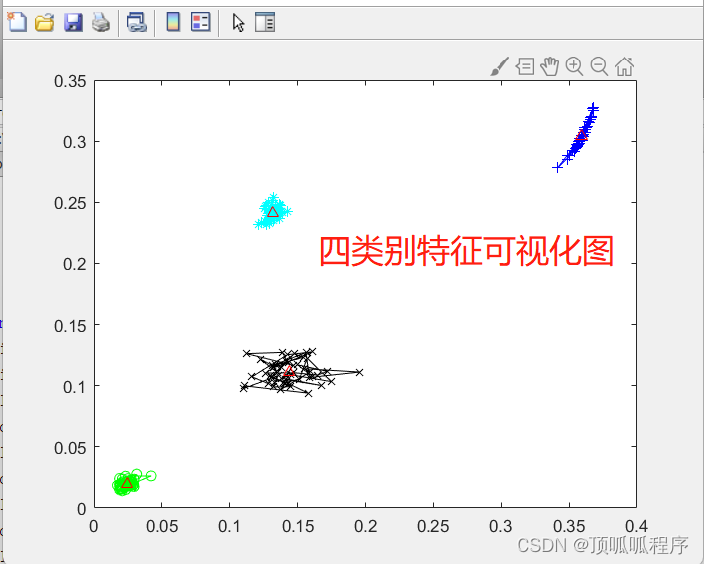
前言:
下午的题目一般有6道题目,前4题是必答题,第5题和第6题二选一。每题15分,一共75分,45分即可通过。
接下来,我们以2022下半年软件设计师案例来当作教材来讲,下午的每种类型的题目该如何去解决。
一.数据流图解析
题目
【说明】
随着新能源车数量的迅猛增长,全国各地电动汽车配套充电桩急速增长,同时也带来了充 电桩计量准确性的问题。充电桩都需要配备相应的电能计量和电费计费功能,需要对充电计量准确性强制进行检定。现需开发计量检定云端软件,其主要功能是:
(1)数据接收。接收计量装置上报的充电数据,即充电过程中电压、电流、电能等充电监测 数据和计量数据(充电监测数据为充电桩监测的数据,计量数据为计量装置计量的数据,以 秒为间隔单位),接收计量装置心跳数据,并分别进行存储。
(2)基础数据维护。管理员对充电桩、计量检定装置等基础数据进行维护。
(3)数据分析。实现电压、电流、电能数据的对比,进行误差分析,记录充电桩的充电误差, 供计量装置检定。系统根据计量检测人员给出的查询和统计条件展示查询统计结果。
(4)充电桩检定。分析充电误差:计量检测人员根据误差分析结果和检定信息记录,对充电桩进行检定,提交检定结果:系统更新充电桩中的检定信息(检定结果和检定时间),并存 储于检定记录。
(5)异常告警。检测计量装置心跳,当心跳停止时,向管理员发出告警。
(6)检定信息获取,供其它与充电桩相关的第三方服务查询充电桩中的检定信息。 现采用结构化方法对计量检定云端软件进行分析与设计,获得如图 1-1 所示的上下文数据 流图和图 1-2 所示的 0 层数据流图。


【问题 1】(4 分)
使用说明中的词语,给出图 1-1 中的实体 E1~E4 的名称。
【问题 2】(5 分)
使用说明中的词语,给出图 1-2 中的数据存储 D1~D5 的名称。
【问题 3】(4 分)
根据说明中的词语,补充图 1-2 中缺失的数据流及其起点和终点。
【问题 4】(2 分) 根据说明,给出“充电监测与计量数据”数据流的组成。
解析:
问题1(4 分)
问:使用说明中的词语,给出图 1-1 中的实体 E1~E4 的名称。
解析数据流的题,首先先看问题1中E对应的民称,然后在回头看题目,前两道题一般都是比较简单的。E的名称,我们可以带着几个疑问去回头阅读描述:


E1的话,我们可以带着以下几个疑问从描述中查找
1.心跳数据由谁上报?
2.计量数据由谁上报?
