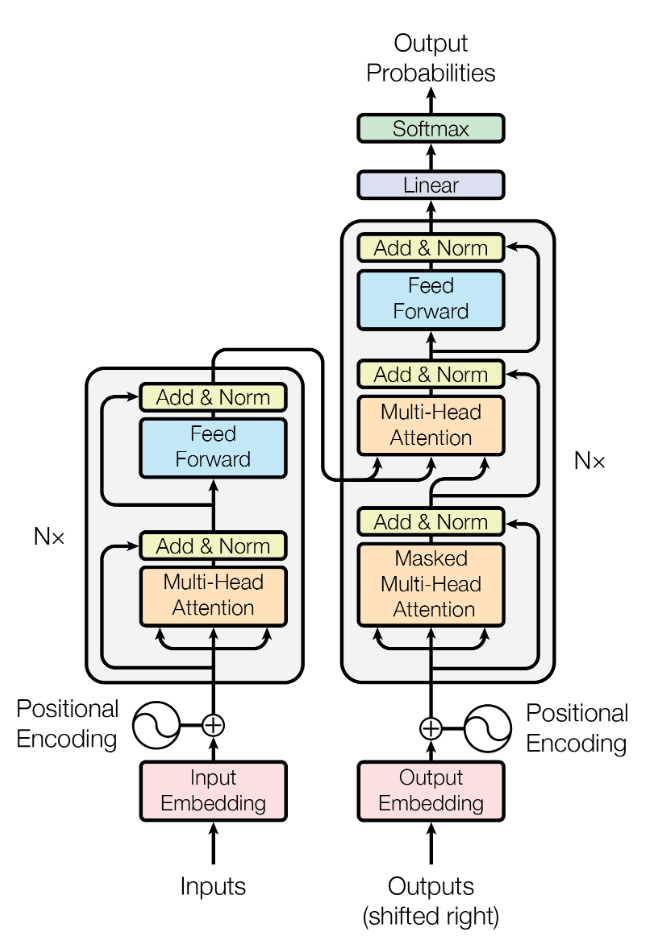
Transformer:Attention is all you need URL(46589)2017.6
- 提出Attention机制可以替代卷积框架。
- 引入Position Encoding,用来为序列添加前后文关系。
- 注意力机制中包含了全局信息
- 自注意力机制在建模序列数据中的长期依赖关系方面表现出色,因为它能够在序列中的每个位置上计算所有其他位置的注意力权重,并且能够通过这些权重来捕获全局的语义信息。但其无法显式地建模序列中的局部结构。这意味着自注意力机制在处理某些序列数据时可能会出现一些问题,比如处理具有很强局部结构的序列时可能无法捕获这种结构的信息。
- 详细见transformer
- 【Transformer】10分钟学会Transformer | Pytorch代码讲解 | 代码可运行 - 知乎 (zhihu.com)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding URL(24662)2018.10
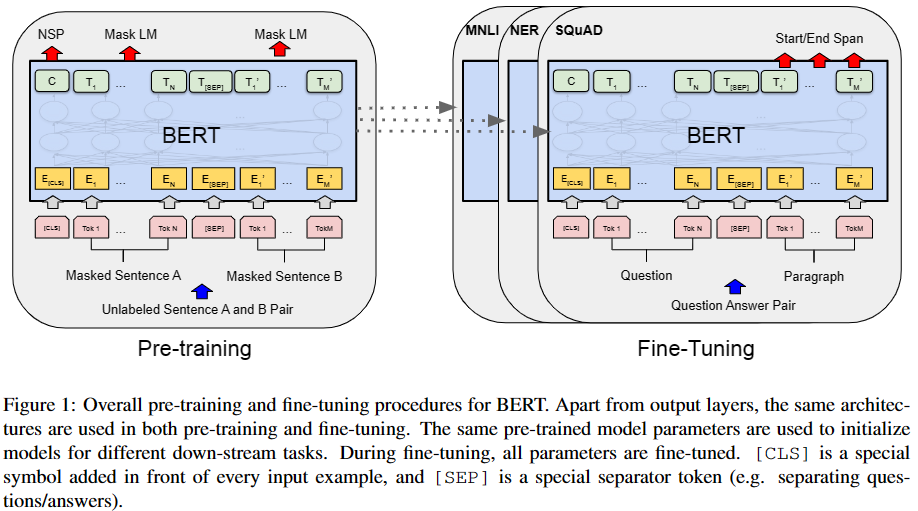
Input/Output Representations
