本文介绍了几篇结合使用CNN和Transformer进行半监督学习的论文,CNN&Trans(MIDL2022),Semi-ViT(ECCV2022),Semiformer(ECCV2022).
Semi-Supervised Medical Image Segmentation via Cross Teaching between CNN and Transformer, MIDL2022
论文:https://arxiv.org/abs/2112.04894
代码:GitHub - HiLab-git/SSL4MIS: Semi Supervised Learning for Medical Image Segmentation, a collection of literature reviews and code implementations.
论文提出一种简单而有效的CNN和Transformer之间的正则化方案,称为CNN和Transformer之间的交叉教学。该框架以标记图像和未标记图像作为输入,每个输入图像分别通过CNN和Transformer来产生预测。对于标记的数据,CNN和transformer分别由真实标签进行监督。使用由CNN/Transformer生成的未标记图像的预测来分别更新Transformer/CNN的参数。
所提出的优点有两个方面:
- 交叉教学是隐式一致性正则化,它可以产生比显式一致性规则化更稳定、更准确的伪标签。显式一致性正则化强制最小化不同网络预测的差异,同时对其进行优化,这可能导致不同网络的预测是相同的,但预测是错误的。
- 该框架得益于两种不同的学习范式,CNN专注于局部信息,而Transformer则对远程关系进行建模,因此交叉教学可以帮助同时学习具有这两种属性的统一分割器。
主要贡献有两方面:
- 提出了一种简单而有效的半监督医学图像分割交叉教学方案。这个当利用CNN和Transformer的优势相互补偿以获得更好的性能时,所提出的方案隐含地鼓励了不同网络之间的一致性;
- 据我们所知,这是首次尝试使用Transformer来执行半监督医学图像分割任务,并证明它可以在公共基准上优于现有的八种半监督方法。
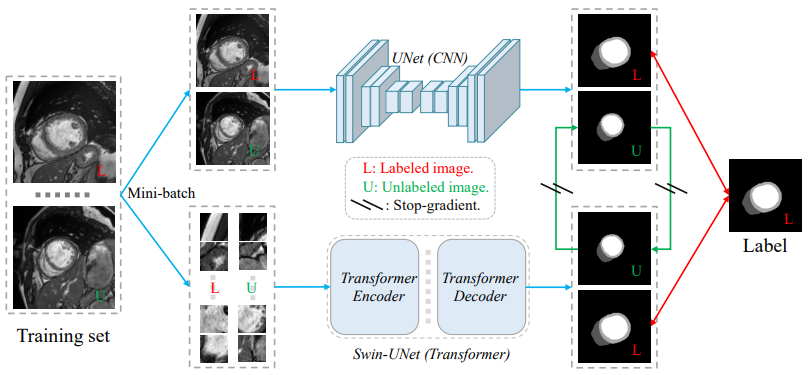
有监督分支,使用真实标签监督CNN流和Transformer流的预测结果。无监督分支,CNN流和Transformer流的预测结果互为伪标签,交叉监督。