则很容易得出E1:计量装置。
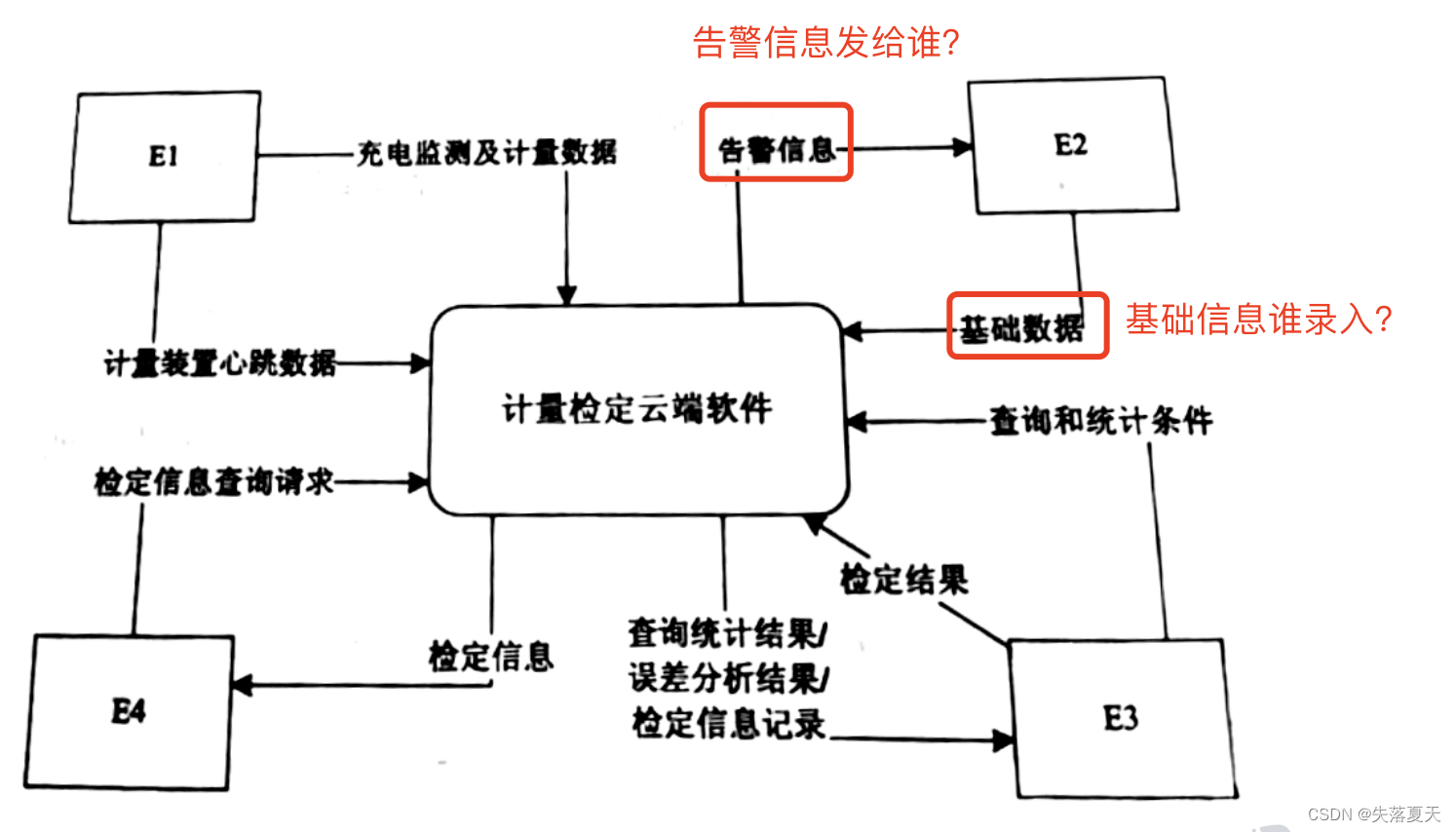
E2的话,我们可以带着以下几个疑问从描述中查找
1.告警信息通知给谁?
2.谁录入的基础数据?
则很容易得出E2:管理员。

E3的话,我们可以带着以下几个疑问从描述中查找
1.谁向系统提交的查询和统计条件?
2.检定信息记录发给了谁?
3.谁提交的检定结果?
