Automated WebAssembly Function Purpose Identification With Semantics-Aware Analysis
WWW23
文章结构
- intro
- background
- system design
- abstraction gen
- applying abstractions
- classifier
- data collection and handling
- data acquisition
- statistics of collected data
- module-level categorization
- function-level categorization
- evaluation
- discussion
- related work
- conclusion
Intro
WebAssembly(简称Wasm)是最新的网络标准。自2015年首次亮相以来[6],WebAssembly在前端领域引起了巨大轰动。一些知名的科技公司,如eBay、Google和Norton,在面向用户的项目中采用这项技术,以在诸如条形码阅读[35]、模式匹配和TensorFlow.js机器学习应用程序[44]等用例中提高性能,超越JavaScript。目前,所有主要的浏览器都支持WebAssembly[29]。
该语言定义了一种可移植且紧凑的字节码格式,用作其他语言(如C、C++和Rust)的编译目标。这使得将本地程序作为模块移植到Web并以接近本地速度执行成为可能。与直接编写不同,诸如Emscripten [4] 和 Wasmbingden [39] 的编译器生成WebAssembly字节码。WebAssembly还定义了一种文本格式,旨在使调试更加容易。文本格式提供了模块内部结构的可读表示,包括类型、内存限制和函数定义。尽管可读,但与高级语言相比,文本格式的学习曲线仍然相对陡峭。
WebAssembly有两个特性使得人类读者难以解释。
- WebAssembly只有四种数值数据类型,即i32、i64、f32和f64,使得一些应用程序的指令序列相似,如字符串操作和加密哈希。WebAssembly has only four numeric data types,i32, i64, f32, and f64, making the instruction sequences of several applications, such as string manipulation and cryptographic hashing,similar.
- 其堆栈机设计使得在给定位置推导变量的值变得困难。必须从给定位置跟踪堆栈,以确定在特定代码位置计算的值。its stack machine design makes deriving the value of a variable at a given location difficult. The stack must be traced from a given location to identify the computed value at a specific code location.
源映射(source maps)可用于在高级源语言中找到相应的功能。然而,许多WebAssembly模块,包括恶意模块,都通过第三方服务传递,其中源代码不可用[32]。对于这种情况,终端用户需要手动验证WebAssembly模块的实际功能。先前的研究[14, 32]关注了WebAssembly样本的目的。然而,很少有研究帮助开发人员理解WebAssembly模块实现的功能。
14: An Empirical Study ofReal-WorldWebAssembly Binaries: Security, Languages, Use Cases WWW 21
32: New Kid on the Web: A Study on the Prevalence of WebAssembly in the Wild DIMVA 2019
为此,我们开发了一个自动分类工具WASPur,以帮助开发人员了解应用程序中各个WebAssembly函数的预期功能。WASPur在模块的语法差异上构建了关于语义功能的抽象,这些抽象可用于机器学习分类器,以确定WebAssembly函数实现的功能。具体而言,我们的工作做出了以下贡献:
- 我们提出了一种中间表示(IR),用于抽象WebAssembly应用程序底层语义,实现对语法鲁棒性的分析。
- 我们通过爬取真实世界的网站、Firefox插件、Chrome扩展和GitHub存储库,构建了一个多样化的WebAssembly样本数据集。
- 我们对收集到的WebAssembly样本进行了全面的分析。我们确定了这些样本的目的,并将它们分类为12个类别。
- 我们开发了一个自动分类工具WASPur,可以根据其功能准确标记给定的WebAssembly函数,准确率为88.07%。
Background

WebAssembly定义了一种紧凑的字节码格式,旨在通过网络调用进行高效传输。该标准还定义了字节码的文本表示,以允许开发人员调试代码。图1显示了一个WebAssembly模块在字节码和文本格式中的样子。图1(a)中显示的C++代码片段包含一个主函数,该函数分配了两个变量,然后比较它们的值。这段代码编译为图1(b)中显示的WebAssembly二进制代码。二进制格式是WebAssembly模块传递到浏览器并由其编译的方式。WebAssembly二进制代码可以被翻译成其文本格式,如图1©所示,它展示了WebAssembly指令的示例,如i32.sub和i32.load。
WebAssembly模块具有清晰定义的结构。每个模块由10个部分组成,每个部分描述模块的不同组件:
- Types - 此部分定义了模块中使用的所有函数类型,包括参数和结果的数据类型。
- Functions - 此部分通过它们的类型、使用的局部变量和由一系列WebAssembly指令组成的函数体定义了所有的WebAssembly函数。
- Tables - 此部分定义了作为间接函数调用目标使用的函数表,即使用call_indirect。
- Memory - 此部分定义了模块的线性内存部分的属性。
- Globals - 此部分列出了在模块中所有函数中可访问的全局变量。
- Elements - 此部分列出了将用于初始化指定函数表的函数索引。
- Data - 此部分列出了将用于初始化指定线性内存部分的字节序列。
- Start - 此部分定义了模块初始化后是否调用任何一个函数。
- Imports - 此部分声明了从JavaScript导入的函数,将在WebAssembly函数内调用。
- Exports - 此部分指定了将导出到主机JavaScript上下文的哪些WebAssembly函数,以便可以在那里调用它们。
我们的分类方法主要关注Functions部分,因为这部分包含了通过WebAssembly指令实现的大部分过程功能。
System
Use a semantics-aware intermediate representation designed to capture the effects produced by wasm instructions.
