在数据科学领域,Jupyter Notebook 已成为处理数据的必备工具。 其用途包括数据清理和探索、可视化、机器学习和大数据分析。
Jupyter Notebook的安装非常简单,如果你是小白,那么建议你通过安装Anaconda来解决Jupyter Notebook的安装问题,因为Anaconda已经自动为你安装了Jupter Notebook及其他工具。
当Anaconda安装好后,打开 jupyter notebook, 访问本地localhost:8888 即可愉快的通过浏览器开启沉迷学习之旅。
(温馨提示:如果你同时启动了多个Jupyter Notebook,由于默认端口“8888”被占用,因此地址栏中的数字将从“8888”起,每多启动一个Jupyter Notebook数字就加1,如“8889”、“8890”……)
假如小伙伴们想一起共享开发环境,或比如把实验室内服务器的notebook共享给项目组的其他同学,那该怎么办呢? 那么这时花生壳这个内网穿透神器就可以派上用场了。
具体步骤见下。
1. 配置notebook支持远程访问。
1.1 生成默认配置文件
打开运行框,输入命令:jupyter notebook --generate-config 
1.2 生成访问密码(token)
从notebook或ipython中输入如下命令,设置远程访问密码,同时注意复制输出的xxx加密密码串。 命令: from notebook.auth import passwd passwd() 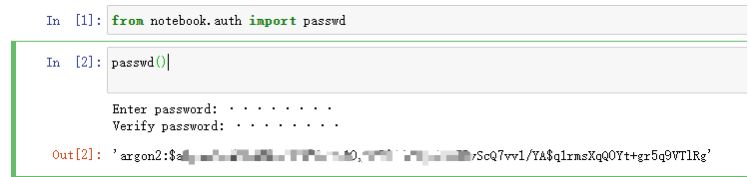
1.3 修改配置
修改./jupyter/jupyter_notebook_config.py中对应行如下
c.NotebookApp.ip='*'
c.NotebookApp.password = u'argon2xxxxxxxxxx'
1.4 打开浏览器测试访问
重启notebook,并访问 http://127.0.0.1:8888/ 。
输入刚才设置的密码,查看访问是否成功。
2. 配置花生壳内网穿透映射
2.1 配置映射指向notebook本机访问地址。
2.1.1 安装登录花生壳客户端
(1) 安装客户端
安装花生壳客户端(点击下载)。
(2)登录客户端
①已经有花生壳账号,直接输入账号和密码登录花生壳(内网穿透)客户端
②未拥有花生壳账号,在登录界面点击右下方的“注册账号”,注册账号后再登录客户端
2.1.2 填写映射信息
确认映射内容填写无误,点击“保存”即可。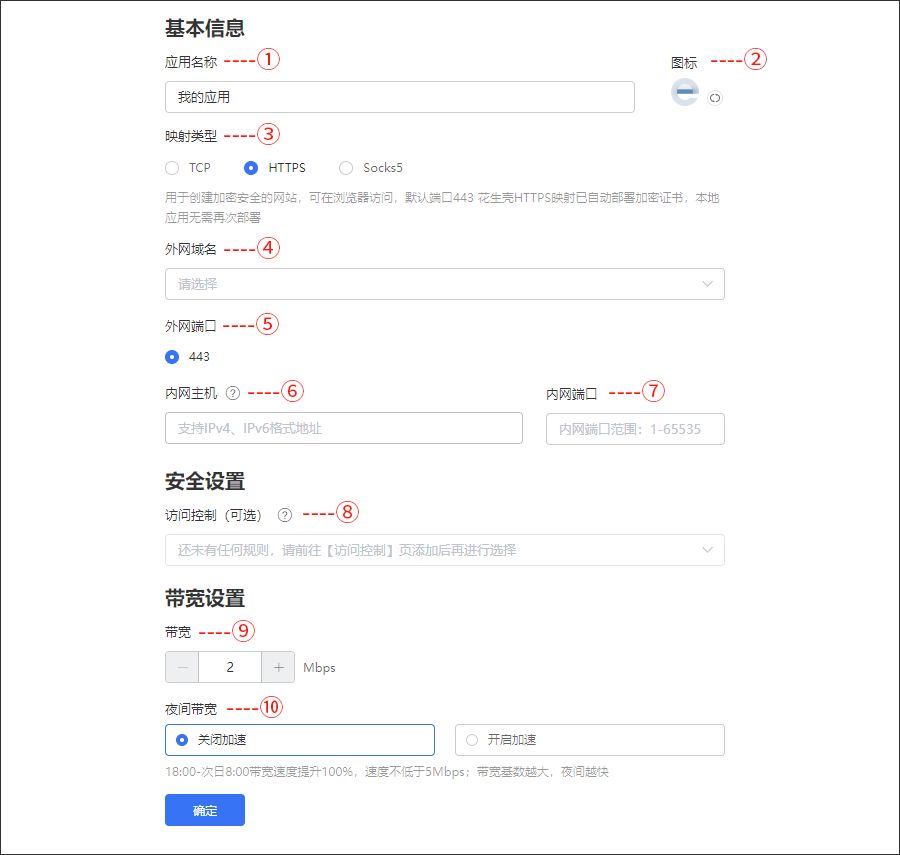
2.1.3 查看映射诊断信息
当映射添加正确,右侧的诊断信息会显示“连接成功”;
若无该提示,则需检查自己之前的步骤是否做对。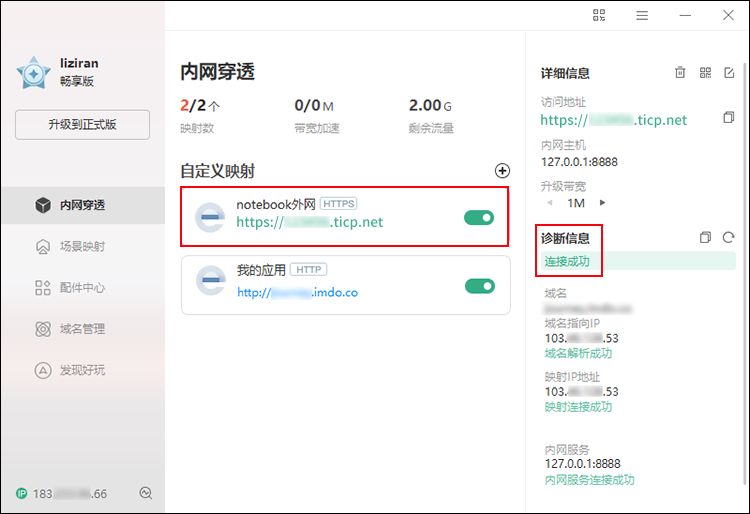
3.浏览器访问映射
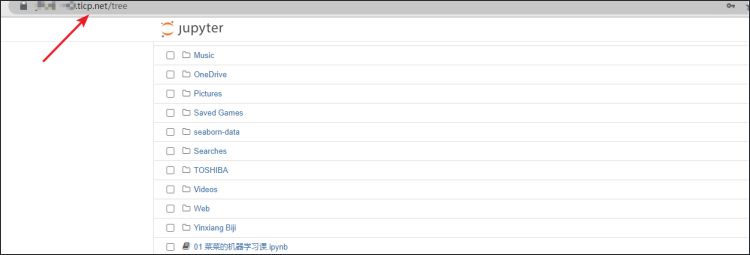
浏览器输入刚才添加的“notebook外网”映射,比如我的是https://xxxx.ticp.net ,即可愉快的在外网访问本地notebook了。