随着越来越多的代码生成模型公开可用,现在可以以我们以前无法想象的方式进行文本到网络甚至文本到应用程序。
本教程介绍了一种通过流式传输和渲染内容来生成 AI Web 内容的直接方法。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、在 Node 应用程序中使用 LLM
虽然我们通常将 Python 视为与 AI 和 ML 相关的所有内容,但 Web 开发社区严重依赖 JavaScript 和 Node.js。
以下是你可以在此平台上使用大型语言模型的一些方法。
1.1 在本地运行模型
有多种方法可以在 Javascript 中运行 LLM,从使用 ONNX 到将代码转换为 WASM,再到调用用其他语言编写的外部进程。
其中一些技术现在可以作为即用型 NPM 库提供:
使用 AI/ML 库,例如 Transformers.js(支持代码生成)
使用专用的LLM库,例如llama-node(或浏览器的web-llm)
通过 Pythonia 等桥梁使用 Python 库
然而,在这样的环境中运行大型语言模型可能会占用大量资源,尤其是在你无法使用硬件加速的情况下。
1.2 使用 API
如今,各种云提供商提出了商业 API 来使用语言模型。 以下是当前的 Hugging Face 产品:
免费的推理 API 允许任何人使用社区中的中小型模型。
更先进、可用于生产的推理端点 API,适合需要更大模型或自定义推理代码的用户。
可以使用 NPM 上的 Hugging Face Inference API 库从 Node 使用这两个 API。
💡 性能最佳的模型通常需要大量内存(32 Gb、64 Gb 或更多)和硬件加速才能获得良好的延迟(请参阅基准测试)。 但我们也看到了模型尺寸缩小的趋势,同时在某些任务上保持相对较好的结果,内存要求低至 16 Gb 甚至 8 Gb。
2、系统架构
我们将使用 NodeJS 创建我们的生成式 AI Web 服务器。
该模型将是在推理端点 API 上运行的 WizardCoder-15B,但你可以随意尝试其他模型和技术栈。
如果你对其他解决方案感兴趣,这里有一些替代实现的提示:
- 使用 Inference API:代码和空间
- 使用 Node 中的 Python 模块:代码和空间
- 使用 llama-node (llama cpp):代码
3、初始化项目
首先,我们需要设置一个新的 Node 项目(如果需要,你可以克隆此模板)。
git clone https://github.com/jbilcke-hf/template-node-express tutorial
cd tutorial
nvm use
npm install
然后,我们可以安装Hugging Face Inference客户端:
npm install @huggingface/inference
并在 src/index.mts 中进行设置:
import { HfInference } from '@huggingface/inference'// to keep your API token secure, in production you should use something like:
// const hfi = new HfInference(process.env.HF_API_TOKEN)
const hfi = new HfInference('** YOUR TOKEN **')
4、配置推理端点
