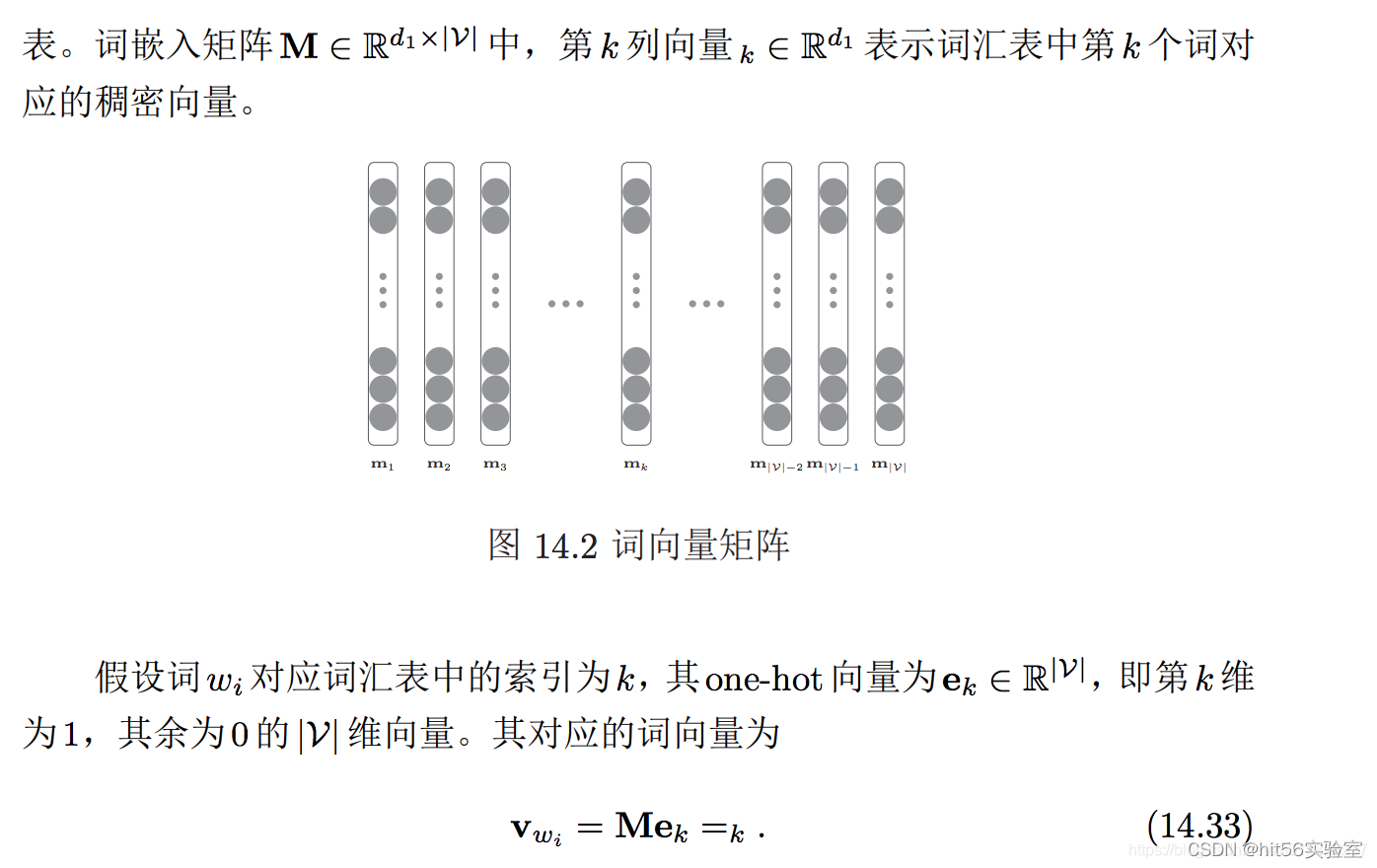
本篇的主要脉络同样依据中科大何向南教授、合工大汪萌教授联合在 TKDE 上的一篇综述文章展开:Bias and Debias in Recommender System: A Survey and Future Directions。
下面按照前导文章中介绍的数据偏差 Selection Bias、Conformity Bias、Exposure Bias、Position Bias,分别介绍相应的去偏方法。Popularity Bias、Unfairness 以及如何减缓闭环累积误差的方法,暂时不会在本文中涉及。
一、基础概念
1. Propensity Score
Propensity Score 的详细介绍建议查看下文,,注意掌握几个变量定义:干预变量 T,结果变量 Y,混淆变量 X,观测变量 U
集智科学家:如何在观测数据下进行因果效应评估78 赞同 · 1 评论文章编辑
-
- 定义:在干预变量之外的其他特征变量为一定值的条件下,个体被处理的概率
- 倾向指数概括了群体的特征变量,如果两个群体的倾向指数相同,那他们的干预变量就是与其他特征变量相独立的。对于药物实验来说,如果能保证两群人的他吃药的概率完全一样,那么可以说这两群人其他特征分布也是一样
- 倾向指数在实际应用中观测不到,但可以使用有监督学习的方法进行估计,一般是回归
在推荐中来说“被处理”可以理解为“被观测到”,如何计算某个 item 被某个 user 观测到的概率?容易想到的思路是在保持其他条件相同再计算概率,例如排序队列位置不同时重复同个 user 在同个 item 上的观测概率,但这种理想情况一般会伤害用户体验。
如何计算 Propensity Score 是一个独立问题,可以 naive 的统计方法(统计历史上同位置的平均点击率)、隐变量学习(例如 click models 中预估 position bias 的方法,可以参考我之前的文章 成指导:深入点击模型(二)PBM, UBM 与 EM 算法),或者 [SIGIR 2018] Unbiased Learning to Rank with Unbiased Propensity Estimation 中介绍的通过对偶学习 Ranking Model 和 Propensity Model 来求解 Propensity Score 思路,也可以用于参考。
2. 点击模型(click models)
介绍点击模型之前,需要区分 click models 区别于 FM/FFM/Wide&Deep/DeepFM 等一系列近年大火的 CTR 模型,点击模型关注更多的是可解释性,通过人为知识提出先验假设,再通过概率图模型独立建模各因素,更多时候依赖于 EM 算法求解。因此各种 bias 其实都可以作为其中一个因素存在于概率图,然后被求解出来。点击模型被广泛使用于解决 exposure bias/ position bias 中,之前我有两篇文章深入介绍过点击模型,这里就不重复写了:
