Django的主要目的是简便、快速的开发数据库驱动的网站。它强调代码复用,多个组件可以很方便的以"插件"形式服务于整个框架,Django有许多功能强大的第三方插件,你甚至可以很方便的开发出自己的工具包。这使得Django具有很强的可扩展性。它还强调快速开发和DRY(DoNotRepeatYourself)原则
Django全套笔记直接地址: 请移步这里
共 4 章,47 子模块


数据库操作-查询
查询集QuerySet
1 概念
Django的ORM中存在查询集的概念。
查询集,也称查询结果集、QuerySet,表示从数据库中的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
对查询集可以再次调用过滤器进行过滤,如
>>> books = BookInfo.objects.filter(readcount__gt=30).order_by('pub_date')
>>> books
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。
从SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by子句。
判断某一个查询集中是否有数据:
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
2 两大特性
1)惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集books
books = BookInfo.objects.all()
继续执行遍历迭代操作后,才真正的进行了数据库的查询
for book in books:print(book.name)
2)缓存
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
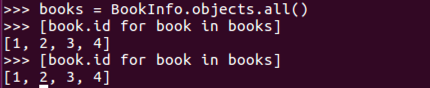
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from book.models import BookInfo[book.id for book in BookInfo.objects.all()][book.id for book in BookInfo.objects.all()]


情况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。
books=BookInfo.objects.all()[book.id for book in books][book.id for book in books]

3 限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:第1、2项,运行查看。
>>> books = BookInfo.objects.all()[0:2]
>>> books
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>
4.分页
文档
#查询数据books = BookInfo.objects.all()#导入分页类from django.core.paginator import Paginator#创建分页实例paginator=Paginator(books,2)#指定页码的数据page_skus = paginator.page(1)#分页数据total_page=paginator.num_pages
视图
重点
-
HttpRequest
- 位置参数和关键字参数
- 查询字符串
- 请求体:表单数据,JSON数据
- 请求头
-
HttpResponse
-
HttpResponse
-
JsonResponse
-
