最近发现ES是个很重要的内容啊,各种大厂都会使用ES来做一些大范围的搜索之类的功能,所以今天我们也来学习一下。
首先我们要准备Java的环境,推荐版本8、11、14
ES官方的JDK兼容性列表(有些慢,需要耐心等待一下哈)
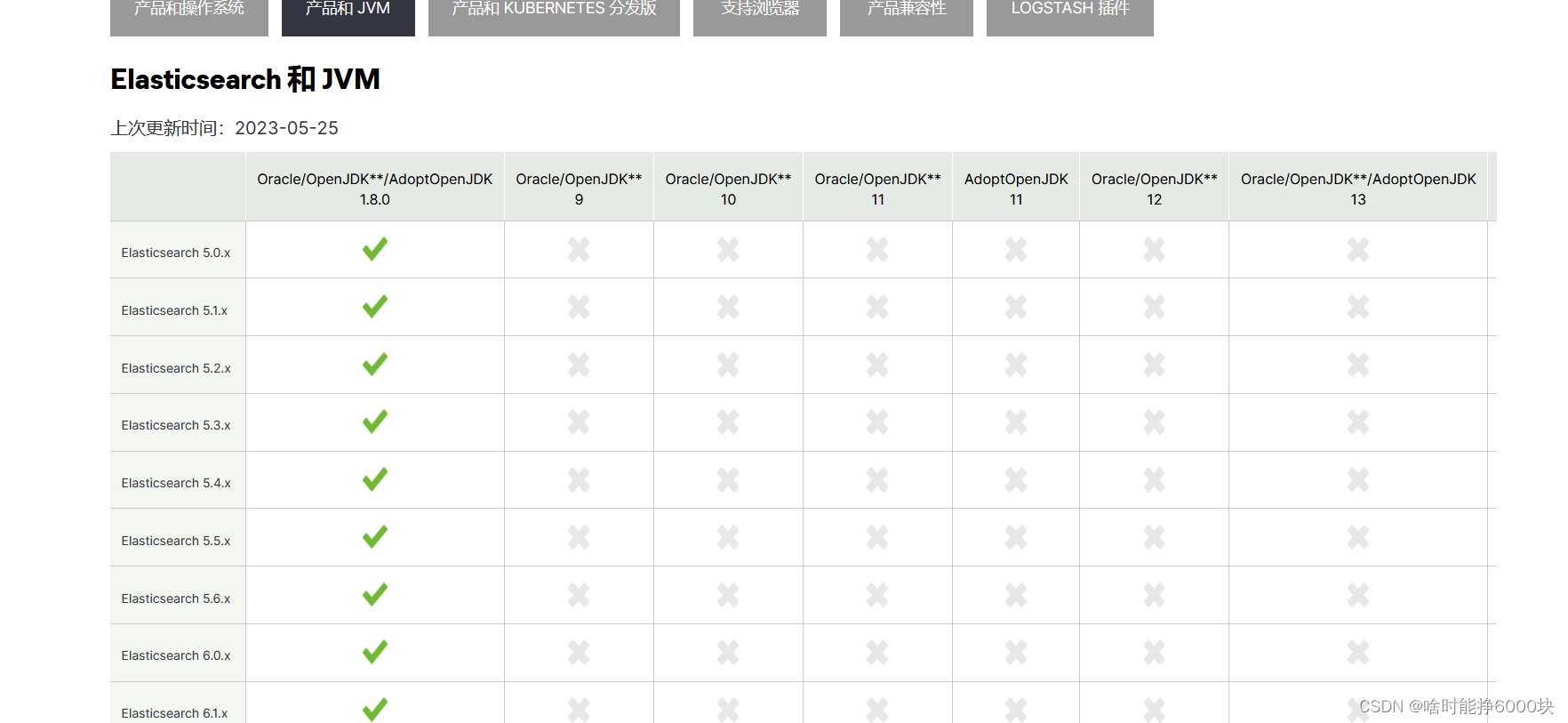
在我写文章时,针对JDK1.8能支持的ES最高版本是Elasticsearch 7.17版本。
ES官方的操作系统兼容性列表(有些慢,需要耐心等待一下)
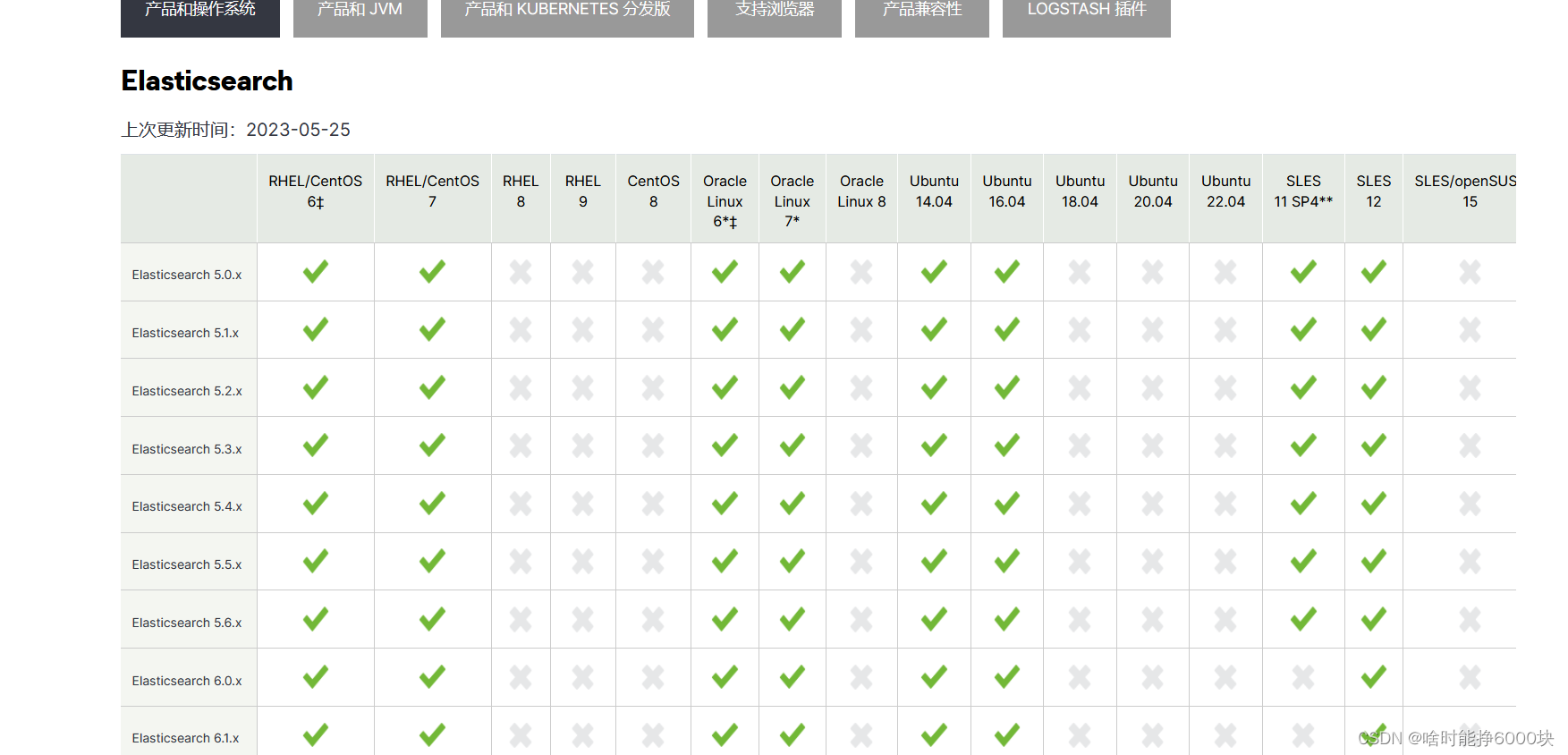
ES官方的自身产品兼容性(同样有些慢)

