前言
通常我们在开发完Flink任务提交运行后,需要对任务的参数进行一些调整,通常需要调整的情况是任务消费速度跟不上数据写入速度,从而导致实时任务出现反压、内存GC频繁(FullGC)频繁、内存溢出导致TaskManager被Kill。
今天讲一下Flink任务中常见的性能场景及解决思路。
反压
在Flink任务中多个Task之间需要进行数据交换,在流式计算中数据的生产方的生产速度和消费方的消费速度不匹配时,可能会导致计算节点OOM或丢失数据,在Flink中通过反压机制平衡数据生产方和消费方的处理速度,以求系统达到整体的平衡。
实时任务出现反压时,在Blink版本中做了大量的改进,从资源使用、作业调优、日志查询等维度新增了大量功能,使得用户可以更方便的对Flink作业进行运维,Vertex 增加了InQueue,OutQueue等多项指标,可以方便的追踪数据的反压、过滤及倾斜情况通常,我们可以通过在Flink Web UI中观察出现红色的Vertex节点及其上下游,重点需要关注的指标是Out Queue的占用率,当Out Queue占用率高表示该节点的下游节点消费能力不足,需要重点调解该下游节点的计算资源(已贡献社区)。
如果是老的Flink版本,可以先在 Flink web ui 中,定位到具体的算子之后,查看 BackPressure 模块,通过颜色和数值来判断任务的繁忙和反压情况(若颜色为红色,表示当前算子繁忙,有反压的情况;若颜色为绿色,标识当前算子不繁忙,没有反压)。
如果你看到 subtasks 的状态为 OK 表示没有反压。HIGH 表示这个 subtask 被反压。状态用如下定义:
- OK: 0% <= 反压比例 <= 10%
- LOW: 10% < 反压比例 <= 50%
- HIGH: 50% < 反压比例 <= 100%

常见场景及解决思路
场景一、任务反压(算子消费瓶颈)
典型场景为,一连串的计算节点都是红色,Out Queue都是100%,此时需要定位到最后一个Out Queue为100%的算子节点的下游节点,该节点的消费能力不达标,导致上游消息堆积。我们可以对该算子的资源进行调整,如 适当调大并发度,对应内存可适当调小,如果是窗口聚合节点则可以调大内存(在开窗场景下,window数据计算节点需要缓存窗口大小时长的数据,并在checkpoint时需要将窗口的中间状态存储,因此需要增加窗口计算节点的堆内存)