-
采用WordPiece编码,又为了解决前后句子问题,BERT采用了两种方法去解决:
-
在组合的一序列tokens中把**分割token([SEP])**插入到每个句子后,以分开不同的句子tokens。
-
为每一个token表征都添加一个Segment Embedding来指示其属于句子A还是句子B。
-
-
在每个序列队首位置添加一个**[CLS]标记,该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用(在之后的下游**任务中,对于句子级别的任务,就把C输入到额外的输出层中,对于token级别的任务,就把其他token对应的最后一个Transformer的输出输入到额外的输出层)
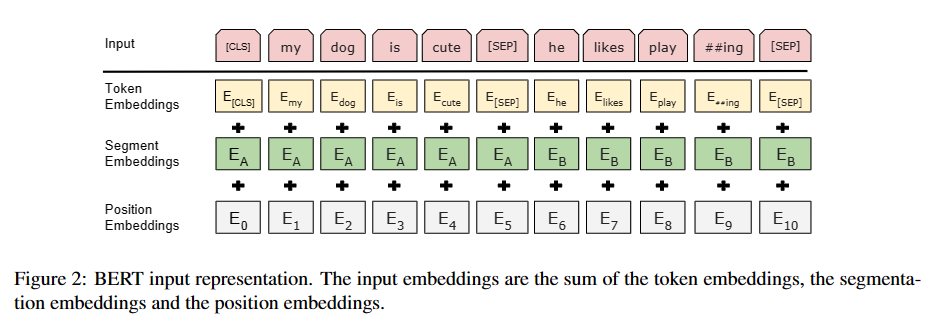
训练策略
-
Masked Language Model(MLM)改进了原始Transformer在预测时只能获取当前时刻前的信息,通过引入cloze(完形填空)的训练思路,让模型获得双向语言特征(部分语言问题本身需要通过获取双向信息才能达到更好的效果)。
-