使用基于语义感知的中间表示来捕获wasm指令产生的影响。
如下图所述,两个关键组件:
- IR抽象,将所有函数抽象为IR表示
- 分类器,将IR单元输入到神经网络分类器中,分类器在多次出现在WebAssembly 模块中的函数名称进行训练,并输出被检查函数属于相似命名函数组的概率。
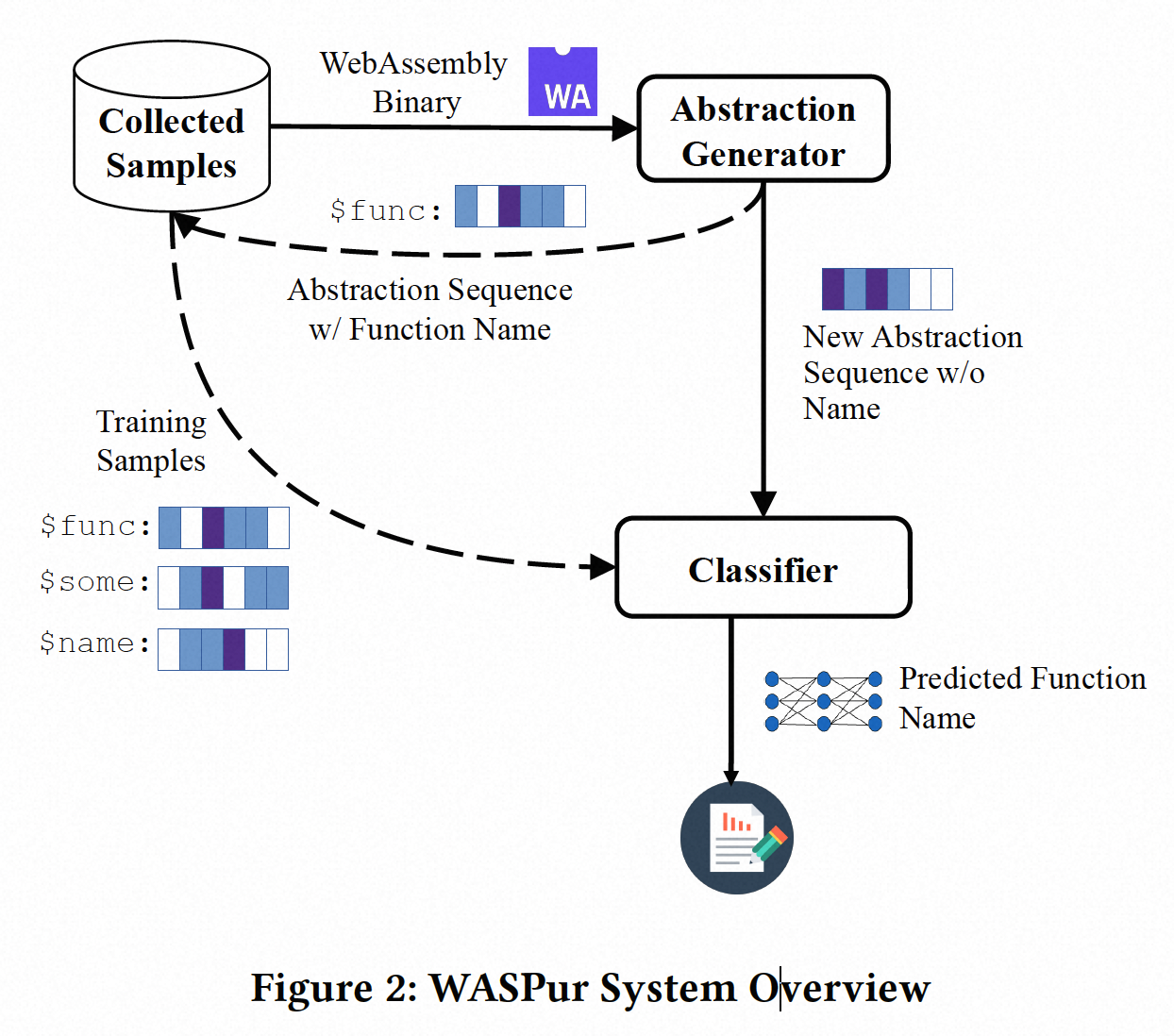
Abstraction gen
定义 1(抽象规则)。抽象规则是一个元组(𝑆, 𝑎, 𝐷𝑒𝑓 ),其中:
- 𝑆 表示一个或多个堆栈操作,用于模拟 WebAssembly 指令对虚拟堆栈的影响、
- 𝑎是将 WebAssembly 指令映射到类 C 抽象的转换函数、
- 𝐷𝑒𝑓是当前代码位置所有存活变量的定义集。
我们提出的抽象规则将 WebAssembly 字节代码抽象为五组:
(1) 数字指令: 在堆栈值上执行数值计算。
(2) 参数指令: 操作虚拟堆栈,无需额外计算。
(3) 控制指令: 利用堆栈中的值改变程序的控制流。
(4) 变量指令: 分配和获取局部变量。
(5) 内存指令: 分配和获取内存值。
下表显示了 WebAssembly 指令的子集,以及我们如何抽象每组指令。
**数值指令。**WebAssembly执行基于堆栈机体系结构,因此我们的抽象模型基于其对堆栈的影响来对WebAssembly指令进行建模。建模堆栈使我们的抽象能够捕捉程序的数据和控制流。第一组抽象模型是对在堆栈值上执行数值计算的指令。例如,指令“i32.const 𝑐”将32位常数𝑐推送到堆栈上。前缀i32表示𝑐的数据类型为32位整数。类似地,64位整数由i64前缀表示,32位浮点数由f32前缀表示。我们通过将这些指令应用于表示参数、变量和加载值的符号值来捕捉它们。
**参数指令。**该组包括两个WebAssembly指令,“drop”和“select”。这些指令可以从堆栈中删除一个值而不执行其他计算。我们通过它们对虚拟堆栈的影响来对这些指令进行建模。
**控制指令。**WebAssembly支持诸如if、loop和block之类的控制流构造。条件语句如“if 𝐼”被抽象为“if (𝑒)”,其中条件𝑒从堆栈中弹出。