交叉教学的最初想法受到了现有三种方式的启发:深度共同训练、共同教学和交叉伪监督。
- 深度协同训练训练具有不同视图输入的多个深度神经网络,并鼓励半监督学习的视图一致性。
- 协同教学同时训练两个深度神经网络,并让它们在一个小批量中相互教学,以实现噪声鲁棒学习。
- 交叉伪监督训练具有相同架构和不同初始化的两个网络,以在小批量中相互教学,用于半监督学习。
所有这些方法都引入了扰动,并鼓励预测在训练阶段保持一致。不同之处在于,深度协同训练使用输入级扰动(多视图),协同教学使用监督级扰动(噪声标签),交叉伪监督引入网络架构级别的扰动。
本文介绍了学习范式层面和输出层面的扰动。

与一致性正则化损失不同,交叉教学损失是一个双向损失函数,一个流从CNN到Transformer,另一个流是Transformer到CNN,没有明确的约束来强制它们的预测变得相似。框架中,转换器也只是用于补充训练,而不是用于产生最终预测。

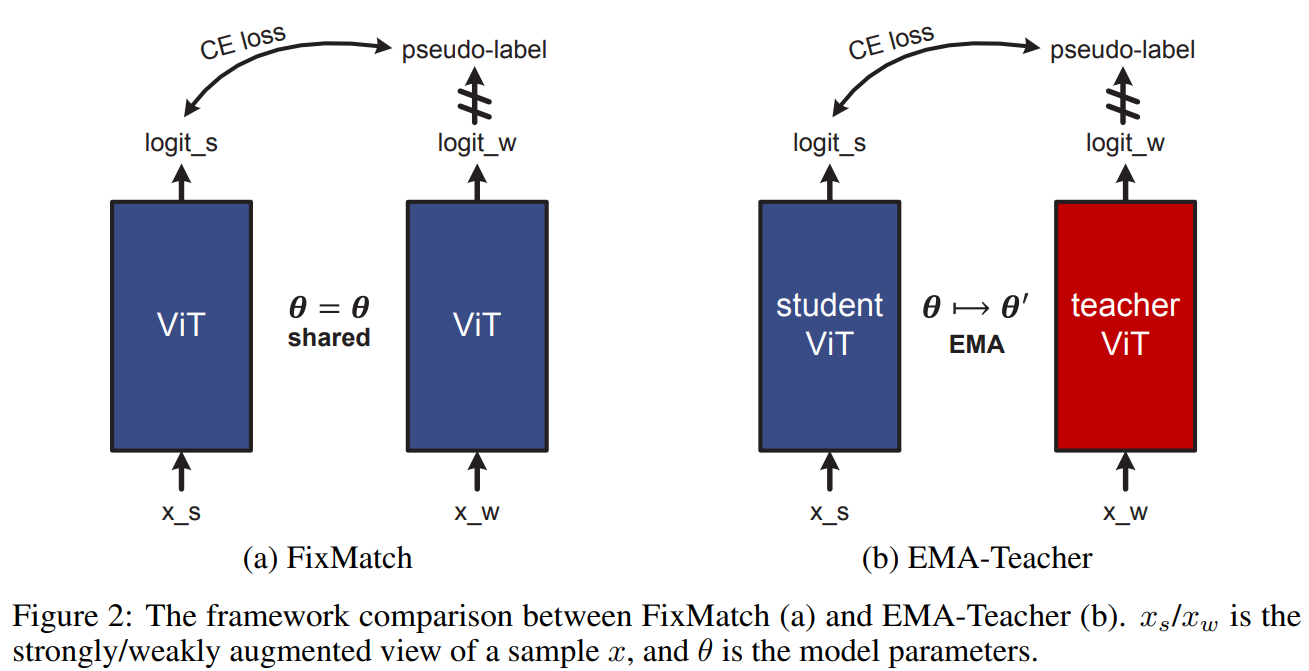
Semi-supervised Vision Transformers at Scale, ECCV2022
论文:https://arxiv.org/abs/2208.05688
