Array.prototype.find() 是 JavaScript 的一个数组方法,它被用来在数组中查找一个符合条件的元素。一旦找到第一个符合条件的元素, find() 会立即返回这个元素的值,否则返回 undefined。
以下是 find() 方法的基本语法:
arr.find(callback(element[, index[, array]])[, thisArg])
参数:
callback: 回调函数,在数组每个元素上执行,接受三个参数:currentValue : 数组中正在处理的当前元素。
index (可选): 数组中正在处理的当前元素的索引。
array (可选): find() 方法被调用的数组。
thisArg (可选): 执行回调时用作 this 的对象。
返回值:
返回数组中第一个满足所提供测试函数的元素的值,否则返回 undefined。
1.使用currentValue 参数:
// 例子1:寻找数组中第一个大于10的元素
let array = [5, 12, 8, 130, 44];
/**
我们传给 find() 函数一个回调函数,该函数会对数组的每个元素进行测试。当找到第一个大于10的数时,find() 就立即返回这个数。
*/
let found = array.find(element => element > 10);console.log(found,'-----------found'); // 输出: 12
2.使用 currentValue 和 index 参数
/**
例子2:除了检查元素是否大于10,我们还检查其索引是否大于2。因此,find() 返回的是第一个在索引大于2且值大于10的元素。
*/
var array2 = [5, 12, 8, 130, 44];var found = array2.find(function(element, index) {return element > 10 && index > 2;
});console.log(found); // 130
3.使用 currentValue,index 和 arr 参数
/**
例子3:我们查找最后一个元素(索引等于数组长度减一)且该元素大于10的元素。因为44不满足条件,所以返回 undefined。
*/var array3 = [5, 12, 8, 130, 44];var found = array3.find(function(element, index, arr) {return element > 10 && index === arr.length - 1;
});console.log(found); // undefined
4.其他
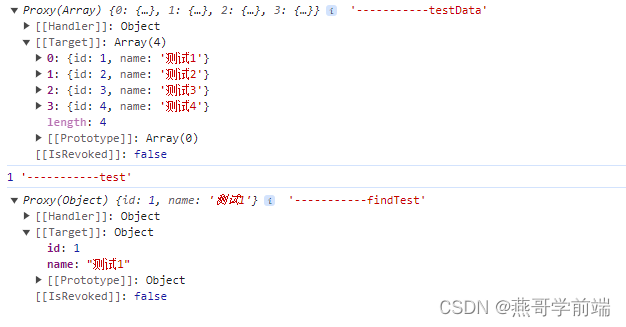
// 例子4:取出testData中与test对应的对象
const testData = ref([{id:1,name:'测试1'
},{id:2,name:'测试2'
},{id:3,name:'测试3'
},{id:4,name:'测试4'
},])const test = ref(testData.value[0].id) // 1
const findTest = testData.value.find((item)=> item.id = test.value)console.log(testData.value,'-----------testData');
console.log(test.value,'-----------test');//1
console.log(findTest,'-----------findTest'); // { id:1, name:'测试1' }