在if块范围内定义的抽象存储在内部抽象的列表中。我们使用“block”和“for”抽象分别对“block”和“loop”指令进行建模。两个抽象都定义了一个标签,例如“loop 𝑔:”,用于封装一段代码。‘br 𝑔”和“br_if 𝑔”指令控制控制流是否将转到带标签的块的开始。为了模拟这种行为,我们还将在块中定义的任何抽象存储到内部抽象的列表中。而“for”抽象还包含控制循环是否终止的条件。“call”指令使用显式函数名称进行直接调用,“call_indirect”指令使用对函数表的索引进行间接调用。我们使用相应的“call”和“call_indirect”抽象对这两个指令进行建模。
**变量指令。**变量指令可以从局部或全局变量加载值,也可以为它们分配值。为了对加载变量的指令(如“get_global”)进行建模,我们使用符号值来表示它们在堆栈上的位置。对于分配值给变量的指令(如“set_local”),我们使用“set”抽象来记录目标变量和分配的值的信息。我们还在变量定义集中记录变量分配的历史。例如,为了处理操作“set_local 𝑣”,我们的定义集将被更新以反映局部变量 𝑣 当前包含值 𝑒。
**内存指令。**类似于变量指令,有一些内存指令可以在线性内存中加载(例如,“i64.load”)或存储(例如,“i32.store”)值。我们使用符号值来表示特定内存索引处的值,从而对加载指令进行建模。我们通过构建“store”抽象来对内存存储指令进行建模,该抽象跟踪目标内存位置和值。我们还在变量定义集中记录这些内存存储的历史。例如,“i32.store8”会被抽象为“W8(𝑒2, 𝑒1)” ,其中𝑒2是源地址,𝑒1是目标地址。定义集会更新以反映内存索引 𝑒2 包含值 𝑒1。
我们观察到,WebAssembly应用程序通常使用连续的内存复制操作,因此我们根据两个规则将连续的“store”抽象合并为单个抽象。对连续内存缓冲区的顺序写入被简化为“memcpy”抽象,通过推断“store”抽象中的起始地址、目标地址和要复制的内存长度来实现。对连续内存缓冲区进行写入的语义也可以通过使用循环逐字节写入并类似地推断地址和内存大小来实现。
Applying abstraction