代码: GitHub - amazon-science/semi-vit: PyTorch implementation of Semi-supervised Vision Transformers
论文研究了视觉Transformer (ViT) 的半监督学习 (SSL)。
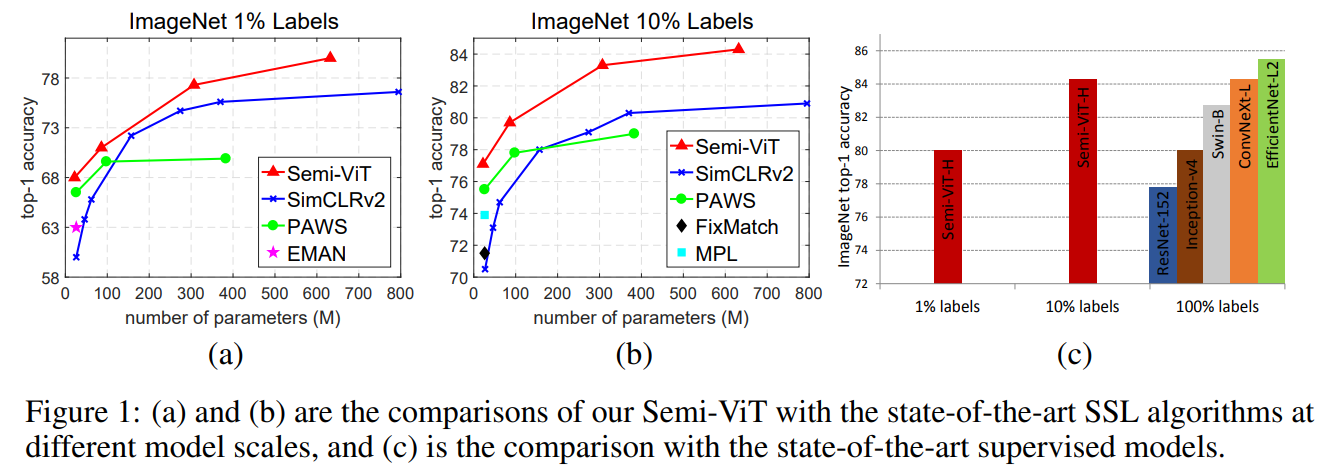
提出了一种新的SSL流程:首先是无监督/自监督的预训练,然后是有监督的微调,最后是半监督的微调。在半监督微调阶段,采用指数移动平均(EMA)-Teacher框架,而不是流行的FixMatch框架,因为前者更稳定,并且能为半监督Vision Transformer提供更高的精度。此外,提出了一种Probabilistic Pseudo Mixup机制,用于interpolate未标记样本及其伪标签,以改进正则化,这对于训练具有弱归纳偏置的ViT非常重要。本文提出的方法叫Semi-ViT。

Pseudo Mixup、Pseudo Mixup+、Probabilistic Pseudo Mixup的比较。红色样本的是通过置信阈值的样本,而蓝色的不是。
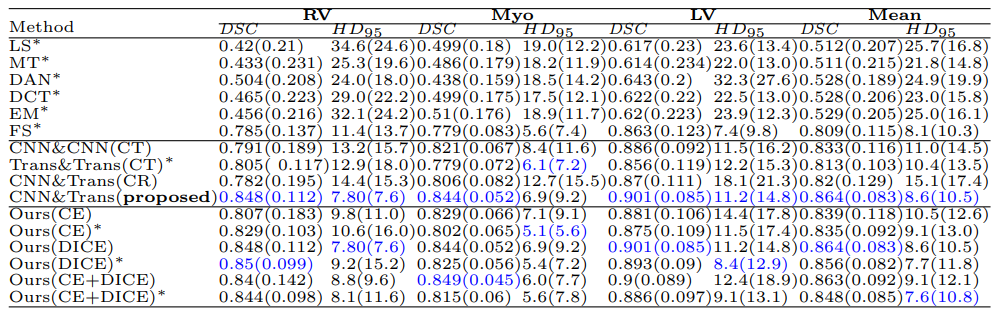
