目录
一、论文速读
1.1 摘要
1. 2 论文概要总结
二、论文精度
2.1 论文试图解决什么问题?
2.2 论文中提到的解决方案之关键是什么?
2.3 用于定量评估的数据集是什么?代码有没有开源?
2.4 这篇论文到底有什么贡献?
2.5 下一步呢?有什么工作可以继续深入?
一、论文速读
论文arxiv链接
1.1 摘要
视觉问答(VQA)作为一种需要在视觉和语言之间架起桥梁以正确推断答案的多模态任务,已被密集研究。最近的尝试开发了各种基于注意力的模块来解决VQA任务。然而,模型推理的性能在很大程度上受限于用于语义理解的视觉处理。大多数现有的检测方法依赖于边界框,这对VQA模型来说仍然是一个严峻的挑战,即理解图像中物体语义的因果关系并正确推断上下文信息。为此,我们在这项工作中提出了一个不使用边界框的更精细的模型框架,称为“实例外语义观察”(LOIS),以解决这一重要问题。LOIS能够提供更细粒度的特征描述来产生视觉事实。此外,为了克服实例掩码引起的标签模糊问题,我们设计了两种类型的关系注意力模块:1)内模态和2)跨模态,用于从不同多视角特征中推断正确答案。具体来说,我们实现了一个相互关系注意力模块,以模拟实例对象和背景信息之间复杂和深层的视觉语义关系。此外,我们提出的注意力模型还可以通过关注与重要单词相关的问题来进一步分析显著的图像区域。在四个基准VQA数据集上的实验结果证明,我们提出的方法在提高视觉推理能力方面具有良好的性能。
1. 2 论文概要总结
-
相关工作:
论文详细回顾了视觉问答(VQA)的发展,着重分析了特征提取、基于注意力的模型等多种方法。它指出,尽管近年来提出了各种检测方法,但深入理解图像内容和语义背景信息仍是VQA中的一个重大挑战。 -
主要贡献:
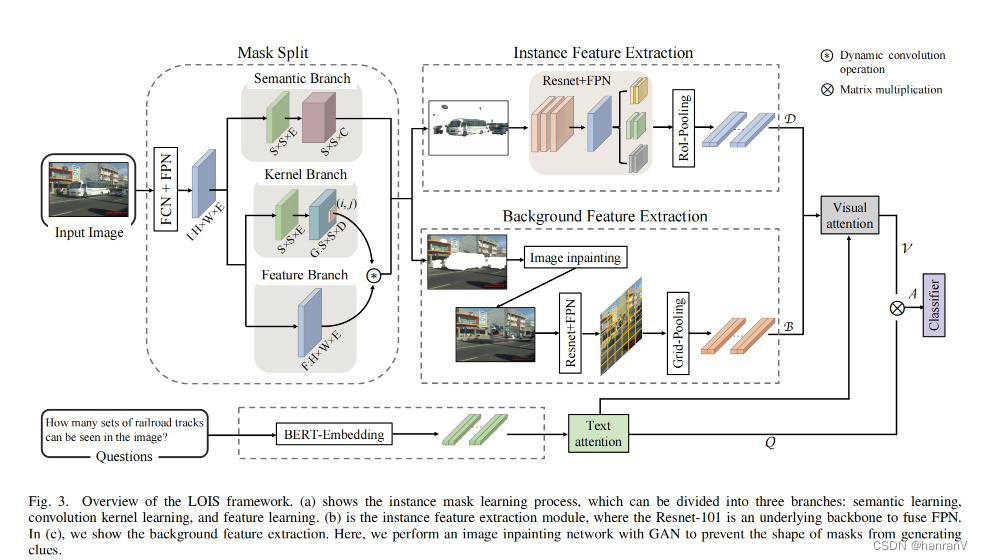
提出了一个新颖的框架“LOIS”,用于视觉问答任务中实例语义的建模。LOIS框架不需要边界框检测,可以提供更细致的边缘特征描述。此外,该框架还通过学习多视角的视觉属性,平衡局部实例和全局背景特征,从而加强对复杂语义关系的推理。
-
论文主要方法:
LOIS框架利用了两种关系注意力模块:内模态和跨模态,来推断从多视角特征中提取的正确答案。它通过相互关系注意力模块来建模实例对象和背景信息之间的复杂视觉语义关系,并进一步分析显著图像区域,聚焦于与重要词汇相关的问题。 -
实验数据:
在四个基准VQA数据集上进行了实验,以评估LOIS的性能。此外,还在数据集上进行了广泛的消融实验,以探索不同超参数的影响,并提供了与当前最先进方法的定性比较。 -
未来研究方向:
论文提出未来将应用LOIS框架于更多VQA场景和任务,并进一步探索图像与问题之间不同的语义关联。
二、论文精度
2.1 论文试图解决什么问题?
旨在解决视觉问答(VQA)任务中的一个核心问题:如何提高对图像中实例语义的理解以准确回答与图像内容相关的问题。具体而言,论文针对的主要问题包括:
-
语义理解的局限性:现有的VQA模型在理解图像中对象的语义关系及其上下文信息方面存在局限。大多数现有检测方法依赖于边界框(bounding boxes),这限制了模型对图像中对象和场景的全面理解。
-
处理边界框带来的挑战:传统的基于边界框的方法在提取对象特征时,可能会丢失重要的边缘细节,导致对实例语义的理解不够精确。
-
跨模态关联问题:VQA任务要求模型能够处理来自不同模态(图像和文本)的信息,并理解这些信息之间的复杂关系。现有方法在融合视觉和语言特征时,可能无法有效捕捉这些复杂的跨模态关系。
为解决这些问题,论文提出了LOIS框架,该框架不依赖于传统的边界框检测,而是通过更细致的像素级处理和关系注意力机制来提升对图像中实例语义的理解,并在此基础上进行准确的答案推理。这样,LOIS能够更好地处理VQA中的语义理解和跨模态关联问题。
2.2 论文中提到的解决方案之关键是什么?