要应用我们的抽象,首先我们为每个函数构建一个函数内控制流图(iCFG)。该图包含通过遍历单个函数的指令序列构建的抽象序列。我们对抽象进行了一些转换,以压缩它们,例如将连续的重复操作组合成循环。
在构建了每个函数的iCFG之后,我们通过在“call”抽象上连接单个iCFG来构建一个函数间控制流图(ICFG)。为了进行图遍历,为每个函数构建一个单独的ICFG,所选函数用作遍历的起点。我们将深度限制为两个调用层级,以防止由递归函数引起的循环。对于“call_indirect”抽象,我们连接所有与声明的函数类型匹配的函数。
Classifier
利用从程序抽象构建的IR,分类器通过预测具有相似IR轨迹的函数的函数名来确定函数的功能。我们将在以下部分详细描述如何对抽象进行编码以及如何训练分类器。
3.3.1 将抽象编码为特征
分类器使用神经网络模型为给定的抽象序列预测标签。输入需要被编码成一个数值表示,以输入到模型中。我们输入神经网络的是在遍历目标函数的函数间控制流图(ICFG)时产生的抽象序列。然后,该序列被视为一个抽象类型字符串,例如,“set set for store if …” 这个字符串被嵌入为一个数值向量,其中整数表示我们定义的八种抽象类型之一。这个向量需要一个预定义的序列长度,因此比这个长度长的抽象轨迹会被截断。
3.3.2 训练分类器
分类器是在收集到的WebAssembly文件的生成函数抽象序列上进行训练的。为了训练和评估分类器,WebAssembly函数被根据它们的抽象序列分组在一起,这里使用非最小化名称的WebAssembly函数。我们使用这些函数名作为分类的标签。标签字符串使用多热编码方案进行编码,将每个标签映射到数值向量的索引。分类器输出一个向量,其中浮点值对应于某个标签应该应用于样本的概率。分类器通过将数据集分成80%的训练集、10%的验证集和10%的测试集进行评估。
3.3.3 神经网络架构
支持我们分类器的神经网络以抽象序列作为输入。一个嵌入层将抽象序列字符串编码为最多250个整数的数值向量。每个隐藏层使用TensorFlow提供的全连接Dense层类型。输出层由189个单元组成,使用SoftMax激活函数。该层中的单元对应于网络预测的标签值的索引。网络配置为使用真实标签和预测标签之间的交叉熵损失作为损失函数,并使用Adam梯度下降方法作为优化算法。我们配置网络在训练模型时使用30次迭代。