实验:
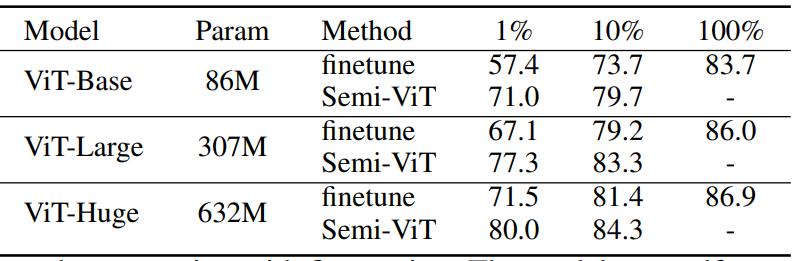
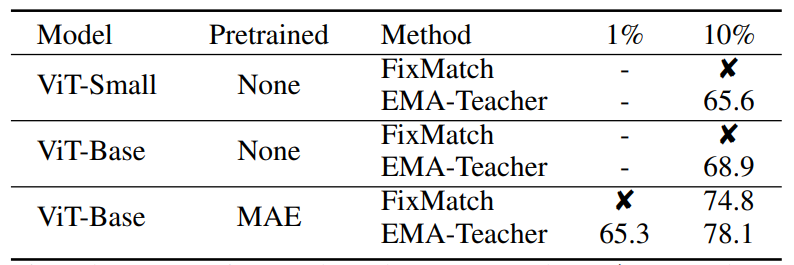


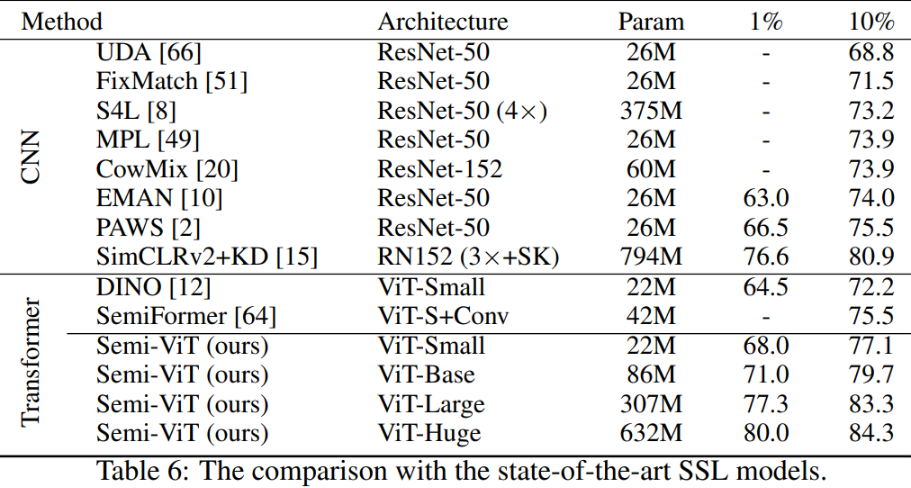
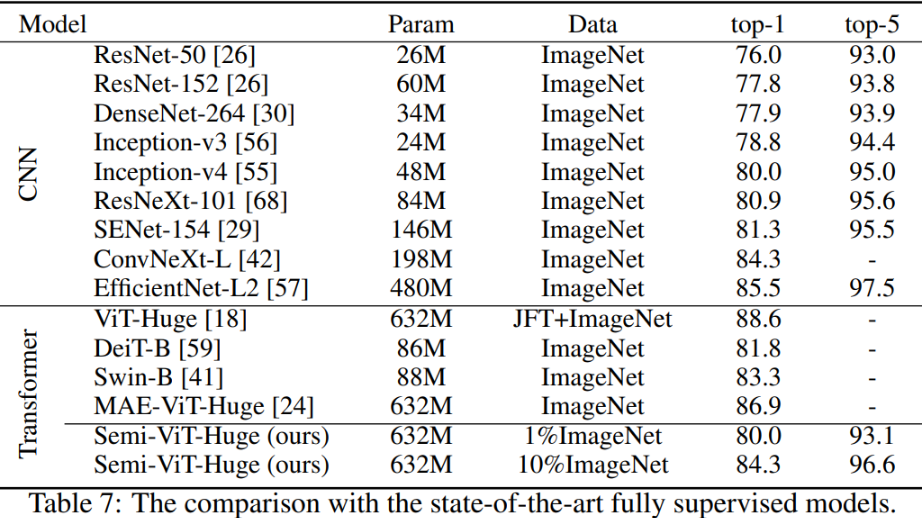
Semi-Supervised Vision Transformers, ECCV 2022
讲解:【论文阅读】《Semi-supervised Vision Transformers》 - 知乎 (zhihu.com)
论文:[2111.11067] Semi-Supervised Vision Transformers (arxiv.org)
代码:wengzejia1/Semiformer (github.com)
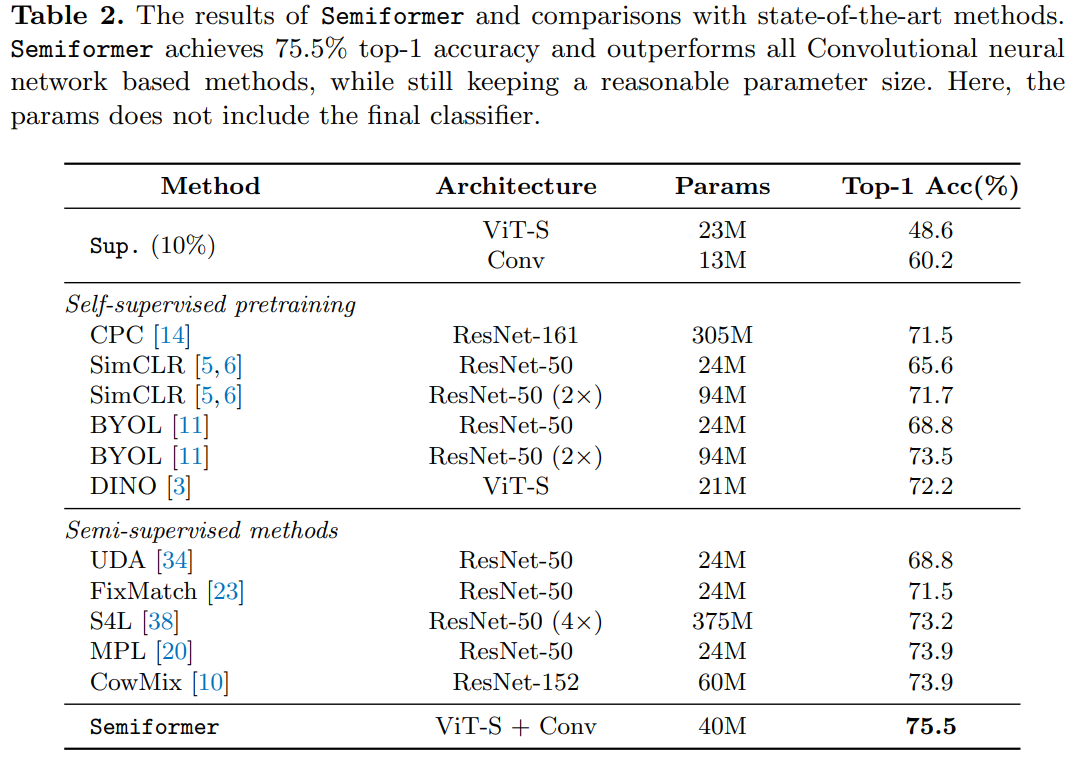
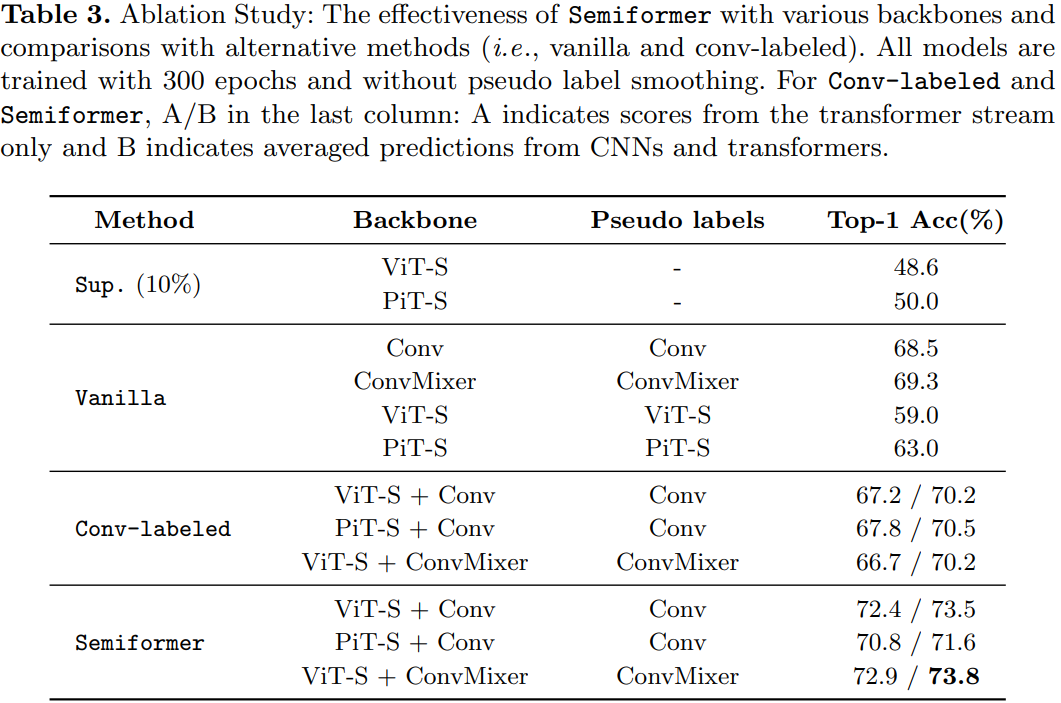
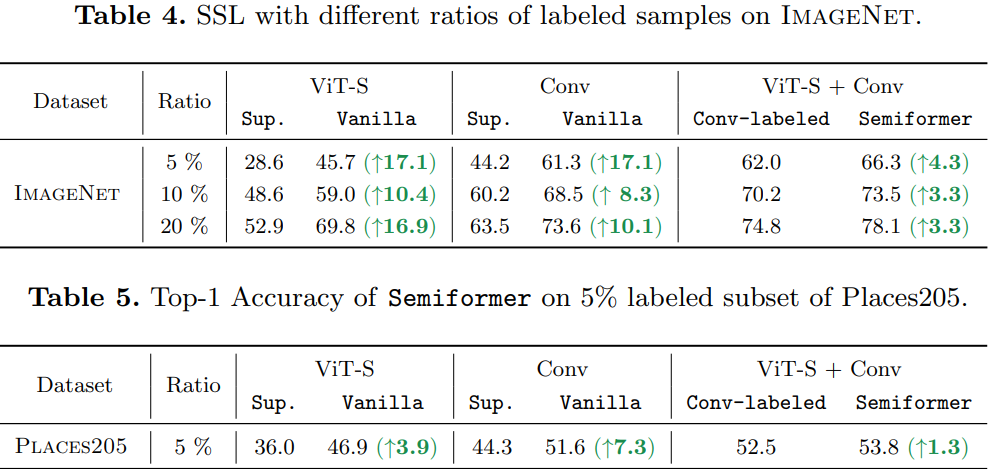
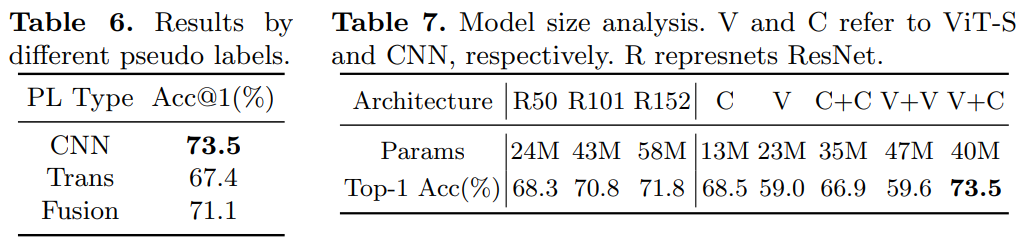