关键解决方案包含以下几个核心部分:
-
像素级实例语义检测:与传统依赖边界框的方法不同,LOIS采用像素级的实例检测,这允许更细致地识别和处理图像中的对象。这种方法不仅减少了对边界框的依赖,还能更精确地捕捉对象的边缘特征,提高对实例语义的理解。
-
关系注意力模块:LOIS框架中包含两种类型的关系注意力模块——内模态(intra-modality)和跨模态(inter-modality)。内模态注意力模块用于加强图像内部不同视觉元素之间的关联,而跨模态注意力模块则用于强化视觉特征和文本问题之间的语义关联。这些注意力机制有助于模型更好地理解和分析图像内容与问题之间的复杂关系。
-
多视角视觉属性的学习:LOIS通过学习多视角的视觉属性,能够在保留局部实例特征的同时,考虑全局背景信息,实现对视觉场景的全面理解。
-
高级交互和推理:通过结合上述技术,LOIS框架能够处理和推理复杂的视觉和语言信息,提供更准确的答案预测。这种高级交互和推理机制是LOIS在VQA任务中取得优异性能的关键。
综上所述,LOIS框架的核心在于它对于实例语义的精确处理能力和复杂跨模态关系的高效推理能力,这使得它在视觉问答任务中表现出色。
2.3 用于定量评估的数据集是什么?代码有没有开源?
使用以下四个基准数据集进行定量评估:
-
VQA v1: 这是一个广泛使用的视觉问答数据集,包含多种类型的问题和答案。
-
VQA v2: 这是VQA v1的扩展版本,旨在通过平衡配对减少数据集偏差。
-
COCO-QA: 由Microsoft COCO数据集创建,相对于VQA v1和VQA v2更小,包含四种类型的问题:对象、数量、颜色和位置。
-
VQA-CP v2 (VQA under Changing Priors): 这个数据集是从VQA v2重组的,旨在通过改变训练和测试集中答案的先验分布来减少问题导向偏差。
关于代码的开源情况,论文中没有明确提到代码是否开源。通常情况下,学术论文的作者可能会在论文发布后的某个时间点将代码开源,或者在其他平台(如GitHub)分享。
2.4 这篇论文到底有什么贡献?
主要贡献可以概括为以下几点:
-
创新的框架:提出了LOIS(Looking Out of Instance Semantics),这是一个新颖的视觉问答(VQA)框架。与传统依赖边界框的方法不同,LOIS采用了像素级的实例语义检测,提高了对图像中实例语义的理解。
-
关系注意力模块:LOIS引入了内模态和跨模态两种类型的关系注意力模块,这些模块能够加强图像内部视觉元素之间以及视觉特征与文本问题之间的语义关联。这种注意力机制的应用提升了模型对复杂语义关系的捕捉能力。
-
多视角视觉属性的有效整合:LOIS通过综合考虑局部实例特征和全局背景信息,能够从多个视角有效地提取视觉属性,进而增强了模型对整体视觉场景的理解。
-
提升VQA性能:通过在四个基准VQA数据集上的实验,论文展示了LOIS框架在捕捉视觉与语言领域之间高层次交互方面的优势,证明了其在视觉问答任务中的有效性。
-
推动研究领域发展:该论文的研究为VQA领域提供了新的视角和方法,可能会激发后续研究在实例语义理解和跨模态关联问题上的进一步探索。
总而言之,主要贡献在于提出了一个创新的框架,该框架通过改进实例语义的检测和处理方式,以及加强视觉和语言信息的整合,从而提升了VQA任务的性能和效果。
2.5 下一步呢?有什么工作可以继续深入?
接下来的研究可以从以下几个方面展开:
-
多样化和更复杂的数据集:尽管LOIS在现有的几个基准数据集上表现出色,但未来的研究可以将其应用于更多样化和复杂的数据集,以验证其适应性和鲁棒性。
-
实时处理和优化:考虑到VQA任务在实际应用中的实时性要求,研究可以集中在优化LOIS框架的计算效率和速度上,使其能够更快速地处理大规模或实时数据。
-
跨模态融合的进一步改进:虽然LOIS已经应用了内模态和跨模态的关系注意力模块,但仍有空间进一步改进这些机制,特别是在处理更复杂或更微妙的跨模态关系时。
-
其他视觉问答场景的应用:将LOIS应用于不同类型的VQA场景,如医学图像分析、监控视频解读等,探索其在特定应用中的表现和适用性。
-
可解释性和透明度:增强模型的可解释性,使其推理过程更加透明和可理解,这对于增强用户信任和满足某些应用领域的需求至关重要。
-
集成最新的AI技术:考虑集成最新的人工智能技术,如GPT-3、BERT等先进的自然语言处理模型,以及最新的计算机视觉技术,来进一步提升模型的性能。
-
长期和持久的学习:研究模型在长期和持久的学习环境下的表现,特别是在不断变化的数据环境中适应和学习的能力。