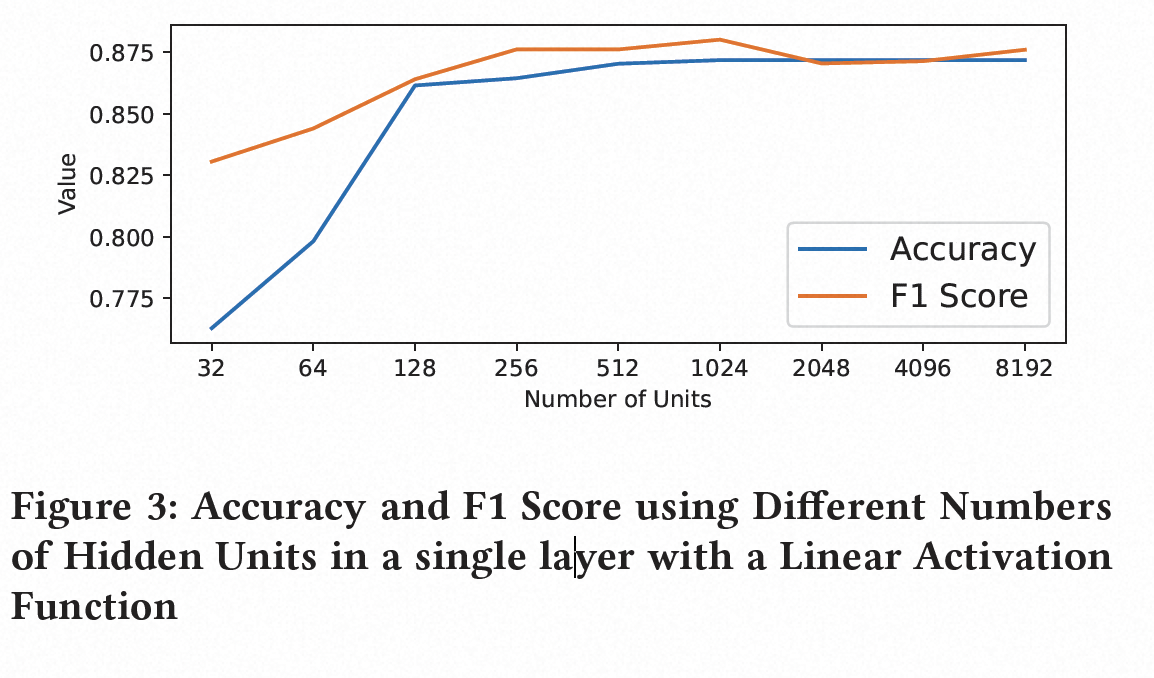
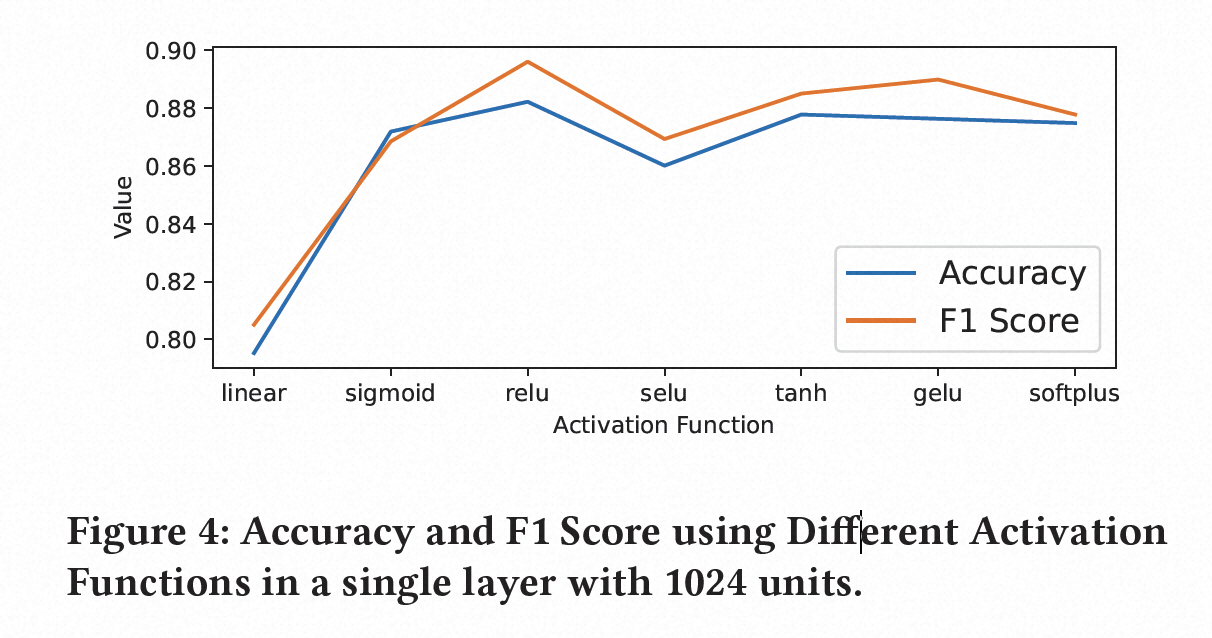
我们的模型的分类性能取决于使用适当的超参数值。我们调整神经网络模型的超参数,以确定从给定的抽象序列输入预测标签的合适配置。为了确定最佳的隐藏层单元数、激活函数和层数,我们构建了不同超参数值的神经网络,以确定我们的分类器能够达到的最高准确度值。
Data collection
我们收集WebAssembly样本以构建神经网络模型的训练和评估数据集。在以下部分,我们描述了从各种来源收集WebAssembly二进制样本的过程。我们还详细描述了这些样本以及它们实现的用例。
我们从四个来源收集WebAssembly样本:
(1) Alexa前100万个网站,
(2) 安装用户最多的17,682个热门Chrome扩展,
(3) 安装用户最多的16,385个热门Firefox插件,
(4) 1.12亿GitHub仓库。
4.1.1 Alexa前100万个网站
我们从2018年10月到2020年5月爬取了Alexa前100万个网站。对于每个网站,我们访问了主页和所有一级子页面。我们决定将爬取限制为一级子页面而不是所有子页面,因为对于包含数千个子页面的复杂网站,完整扫描需要数小时。为了下载在页面上运行的WebAssembly二进制文件,我们使用启用了“–dump-wasm-module”标志的Chromium浏览器版本77来转储浏览器解码的任何WebAssembly模块。
4.1.2 Chrome扩展
我们通过使用修改后的Chromium浏览器运行所有安装用户超过1,000的扩展来获取来自Chrome扩展的WebAssembly样本。我们从2019年3月25日到2019年3月30日爬取了Chrome扩展。下载所有Chrome扩展花费了一天的时间,评估每个扩展花费了四天的时间。这导致了总共17,682个Chrome扩展。
4.1.3 Firefox插件