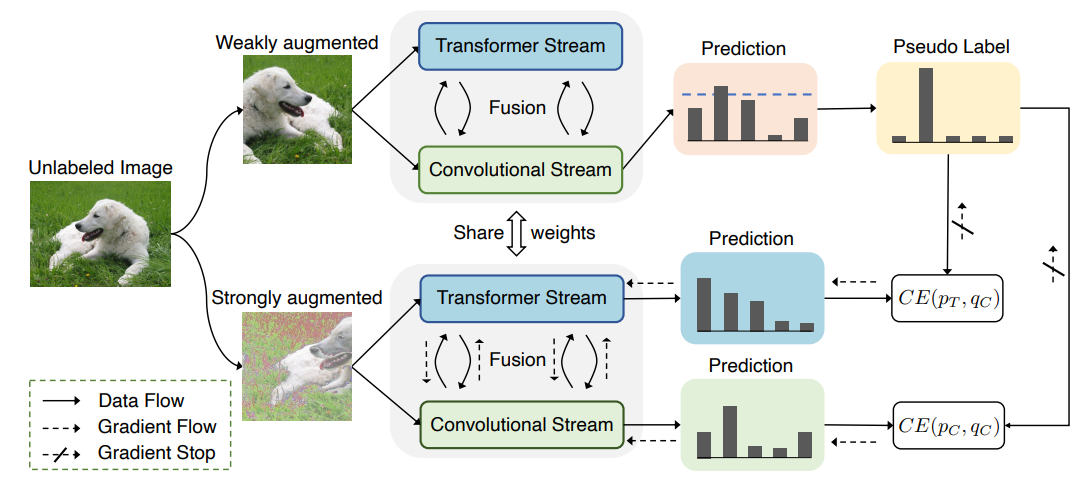
作者调研发现ViT在半监督ImageNet任务中表现的的不是很好。相反,卷积神经网络在一些少量标注的数据领域表现的很好。探索发现造成这种结果的原因:CNN有着较强的空间 inductive bias。于是,作者引入了一个联合半监督学习框架:Semiformer,它包含一个Transformer分支,一个卷积分支 和一个在两分支之间进行知识共享(knowledge sharing)的融合模块。卷积分支在有限的监督数据下进行训练并生成伪标签去监督Transformer分支在未标注数据上的训练。
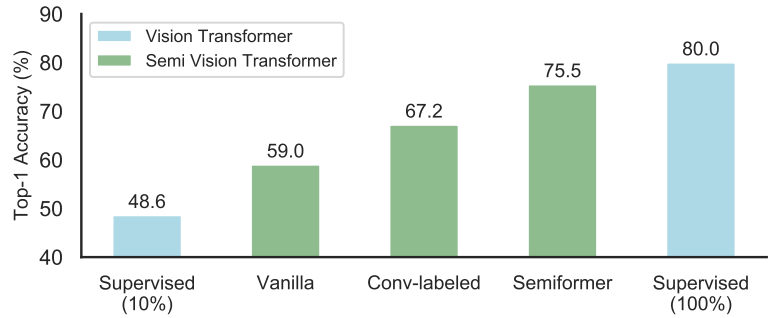
探索实验:
初始实验表明,使用训练策略(FixMatch)训练出来的ViT所得到的表现甚至要比不使用FixMatch训练而来的CNN表现的差得多。由此作者假设在ViT和CNN之间在小数据上的这种差距是由于CNN存在着额外的inductive bias。
CNN的inductive bias应该是locality和spatial invariance,即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)。