Next Sentence Prediction(NSP),普通MLM任务只是倾向于对每个token层次的特征进行表征,但不能对相关token的句子层次特征进行表示,为了使得模型能理解句子间的关系,采用了NSP任务来进行训练。
具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句*(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)*。接下来把训练样例输入到BERT模型中,用**[CLS]对应的C信息**去进行二分类的预测。
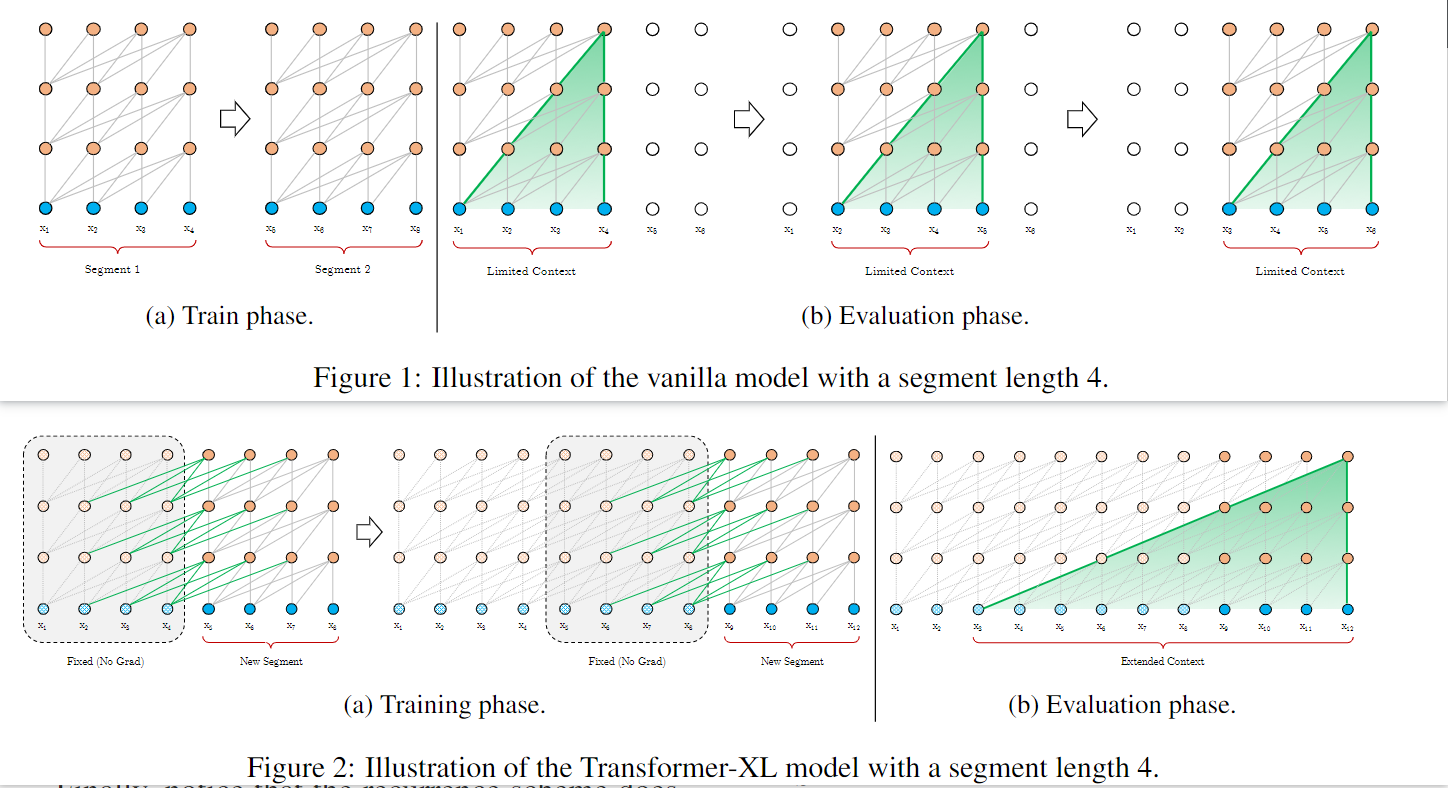
Transformer-XL: Attentive Language Models beyond a Fixed-Length Context URL(1103)2019.1
-
Segment-Level Recurrence,对于每个被segment的序列,将前一个序列计算的隐状态序列进行缓存,并利用到当前状态下的前向计算中(可以缓存多个序列)
-
提出相对位置编码:将序列每个位置信息表示为由位置偏移量和时间步数组成的向量,然后映射到固定的维度空间输入到注意力机制中
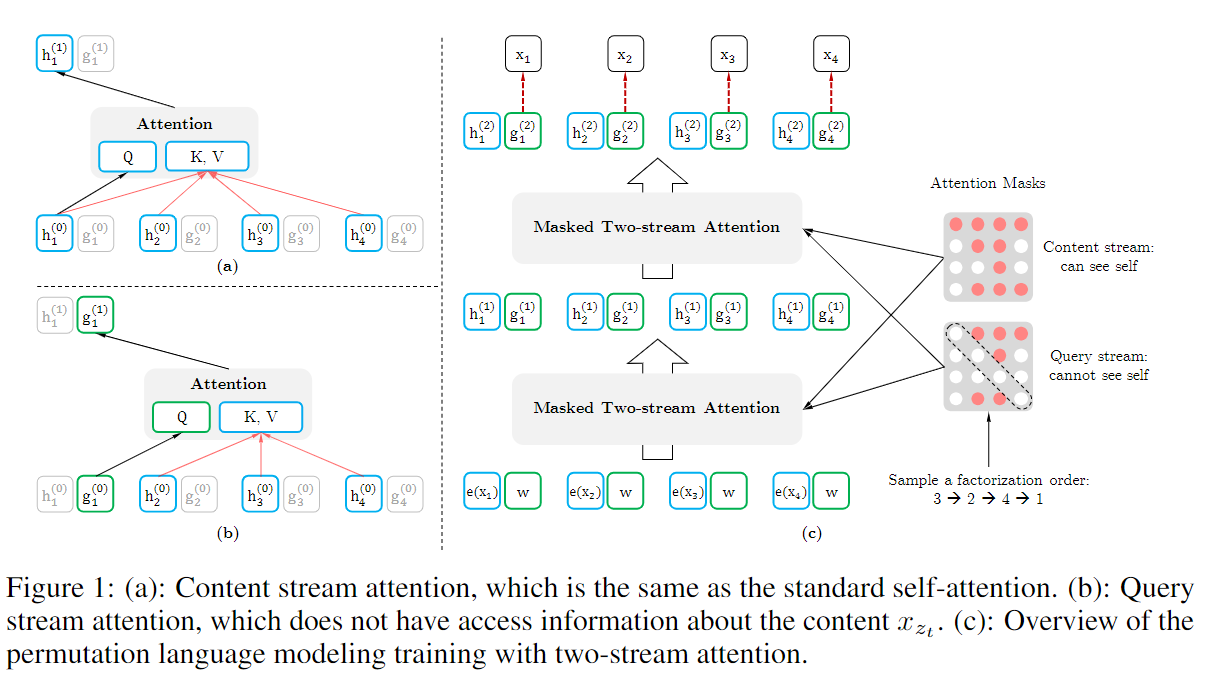