从Firefox插件中获取的样本是通过爬取官方Firefox插件网站以下载.xpi插件存档而获得的。.xpi存档被扫描以查找以“.wasm”结尾的文件。我们在2019年7月30日爬取了Firefox插件。下载和扫描所有插件花费了一天的时间。总共分析了16,385个Firefox插件。
4.1.4 GitHub仓库
我们使用pga命令行工具从Public Git Archive数据集[27]中获取WebAssembly样本。我们指定了“–lang”过滤器以获取使用WebAssembly作为语言过滤器的存储库。然后,我们使用GitHub REST API [15]扫描这些存储库,找到并下载所有WebAssembly二进制文件(.wasm)。这个过程在2019年10月3日花了一天的时间。
表2显示了每个已爬取来源的WebAssembly二进制文件的数量。它显示了每个来源的已爬取应用程序/项目数量,使用WebAssembly的应用程序/项目数量以及从每个来源识别的WebAssembly程序数量。总共,我们从所有来源识别了6,769个WebAssembly样本。这些应用程序/项目可以使用多个WebAssembly文件来实现复杂的用例,因此识别的WebAssembly样本数量超过了应用程序/项目的数量。在收集的6,769个WebAssembly模块中,有1,829个是独特的。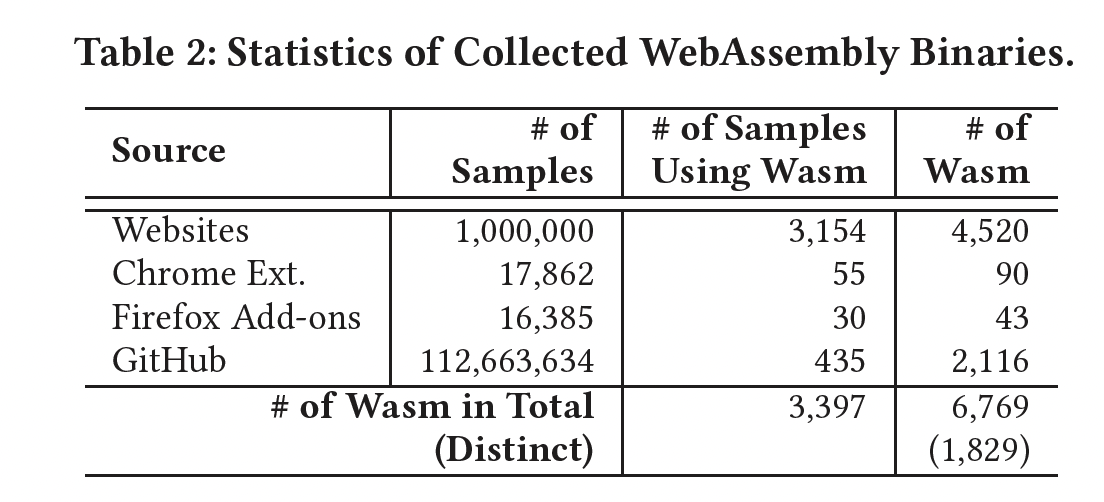
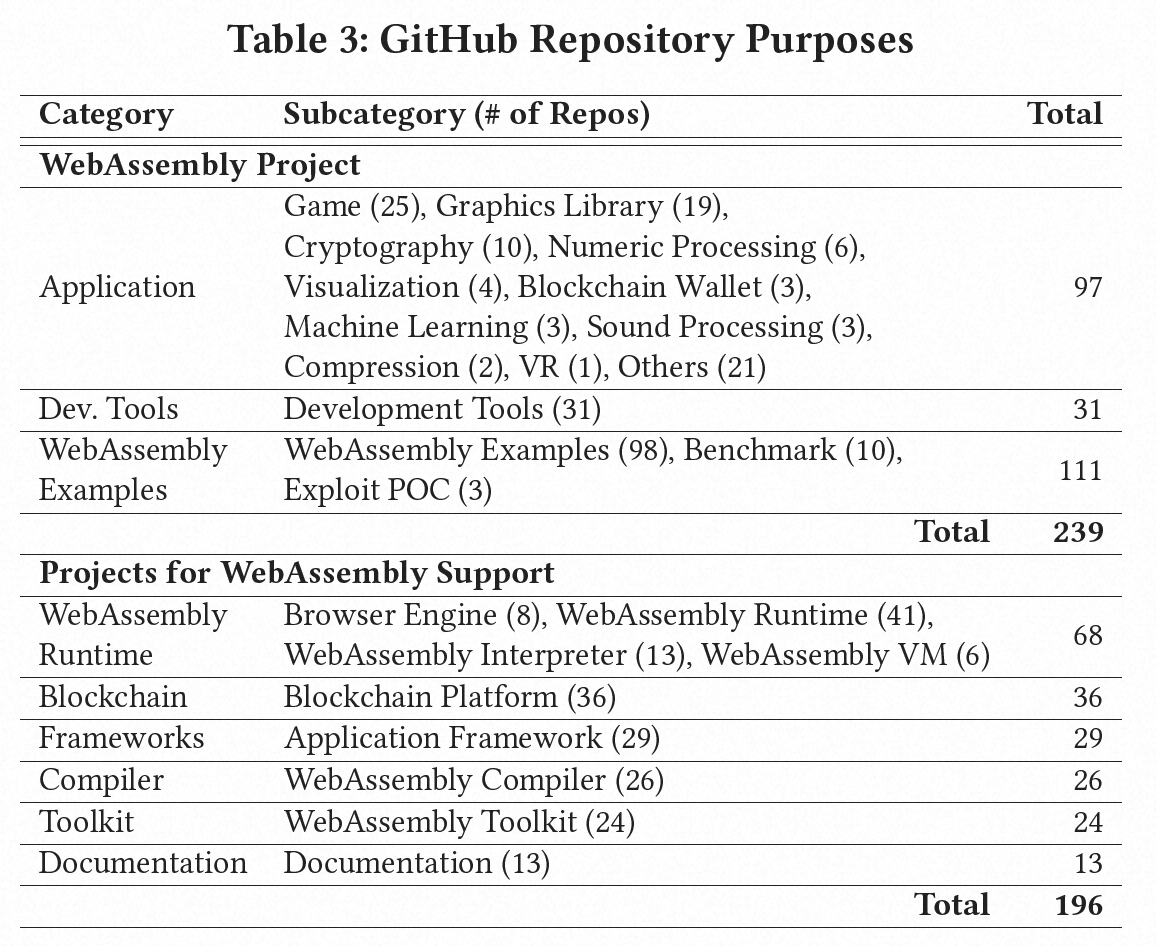
在1.12亿个GitHub仓库中,我们识别了435个与WebAssembly相关的仓库。表3显示了我们手动检查的结果,包括仓库的用途。这些WebAssembly GitHub仓库包括239个使用WebAssembly构建的仓库(97个应用程序,31个开发工具和111个WebAssembly示例)以及196个提供WebAssembly支持的仓库(68个WebAssembly运行时,36个区块链项目,29个框架,26个编译器,24个工具包和13个文档仓库)。此外,我们在各个组中确定了更细分的子类别,例如在"Applications"组中有25个游戏和3个机器学习应用程序,在"WebAssembly Runtime"组中有8个浏览器引擎和6个WebAssembly虚拟机。