则很容易得出E3:计量检测人员。
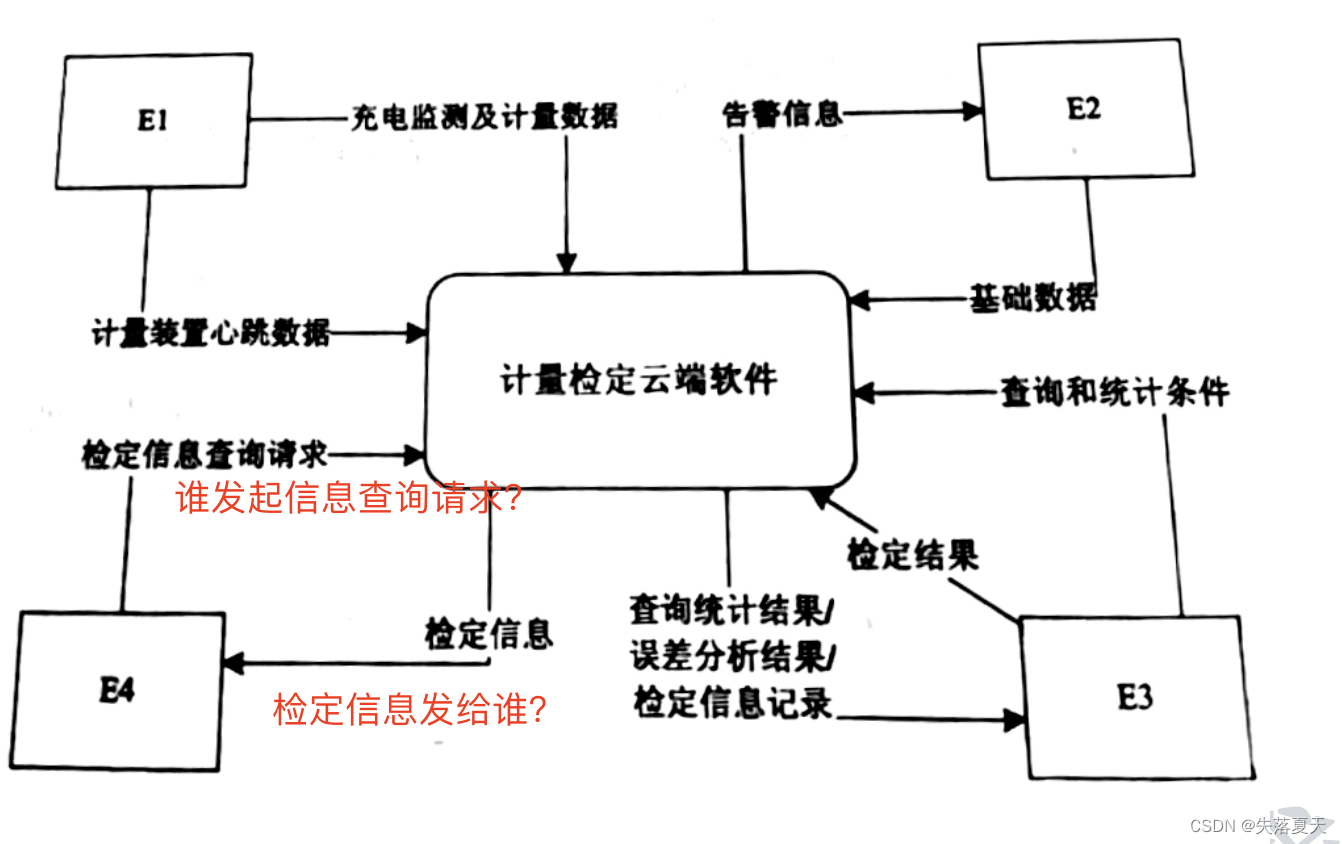
E4的话,我们可以带着以下几个疑问从描述中查找
1.谁发起信息查询请求?
2.检定信息返回给谁?
