前置
锁理论
锁总结
锁实践
记录锁
间隙锁
临键锁
对数据库的操作有读、写,组合起来就有 读读、读写、写读、写写,读读不存在安全问题,安全问题加锁都可以解决,但所有的操作都加锁太重了,只有写写必须要求加锁,读写、写读可以用MVCC。MySQL的默认隔离级别是RR,但是RR在MVCC的加持下还是存在幻读,这时候就还是需要加锁,间隙锁就是用来在RR级别下解决幻读的问题。
共享锁、排他锁
共享锁(shared lock )也叫读锁、S锁,数据被某个事务获取了共享锁之后,还可以被其它事务获取共享锁,但是不能被其它事务获取排他锁。
排他锁(exclusive Lock)也叫写锁、X锁,数据被某个事务获取之后就不能被其它事务获取任何锁。
总结:共享锁和共享锁之间不冲突,排他锁和共享锁、排他锁都冲突。默认select的时候是不加锁的,更新、添加、删除的时候会加排他锁。
强制加共享锁 lock in share mode ,强制加排他锁 for update
select * from my_table where id = 1 lock in share mode;
select * from my_table where id = 1 for update;
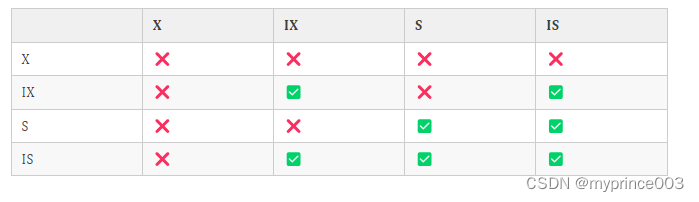
意向锁:意向共享锁、意向排他锁
加锁的时候可能锁某一行或几行的数据,也可能锁整个表,但上面共享锁只能和共享锁兼容,排他锁和两者都不兼容。虽然锁表的场景很少,如果要用共享锁锁表不得一行行去遍历看看数据有没有被排他锁锁过,如果要用排它锁锁表就得一行行去遍历看是否存在数据被共享锁或排他锁占用。