接下来我们要开始下载安装ES了
elastic官方下载地址 或者使用 elastic中文下载中心
我这边访问官方地址太慢了,所以就用后者下载中心进行下载了,学习的版本为7.10.0

下载完成后,我们得到文件

将该文件解压两次,得到最终文件

ElasticSearch目录结构如图:

| 目录名称 | 描述 |
| bin | 可执行脚本文件,包括启动elasticsearch服务,插件管理,函数命令等。 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| lib | elasticsearch依赖的java库。 |
| data | 默认的数据存放目录,包含节点,分片,索引,文档的所有数据,生产环境要求必须修改。 |
| logs | 默认的日志文件存储路径,生产环境要求必须修改。 |
| modules | 包含所有的elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 保存已经安装的插件。 |
| jdk/jdk.app | 7.0以后才有的自带的java环境。 |
然后将我们下载好的文件放到Linux服务器上。
# 解压linux压缩包
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz# 将ES文件夹改名(便于后面使用,不改也没关系)
mv elasticsearch-7.10.0 elasticsearch# 因为安全问题,ES不支持root用户直接访问,所以需要创建新用户
# 在服务器中新增名称为es的用户
useradd es# 设置用户的登录密码,需要输入es用户的密码
passwd es# 将改名后的ES文件夹使用权限赋予用户es
chown -R es:es ES文件的全路径名称# 如果需要删除用户
userdel -r es# ES可能会产生大量文件,所以可以限制每个进程能够打开的最大文件数
vim /etc/security/limits.conf
# 在文件末尾添加
es soft nofile 65535
es hard nofile 65535vim /etc/security/limits.d/20-nproc.conf
# 在文件末尾添加
es soft nofile 65535
es hard nofile 65535vim etc/sysctl.conf
# 在文件末尾添加
vm.max_map_count=655360# 最后重新加载
sysctl -p# 切换用户
su es# 在ES文件夹中bin目录下,输入该命令启动
elasticsearch哎,试了一下午,我的服务器内存不够用了。。。只能用本地windows的ES了。
我们可以通过elasticsearch文件夹中的config目录下的jvm.options去确定ES所需要的内存大小。
通过JDK文件夹中jre/lib/amd64/jvm.cfg文件设置JVM的可分配的内存大小。
最后我在Linux环境上通过free -m(以M为单位展示物理内存的使用情况)发现,剩余内存根本支持不了ES的启动,所以最终放弃了,只有会使用windows版进行学习。
验证服务启动成功:访问 http://localhost:9200 显示类似json内容

到这里ES就安装完成了,希望对小伙伴们有帮助。