redirect
-
-
类视图
-
类视图的定义和使用
-
类视图装饰器(难点)
-
视图介绍和项目准备

视图介绍
-
视图就是
应用中views.py文件中的函数 -
视图的第一个参数必须为
HttpRequest对象,还可能包含下参数如- 通过正则表达式组的位置参数
- 通过正则表达式组获得的关键字参数
-
视图必须返回一个
HttpResponse对象或子对象作为响应- 子对象:
JsonResponseHttpResponseRedirect
- 子对象:
-
视图负责接受Web请求
HttpRequest,进行逻辑处理,返回Web响应HttpResponse给请求者- 响应内容可以是
HTML内容,404错误,重定向,json数据…
- 响应内容可以是
-
视图处理过程如下图:

使用视图时需要进行两步操作,两步操作不分先后
- 配置
URLconf - 在
应用/views.py中定义视图
项目准备
-
创建项目+创建应用+安装应用+配置模板路径+本地化+mysql数据库+URLconf+视图
-
mysql数据库使用之前的book
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','HOST': '127.0.0.1', # 数据库主机'PORT': 3306, # 数据库端口'USER': 'root', # 数据库用户名'PASSWORD': 'mysql', # 数据库用户密码'NAME': 'book' # 数据库名字}
}
-
URLconf
settings.py中:指定url配置
ROOT_URLCONF = 'bookmanager.urls'- 项目中
urls.py:只要不是admin/就匹配成功,包含到应用中的urls.py
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
url(r’^admin/', include(admin.site.urls)),
# 只要不是‘admin/’就匹配成功,包含到应用中的urls.pyurl(r'^', include('book.urls')),
]
* 应用中`urls.py`:匹配`testproject/`成功就调用`views`中的`testproject`函数,测试项目逻辑```python
from django.conf.urls import url
import viewsurlpatterns = [# 匹配`testproject/`成功就调用`views`中的`testproject`函数url(r'^testproject/$', views.testproject),
]
- 视图:测试项目逻辑
from django.http import HttpResponse# 测试项目逻辑def testproject(request):return HttpResponse('测试项目逻辑')
- 在models.py 文件中定义模型类
from django.db import models# Create your models here.# 准备书籍列表信息的模型类class BookInfo(models.Model):# 创建字段,字段类型...name = models.CharField(max_length=20, verbose_name='名称')pub_date = models.DateField(verbose_name='发布日期',null=True)readcount = models.IntegerField(default=0, verbose_name='阅读量')commentcount = models.IntegerField(default=0, verbose_name='评论量')is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')class