实际上是不可能遍历的,代价太大,所以在对某些数据加共享锁的时候,就会给表加上 意向共享锁,对某些数据加排他锁的时候就会对表加上 意向排他锁。
这样再对表加锁的时候只需要判断是否有对应的意向锁就好了,而不需要遍历。意向锁之间是不冲突的。
共享锁(S)、排他锁(X)、意向共享锁(IS)、意向排他锁(IX)的兼容关系
记录锁、间隙锁、临键锁
前置
上面说了一些锁的概念,现在来尝试一下给数据加锁,在正式开始之前需要了解一下MySQL的数据存储结构:
在主键索引形成的B+Tree里面,非叶子结点存储的是主键索引,叶子结点存储的是数据
在非主键索引形成的B+Tree里面,非叶子结点存储的是当前索引,叶子结点存储的是主键索引
如果没有主键索引,会拿第一个唯一索引来做聚簇索引,如果也没有唯一索引就会创建一个看不见的唯一键。
所以当通过非主键索引去找数据的时候,其实是先通过非主键索引找到主键索引,再通过主键索引去找数据,这个过程被称为 回表。
锁理论
记录锁(Record Locks):记录锁是基于索引记录上的锁,它锁定的行数是固定的、明确的,根据情况它可以是共享锁、排他锁。间隙锁(Gap Locks):间隙锁的目的是在RR级别下,防止幻读,幻读的产生是当前事务多次的查询结果数量上不一致,间隙锁的目的就是保证当前范围内的数据不会被更改,所以它会锁住某些个区间的数据。临键锁(Next-key Locks):等于 记录锁+间隙锁,所以我们只需要知道这两个锁的定义就好了,MySQL默认级别是RR、默认锁上临键锁。