- 成指导:深入点击模型(一)RCM, CTR, CM 与 极大似然估计
- 成指导:深入点击模型(二)PBM, UBM 与 EM 算法
二、数据偏差
数据偏差的处理方法有一些共通思路,这里先把共通思路介绍一下,再分开介绍各种 Bias 的独特处理方法。一般需要去偏的步骤有 2 个,分别是在评估中去偏、训练中去偏。
1. 评估去偏
评估推荐系统在评分预测、推荐准确率上的常见 user-item 评估度量指标吧δ_{u,i}可以是 AUC、MAE、MSE、DCG@K、Precision@K,对多个评分样本的评估度量 H(R^) ,一般是单个样本度量的加权平均。这里“多个样本”常规做法是指观测到的样本而不是真实的全量样本,此时会出现 selection bias 造成的评估指标上的偏差,修正后的评估度量为
常用工具有 Propensity Score(倾向分数) 。做法是在单个样本的评估指标中加入 IPS(逆倾向得分,即倾向指数的倒数),倾向性 P_{u,i}定义为观测某个 user-item 评分值的边际概率 P(O_{u,i}=1) ,因此修正评估度量
2. 训练去偏
- 数据代入法。数据偏差的本质是缺少无偏数据,那么通过协同过滤、社交关系加强等方式,补充尽可能相似的数据源,并且根据相似程度决定数据源的贡献程度
- 倾向分数。这个比较好理解,利用 IPS(逆倾向分数)修正每组样本的 loss 贡献值,如
,其中Reg(θ) 是参数的正则化限制
- Meta Learning。Meta Learning 的 motivation 就是如果模型可以先在数据较多的数据集上学到这些有关“该如何学习新的知识”的先验知识,由此让模型先学会“如何快速学习一个新的知识”,再去数据较少的数据集上学习就变得很容易了。这么看 Meta Learning 完美契合 selection bias 的解决方案,但因为这是个独立学科方向,建议参考以下回答单独理解:
什么是meta-learning?599 关注 · 17 回答问题编辑
三、选择偏差
1. 评估去偏
- ATOP
ATOP 是另一种度量推荐系统效果的无偏指标。ATOP 方法同时建立在 2 个假设之上:(1)高相关性评分在观测数据上是随机缺失的;(2)其他评级值允许任意丢失数据机制只要丢失的概率高于相关的评分值。这两个假设实际上较难同时符合,因此 ATOP 的应用也较少
记为用户 u 已观测到的相关性 item 的个数,
为在 TopK item 中的个数,作者证明 ATOP 是对平均召回率的无偏估计,并与用户的平均精度成正比

2. 训练去偏
Doubly Robust 模型。这个方法需要根据已有数据,再学习一个预测的模型反事实评估某个个体在干预变量变化后,结果变量的期望值。经过证明,只要倾向指数的估计模型和反事实预测模型中有一个是对的,计算出的平均因果效应就是无偏的;但如果两个模型估计都是错误的,那产生的误差可能会非常大(看起来也并非多么 robust)。