则很容易得出E4:第三方服务。
问题2(5 分)
问:使用说明中的词语,给出图 1-2 中的数据存储 D1~D5 的名称。
问题2是最简单的,如果输入和输出一样,则表就是输入量+表。只有只有输入或者只有输出,则使用输入+表活着输出+表,而且这里基本上就意味着缺少数据流。
D1输入的是充电检测及计量数据,输出也是一样的,则表就一定是充电检测及计量数据表。
D2输入的是基础信息,没有输出,则表就一定是基础信息表。这里缺少一个D2输出的数据流。
D3输入的是计量装置心跳数据,输出是心跳数据,则表就是心跳数据表。
D4输入的是充电误差信息,输出是充电误差,则表就一定是充电误差表。
D5输入没有,输出是检定记录,则表就一定是检定记录表。这里缺少一个D5输入的数据流。
问题3(4 分)
问:根据说明中的词语,补充图 1-2 中缺失的数据流及其起点和终点。
一般来说,问题3是最难的。这里总结一下,数据流一般来说,都是E,D和P进行的交互,E和D一般不会直接交互。接下来,就是如何发现缺失的数据流,一般有三条规律,分享给大家。
规律1:XX表,一般输入和输出是成对存在的,如果缺少输入或者输出,那么就意味着很有可能少了一条数据流。

规律2:P中输入和输出的数据流,一般是成对存在的。如果输入项中有,输出项中没有,那么也就意味着少了一条数据流。

规律3:P操作一般都依赖数据表,比如依赖数据表计算,活着把输入数据存储到数据表。

根据上面的规律1,可以发现D2没有输出,D5没有输出。
那么谁需要基础信息?我们可以推理得知是数据分析的时候,则缺少数据流D2->P4,基础信息。
同样谁录入记录?我们可以从描述中得知是充电桩检定的时候,则缺少数据流P4->D5,检定记录。
根据上面的规律2,可以发现P3输入一条,输出有两条,则少了一条。
查询统计结果谁发起的?自然是计量检测人员,则缺少数据流:E3->P3,查询和统计条件。
根据上面的规律3,可以发现P6没有依赖或者存储到任何数据表,也是有问题的。
根据描述,发现缺少数据流:D5->P6,检定记录。
当然,肯定还有一些其它的数据流,但是比较难找,这里就不一一列举了。
【问题 4】(2 分)
根据说明,给出“充电监测与计量数据”数据流的组成。
问题4的范围就不固定了,一般问的范围是比较广的。
这个题是很简单的,直接从描述中所有充电监测与计量数据,发现如下的描述:

则我们直接拷贝即可,答案:
充电过程中电压、电流、电能等充电监测 数据和计量数据(充电监测数据为充电桩监测的数据,计量数据为计量装置计量的数据,以 秒为间隔单位),接收计量装置心跳数据,并分别进行存储。
二.数据库设计之概念结构设计解析
题目
【说明】 某营销公司为了便于对各地的分公司及专卖店进行管理,拟开发一套业务管理系统,请根 据下述需求描述完成该系统的数据库设计。
【需求描述】
(1) 分公司信息包括:分公司编号、分公司名、地址和电话。其中,分公司编号唯一确定分公司关系的每一个元组。每个分公司拥有多家专卖店,每家专卖店只属于一个分公司。
(2) 专卖店信息包括:专卖店号、专卖店名、店长、分公司编号、地址、电话,其中店号 唯一确定专卖店关系中的每一个元组。每家专卖店只有一名店长,负责专卖店的各项业务: 每名店长只负责一家专卖店:每家专卖店有多名职员,每名职员只属于一家专卖店。
(3)职员信息包括:职员号、职员名、专卖店号、岗位、电话、薪资。其中,职员号唯一标 识职员关系中的每一个元组。岗位有店长、营业员等。
【概念模型设计】
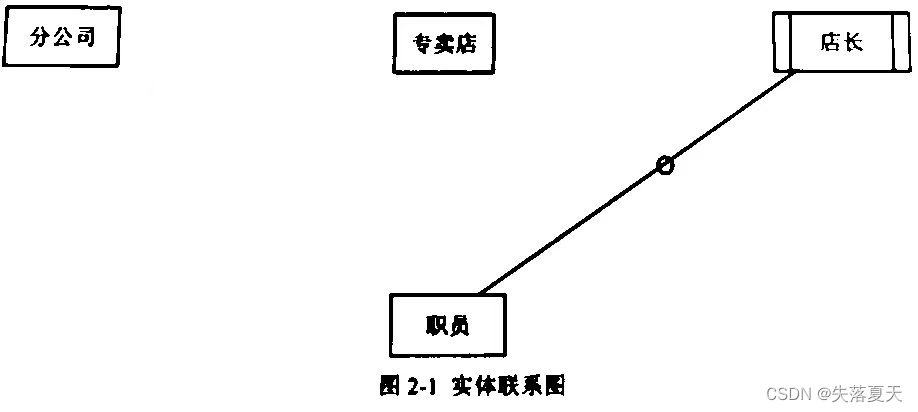
根据需求阶段收集的信息,设计的实体联系图(不完整)如图 2-1 所示。
【逻辑结构设计】
根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整):分公司(分公司编号,分公司名,地址,电话) 专卖店(专卖店号,专卖店名,___(a)__,职员,地址,电话) 职员(职员号,职员名,____(b)___,岗位,电话,薪资)
【问题 1】(6 分)
