生成式AI,尤其是以ChatGPT为首的大语言模型正在改变人们的生活方式,我想一定有小伙伴想加入NLP这个行列。
微软重磅发布4个适合初学者的机器学习资料
我在前一篇文章中分享了微软人工智能初学者课程,其中的【生成式AI】非常适合初学者,今天我将分享NLP的进阶课程。
https://web.stanford.edu/class/cs224n/
关注v公众号:人工智能大讲堂,后台回复snlp获取全部资料。
资料分为三种:课堂讲义,课后笔记,相关论文。
第一周课程:
第一讲:词嵌入
计算机只能处理数字,在将文本输入到模型之前,需要将其数字化,而词嵌入就是一种将文本数字化的方法。
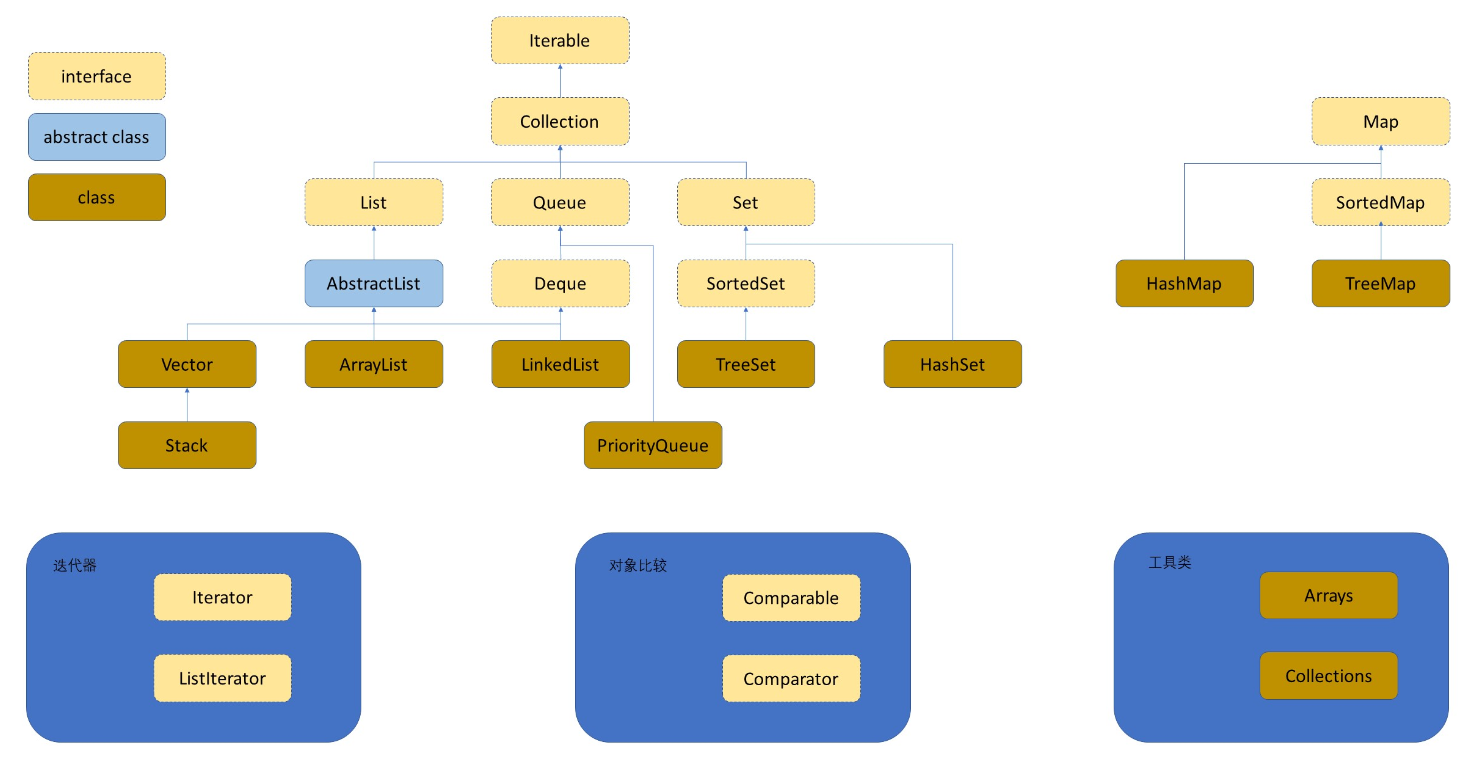
在讲词嵌入之前,有必要先讲一下Tokenizer,Tokenizer是将文本分割成Token,常见的Token有字符,单词,或者子词(sub word)。
Tokenizer后,就可以将Token转换成数字了。
最简单的方式是直接使用字符编码(ASCII,Unicode),但这种方式无法保留单词的语义信息,且不同编码方式之间无法进行转换。
另一种方法是,因为常用的字符和词的个数是有限的,可以构造字典或者词典,然后将字符或者单词替换成在字典或者词典中的位置,或者是one-hot编码。但这种方式仍然无法保留语义信息。
什么是语义信息?可以这么理解,“男人”和“皇帝”语义相近,所以在向量空间中距离应该接近,也就是向量余弦相似度大。
上面这三种方法是一种硬编码方法,而词嵌入是一种软编码方法。
因为单词与字符相比具有更丰富的语义信息,所以NLP中通常将文本分割成词或者子词(sub word)。
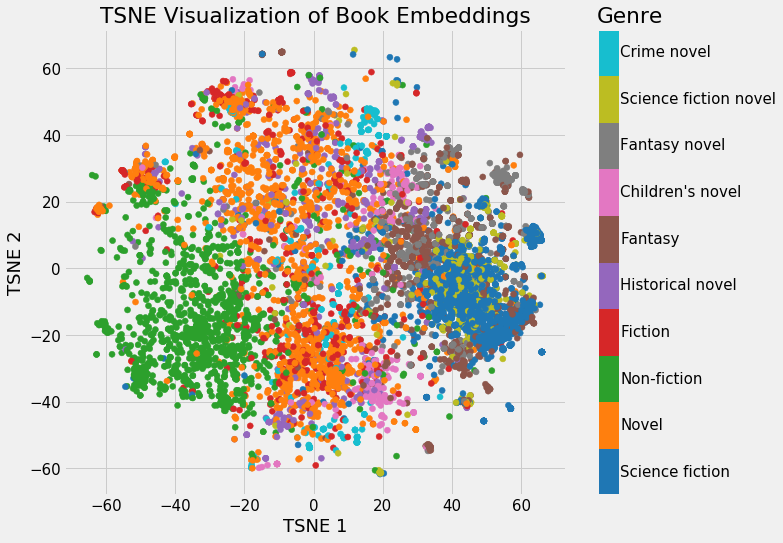
Tokenizer后就可以进行词嵌入了,将词转换成具有语义信息向量的方法就是词嵌入方法,word2vec就是其中一种。其主要思想是通过神经网络模型对大规模语料进行训练,训练完成后得到词向量矩阵。

例如,如果一个词表有4096个单词,每个单词用512维向量表示,那么word2vec训练完成后就得到一个4096*512大小的矩阵,或者将矩阵构造成查找表,通过Tokenizer后的one-hot编码与词向量矩阵相乘或者根据位置索引查表就能得到词嵌入向量了。
第二讲:语言模型
将文本数字化后,接下来讲语言模型,语言模型(Language Model)是自然语言处理中的一个核心问题,是用来计算一个序列词语或字符出现的概率的模型。它也是后续GPT,Bert等大语言模型的理论基础。
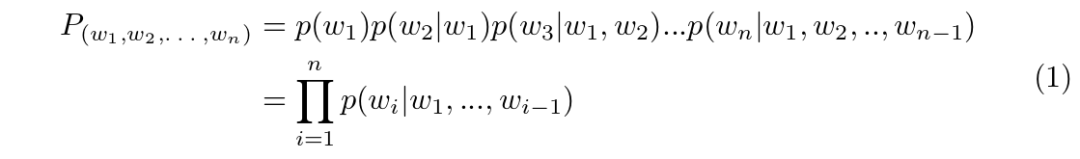
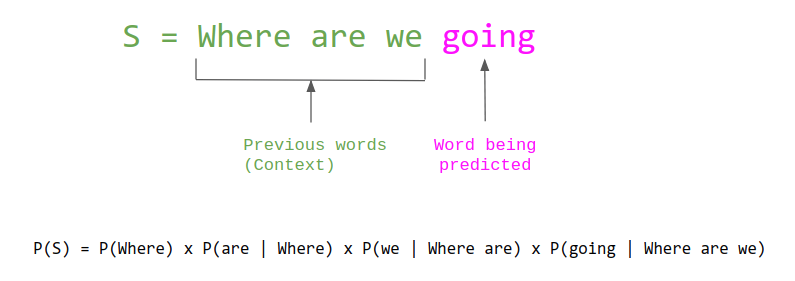
常用的语言模型主要有以下几类:
n-gram语言模型
基于n-gram统计的传统语言模型,通过统计语料中序列出现的次数来估计概率。
如果n=2,也就是计算一个词跟在另一个词后面出现的概率。比如对句子“我爱北京天安门”,可以计算概率:
P(天安门|北京) = C(北京天安门)/C(北京)
这里:
-
C(北京天安门) 是“北京天安门”这个2-gram的出现次数
-
C(北京) 是“北京”这个1-gram的出现次数
n太小会导致语言模型太弱,n太大会导致概率无法估计。
深度学习模型
所以,更常用的方式是通过神经网络去构建语言模型,通过词向量和神经网络映射,获得词语的分布式表示。如RNN、LSTM、GRU,Transformer等语言模型。学习能力强,但是需要大量数据和计算资源。
其中,transformer模型效果最好。
第二周课程:
第一讲:神经网络和反向传播
既然已经明确了用神经网络去构建语言模型,那么有必要了解NLP中常用的模型架构以及如何训练模型。
NLP处理的是时序数据,擅长处理时序数据的是循环神经网络,按照NLP的发展历程来看,其模型经历了RNN->LSTM->GRU->Transformer的迭代。
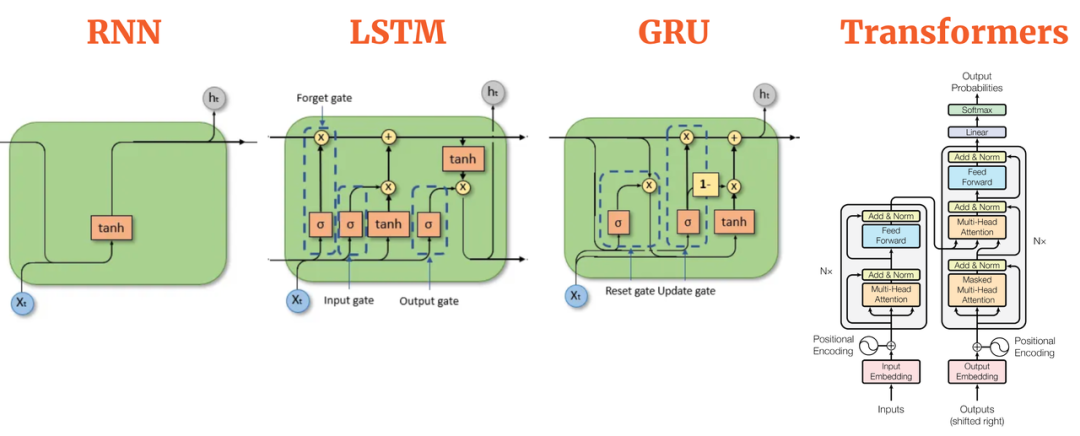
Transformer已经成为主流模型,除了其自身的注意力机制外,还有一个优点,在CV中,当模型越来越大后,虽然可以通过残差连接加快模型收敛,但模型的效果提升有限,而Transformer在数据量和计算资源充足的情况下,模型越大效果越好,这也是为什么大公司都在搞军备竞赛一样,动不动就搞出个1000多亿个参数的模型。
但循环神经网络的训练过程也要比CV更复杂,RNN训练过程就容易出现梯度消失和爆炸问题。
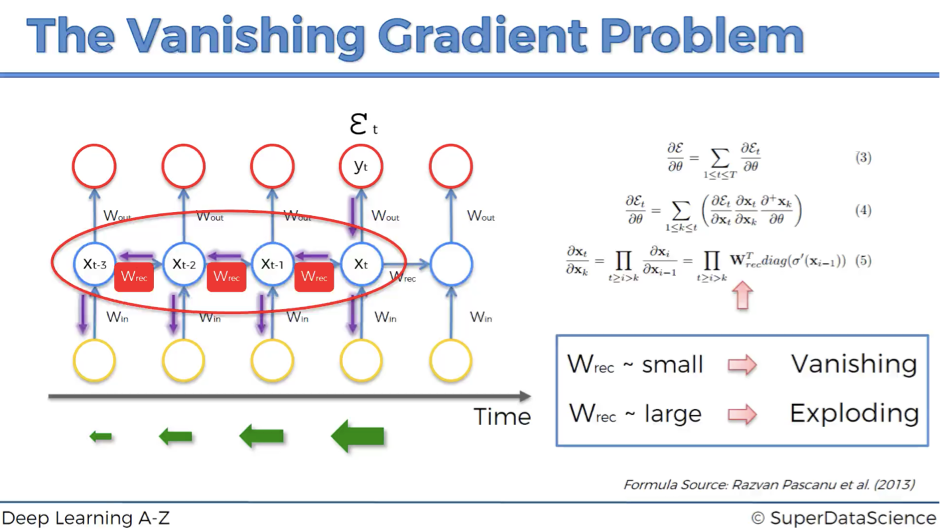
虽然训练复杂,但本质上也是基于链式法则的反向传播过程对参数进行更新。
