制作一个简单的C语言词法分析程序_用c语言编写词法分析程序-CSDN博客文章浏览阅读322次。C语言的程序中,有很单词多符号和保留字。一些单词符号还有对应的左线性文法。所以我们需要先做出一个单词字符表,给出对应的识别码,然后跟据对应的表格来写出程序。_用c语言编写词法分析程序https://blog.csdn.net/lijj0304/article/details/134078944
前置程序词法分析器参考这个帖子⬆️
递归下降语法分析程序设计与实现-CSDN博客文章浏览阅读127次。制作一个简单的C语言词法分析程序_用c语言编写词法分析程序-CSDN博客文章浏览阅读276次。C语言的程序中,有很单词多符号和保留字。一些单词符号还有对应的左线性文法。所以我们需要先做出一个单词字符表,给出对应的识别码,然后跟据对应的表格来写出程序。_用c语言编写词法分析程序前置程序词法分析器参考这个帖子⬆️。https://blog.csdn.net/lijj0304/article/details/134331022
递归下降实现语法分析可以看这个⬆️
1.程序目标
制作一个LL(1)语法分析程序,程序可以识别词法分析器的输出文件中的二元序列,拼凑出用户输入。通过表驱动程序,实现赋值语句的LL(1)文法的LL(1)分析过程。算式的语法如下:
G[S]: S→V=E E→TE′ E′→ATE′|ε T→FT′ T′→MFT′|ε F→ (E)|i A→+|-M→*|/ V→i
2.程序设计
我根据给定的语法,计算处所需要用到的first集和follow集,接着做select集,然后可以做出LL(1)分析表:
| i | + | - | * | / | ( | ) | # | |
|---|---|---|---|---|---|---|---|---|
| S | S→V=E | |||||||
| E | E→TE’ | E→TE’ | ||||||
| E’ | E’→ATE’ | E’→ATE’ | E’→ ε | E’→ ε | ||||
| T | T→FT’ | T→FT’ | ||||||
| T’ | T’→ ε | T’→ ε | T’→MFT’ | T’→MFT’ | T’→ ε | T’→ ε | ||
| F | F→i | F→(E) | ||||||
| M | M→* | M→/ | ||||||
| A | A→+ | A→- | ||||||
| V | V→i |
LL(1)的语法分析部分使用栈的思想来实现,定义了一个字符串的栈stack,LL1分析过程中产生的串存储在栈中,同时对于输入串有一个定位指针,栈顶元素和指针指向的字符比对,一样则栈顶元素出栈,指针往后移动。
下面是程序LL(1)分析流程图
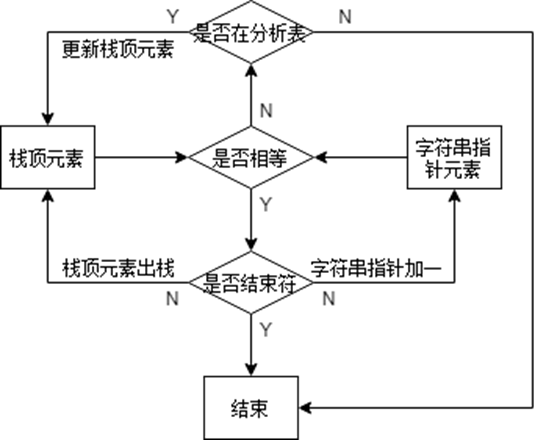
3.完整程序
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#define MAX_LEN 1000
char str[MAX_LEN];
char stack[MAX_LEN];
int top = 0;int LL1(char *str, char *stack) {int i = 0;while(str[i] != '#') {if(top < 0) return 0;if(stack[top] == str[i]) {printf("%c -> ", stack[top]);top--;i++;}else if(stack[top] == 'S') {if(str[i] == 'i') {stack[top++] = 'E';stack[top++] = '=';stack[top] = 'V';}else return 0;}else if(stack[top] == 'E') {if(str[i] == 'i') {stack[top++] = 'e';stack[top] = 'T';}else if(str[i] == '(') {stack[top++] = 'e';stack[top] = 'T';}else return 0;}else if(stack[top] == 'e') {if(str[i] == '+') {stack[top++] = 'e';stack[top++] = 'T';stack[top] = 'A';}else if(str[i] == '-') {stack[top++] = 'e';stack[top++] = 'T';stack[top] = 'A';}else if(str[i] == ')' || str[i] == '#') {printf("%c -> ", str[i]);top--;}else return 0;}else