锁总结
锁都是基于索引去找到数据记录再加锁的,而索引的规则是:通过其它索引找到主键索引,所以:
没有使用索引做更新相关操作会锁表。
通过唯一/主键索引等值加锁,只会锁具体的行,非唯一索引则不一定,SQL优化器会基于数据分布选择记录锁,或临键锁。
只有在RR级别下才有间隙锁,目的是为了解决幻读,如果操作的数据是跨多个范围,就会加多个区间的间隙锁。
MySQL默认的锁就是【临键锁】,所以在执行SQL的时候,记录锁和间隙锁是会同时存在的。范围是左开右闭的区间。
在SQL查询的时候,我们知道是先通过索引去找数据的,其实加锁也是基于索引的,通过索引找到对应的数据然后把相关的数据行都锁上,如果没有使用索引就会扫描全表,也就会锁表。
锁实践
基于上面的理论和总结,我们用实际的SQL来证明一下,加深印象。
记录锁
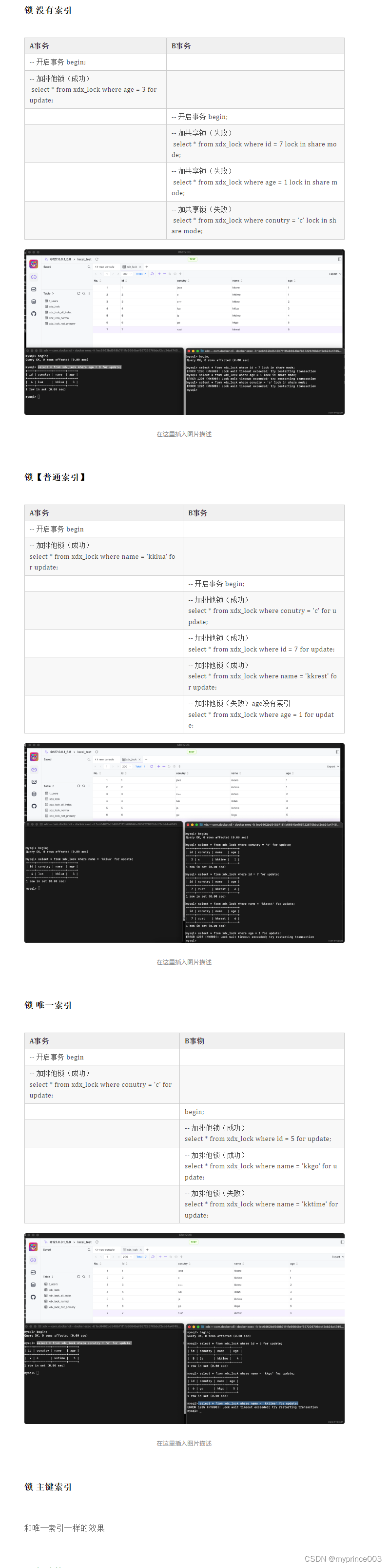
创建一个表,并往里面塞一些数据,然后来验证
CREATE TABLE `xdx_lock` (`id` int NOT NULL COMMENT '主键索引',`conutry` varchar(255) NOT NULL COMMENT '唯一索引',`name` varchar(255) NOT NULL COMMENT '普通索引',`age` int NOT NULL COMMENT '不是索引',PRIMARY KEY (`id`),UNIQUE KEY `conutry_idx` (`conutry`),KEY `name_idx` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='锁表测试'