WebAssembly程序的分类
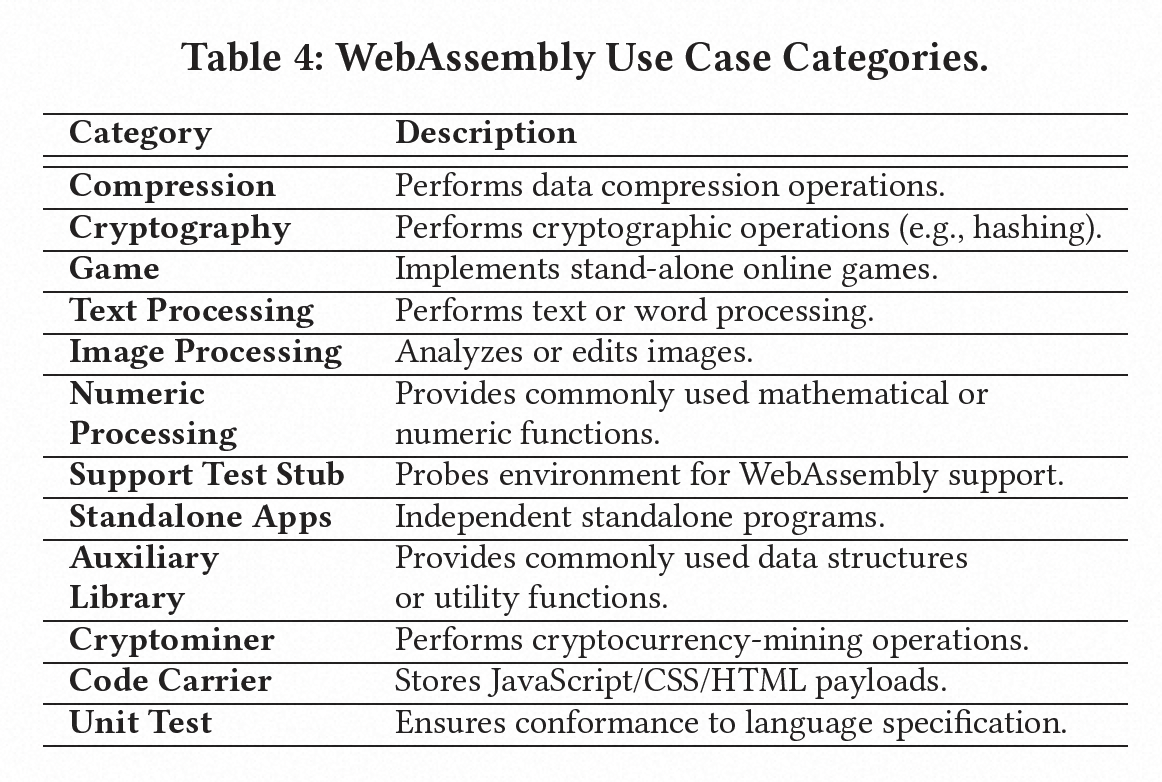
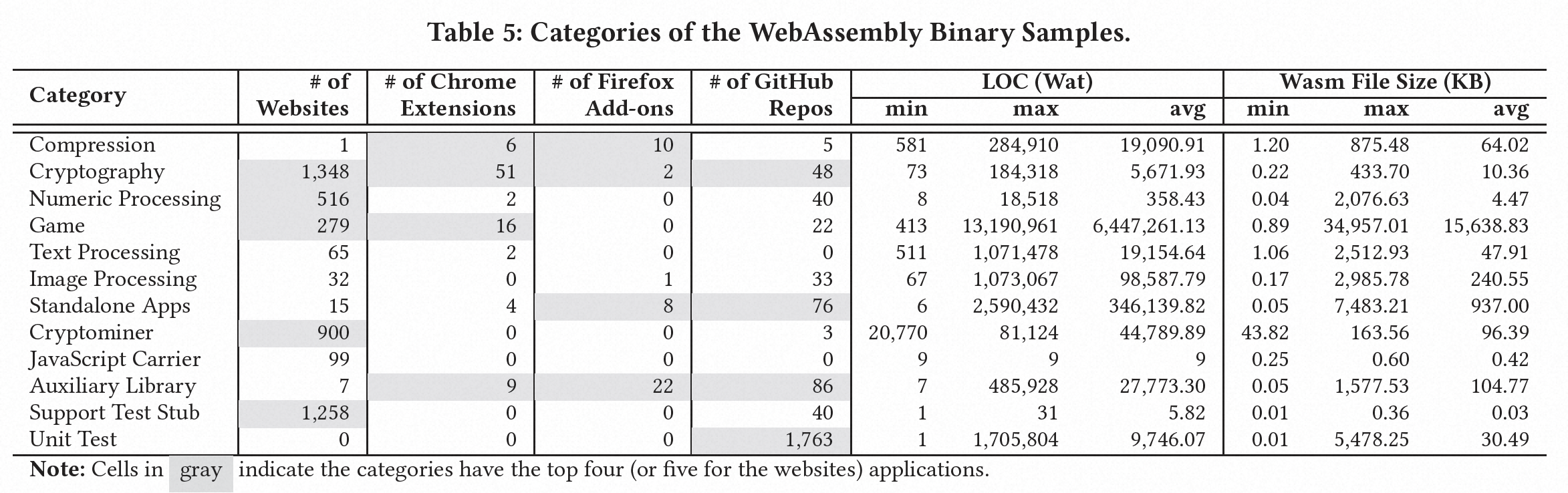
对于了解WebAssembly程序在野外的预期目的,识别其类别(即预期目的)至关重要。为了发现这些样本的预期目的,我们通过依赖于从WebAssembly二进制文件获取的四种类型的信息(导入函数名称、导出函数名称、内部函数名称和文件来源),对文件进行手动检查和标记。如表4所示,我们将这些样本分为12个不同的类别。我们发现在我们调查的所有WebAssembly样本来源中都有各种各样的类别。对于每个类别,我们在表5中提供了在每个源位置找到的模块数量、文本文件大小的统计数据以及二进制文件大小的统计数据。
模块中的函数名称通常携带有关模块用途的信息描述。对于GitHub存储库中的源文件,我们使用文件在项目上下文中的用途来识别类别特征。对于浏览器扩展,我们查看了扩展的描述页面以及捆绑在扩展存档中的WebAssembly和JavaScript文件,以确定扩展的目的以及WebAssembly模块在其中扮演的角色。
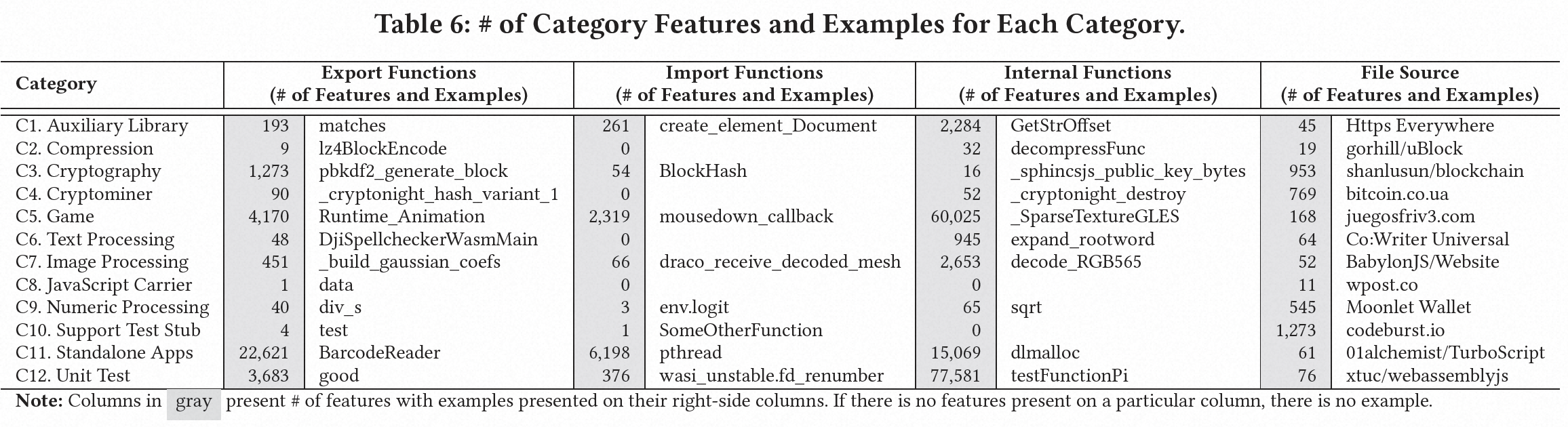
总体而言,我们从模块的导入、导出和内部函数名称中产生了超过204,619个签名。表6总结了这些签名。
理解WebAssembly模块中各个函数的目的
理解构成模块的个体WebAssembly函数的目的也有助于开发人员理解整个模块。WebAssembly是一种经过编译的语言,通常经过编译器优化。在许多情况下,这些优化会使模块中定义的WebAssembly函数的函数名最小化,以及附带的JavaScript代码也会被最小化。我们观察到在1,829个总模块中有923个模块使用了最小化的函数名,从而减少了开发人员寻求理解模块功能时的关键信息。