Meta:db_table = 'bookinfo' # 指明数据库表名verbose_name = '图书' # 在admin站点中显示的名称def __str__(self):"""定义每个数据对象的显示信息"""return self.name# 准备人物列表信息的模型类class PeopleInfo(models.Model):GENDER_CHOICES = ((0, 'male'),(1, 'female'))name = models.CharField(max_length=20, verbose_name='名称')gender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别')description = models.CharField(max_length=200, null=True, verbose_name='描述信息')book = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='图书') # 外键is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')class Meta:db_table = 'peopleinfo'verbose_name = '人物信息'def __str__(self):return self.name
1**)生成迁移文件**
python manage.py makemigrations
2)同步到数据库中
python manage.py migrate
3**)添加测试数据**
insert into bookinfo(name, pub_date, readcount,commentcount, is_delete) values
('射雕英雄传', '1980-5-1', 12, 34, 0),
('天龙八部', '1986-7-24', 36, 40, 0),
('笑傲江湖', '1995-12-24', 20, 80, 0),
('雪山飞狐', '1987-11-11', 58, 24, 0);
insert into peopleinfo(name, gender, book_id, description, is_delete) values('郭靖', 1, 1, '降龙十八掌', 0),('黄蓉', 0, 1, '打狗棍法', 0),('黄药师', 1, 1, '弹指神通', 0),('欧阳锋', 1, 1, '蛤蟆功', 0),('梅超风', 0, 1, '九阴白骨爪', 0),('乔峰', 1, 2, '降龙十八掌', 0),('段誉', 1, 2, '六脉神剑', 0),('虚竹', 1, 2, '天山六阳掌', 0),('王语嫣', 0, 2, '神仙姐姐', 0),('令狐冲', 1, 3, '独孤九剑', 0),('任盈盈', 0, 3, '弹琴', 0),('岳不群', 1, 3, '华山剑法', 0),('东方不败', 0, 3, '葵花宝典', 0),('胡斐', 1, 4, '胡家刀法', 0),('苗若兰', 0, 4, '黄衣', 0),('程灵素', 0, 4, '医术', 0),('袁紫衣', 0, 4, '六合拳', 0);
URLconf
- 浏览者通过在浏览器的地址栏中输入网址请求网站
- 对于Django开发的网站,由哪一个视图进行处理请求,是由url匹配找到的
配置URLconf
-
1.
settings.py中- 指定url配置
ROOT_URLCONF = '项目.urls' -
2.项目中
urls.py- 匹配成功后,包含到应用的
urls.py
url(正则, include('应用.urls')) - 匹配成功后,包含到应用的