💡 注意:如果你不想支付 Endpoint 实例的费用来完成本教程,可以跳过此步骤并查看这个免费的 Inference API 示例。 请注意,这仅适用于较小的型号,其功能可能不那么强大。
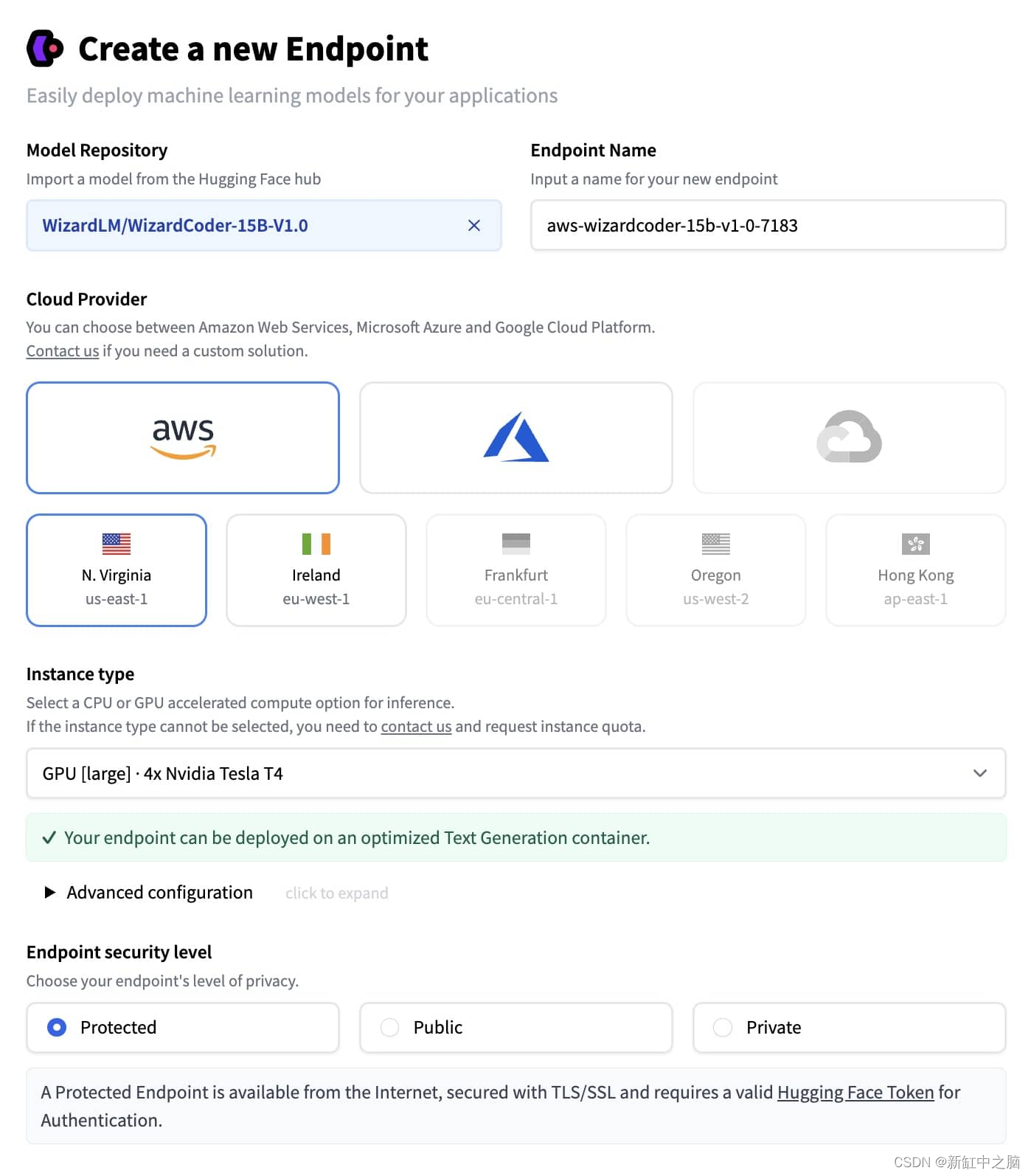
要部署新的端点,你可以转到端点创建页面。
你必须在模型存储库下拉列表中选择 WizardCoder,并确保选择足够大的 GPU 实例:
创建端点后,你可以从此页面复制 URL:
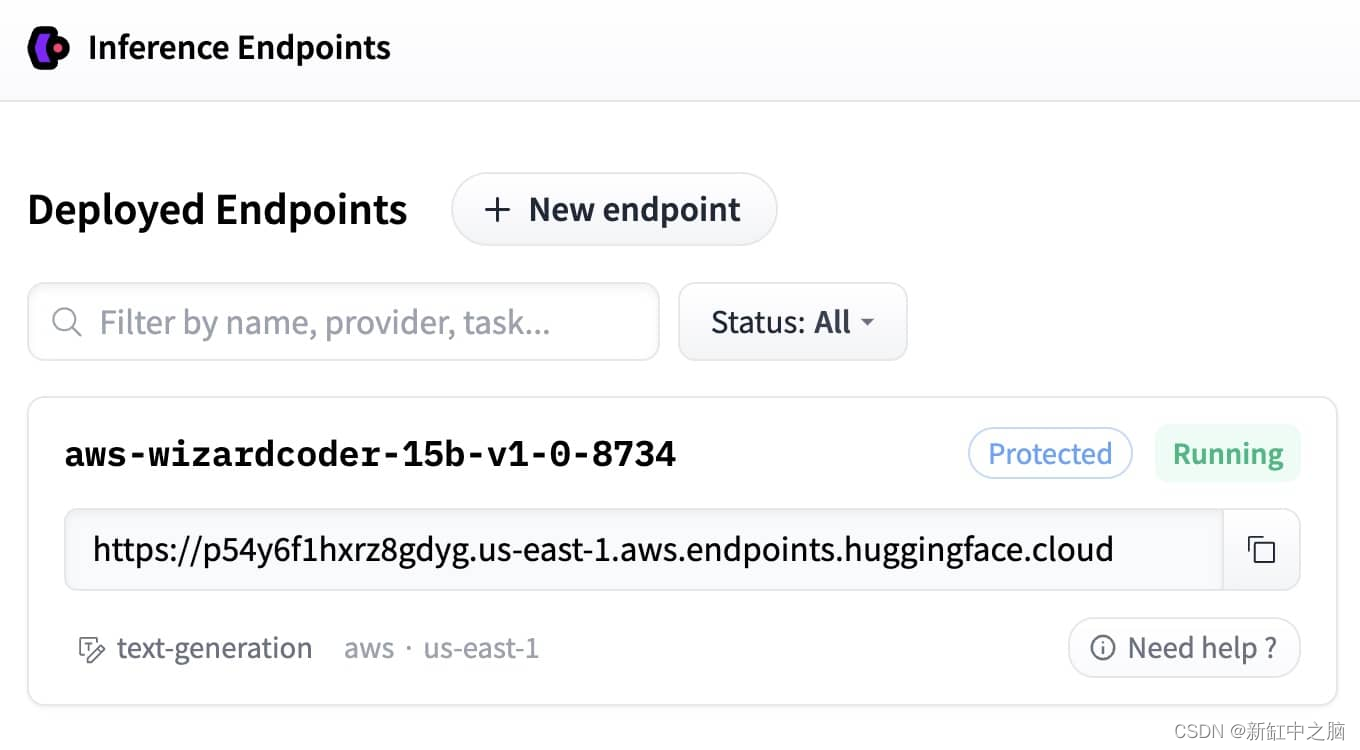
配置客户端以使用它:
const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **')
现在可以告诉推理客户端使用我们的专用端点并调用我们的模型:
const { generated_text } = await hf.textGeneration({inputs: 'a simple "hello world" html page: <html><body>'
});
5、生成 HTML 流
现在是时候在 Web 客户端访问 URL(例如 /app)时向 Web 客户端返回一些 HTML。
我们将使用 Express.js 创建端点,以流式传输 Hugging Face Inference API 的结果。
import express from 'express'import { HfInference } from '@huggingface/inference'const hfi = new HfInference('** YOUR TOKEN **')
const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **')const app = express()
由于我们暂时没有任何 UI,界面将是一个简单的提示 URL 参数:
app.get('/', async (req, res) => {// send the beginning of the page to the browser (the rest will be generated by the AI)res.write('<html><head></head><body>')const inputs = `# Task
Generate ${req.query.prompt}
# Out
<html><head></head><body>`for await (const output of hf.textGenerationStream({inputs,parameters: {max_new_tokens: 1000,return_full_text: false,}})) {// stream the result to the browserres.write(output.token.text)// also print to the console for debuggingprocess.stdout.write(output.token.text)}req.end()
})app.listen(3000, () => { console.log('server started') })
启动你的Web服务器:
npm run start
然后打开链接 https://localhost:3000?prompt=some prompt。 片刻之后你应该会看到一些原始的 HTML 内容。