为了验证这种假设,作者建议使用CNN来生成用于VIT的半监督学习的伪标签,如图2b所示:CNN和ViT是从半监督数据上同时进行训练,然而ViT使用的伪标签是由CNN生成的,训练两个模型使用同样的FixMatch。通过这样做,我们能够去有效的提高最终的ViT top-1 Acc 8%。结果表明CNN的inductive bias在少量标注数据的领域很有帮助。
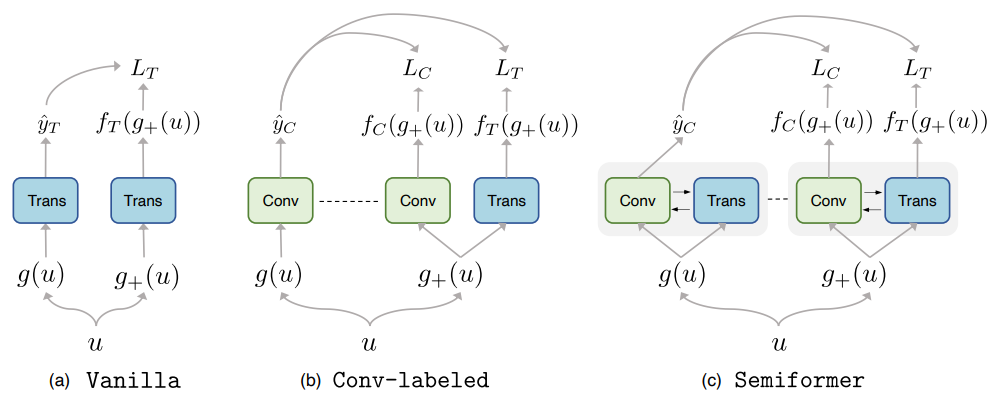

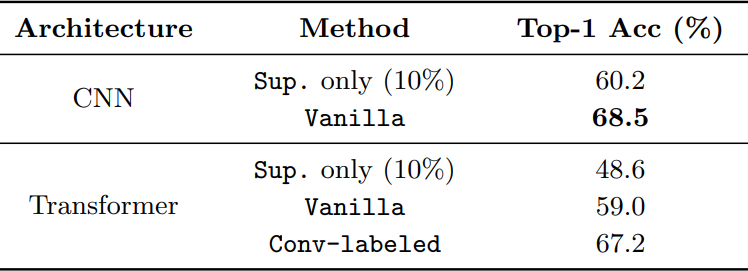
虽然CNN生成的伪标签是有效的,但在半监督benchmark中,最终的VIT仍然略弱于CNN。作者认为,通过伪标签来表现inductive bias是不够的,这促使他们在体系结构层面上设计一种联合知识共享机制。由此引入了一种新的ViT半监督学习框架,称之为Semiformer。新的框架由基于卷积的架构和基于transformer的架构组成,使得分支可以通过共同生成的伪标签方案和跨分支的特征交互模块来实现互补。