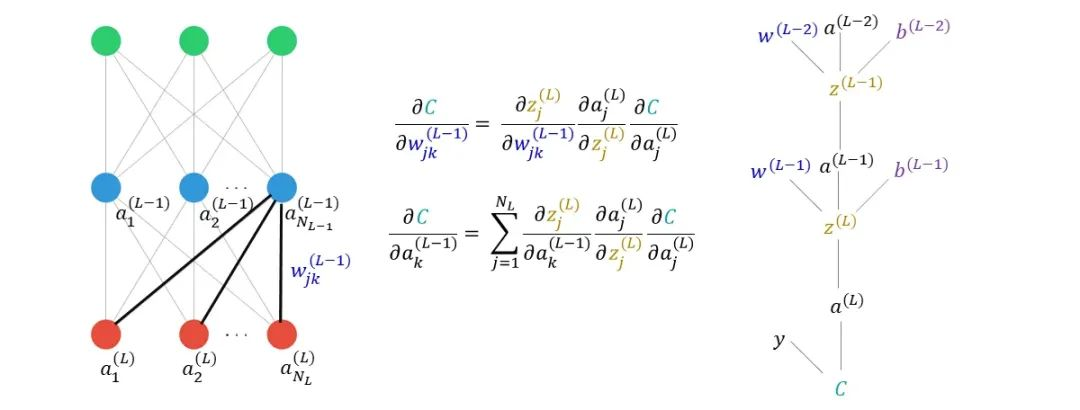
第三周课程:
第一讲:RNN和语言模型
第三周主要讲解具体的模型,第一个是RNN,因为RNN是NLP的鼻祖。
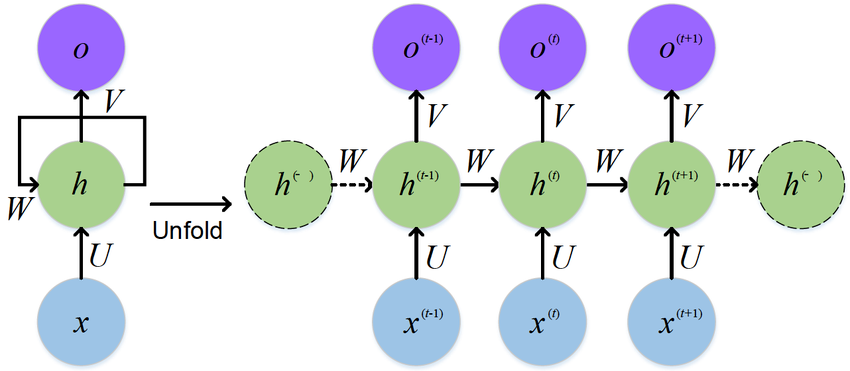
同CV中的模型一样,RNN也有输入层,隐藏层,和输出层,不同的是,它有时间的概念,不同时间步参数是共享的。
如果是类似机器翻译的任务,也就是seq in,seq out,那么每一个输入后,都会有一个输出。
如果是类似情感分析的人类任务,则使用最后一个时间步的隐藏状态,因为它考虑了前面所有时间的隐藏状态。
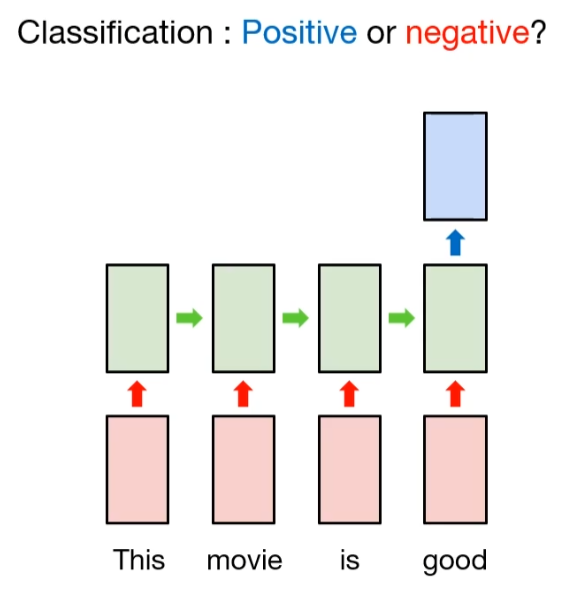
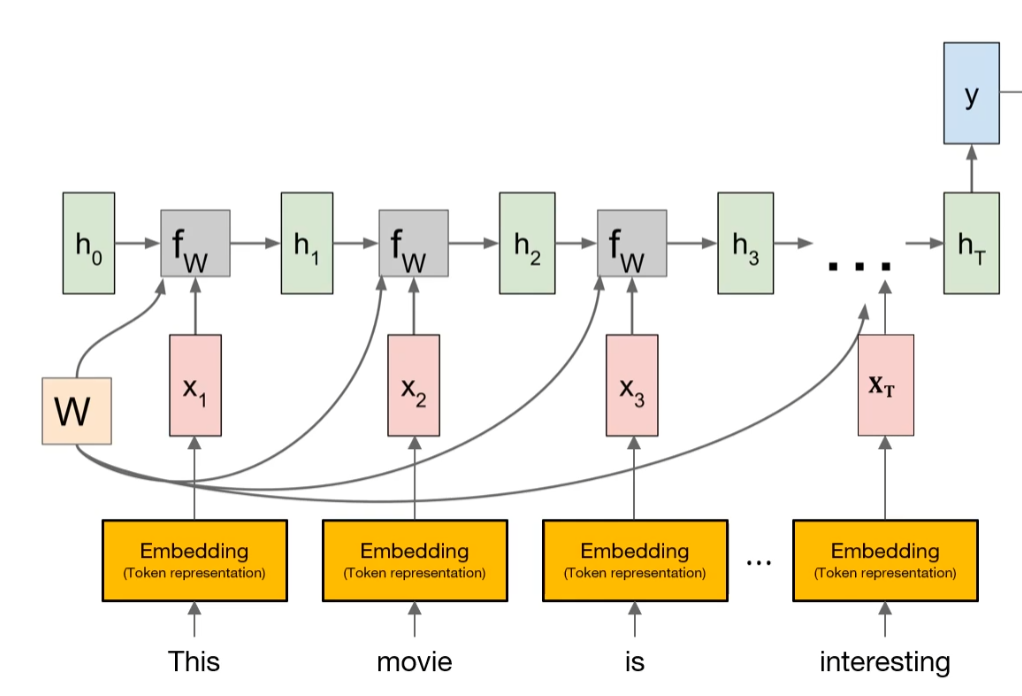
第二讲:Seq2Seq模型
对于seq in,seq out的任务,如果使用RNN模型,也就是每一个输入后都有一个输出,那么输出只会考虑当前时间点以前的输入和隐藏状态,并没有捕获整个输入的信息。
为了捕获整个输入的信息,就有了Seq2Seq模型,本质上是一个编码器和解码器模型,编码器对输入进行编码,保存到隐藏状态中,然后在解码器中使用编码器中的隐藏状态。