根据需求描述,图 2-1 实体联系图中缺少三个联系。请在答题纸对应的实体联系图中补充 三个联系及联系类型。
注:联系名可用联系 1、联系 2、联系 3:也可根据你对题意的理解取联系名。
【问题 2】(6 分)
(1)将关系校式中的____(a)___、____(b)___的属性补充完整,并填入答题纸对应的位置 上。
(2)专卖店关系的主键:____(c)___ 和外键:____(d)___。
职员关系的主键:____(e)___ 和外键:____(f)___。
【问题 3】(3 分)
为了在紧急情况发生时,能及时联系到职员的家人,专卖店要求每位职员至少要填写位紧 急联系人的姓名、与本人关系和联系电话。根把这种情况,在用 2-1 中还需来机的实体 ___(g)___,职员关系与该实体的联系类型为____(h)___。
(3)给出该实体的关系模式。
解析:
【问题 1】(6 分)
根据需求描述,图 2-1 实体联系图中缺少三个联系。请在答题纸对应的实体联系图中补充 三个联系及联系类型。
注:联系名可用联系 1、联系 2、联系 3:也可根据你对题意的理解取联系名。
找关联关系,就要仔细阅读需求描述,然后从需求描述中寻找关联关系,尤其要关注多对多的对应,比如描述中的:

则根据描述一共有3个关系:
分公司和专卖店的关系,分公司1:专卖店N;
专卖店和店长的关系,专卖店1:店长1;
专卖店和职员的关系,专卖店1:职员N。
【问题 2】(6 分)
(1)将关系校式中的____(a)___、____(b)___的属性补充完整,并填入答题纸对应的位置 上。
(2)专卖店关系的主键:____(c)___ 和外键:____(d)___。
职员关系的主键:____(e)___ 和外键:____(f)___。
a和b直接从描述中搜索,很容易就能得到答案。


a为:店长,分公司编号
b为:专卖店号
专卖店信息中,主键是确定唯一关系的,看是否可以通过主键确定唯一性,则专卖店号就是主键,c:专卖店号。
外键是关联其它表信息的,看有哪些字段可以关联到其它表中。则店长,分公司编号都是可以关联其它表,则为外键,d:店长,分公司编号。
同样的,职员关系的主键就是职员号,e:职员号。外键专卖店号,f:专卖店号。
【问题 3】(3 分)
为了在紧急情况发生时,能及时联系到职员的家人,专卖店要求每位职员至少要填写1位紧急联系人的姓名、与本人关系和联系电话。根把这种情况,在用 2-1 中还需来添加实体 ___(g)___,职员关系与该实体的联系类型为____(h)___。
(3)给出该实体的关系模式。
添加实体:g:紧急联系人;
至少填写1位紧急联系人,则就是N。所以职员1:紧急联系人N。
关系模式:
紧急联系人(紧急联系人编号,职员号,紧急联系人姓名,与本人关系,联系电话)
三.面向对象类图设计
题目
【说明】
图 3-1 所示为某软件系统中一个温度控制模块的界面。界面上提供了两种温度计量单位, 即华氏度(Farechet)和摄氏度(Celsius)。软件支持两种计量单位之间的自动换算,即若输 入一个华氏度的温度,其对应的摄氏度温度值会自动出现在摄氏度的显示框内,反之亦然。 用户可以通过该界面上的按钮 Raise (升高温度)和 Lower (降低温度)来改变温度的值。界 面右侧是个温度计,将数字形式的温度转换成温度计上的制度比例进行显示。当温度值改 变时,温度计的显示也随之同步变化。

现在采用面向对象方法现实该温度控制模板,得到如图 3-2 所示的用例图和 3-3 所示的类 图。

【问题 1】(4 分)
根据说明中的描述,给出图 3.2 中 U1~U4 所对应的用例名。
【问题 2】(8 分)
根据说明中的描述,给出图 3-3 中 C1~C8 所对应的类名(类名使用图 3-1 中标注的词汇)。
【问题 3】(3 分)
现需将图 3-1 所示的界面改造为个更为通用的 GUI 应用,能够实现任意计量单位之间的换 算,例如千克和确之间的模算、厘米和英寸之间的换算等等。为了实现这个新的需求,可 以在图 3-3 所示的类图上增加哪种设计模式?请解释选择该设计模式的原因(不超过 50 字)。