6、调整提示
每种语言模型对提示的反应都不同。 对于 WizardCoder,简单的指令通常效果最好:
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
Write application logic inside a JS <script></script> tag.
Use a central layout to wrap everything in a <div class="flex flex-col items-center">
# Out
<html><head></head><body>`
7、使用Tailwind
Tailwind 是一种流行的 CSS 内容样式框架,WizardCoder 擅长开箱即用。
这允许代码生成随时随地创建样式,而不必在页面的开头或结尾生成样式表(这会让页面感觉卡住)。
为了提高结果,我们还可以通过显示方式来引导模型( )。
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
You must use TailwindCSS utility classes (Tailwind is already injected in the page).
Write application logic inside a JS <script></script> tag.
Use a central layout to wrap everything in a <div class="flex flex-col items-center'>
# Out
<html><head></head><body class="p-4 md:p-8">`
8、预防幻觉
与较大的通用模型相比,在专用于代码生成的轻型模型上可靠地防止幻觉和失败(例如鹦鹉学舌地回传整个指令,或编写“lorem ipsum”占位符文本)可能很困难,但我们可以尝试减轻 它。
你可以尝试使用祈使语气并重复说明。 一种有效的方法还可以是通过用英语给出部分输出来显示方法:
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
Never repeat these instructions, instead write the final code!
You must use TailwindCSS utility classes (Tailwind is already injected in the page)!
Write application logic inside a JS <script></script> tag!
This is not a demo app, so you MUST use English, no Latin! Write in English!
Use a central layout to wrap everything in a <div class="flex flex-col items-center">
# Out
<html><head><title>App</title></head><body class="p-4 md:p-8">`
9、添加对图像的支持
我们现在有一个可以生成 HTML、CSS 和 JS 代码的系统,但当要求生成图像时,它很容易产生幻觉损坏的 URL。
幸运的是,在图像生成模型方面我们有很多选项可供选择!