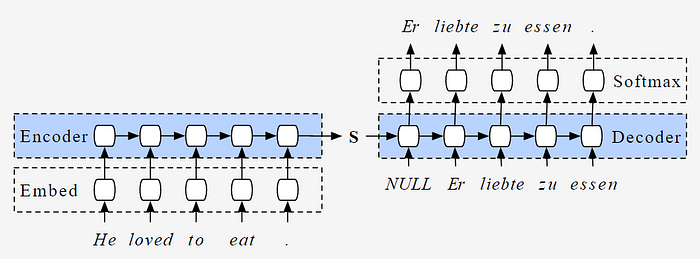
第四周课程:
第一讲:Tranformer
Tranformer太重要了,所以整个一周都在讲Tranformer。
Tranformer也是一种编码器-解码器结构,编码器和解码器中都通过多头注意力机制捕获不同位置单词的关系。
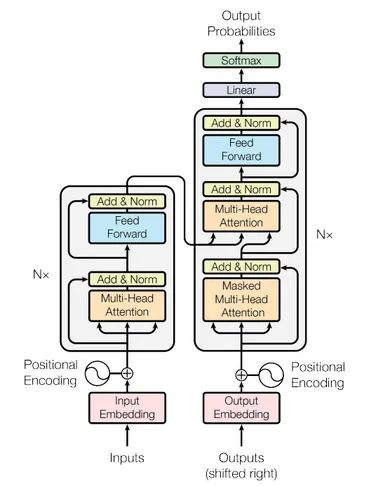
GPT就是一种transformer Decoder模型,Bert则是transformer Encoder模型,本质上都可以看作是概率模型。

第五周课程:
第一讲:预训练模型
大模型可以分为基础模型或者通用模型,以及在基础模型上进行微调而来的专用模型。
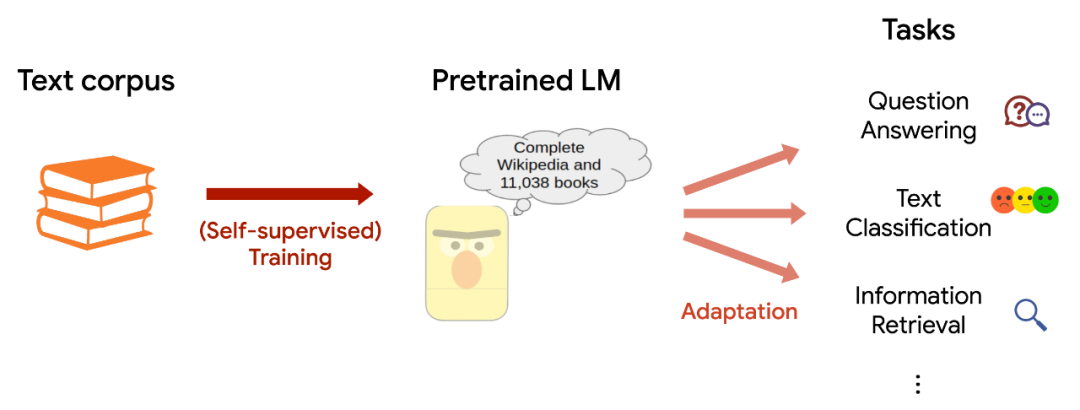
基础模型也被成为预训练模型,是在大量预料库中进行无监督训练而来的。
以Bert为例,如果直接使用Bert的预训练模型,因为Bert是一种Encoder模型,只能完形填空。