XLNet: Generalized Autoregressive Pretraining for Language URL (3062)2019.6
-
Permutation Language Modeling(随机置换语言模型),通过对序列进行permutation,让序列在以AR1模型进行输入的同时具备AE2模型能对上下文信息的优点,但此时位置编码需要修改,从而引入了Two-Stream Self-Attention。
- 由于AR模型在处理序列时只能从左到右或从右到左,即使双向叠加效果也差于BERT,但是BERT的AE模型在推理过程又是看不到的,这导致性能丢失,从而通过PLM来平衡两个步骤。
-
Two-Stream Self-Attention,引入query stream和content stream,其中query stream是用来对随机置换的序列位置进行编码,以此具有位置关系信息。
Computer Vision
VIT:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale URL (976) 2020.10
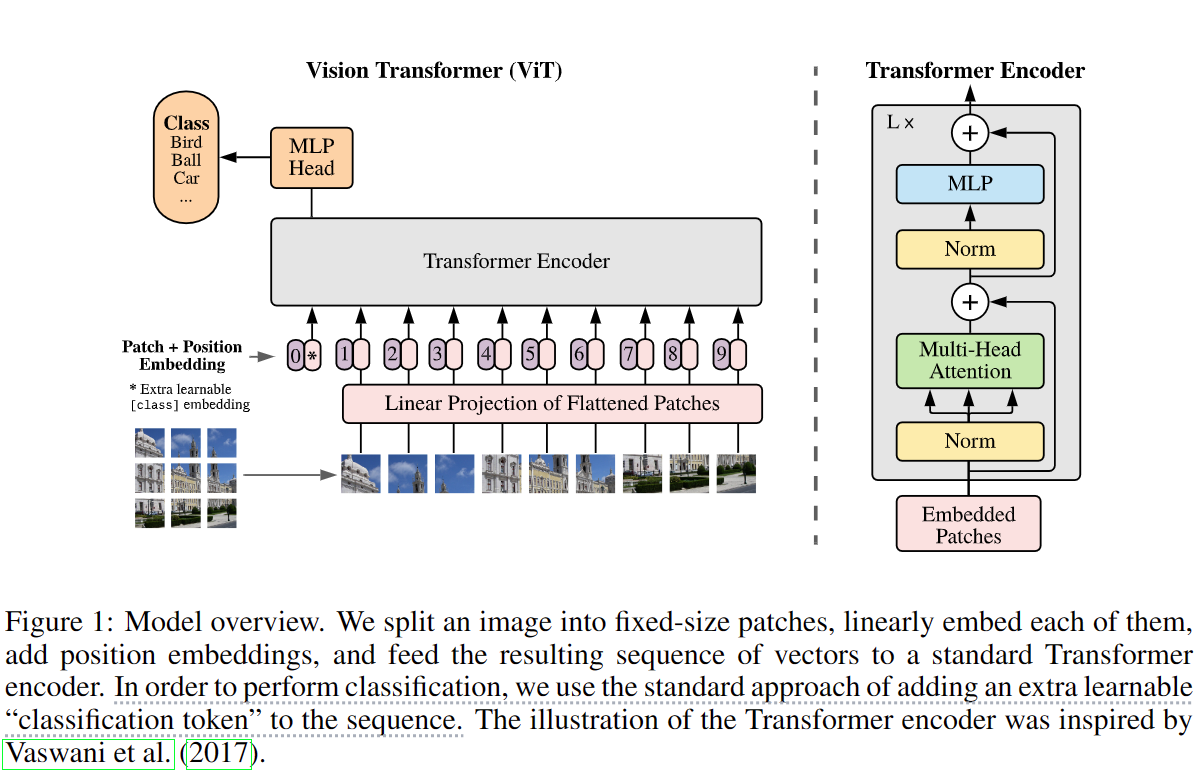
-