场景二、任务无反压,但延迟高(source端瓶颈)
这种情况表现为,整体没有出现明显反压,即所有计算节点的Out Queue都不高。
这种情况的出现,有可能是上游源头节点的并发度不够,如kafka的topic有三个分区,消费的时候,只开了一个并发,通常建议消费并发数和topic的分区一致。
如果增加source的并发度之后,延迟没有下降,则可能是在任务源头节点包含复杂计算,且该算子和源头并发一致,出现了合并任务链(operater chain),此时可以考虑将source算子单独剥离出来,即调整source下游算子的并发度,解除合并任务链。
场景三、任务异常(内存超用)
实时任务异常Failover的情况下,我们需要关注任务是否因为某个TaskManager内存超用被kill的情况,如果发现异常日志中记录了:
"org.apache.flink.runtime.io.network.netty.exception.RemoteTransportException: Connection unexpectedly closed by remote task manager 'null'. This might indicate that the remote task manager was lost"
则普遍情况是因为内存超用,我们需要根据异常信息中提示的任务节点,调整执行计划中对应节点的内存配置,具体可在WebUI中查看Exceptions模块中查看,其中Root Exception里面记录了最新一次发生的异常栈,Exception History中记录的是任务运行过程中所有发生的异常,以及每次异常的计算节点是哪些。
场景四、GroupBy
针对group by场景,可以通过配置minibatch,来提升吞吐,降低状态的访问,减少对下游的输出压力。
在Stram SQL纯流模式下,每进来一条数据都会去操作state,IO消耗较大,设置minibatch后,同一个key的一批数据只访问一次state,且只输出最新的一条数据,即减少了state的访问也减少了向下游的数据更新,minibatch的配置如下:
# 1. 表示整个job允许延迟
blink.miniBatch.allowLatencyMs=5000# 2. 单个batch的size