如果要使用Bert进行聊天怎么办?这就需要在预训练模型基础上进行有监督的微调,例如,使用成对的问答预料,加上人类反馈的强化学习。
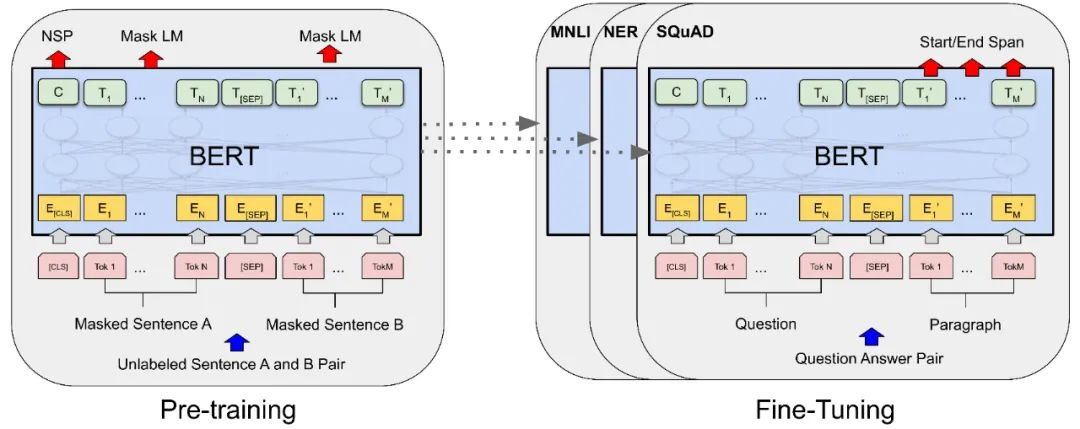
我们目前所使用的ChatGPT也是在GPT 3.5-turbo预训练模型的基础上微调而来的。
第六周课程:
第一讲:提示微调
前面我们提到了需要在预训练模型的基础上进行微调才能得到能够聊天,问答,总结的专用模型,那有哪几种微调方法呢?
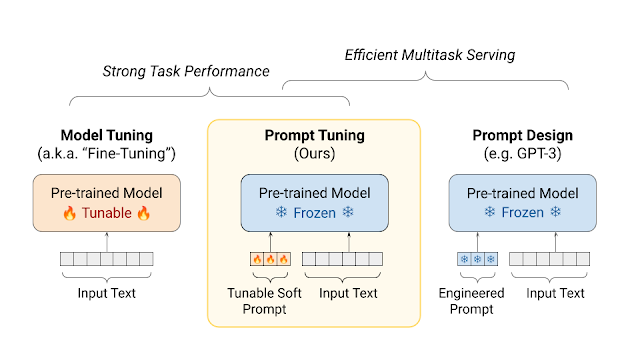
一种是全量微调,也就是用有监督的方式,在训练数据上对模型的全部参数进行调整,如果要想得到效果好的模型,就需要大量的有监督数据和计算资源。
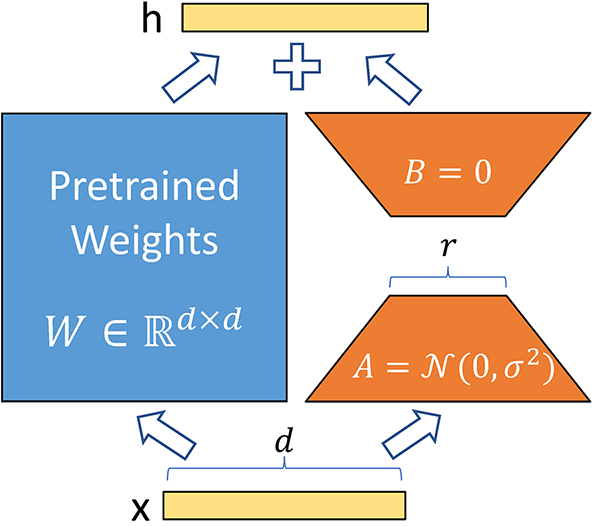
另一种是只调整部分参数,例如LoRA,通过训练两个低秩矩阵来模拟参数的更新,而两个低秩矩阵的参数远小于原始参数的量。
最后一种是原始模型的参数冻结,在提示词上下功夫,通过学习在提示词前面加上一个前缀,或者将提示词映射成模型更能理解的提示词。这样做的好处是如果要训练多个专用模型,内存中只需要存储一个原始模型即可。