采用将图片分为多个patch,再将每个patch投影为固定向量作为输入,为了更好的进行下游任务进行图像分类等操作,采用和[BERT](#Input/Output Representations)相似的操作,在输入序列最前面加一个**[CLS]**标记。从而,通过patch embedding将一个视觉问题转换为了一个seq2seq问题。
-
ViT(Vision Transformer)解析 - 知乎 (zhihu.com)
Pyramid Vision Transformer:A Versatile Backbone for Dense Prediction without Convs
[2102.12122] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions (arxiv.org)
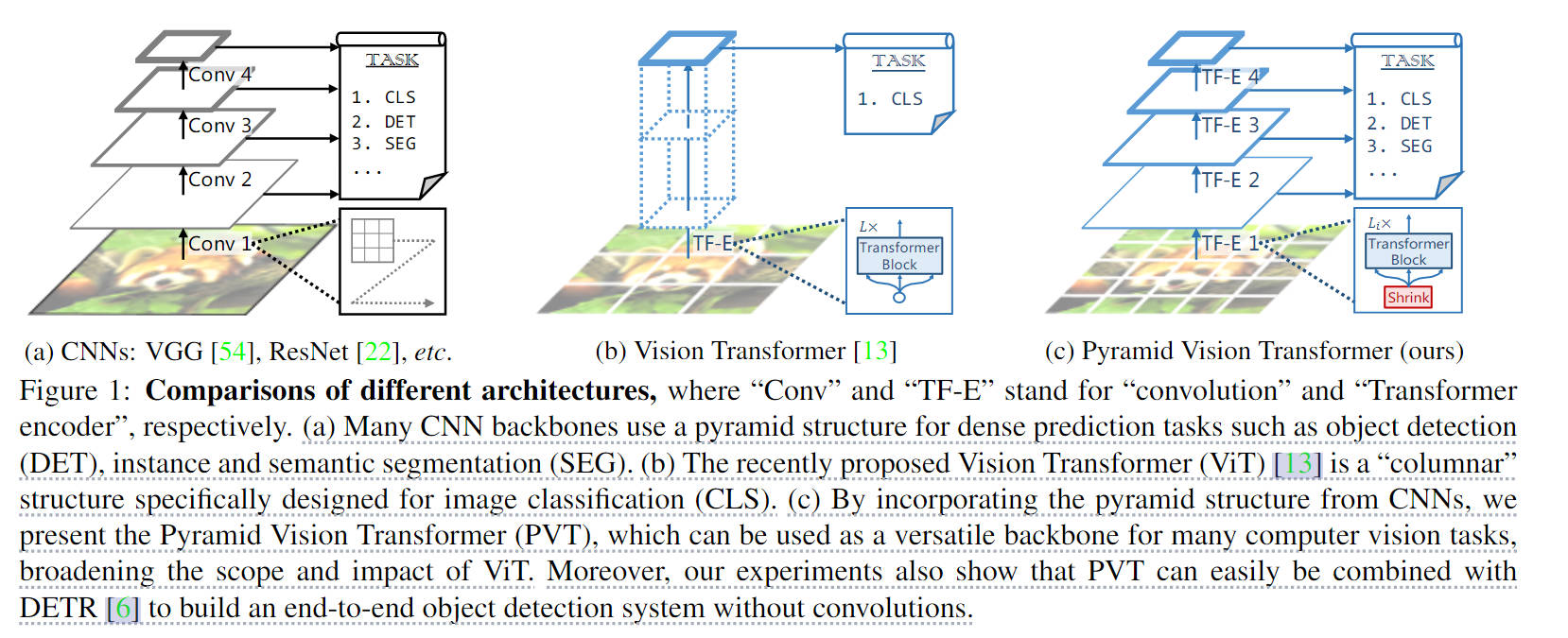
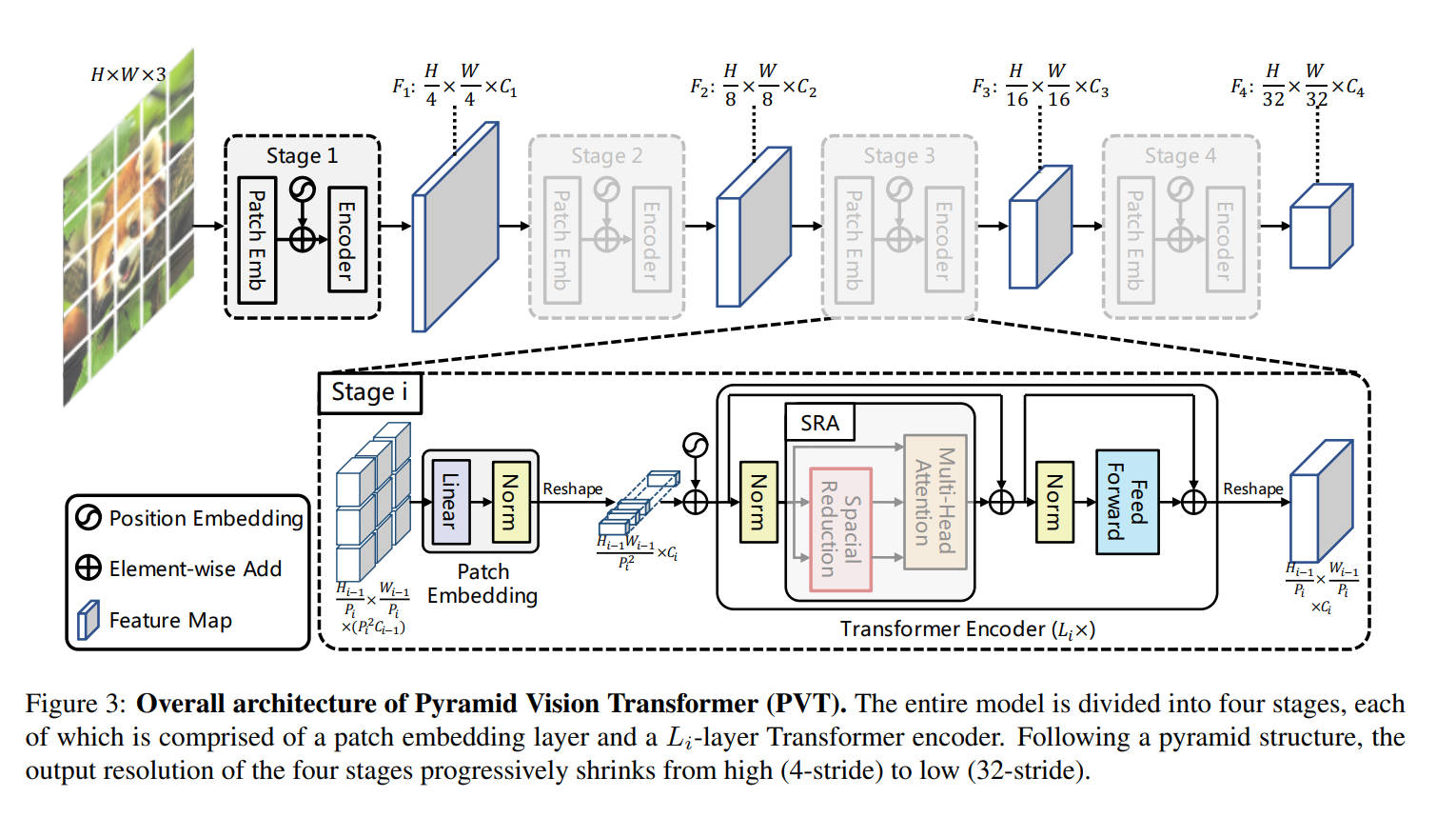
- 利用了progressive shrinking pyramid,可以输出多分辨率的feature map,方便进行更多下游任务,通过人为限制kv的尺寸大小限制计算量
- 使用层级式架构,能输出不同stage后的特征图,方便进行下游任务。