解析:
【问题 1】(4 分)
这里我们首先看U2下面的显示摄氏度,与其对应的就是显示华氏度,所以U2就是显示华氏度。因为U1就是显示温度。显示温度通过描述可以得知有三种,所以U3就是温度计显示。U1和U2除了显示温度的共同点,另外一个共同点就是相互的转换了,所以U4就是自动换算。
| 名称 | 用例名 |
| U1 | 显示温度 |
| U2 | 显示华氏度 |
| U3 | 温度计显示 |
| U4 | 自动换算 |
【问题 2】(8 分)
首先看到Button,其属于Widget,且和C2,C3,C4同一级别。则C2到C4肯定也属于Widget,从图中可以看到,除了按钮,还有温度计的Bar,编辑框EditBox,以及编辑框上面的描述Text。
然后,我们看到C5到C8都属于Button的扩展类型,则对应图中寻找有多少种Button即可。RahrenheiRaise,RahrenheiLower,CelsiusRaise,CelsiusLower。
确定了C2到C8之后,我们发现都指向C1,那么只有TemperatureCovertorDialog能够装载所有的Widget从而产生关联。
| 参数名 | 类名 | |
| C1 | TemperatureCovertorDialog | |
| C2 | Bar | |
| C3 | EditBox | |
| C4 | Text | |
| C5 | RahrenheiRaise | |
| C6 | RahrenheiLower | |
| C7 | CelsiusRaise | |
| C8 | CelsiusLower |
【问题 3】(3 分)
这道题问的就比较专业了,对于设计模式不太熟悉的同学可以战略性放弃。
但是如果软考题做多了,就可以知道这属于策略模式,这个就没有什么可讲的了,主要靠积累。
策略模式(Strategy Pattern)属于对象的行为模式。其用意是针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。
四.算法填空题
题目
阅读下列说明和 C 代码,回答问题 1 至问题 3,将解答填入答题纸的对应栏内。
【说明】 试题排序是将一组无序的数据元素调整为非递减顺序的数据序列的过程,堆排序是一种常 用的排序算法。用顺序存储结构存储堆中元素。非递减堆排序的步骤是:
(1)将含 n 个元素的待排序数列构造成一个初始大顶堆,存储在数组 R(R[1],R[2],..., R[n])中。此时堆的规模为 n,堆顶元素 R[1]就是序列中最大的元素,R[n]是堆中最后一个 元素。
(2)将堆顶元素和堆中最后一个元素交换,最后一个元素脱离堆结构,堆的规模减 1,将堆 中剩余的元素调整成大顶堆; (3)重复步骤(2),直到只剩下最后一个元素在堆结构中,此时数组 R 是一个非递减的数据 序列。
【C 代码】
下面是该算法的 C 语言实现。
(1)主要变量说明
n:待排序的数组长度
R[]:待排序数组,n 个数放在 R[1],R[2],...,R[n]中
(2)代码
#include <stdio.h>
#define MAXITEM 100
/**
调整堆
R:待排序数组:
v:节点编号,以v为根的二叉树,R[v]≥R[2v],R[v]≥R[2v+1],且其左子树和右广树都是大顶堆:
n; 堆结构的规模,即堆中的元素数
*/
void Heapify(int R[MAXITEM], int v, int n)
{int i, j;i = v;j = 2 * i;R[0] = R[i];while (i <= n){if (j < n && R[j] < R[j + 1]){j++;}if ((1)){R[i] = R[j];i = j;j = 2 * i;}else{j = n + 1;}}R[i] = R[0];
}/*堆挂序,R为待排序数组:n为数组大小*/
void HeapSort(int R[MAXITEM], int n)
{int i;for (i = n / 2; i >= 1; i--){// (2)}for (i = n; (3); i--){R[0] = R[i];R[i] = R[1];// (4)Heapify(R, 1, i - 1);}
}【问题 1】(8 分)
根据以上说明和 C 代码,填充 C 代码中的空(1)~(4)。
【问题 2】(2 分)
根据以上说明和 C 代码,算法的时间复杂度为(5)(用 O 符号表示)。
【问题 3】(5 分)
考虑数据序列 R=(7,10,13,15,4,20,19,8),n=8,则构建的初始大顶堆为(6), 第一个元素脱离堆结构,对剩余元素再调整成大顶堆后的数组 R 为(7)。
解析:
算法题,往往是下午题里面最难的,有时候我们甚至很难具体简单的描述,理解出题者想表达的意思。但是做题的过程中,往往也是有一些小窍门的。我们以这题为例,我们不去弄懂是怎么实现的,也不了解什么是大顶堆,而尝试去解答这个题。
【问题 1】(8 分)
首先,我们先分析下代码。HeapSort应该是排序方法并且其调用了Heapify,所以Heapify应该是某一次的排序。排序的时候是Heapify(R, 1, i - 1);从1开始的,0并没有用到,所以R[0]应该是用于数据交换的位置。
(1)我们先跳过,先看(2)。(2)只有一行,所以应该是数据赋值或者方法调用。但是下面有不断的i--进行排序,所以这里应该不涉及到赋值,所以应该是初始化一类的操作。怎么初始化呢?肯定是通过若干次的排序进行的,所以这里一定是调用Heapify方法,接下来就是参数的问题。参考下面的Heapify调用,第一个参数就是R,第二个参数应该是i,因为这里的循环是不断向前的,所以我们每次排序只要保证i到N是排序好的即可。所以(2):Heapify(R, i, n);
在看(3),i=n,i--,那么(3)是结束的判断条件,所以(3)应该是i>X。那么X应该是多少呢?还剩下1个的时候自然不需要排序,所以这里就是(3):i>=1。
在看(4),上面R[0] = R[i];和R[i] = R[1];所以这里应该是一个数据交换。结合上面说的R[0]是用于暂存数据的,那么最后一定是把R[0]赋值给某一个位置,结合R[i]=R[1]把第1位进行了赋值,所以这里就是(4):R[1]=R[0]。
再回头看(1),如果想回答这一题,就得对大顶堆有一定的了解了。Heapify方法其实就是在构建一个大顶堆。(1)是一个条件判断,结合下面的赋值,所以这里应该是R[i]>R[j]或者R[j]>R[i]一类的判断。大顶堆,我们认为大的值在上面,换而言之,在前面,所以如果需要交换,那么应该是大的值再后面才需要赋值交换。因此这里应该是(1):R[j]>R[i]。
以上答案是我在不了解推排序和大顶堆的情况下推测的,最终答案并不一定是完全正确的。
【问题 2】(2 分)
算法复杂度的话看代码,HeapSort进行了一个N级别的循环,所以这里至少为N了。然后在看Heapify方法,这里面有一个while循环,但是是j=2*i的进度向前,所以复杂度应该是logN。
因为复杂度就是O(N*logN)。
【问题 3】(5 分)
这题如果不会堆排序,就真的没办法了。
(6):20,15,19,10,4,13,7,8
(7):19,15,13,10,4,8,7,20
五.面向对象程序设计
题目
阅读下列说明和 Java 代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
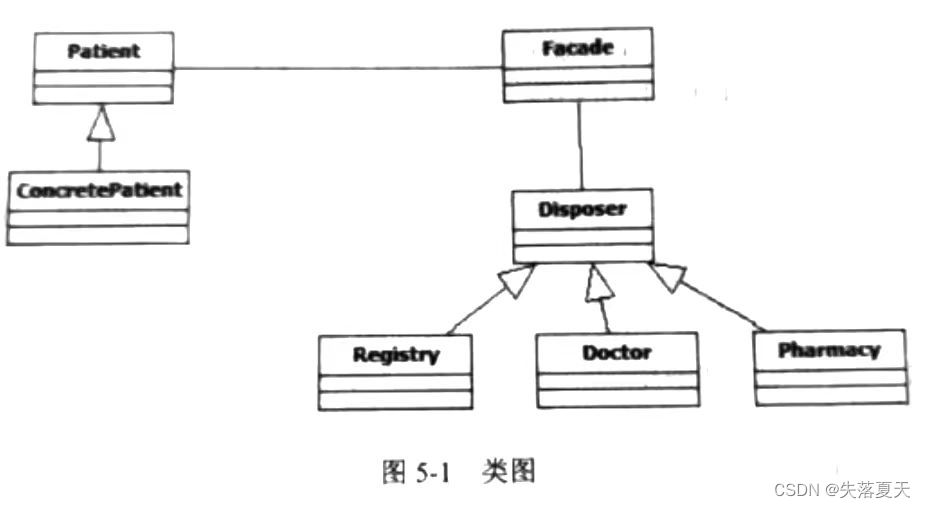
Facade(外观)模式是一种通过为多个复杂子系统提供一个一致的接口,而使这些子系统更 加容易被访问的模式。以医院为例,就医时患者需要与医院不同的职能部门交互,完成挂 号、门诊、取药等操作。为简化就医流程,设置了一个接待员的职位,代患者完成上述就 医步骤,患者则只需与接待员交互即可。如 5-1 给出了以外观模式实现该场景的类图。
【代码】
import java.util.*;interface Patient {___(1)___;
}interface Disposer {___(2)___;
}class Registry implements Disposer {public void dispose(Patient patient) {System.out.println("I am registering..." + patient.getName());}
}class Doctor implements Disposer {public void dispose(Patient patient) {System.out.println("I am diagnosing..." + patient.getName());}
}class Pharmacy implements Disposer {public void dispose(Patient patient) {System.out.println("I am giving medicine..." + patient.getName());}
}class Facade {private Patient patient;public Facade(Patient patient) {this.patient = patient;}public void dispose() {Registry registry = new Registry();Doctor doctor = new Doctor();Pharmacy ph = new Pharmacy();registry.dispose(patient);doctor.dispose(patient);ph.dispose(patient);}
}class ConcretePatient implements Patient {private String name;public ConcretePatient(String name){this.name =name;}public String getName() {return name};}class FacadeTest {public static void main(String[] args) {Patient patient = ___(3)___;___(4)___ f = ___(5)___;___(6)___;}
}【问题 1】(15 分)
(1): (2): (3): (4): (5): (6):
解析:
这道题比较考验Java或者C++的功底,但是实际上哪怕没有这两门语言的功底,只要了解几个关键词,也能了解个大概的。
我们首先了解两个关键词:extends和implements。implements是实现接口(interface),而extends实现抽象类(abstract class)。
上面代码中定义了接口(interface)类Patient,所以(1)就一定是这个接口定义的方法。所以我们直接寻找其实现类,于是找到了ConcretePatient,这个类中实现了方法getName(),所以(1)就是:public String getName();。(2)也是类似的逻辑,找到其实现类Registry或者Docter,我们就可以知道(2):public void dispose(Patient patient);
(3)中定义对象并且初始化类,但是Patient是接口不可能初始化,所以初始化的一定是其实现类,则Patient patient = ___new ConcretePatient("")___;//这里要注意构造方法的入参。
(4)(5)也是定义对象并且初始化类,而且是小写字母f定义变量,则类名应该是大小的F开头,则自然找到Facade。所以(4)(5):Facade f = new Facade(patient);
(6)虽然什么都没有定义,但是结合上面两个对象,以及Facade中的方法定义,我们也可以推断(6):f.dispose();