四、一致性偏差
conformity bias 大多数情况下是由于人们的“从众心理”导致的,比较简单的处理方法就是将投票人数(样本数量)、投票分布、得分平均值,都作为建模的输入信号,用一个拟合器去拟合去偏后的修正得分值。本质上就是希望把“社会因素“作为考虑的一部分。
五、曝光偏差
1. 训练去偏
- 倾向分数
类似 selection debias 小节,使用逆倾向分数计算即可。当计算度量指标的时除以倾向分数。这里提一篇文章 [WSDM 2020] Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback,先假设:即物品必须曝光给用户且相关才会发生点击。之后定义了一个理想化的 loss 函数对 label=0/1 的样本求损失和,每个样本会被相关性等级度量:
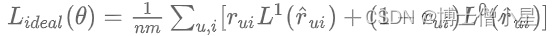
经过去偏操作之后,能够得到修正后的损失函数无偏预估值形式:
- 采样
虽然曝光的内容有偏,但是一般学习中使用到的正负样本都是采样得到的,那么这里就有一个阶段需要独立处理:采样。而在一般的信息检索问题中,负例一般是远远大于正例,所以对冗余的负例选择性采样是一个需要探索的问题。可以使用最简单的随机采样,或者对于比较流行的负例内容做重复采样(流行数据一般经过充分曝光,负例程度比较确信)。更复杂的思路里,会把样本的 side information 或者图关系作为预测采样率的工具,按照采样率工作。
这里多说一点,实际工作中,我们尝试对于未曝光的样本,适当采样作为”伪负样本“(因为不确定未曝光是正是负,但因为推荐问题中正例占比很低)可以增加模型的泛化能力。
六、位置偏差
Position bias 广泛存在于搜索系统中(大家自己想想是不是经常性点击百度/谷歌搜索结果的第一位返回结果),推荐系统中也同样存在。而经典去偏方法就是使用点击模型(包括 click models 的各种书籍或经典论文中,一般也都是拿 position bias 作为分析示例)。同理,逆倾向分数同样适用。点击模型、倾向分数的解释,请参考本文的文章开头。
在神经网络 CTR 模型中,华为发表的[RecSys 2019] PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems,以及 Youtube 发表的 [RecSys 2019] Recommending What Video to Watch Next: A Multitask Ranking System,尝试过将 position bias 作为多塔建模的单独一塔或作为独立一塔的主要输入,并且显式地通过 logits 相乘来反应
即物品必须曝光给用户且相关才会发生点击,而是否曝光仅与物品所处位置
决定。
至此,常见数据偏差的去偏思路与方法已经介绍完成了。