Swin Transformer : Hierarchical Vision Transformer using Shifted Windows URL (351) 2021.3
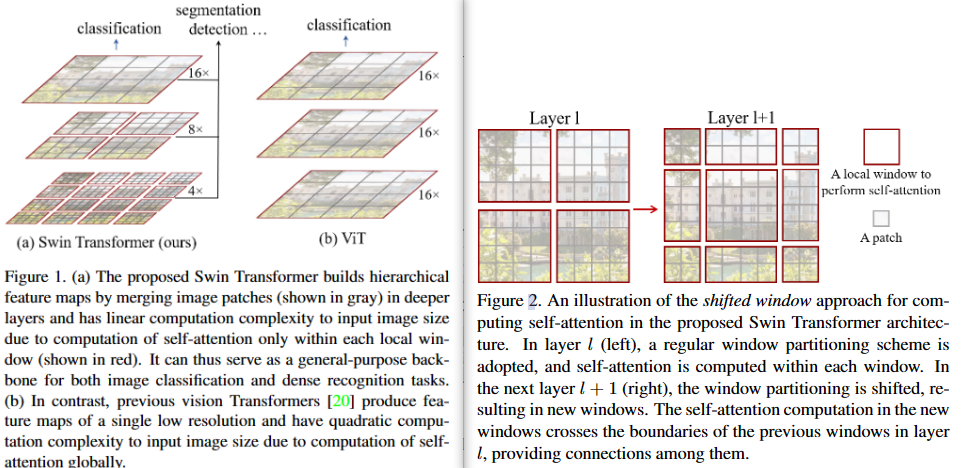
-
下采样的层级设计,能够逐渐增大感受野,从而使得注意力机制也能够注意到全局的特征
-
滑窗操作包括不重叠的 local window,和重叠的 cross-window。不重叠的local windows将注意力计算限制在一个窗口(window size固定),而cross-windows则让不同窗口之间信息可以进行关联,达到更好的效果。
-
论文详解:Swin Transformer - 知乎 (zhihu.com)
Object Detection
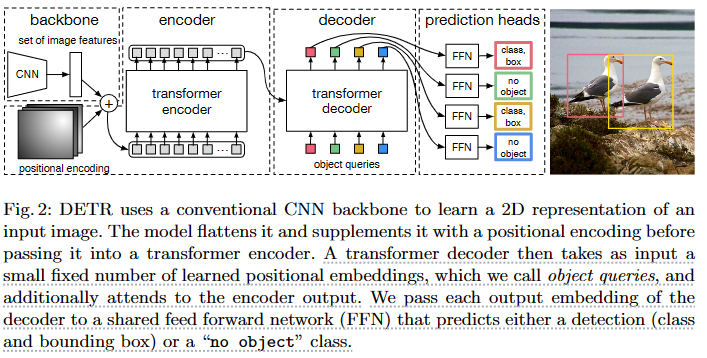
DETR: End-to-End Object Detection with Transformers URL(108) 2020.5
- 绕过proposals、anchors、window center的传统目标检测方法,直接使用transformer的全局注意力实现对目标的预测,避免了一些人为因素影响的先验框。
- 小物体不太好,其运行在分辨率最低的feature map上
- set-based loss(实现端到端),采用匈牙利匹配
- decoder中出现了cross attention,输入包含了object query 以及encoder的输出
- Object queries是一个可学习的向量(num, b,dim)Num是人为给的值,这个东西的作用和cls token类似,也是在整合信息,远大于图片内物体数量。
- end2end 丢弃Transformer,FCN也可以实现E2E检测 - 知乎 (zhihu.com)
- (6) DETR - End to end object detection with transformers (ECCV2020) - YouTube
Deformable DETR: Deformable Transformers for End-to-End Object Detection URL(183)2020.10
- 引入多尺度特征,解决了DETR在小物体上检测的问题。
Footnotes
AutoRegressive language model ↩︎
AutoEncoder language model ↩︎