if(stack[top] == 'T') {if(str[i] == 'i') {stack[top++] = 't';stack[top] = 'F';}else if(str[i] == '(') {stack[top++] = 't';stack[top] = 'F';}else return 0;}else if(stack[top] == 't') {if(str[i] == '*') {stack[top++] = 't';stack[top++] = 'F';stack[top] = 'M';}else if(str[i] == '/') {stack[top++] = 't';stack[top++] = 'F';stack[top] = 'M';}else if(str[i] == '+' || str[i] == '-' || str[i] == ')' || str[i] == '#') {printf("%c -> ", str[i]);top--;}else return 0;}else if(stack[top] == 'F') {if(str[i] == 'i') stack[top] = 'i';else if(str[i] == '(') {stack[top++] = ')';stack[top++] = 'E';stack[top] = '(';}else return 0;}else if(stack[top] == 'A') {if(str[i] == '+')stack[top] = '+';else if(str[i] == '-')stack[top] = '-';else return 0;}else if(stack[top] == 'M') {if(str[i] == '*')stack[top] = '*';else if(str[i] == '/')stack[top] = '/';else return 0;}else if(stack[top] == 'V') {if(str[i] == 'i') stack[top] = 'i';else return 0;}else return 0;}return 1;
}int main() {for(int m = 1; m <= 4; m++) {printf("test%d:\n", m);char txt[] = "./lexical/analyze";char num[6];sprintf(num, "%d.txt", m);strcat(txt, num);FILE *fp = fopen(txt, "r");char buf[MAX_LEN] = "";char input[MAX_LEN] = "";fgets(buf, MAX_LEN, fp);int i = 0, j = 0;for(int k = 0; k < strlen(buf); k++) {if(buf[k] == '1' && buf[k+1] == ',') {str[i++] = 'i';k += 3;while(1) {if(buf[k] == ')' && buf[k+1] == ' ')break;input[j++] = buf[k++];}continue;}if(buf[k] == ',' && buf[k+1] == ' ') {k += 2;while(1) {if(buf[k] == ')' && buf[k+1] == ' ')break;str[i++] = buf[k];input[j++] = buf[k++];}}}printf("Input scentence: %s\n", input);str[i] = '#';fclose(fp);stack[0] = 'S', top = 0;int flag = LL1(str, stack);if(flag == 1) {printf("end\n");printf("Gramma legal: %s\n", str);}else {printf("error\n");printf("Gramma illegal\n");}}return 0;
}4.运行测试
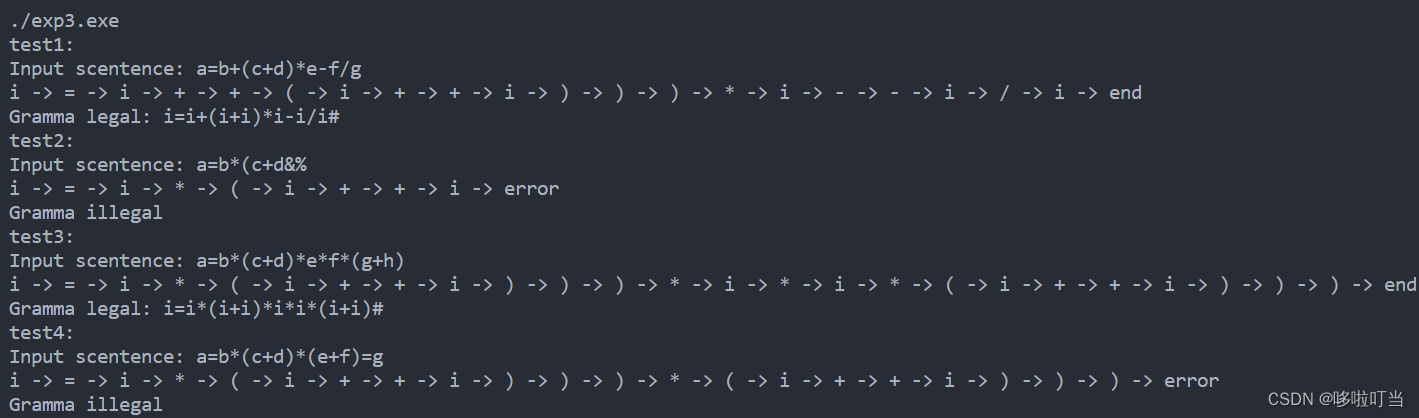


![BUUCTF [BJDCTF2020]纳尼 1](https://img-blog.csdnimg.cn/4992aaab78a749cb82f1e020fe6017aa.png)

![CNVD-2023-12632:泛微E-cology9 browserjsp SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/6b6152d8d9634b3e9e29f8fdddf0f804.png)