-
3.应用中
urls.py- 匹配成功后,调用
views.py对应的函数
url(正则, views.函数名) - 匹配成功后,调用
-
4.提示
1. 正则部分推荐使用 r,表示字符串不转义,这样在正则表达式中使用 \ 只写一个就可以2. 不能在开始加反斜杠,推荐在结束加反斜杠正确:path/正确:path错误:/path错误:/path/3. 请求的url被看做是一个普通的python字符串,进行匹配时不包括域名、get或post参数3.1 如请求地址如下:http://127.0.0.1:8000/18/?a=103.2 去掉域名和参数部分后,只剩下如下部分与正则匹配18/
说明:
虽然路由结尾带/能带来上述好处,但是却违背了HTTP中URL表示资源位置路径的设计理念。
是否结尾带/以所属公司定义风格为准。
路由命名与reverse反解析(逆向)
1 路由命名
在定义路由的时候,可以为路由命名,方便查找特定视图的具体路径信息。
- 在使用include函数定义路由时,可以使用namespace参数定义路由的命名空间,如
url(r'^',include('book.urls',namespace='book'))
命名空间表示,凡是book.urls中定义的路由,均属于namespace指明的book名下。
命名空间的作用:避免不同应用中的路由使用了相同的名字发生冲突,使用命名空间区别开。
- 在定义普通路由时,可以使用name参数指明路由的名字,如
urlpatterns = [url(r'^$',index),# 匹配书籍列表信息的URL,调用对应的bookList视图url(r'^booklist/$',bookList,name='index'),url(r'^testproject/$',views.testproject,name='test'),
]
2 reverse反解析
使用reverse函数,可以根据路由名称,返回具体的路径,如:
from django.core.urlresolvers import reverse#或者from django.urls import reversedef testproject(request):return HttpResponse("OK")# 定义视图:提供书籍列表信息def bookList(request):url = reverse('book:test')print(url)return HttpResponse('index')
- 对于未指明namespace的,reverse(路由name)
- 对于指明namespace的,reverse(命名空间namespace:路由name)
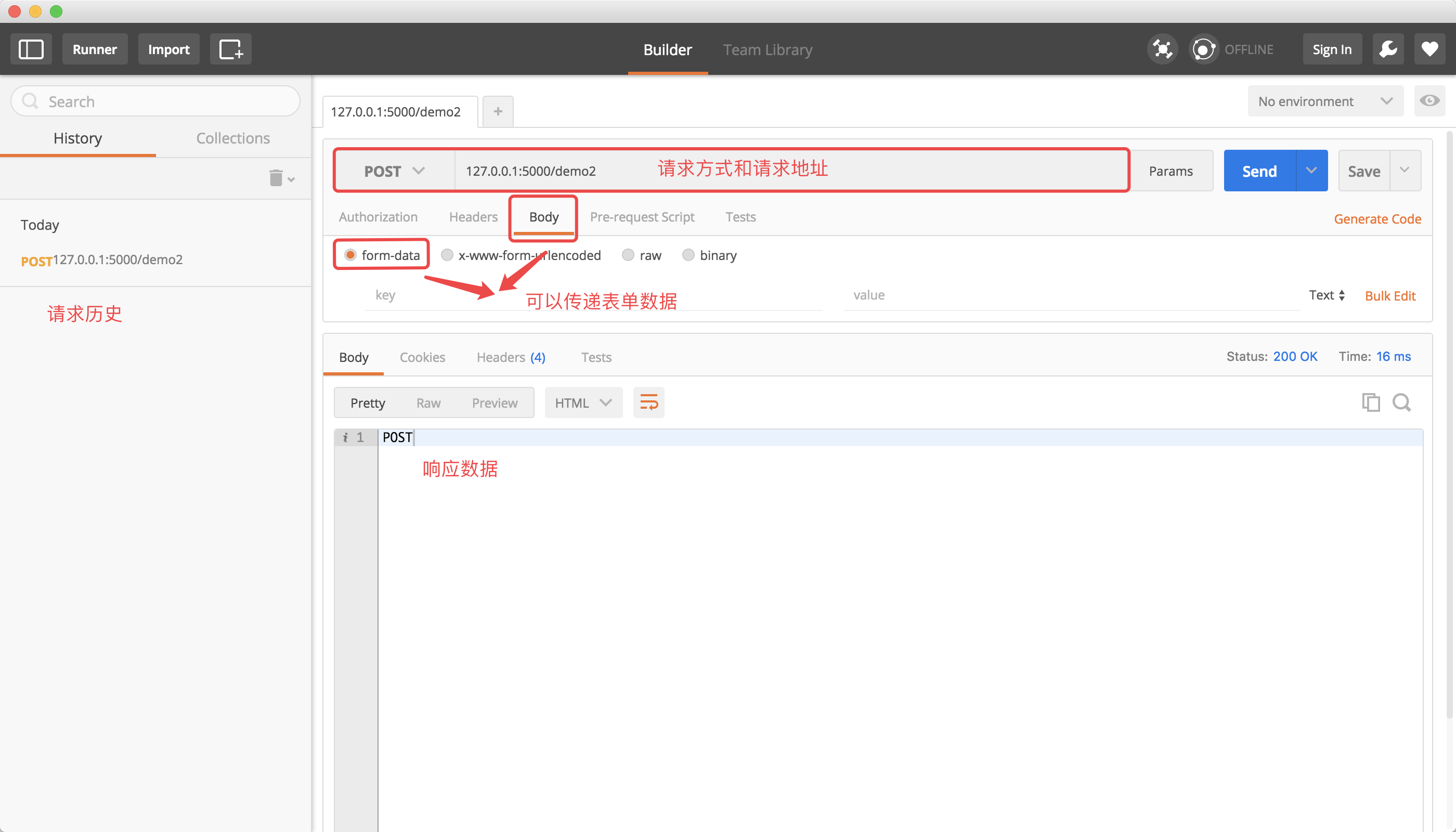
使用 PostMan 对请求进行测试
PostMan 是一款功能强大的网页调试与发送网页 HTTP 请求的 Chrome 插件,可以直接去对我们写出来的路由和视图函数进行调试,作为后端程序员是必须要知道的一个工具。
-
安装方式1:去 Chrome 商店直接搜索 PostMan 扩展程序进行安装
-
安装方式2:https://www.getpostman.com/官网下载桌面版
-
安装方式3:将已下载好的 PostMan 插件文件夹拖入到浏览器
-
打开 Chrome 的扩展程序页面,打开
开发者模式选项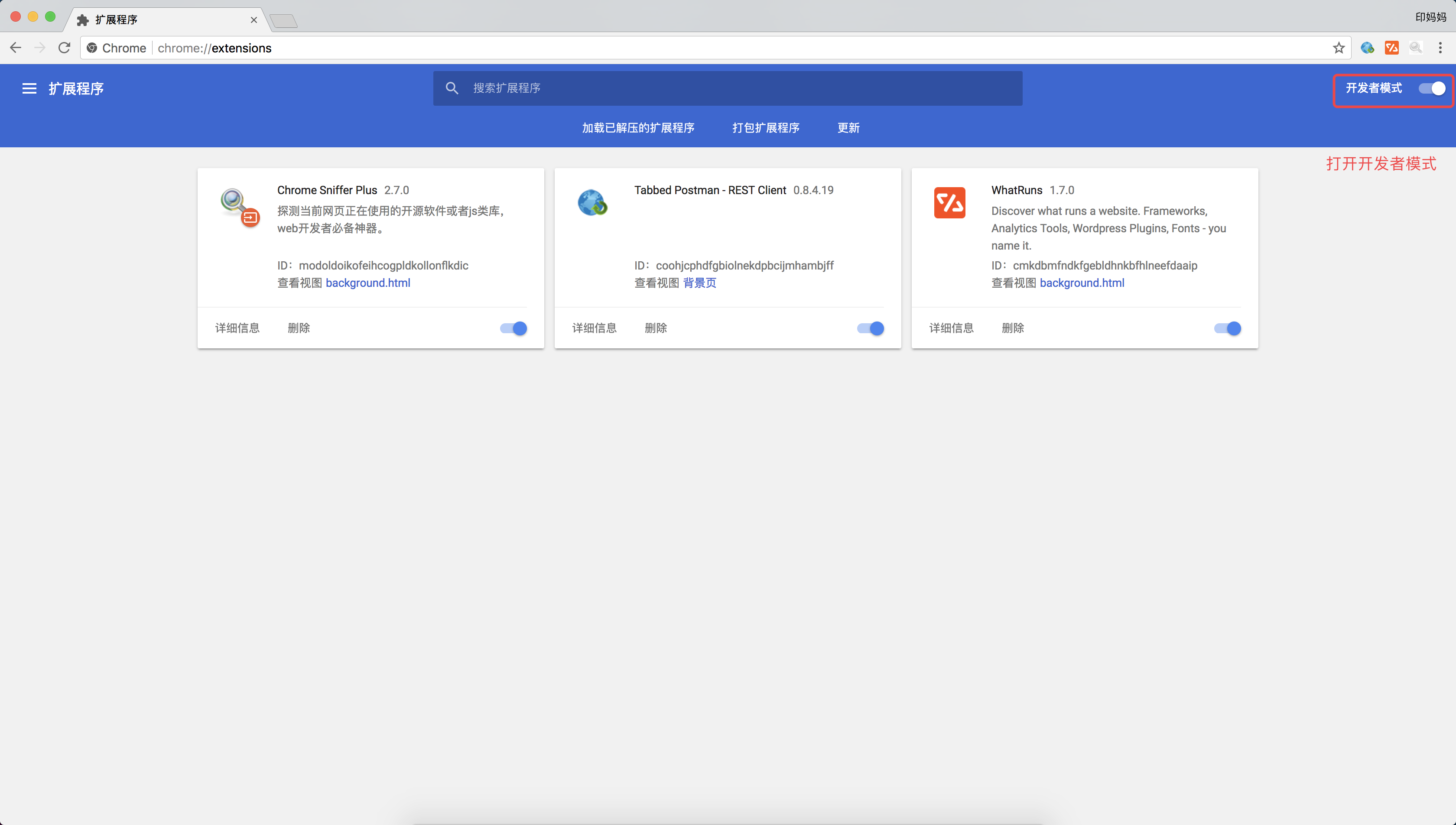
-
将插件文件夹拖入到浏览器(或者点击加载已解压的扩展程序选择文件夹)
- 在 Mac 下生成桌面图标,可以点击启动
- 在 ubuntu 旧版的 Chrome 浏览器中会显示以下效果,可以直接点击启动

-
-
使用 PostMan,打开之后,会弹出注册页面,选择下方的
Skip this,go straight to the app进行程序