blink.miniBatch.size=1000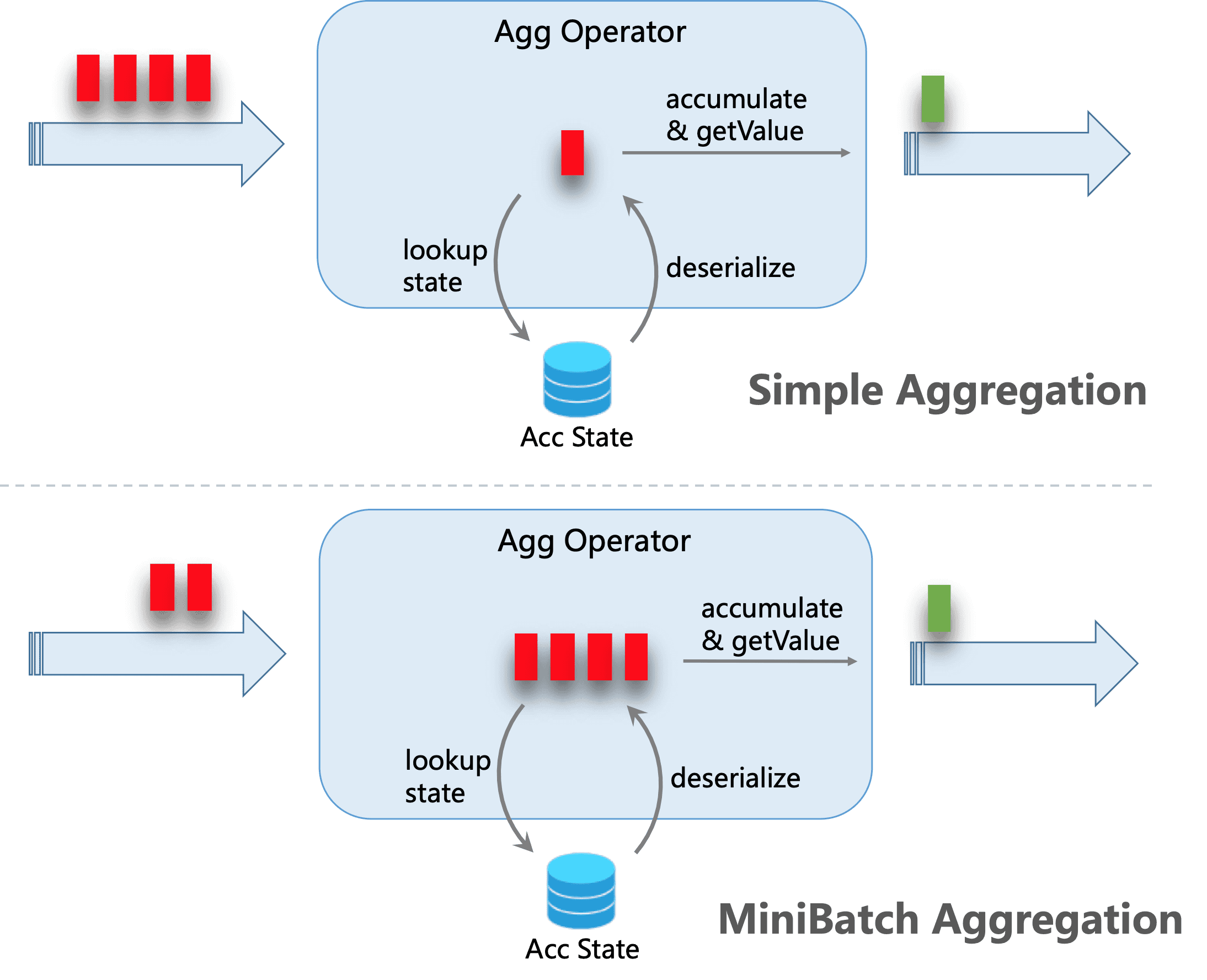
场景五、任务重启,并设置重启时间(初始时间)
这种情况一般出现在任务刚启动时有非常高的延迟,可能是因为在任务启动时或重启时设置了一个比较老的start time,导致任务从很早的时间开始拉取数据,会导致刚开始整个任务的qps非常高,在监控上的表现为一开始有很高的延迟,随后缓慢下降直到正常水平,若没有下降则可以适当增加资源,一般来说这种情况不需要特殊处理,可以根据实际需求来判断是否需要调整start time为当前时间。
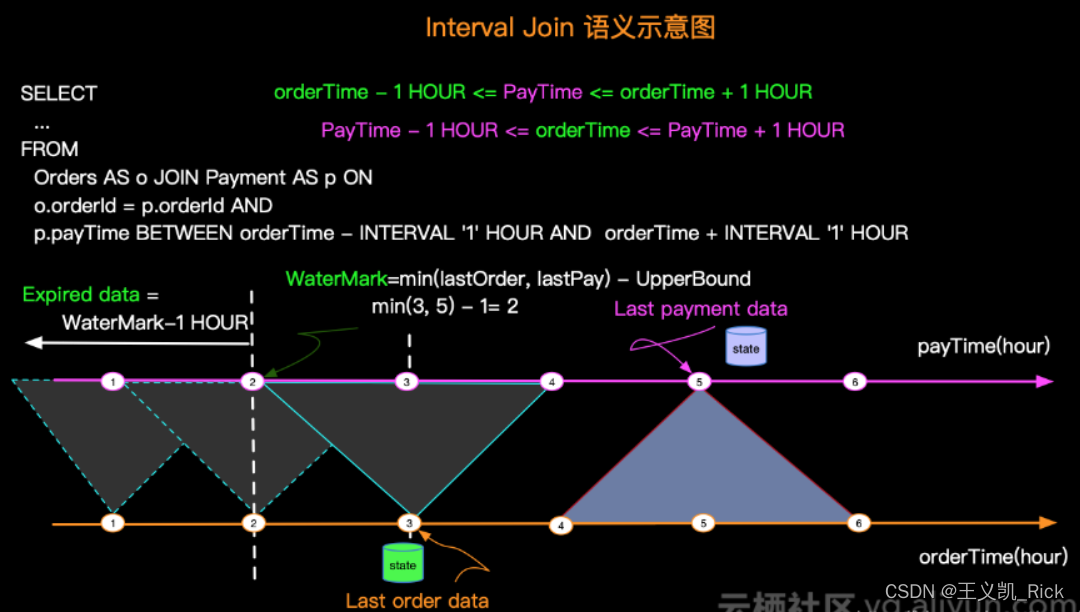
场景六、Time Interval Join 代替 双流Join
建议在双流join的时候,使用时间窗口join,而不是双流join。
默认情况下双流join会将两条流的数据都缓存到状态中,默认状态存储时长为1.5天,状态太大会导致join算子性能低下。
而实际上大部分场景,join都是由时效性要求的,比如商品曝光1分钟引导的点击,其业务上隐含了数据的时效性关联条件,当数据失效后,它的状态是可以清理掉释放资源。
总结
- 判断是否出现反压,在反压节点定位算子,增加并发或调整cpu资源;
- 若无明显反压,则可能是source端瓶颈,可以提升并发度,尽量和source源的分区数量一致,另外可以查看是否是因为source数据处理的算子逻辑太复杂,且和读算子并行一致出现合并任务链(operater chain)的情况,此时可以调整该计算算子的并行度,将source算子剥离出链。
- 参数优化,配置minibatch(针对GroupBy),可提升吞吐,降低状态的访问次数,减少对下游的输出压力。
- 双流join场景中使用Time Interval Join,而不是双流Join,双流Join会把状态保持1.5天,非常消耗资源。
- 重置任务时,根据实际需求出发,若默认很久以前的数据可放弃,则可以调整start time为较近的时间。
- 提升batchSize增加读写IO。
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!