为了识别WebAssembly模块的预期功能,我们利用了收集的模块中存在的函数名。这些函数名可以指示存在C、C++、Rust等常见实用工具的存在,比如malloc和strcmp。其他函数名表明这些函数实现了特定于应用程序的行为,比如AutoThresholdImage和IsPDF等。我们从在至少两个唯一模块中出现的函数的名称中创建标签。我们还将类似的函数名(例如 m a l l o c 、 malloc、 malloc、_malloc和$memory.allocate)压缩成代表该组的单个标签,例如malloc。通过这个过程,我们获得了189个不同的函数类别。在多个模块类别中出现的函数名表明这些函数实现了共同的实用工具。
Evaluation
我们使用从Alexa前100万个网站、Chrome扩展、Firefox插件和GitHub存储库收集的1,829个独特的WebAssembly文件的数据集对WASPur进行训练和评估。为了使用这些样本,我们提取每个函数并为每个函数构建抽象IR。然后,我们将抽象序列编码为数字向量,以在神经网络模型中使用。为了确定提供最佳预测能力的神经网络超参数,我们使用不同数量的层内隐藏单元、不同激活函数和不同层数来测量模型的分类指标。
为了评估WASPur,我们使用了这个WebAssembly模块的数据集来构建一个单独的WebAssembly函数的数据集。对于每个函数,我们记录其名称、抽象遍历序列和其父模块。然后,我们使用函数名称为函数提供一个标签,根据我们在第4.4节中的描述。我们的函数数据集包含了从1,829个独特的WebAssembly文件中提取的11,524,686个函数。其中,151,662个函数有函数名称,而11,373,024个函数没有函数名称,因为经过了优化或缩小的步骤。我们使用这151,662个带标签的函数来训练我们的分类器。
WASPur基于Node.js [8]和Python [9]构建。该系统包含两个组件。抽象生成器组件是一个Node.js应用程序,而分类器组件是用Python实现的。分类器使用了使用Keras [48]和TensorFlow [1]库构建的神经网络模型。分类器模型在一台搭载Intel Core i7 CPU@2.1GHz和64GB RAM的笔记本上进行训练和评估。
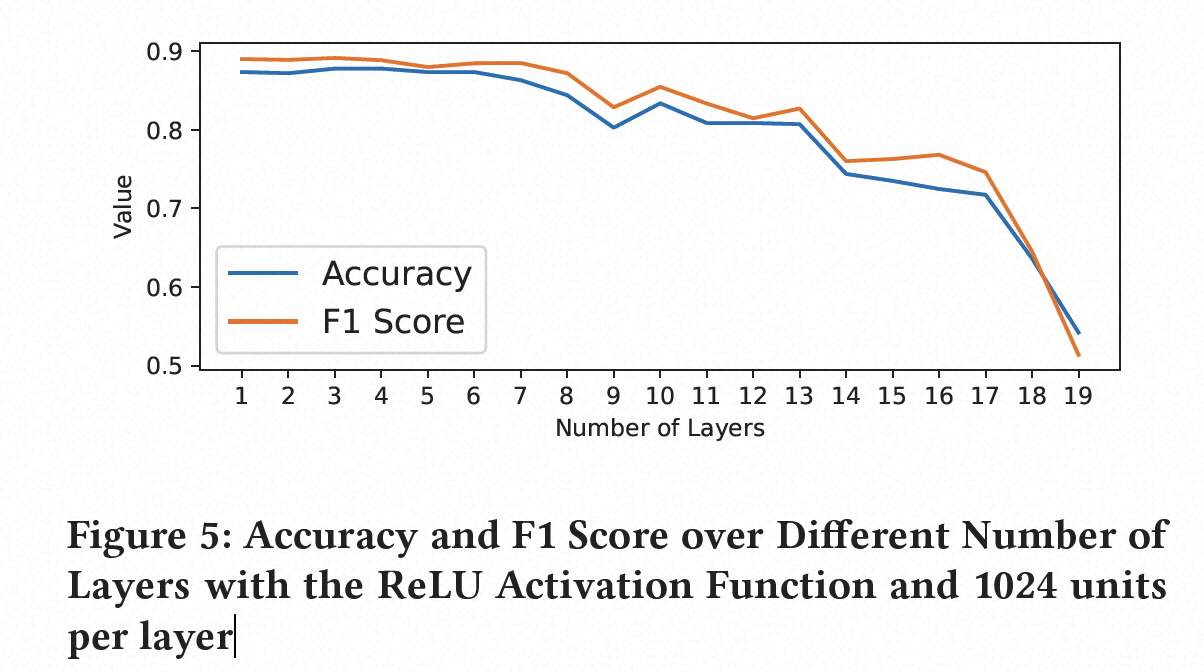
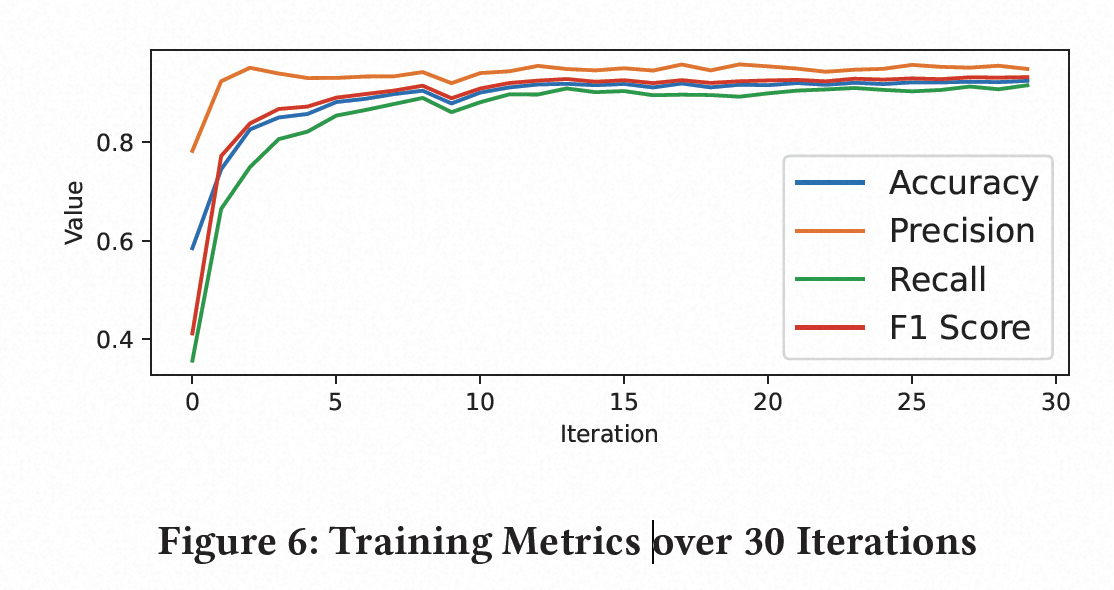
没有跟SOTA的对比