→ 最快的入门方法是使用我们的免费推理 API 以及hub上可用的公共模型之一来调用稳定扩散模型:
app.get('/image', async (req, res) => {const blob = await hf.textToImage({inputs: `${req.query.caption}`,model: 'stabilityai/stable-diffusion-2-1'})const buffer = Buffer.from(await blob.arrayBuffer())res.setHeader('Content-Type', blob.type)res.setHeader('Content-Length', buffer.length)res.end(buffer)
})
将以下行添加到提示符中足以指示 WizardCoder 使用我们新的 /image 端点! (你可能需要针对其他模型进行调整):
To generate images from captions call the /image API: <img src="/image?caption=photo of something in some place" />
你也可以尝试更具体,例如:
Only generate a few images and use descriptive photo captions with at least 10 words!
10、添加一些用户界面
Alpine.js 是一个极简框架,允许我们创建交互式 UI,无需任何设置、构建管道、JSX 处理等。
一切都在页面内完成,因此非常适合创建快速演示的 UI。
这是一个静态 HTML 页面,你可以将其放入 /public/index.html 中:
<html><head><title>Tutorial</title><script defer src="https://cdn.jsdelivr.net/npm/alpinejs@3.x.x/dist/cdn.min.js"></script><script src="https://cdn.tailwindcss.com"></script></head><body><div class="flex flex-col space-y-3 p-8" x-data="{ draft: '', prompt: '' }"><textareaname="draft"x-model="draft"rows="3"placeholder="Type something.."class="font-mono"></textarea> <buttonclass="bg-green-300 rounded p-3"@click="prompt = draft">Generate</button><iframe :src="`/app?prompt=${prompt}`"></iframe></div></body>
</html>
要实现此功能,你必须进行一些更改:
...// going to localhost:3000 will load the file from /public/index.html
app.use(express.static('public'))// we changed this from '/' to '/app'
app.get('/app', async (req, res) => {...
11、优化输出
到目前为止,我们已经生成了 Tailwind 实用程序类的完整序列,这对于赋予语言模型设计自由非常有用。
但这种方法也非常冗长,消耗了我们很大一部分代币配额。
为了使输出更密集,我们可以使用 Daisy UI,这是一个 Tailwind 插件,它将 Tailwind 实用程序类组织到设计系统中。 这个想法是对组件使用简写类名,对其余部分使用实用程序类。
有些语言模型可能没有 Daisy UI 的内部知识,因为它是一个小众库,在这种情况下,我们可以在提示中添加 API 文档:
# DaisyUI docs
## To create a nice layout, wrap each article in:
<article class="prose"></article>
## Use appropriate CSS classes
<button class="btn ..">
<table class="table ..">
<footer class="footer ..">
12、更进一步
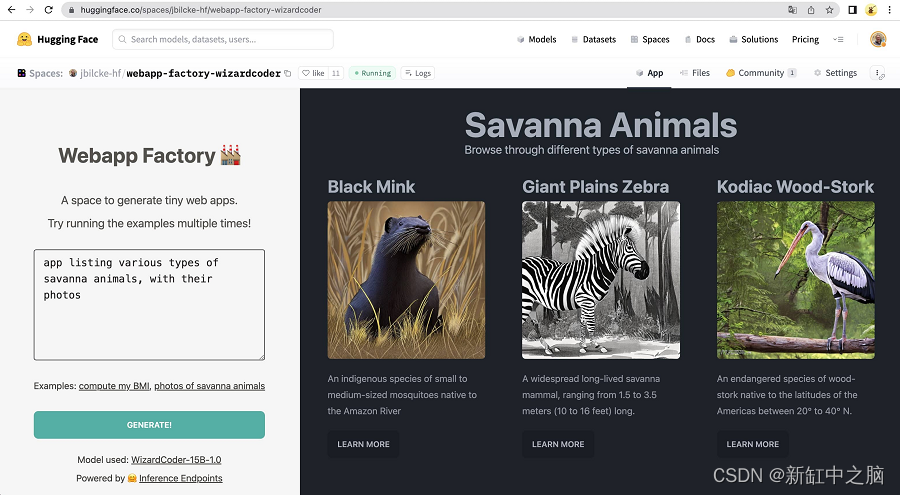
最终的演示空间包括更完整的用户界面示例。
以下是进一步扩展此概念的一些想法:
- 测试其他语言模型,例如 StarCoder
- 为中间语言(React、Svelte、Vue…)生成文件和代码
- 将代码生成集成到现有框架内(例如 NextJS)
- 从失败或部分代码生成中恢复(例如 JS 中的自动修复问题)
- 将其连接到聊天机器人插件(例如,在聊天讨论中嵌入小型网络应用程序 iframe)
原文链接:大模型Web App生成器开发 — BimAnt