Semiformer框架,它为半监督学习联合融合了卷积结构和Transformer。整体框架遵循FixMatch设计,Semiformer只使用CNN的分支来产生伪标签。两个分支使用feature-level相互交流的方式进行融合。

总损失:两种损失赋权重相加。
![]()
有标签数据损失:
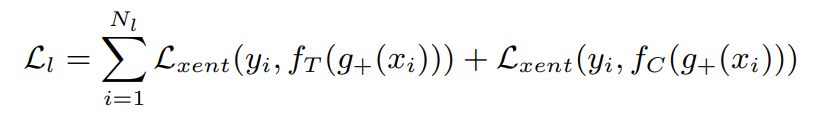
![]()
无标签数据损失:
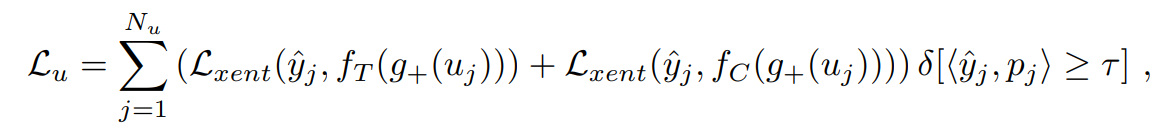
![]()
分支融合。M_T是某一层的ViT特征图,其形状 (d_T,h_T,w_T) 分别代表深度、高度和宽度。设 M_{T,i} 是形状为 ( d_T ,1,1) 的 M_T的第 i个patch特征。所以 M_{T,i} 与原始图像中的一个特定区域有关,与此同时将卷积网络中与相同区域相关的形状为 (d_C,h_C,w_C) 的子特征图标记为 M_{C,i} 。通过下式进行Transformer的patch feature和与之相关的CNN子特征图之间的信息交换。

其中,align操作表示将features 映射至相同的维度空间。average pooling 与 spatial interpolation 方法被用来进行空间维度对齐。
实验: