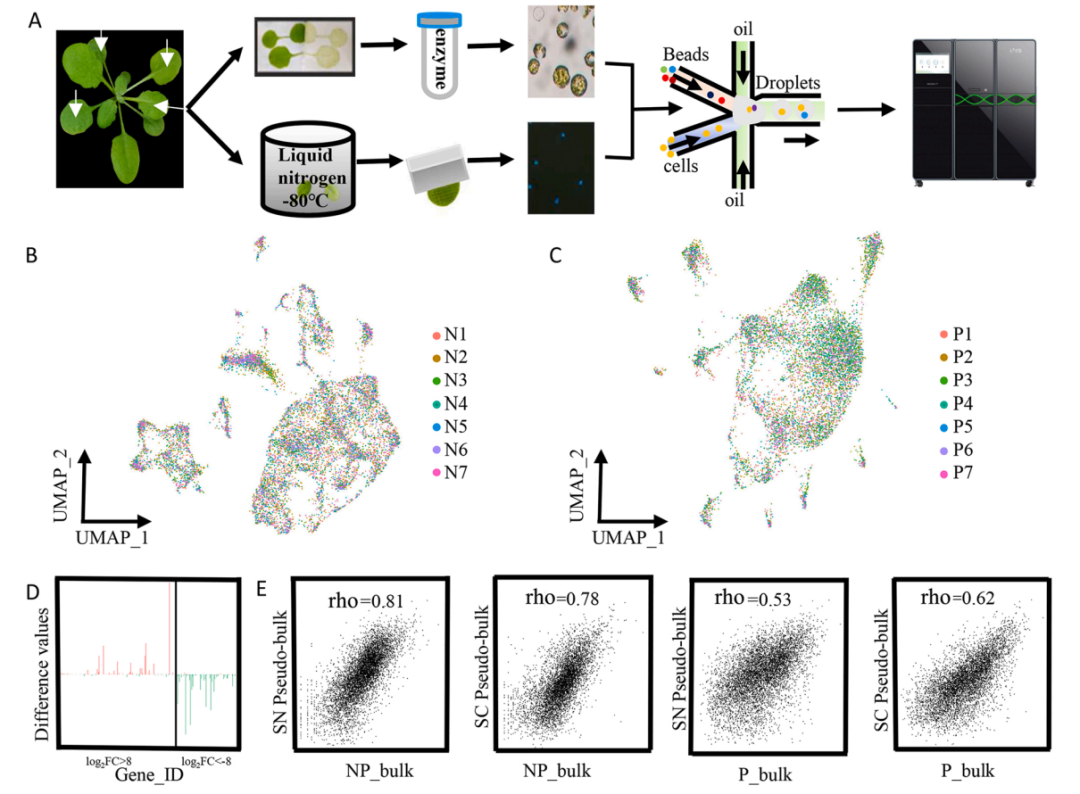
目录
- 前言
- 训练脚本(train_mobilenetv2.py)
- 自定义数据集(my_dataset.py)
前言
Faster R-CNN 是经典的two-stage目标检测模型, 原理上并不是很复杂,也就是RPN+Fast R-CNN,但是在代码的实现上确实有很多细节,并且源码也非常的多,所以看源码的时候也会遇到某些问题,网上完完整整从头到尾讲解的也很少,下面我将会为小伙伴们讲解哔哩哔哩上一个up主简单修改后的fast r-cnn源码,大家可以去看他的视频(源码解析),原理以及源代码真的非常详细易懂,大家也可以去学习,爆赞!!我主要是记录有些自己认为不太明白up主又没有细讲的部分(本人比较笨哈哈)以及梳理整个代码流程,由于很多源码还有debug的图片我都写在博客里,可能看起来会比较多,但是大家一定尽量看看,真的保姆级讲解,大家跟着我走一定能弄懂的!!
下面奉上源码链接(faster r-cnn源码)
训练脚本(train_mobilenetv2.py)
大家看源码之前,可以先看文件里面的README.md文件,看一下需要的配置环境以及如何使用有些指令
源码有两个三个训练脚本,我们不用管多GPU训练的脚本,以train_mobilenetv2.py为例,这个是以mobilenetv2为backbone,另一个是resnet50+FPN(特征金字塔)为backbone的脚本,大差不大,只是结构不同,参数量不同,话不多说,我们直接看main()函数
def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("Using {} device training.".format(device.type))# 用来保存coco_info的文件results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))# 检查保存权重文件夹是否存在,不存在则创建if not os.path.exists("save_weights"):os.makedirs("save_weights")data_transform = {"train": transforms.Compose([transforms.ToTensor(),transforms.RandomHorizontalFlip(0.5)]),"val": transforms.Compose([transforms.ToTensor()])}VOC_root = r"F:\AI\deep-learning-for-image-processing-master\pytorch_object_detection\faster_rcnn" # VOCdevkitaspect_ratio_group_factor = 3batch_size = 8# check voc rootif os.path.exists(os.path.join(VOC_root, "VOCdevkit")) is False:raise FileNotFoundError("VOCdevkit dose not in path:'{}'.".format(VOC_root))# load train data set# VOCdevkit -> VOC2012 -> ImageSets -> Main -> train.txttrain_dataset = VOCDataSet(VOC_root, "2012", data_transform["train"], "train.txt")train_sampler = None# 是否按图片相似高宽比采样图片组成batch# 使用的话能够减小训练时所需GPU显存,默认使用if aspect_ratio_group_factor >= 0:train_sampler = torch.utils.data.RandomSampler(train_dataset)# 统计所有图像高宽比例在bins区间中的位置索引group_ids = create_aspect_ratio_groups(train_dataset, k=aspect_ratio_group_factor)# 每个batch图片从同一高宽比例区间中取train_batch_sampler = GroupedBatchSampler(train_sampler, group_ids, batch_size)nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers# nw = 0print('Using %g dataloader workers' % nw)# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batchif train_sampler:# 如果按照图片高宽比采样图片,dataloader中需要使用batch_samplertrain_data_loader = torch.utils.data.DataLoader(train_dataset,batch_sampler=train_batch_sampler,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)else:train_data_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)# load validation data set# VOCdevkit -> VOC2012 -> ImageSets -> Main -> val.txtval_dataset = VOCDataSet(VOC_root, "2012", data_transform["val"], "val.txt")val_data_loader = torch.utils.data.DataLoader(val_dataset,batch_size=1,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)# create model num_classes equal background + 20 classesmodel = create_model(num_classes=21)# print(model)model.to(device)train_loss = []learning_rate = []val_map = []# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # ## first frozen backbone and train 5 epochs ## 首先冻结前置特征提取网络权重(backbone),训练rpn以及最终预测网络部分 ## # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #for param in model.backbone.parameters():param.requires_grad = False# define optimizerparams = [p for p in model.parameters() if p.requires_grad]optimizer = torch.optim.SGD(params, lr=0.005,momentum=0.9, weight_decay=0.0005)init_epochs = 5for epoch in range(init_epochs):# train for one epoch, printing every 10 iterationsmean_loss, lr = utils.train_one_epoch(model, optimizer, train_data_loader,device, epoch, print_freq=50, warmup=True)train_loss.append(mean_loss.item())learning_rate.append(lr)# evaluate on the test datasetcoco_info = utils.evaluate(model, val_data_loader, device=device)# write into txtwith open(results_file, "a") as f:# 写入的数据包括coco指标还有loss和learning rateresult_info = [str(round(i, 4)) for i in coco_info + [mean_loss.item()]] + [str(round(lr, 6))]txt = "epoch:{} {}".format(epoch, ' '.join(result_info))f.write(txt + "\n")val_map.append(coco_info[1]) # pascal mAPtorch.save(model.state_dict(), "./save_weights/pretrain.pth")# # # # # # # # # # # # # # # # # # # # # # # # # # # ## second unfrozen backbone and train all network ## 解冻前置特征提取网络权重(backbone),接着训练整个网络权重 ## # # # # # # # # # # # # # # # # # # # # # # # # # # ## 冻结backbone部分底层权重for name, parameter in model.backbone.named_parameters():split_name = name.split(".")[0]if split_name in ["0", "1", "2", "3"]:parameter.requires_grad = Falseelse:parameter.requires_grad = True# define optimizerparams = [p for p in model.parameters() if p.requires_grad]optimizer = torch.optim.SGD(params, lr=0.005,momentum=0.9, weight_decay=0.0005)# learning rate schedulerlr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=3,gamma=0.33)num_epochs = 20for epoch in range(init_epochs, num_epochs+init_epochs, 1):# train for one epoch, printing every 50 iterationsmean_loss, lr = utils.train_one_epoch(model, optimizer, train_data_loader,device, epoch, print_freq=50, warmup=True)train_loss.append(mean_loss.item())learning_rate.append(lr)# update the learning ratelr_scheduler.step()# evaluate on the test datasetcoco_info = utils.evaluate(model, val_data_loader, device=device)# write into txtwith open(results_file, "a") as f:# 写入的数据包括coco指标还有loss和learning rateresult_info = [str(round(i, 4)) for i in coco_info + [mean_loss.item()]] + [str(round(lr, 6))]txt = "epoch:{} {}".format(epoch, ' '.join(result_info))f.write(txt + "\n")val_map.append(coco_info[1]) # pascal mAP# save weights# 仅保存最后5个epoch的权重if epoch in range(num_epochs+init_epochs)[-5:]:save_files = {'model': model.state_dict(),'optimizer': optimizer.state_dict(),'lr_scheduler': lr_scheduler.state_dict(),'epoch': epoch}torch.save(save_files, "./save_weights/mobile-model-{}.pth".format(epoch))# plot loss and lr curveif len(train_loss) != 0 and len(learning_rate) != 0:from plot_curve import plot_loss_and_lrplot_loss_and_lr(train_loss, learning_rate)# plot mAP curveif len(val_map) != 0:from plot_curve import plot_mapplot_map(val_map)
代码可能看起来会有点多,数据集用的是PASCAL VOC2012,了解数据集的目录和结构之后,第一个要讲解的是图像增强部分(data_transform),这部分的图像增强方法是自己封装的,我们知道目标检测之前会事先把数据集的每一张图片的ground truth(真实框)通过人工标注出来,但是RandomHorizontalFlip(随机水平翻转)这个操作的时候,对应的真实框(左上x,左上y,右下x,右下y)的坐标也会变,所以需要自己封装进行处理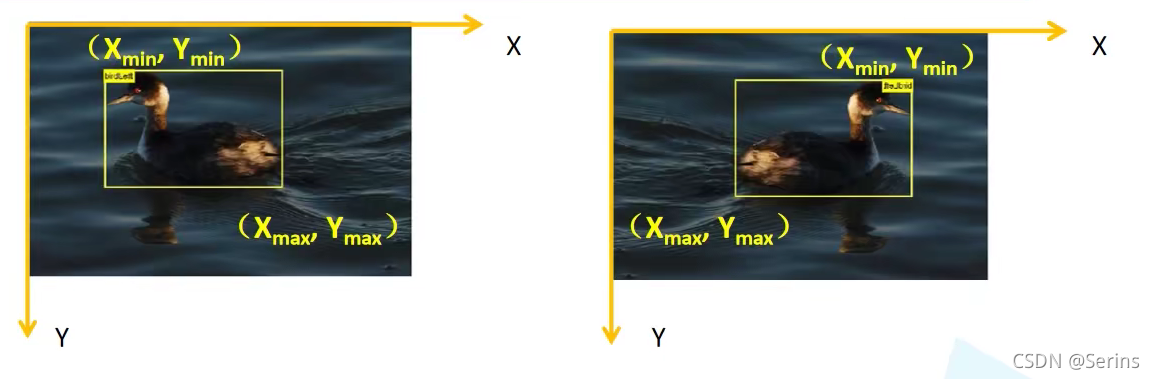
class RandomHorizontalFlip(object):"""随机水平翻转图像以及bboxes"""def __init__(self, prob=0.5):self.prob = probdef __call__(self, image, target):if random.random() < self.prob:height, width = image.shape[-2:]image = image.flip(-1) # 水平翻转图片bbox = target["boxes"]# bbox: xmin, ymin, xmax, ymaxbbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息target["boxes"] = bboxreturn image, target
prob就是随机水平翻转的概率,bbox就是保存的所有真实框的坐标信息,一张图片可能不止一个目标,所以bbox应该是[N, 4]的形状, 通过bbox[:, [0, 2]] = width - bbox[:, [2, 0]]就实现了图像翻转的同时坐标也改变了,注意:上图右边翻转后的坐标位置应该还是对应左上和右下,图上标的右上和左下是不对的,其他的图像增强方式都很简单,看看就明白了,关于自定义数据集VOCDataSet类,后面会单独将,将数据集加载到设备内存后,DataLoader中有个collate_fn参数,这是一个将图片打包的操作,很简单:
def collate_fn(batch):return tuple(zip(*batch))
比如说我们一个batch设置8张图片,debug到这个地方可以看看
这就是传入的八张图片,*batch代表取列表里面的所有元素,zip进行打包并转成元组,加载数据后需要实例化模型,Pascal VOC2012只有20个类别,传入21是因为还多了一个背景
def create_model(num_classes):# https://download.pytorch.org/models/vgg16-397923af.pth# 如果使用vgg16的话就下载对应预训练权重并取消下面注释,接着把mobilenetv2模型对应的两行代码注释掉# vgg_feature = vgg(model_name="vgg16", weights_path="./backbone/vgg16.pth").features# backbone = torch.nn.Sequential(*list(vgg_feature._modules.values())[:-1]) # 删除features中最后一个Maxpool层# backbone.out_channels = 512# https://download.pytorch.org/models/mobilenet_v2-b0353104.pthbackbone = MobileNetV2(weights_path="./backbone/mobilenet_v2.pth").featuresbackbone.out_channels = 1280 # 设置对应backbone输出特征矩阵的channelsanchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),aspect_ratios=((0.5, 1.0, 2.0),))roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], # 在哪些特征层上进行roi poolingoutput_size=[7, 7], # roi_pooling输出特征矩阵尺寸sampling_ratio=2) # 采样率model = FasterRCNN(backbone=backbone,num_classes=num_classes,rpn_anchor_generator=anchor_generator,box_roi_pool=roi_pooler)return model
将所有写好的类都在这里实例化,MobileNetV2可以看这个(MobileNetV2),AnchorsGenerator后面会详细讲,MultiScaleRoIAlign是torchvision封装的类,传入特征层的名字,MobileNetV2特征提取后只会产生一个特征层,名字也是自己取的,所以传入了一个值,output_size就是通过roipooling(Region Of Interest)后输出的特征矩阵尺寸,最后组成FasterRCNN。
这里的训练方式和以往训练图像分类模型的方式有所不同,这里首先冻结前置特征提取网络权重(backbone),训练rpn以及最终预测网络部分,然后解冻前置特征提取网络权重(backbone),接着训练整个网络权重,将训练后的各个指标写入到文件中,以及最终保存权重和画图。大致的话训练流程大家应该都了解了吧,后面再细讲训练时封装的方法,大家先有个体系结构,知道整个大概流程。
自定义数据集(my_dataset.py)
在这一部分开始之前,小伙伴们需要先了解PASCAL VOC2012数据集噢(必须要了解,不然后面看不懂),了解数据集后,我们清楚了数据集的目录结构,再来看这部分代码
class VOCDataSet(Dataset):"""读取解析PASCAL VOC2007/2012数据集"""def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"):assert year in ["2007", "2012"], "year must be in ['2007', '2012']"self.root = os.path.join(voc_root, "VOCdevkit", f"VOC{year}")self.img_root = os.path.join(self.root, "JPEGImages")self.annotations_root = os.path.join(self.root, "Annotations")# read train.txt or val.txt filetxt_path = os.path.join(self.root, "ImageSets", "Main", txt_name)assert os.path.exists(txt_path), "not found {} file.".format(txt_name)with open(txt_path) as read:self.xml_list = [os.path.join(self.annotations_root, line.strip() + ".xml")for line in read.readlines() if len(line.strip()) > 0]# check fileassert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path)for xml_path in self.xml_list:assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path)# read class_indictjson_file = './pascal_voc_classes.json'assert os.path.exists(json_file), "{} file not exist.".format(json_file)json_file = open(json_file, 'r')self.class_dict = json.load(json_file)json_file.close()self.transforms = transforms
传入的参数
voc_root:数据集根目录
year: 哪一年的Pascal VOC数据集
transform:图像增强
txt_name: 根据训练需求传入VOCdevkit//VOC2012//ImageSets//Main文件夹中的txt文件
前面几行os.path.join()代码都是拼接需要的文件路径,方便后面使用,这里我们以train.txt为例,拿到训练集的txt文件,里面是所有训练集图片的编号,读取里面的编号并拼接为xml后缀的形式,方便在Annotations文件夹中打开,拼接完后我们debug发现txt文件的编号对应我们最后得到的xml路径下的编号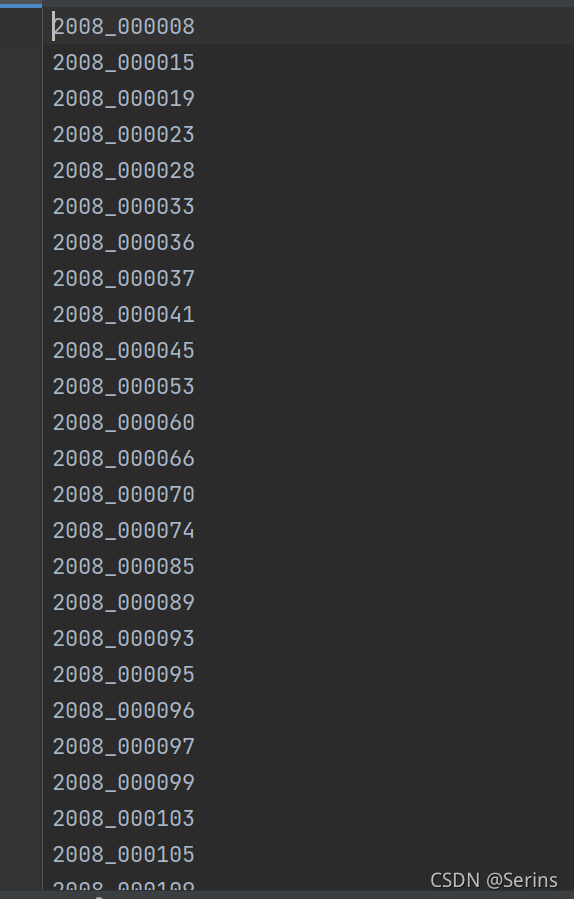
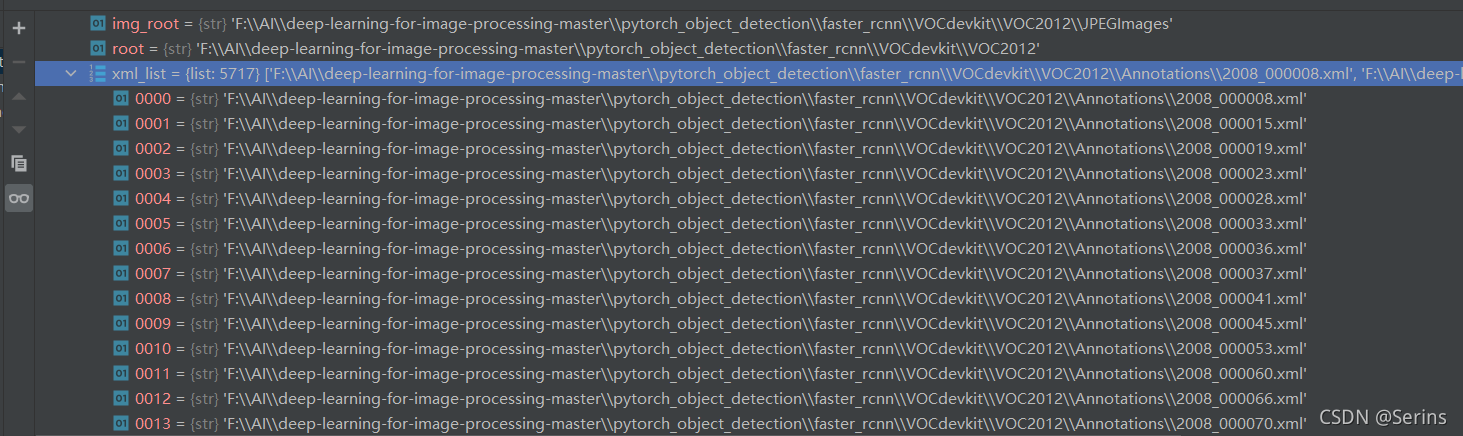
一直到这部分:
json_file = './pascal_voc_classes.json'assert os.path.exists(json_file), "{} file not exist.".format(json_file)json_file = open(json_file, 'r')self.class_dict = json.load(json_file)json_file.close()
pascal_voc_classes.json这个json文件就是以字典的形式保存了Pascal VOC2012数据集的20个类别并用索引表示: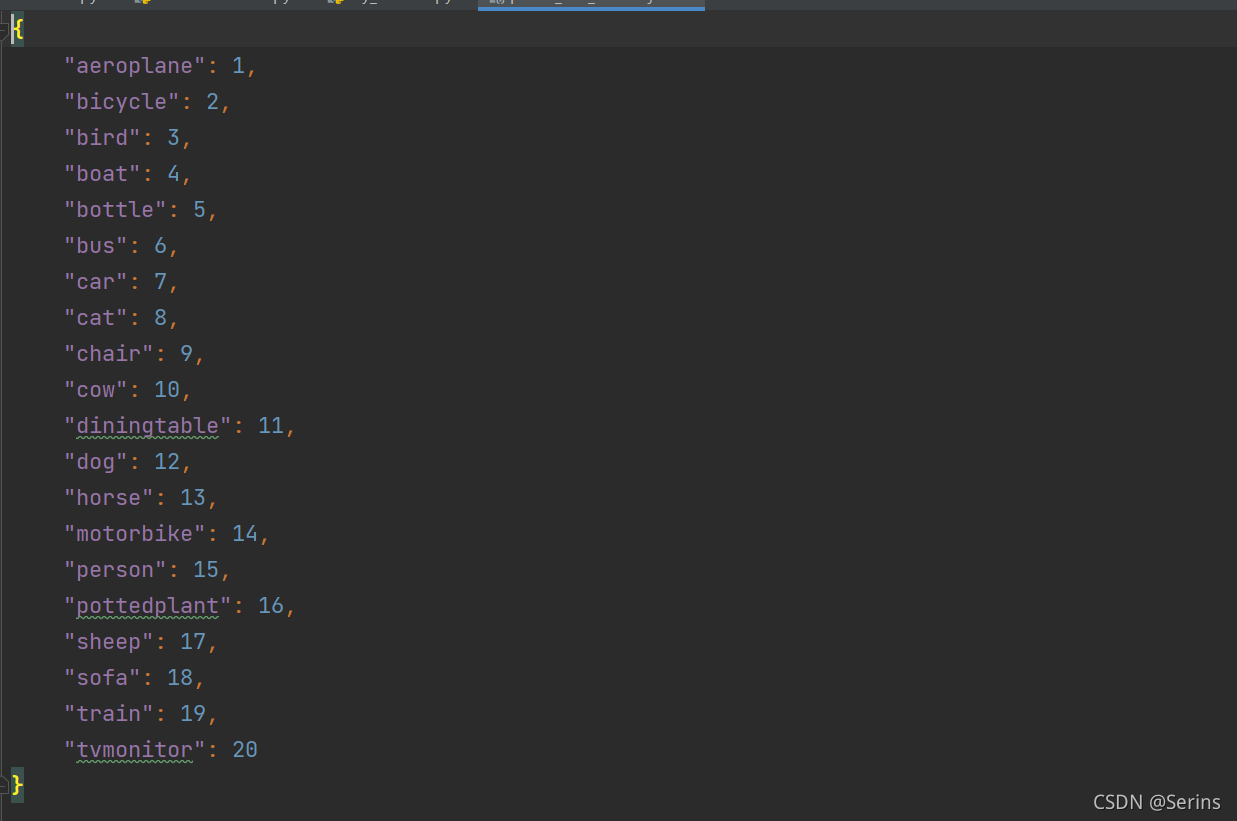
打开这个文件并读取赋值给类变量(加载后记得close关闭文件),后面会用到。

注意:上面是官方的说明,因为是自定义的数据集方法,继承来自pytorch的DataSet类,要求所有的子类必须继承__len__和__getitem__方法,所以这里是必不可少的,__len__就是返回当前数据集的长度,__getitem__用于返回处理后的图片以及标签,下面再细讲。
def __getitem__(self, idx):# read xmlxml_path = self.xml_list[idx]with open(xml_path) as fid:xml_str = fid.read()xml = etree.fromstring(xml_str)data = self.parse_xml_to_dict(xml)["annotation"]img_path = os.path.join(self.img_root, data["filename"])image = Image.open(img_path)if image.format != "JPEG":raise ValueError("Image '{}' format not JPEG".format(img_path))boxes = []labels = []iscrowd = []assert "object" in data, "{} lack of object information.".format(xml_path)for obj in data["object"]:xmin = float(obj["bndbox"]["xmin"])xmax = float(obj["bndbox"]["xmax"])ymin = float(obj["bndbox"]["ymin"])ymax = float(obj["bndbox"]["ymax"])# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nanif xmax <= xmin or ymax <= ymin:print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))continueboxes.append([xmin, ymin, xmax, ymax])labels.append(self.class_dict[obj["name"]])if "difficult" in obj:iscrowd.append(int(obj["difficult"]))else:iscrowd.append(0)# convert everything into a torch.Tensorboxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.as_tensor(labels, dtype=torch.int64)iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)image_id = torch.tensor([idx])area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])target = {}target["boxes"] = boxestarget["labels"] = labelstarget["image_id"] = image_idtarget["area"] = areatarget["iscrowd"] = iscrowdif self.transforms is not None:image, target = self.transforms(image, target)return image, target
该方法通过索引参数 idx 载入每张图片,因为类变量xml_list里面保存了所有的训练集图片的xml文件路径,打开对应的xml文件,这里我debug得到的是这个xml文件(每次debug都可能不一样,因为图片是打乱了的)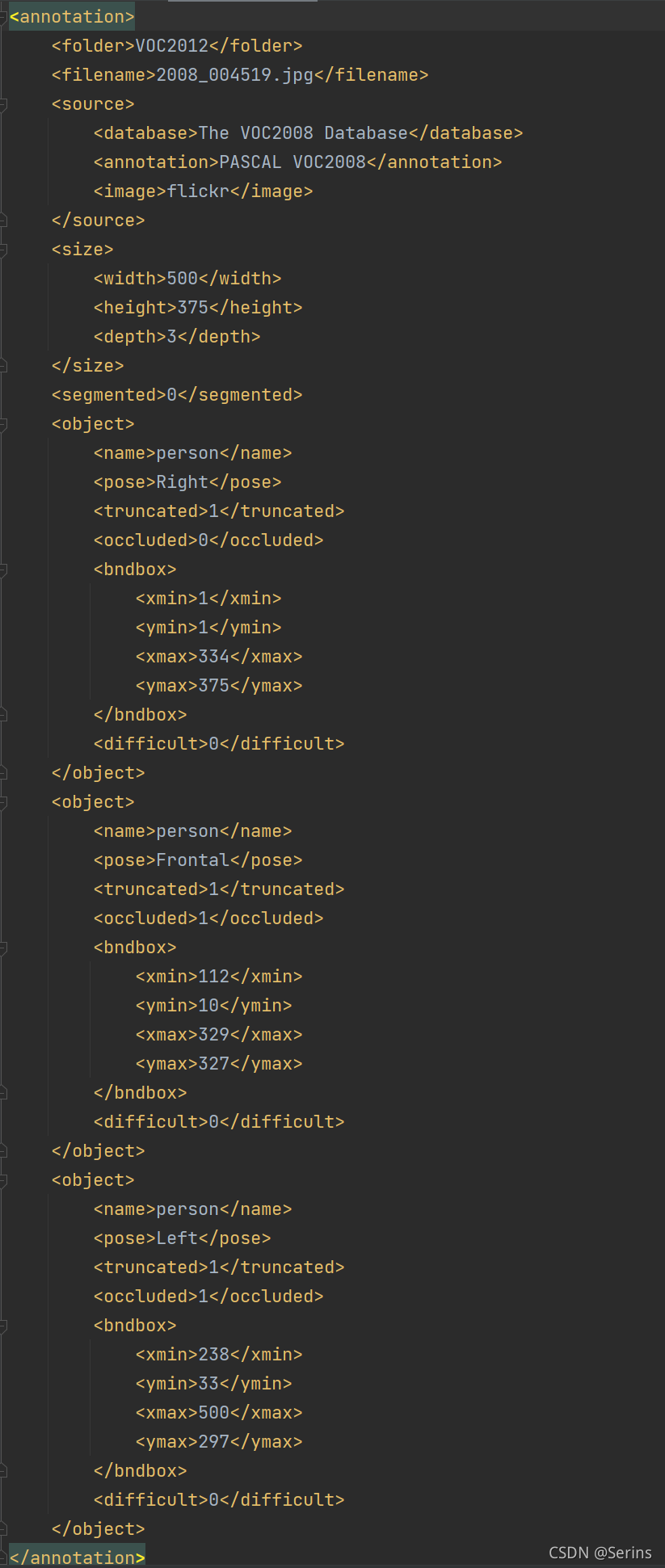
让我们再看看原图片
xml文件里面标注的很清楚,三个真实框的坐标以及类别,我们通过lxml.etree.fromstring先展成数再换成string的格式,调用类方法parse_xml_to_dict(),传入xml的内容,通过递归的方式循环遍历每一层,得到最后的文件内容,
我们可以看看data = self.parse_xml_to_dict(xml)[“annotation”]的debug结果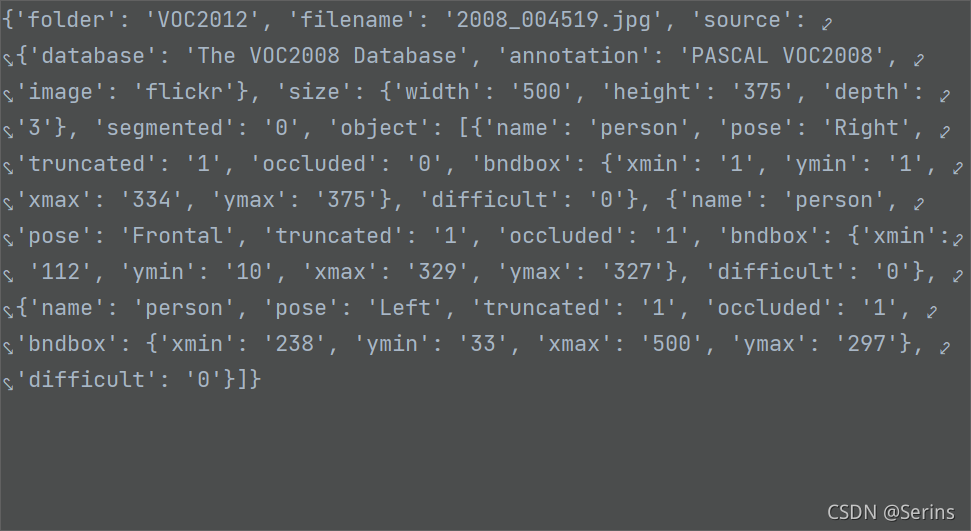
这里我们也顺利拿出了xml文件的所有内容,接下来打开图片并判断是不是JPEG格式的,不是就会报错(原数据集都是jpeg的格式,报错说明数据集有问题),再看上面解析xml后的内容,object是我们的目标,通过列表包裹了多个字典,通过循环列表以及字典的key拿到对应的value,后面一系列操作都是将需要的内容取出来用列表存储,我解释一下这几个列表储存的都是什么:
boxes 存储的所有真实框的坐标
labels存储的真实类别的索引,也就是上面加载的json文件中的类别索引
iscrowd储存的是图片是否难以检测,0就是不难,非0就是比较难检测
再将上述三个列表以及当前图片的索引 idx 转成tensor的形式,area是计算了所有真实框的面积,后面也会用到,最最最后在用一个字典target保存上述所有的信息,debug看一下结果:
最后图像增强一下就好了,其他的部分都差不多,自己看看就好了,至此我们第一部分的代码就讲解完了