间隙锁
让我们再来回忆一下,间隙锁的目的是为了防止幻读,所以间隙锁的目的就是阻止一切会让当前事务数据量变化的操作。
MySQL的数据存储是B+Tree,以主键建立的B+Tree。我们假设表的数据有5条,它们的id分别是 5,10,15,20,25 (这种数据很有可能对吧),虽然它是树结构,但也是排好序的,并且就是以主键为排序的。
间隙锁的原理就是锁住我们查询数据的各种区间,可能不好理解,先举几个例子:
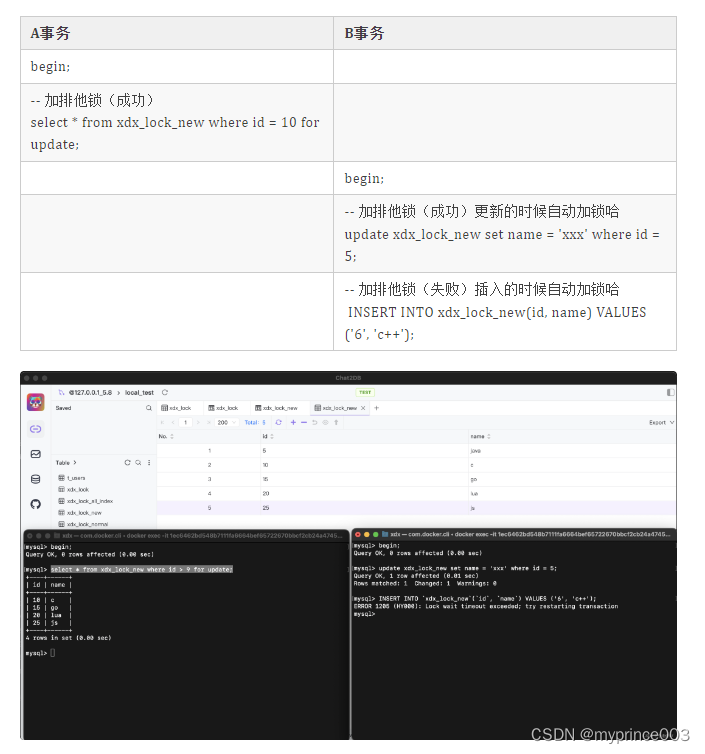
where id > 9, 它锁住的区间就是 (5, +∞) , 开头是5不是9哦,因为9这玩意不存在呀,基于索引加锁,没有索引无法加锁
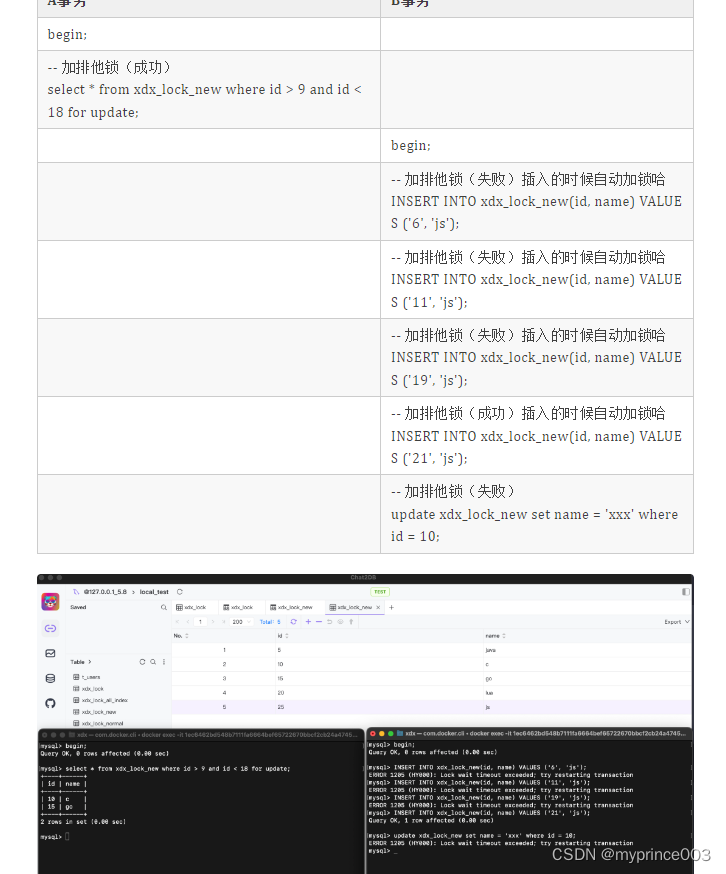
where id > 9 and id < 18, 它锁住的区间就是 (5, 10]、(10, 15]、(15, 20]
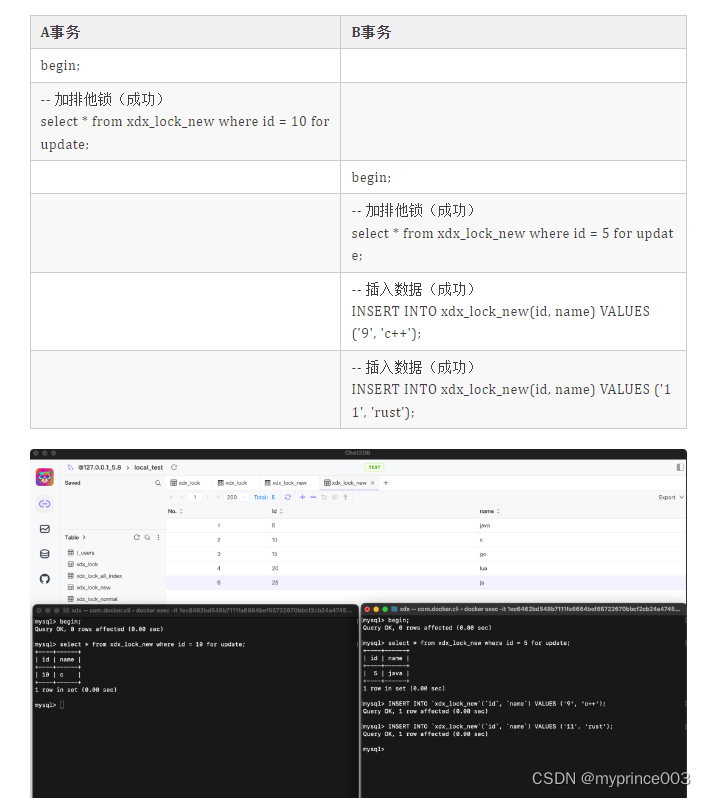
where id = 10,它只会锁住 10 这一条数据
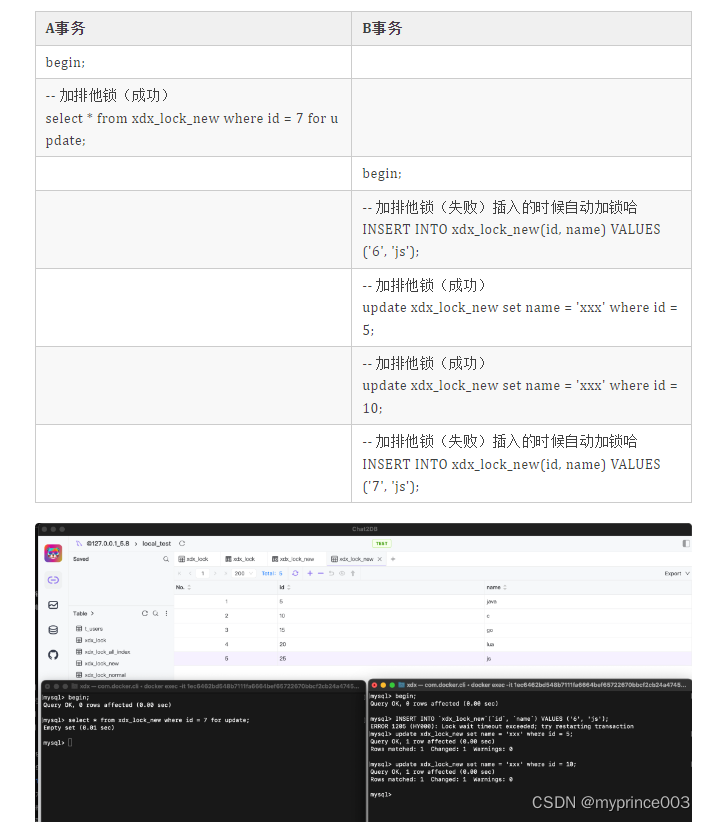
where id = 7,因为7不存在,为了防止后续新增,所以也要锁住最近的一个区间 (5, 10]
注:间隙锁 是左开右开的区间,但间隙锁和临键锁一起的,而临键锁是左开右闭。
CREATE TABLE `xdx_lock_new` (`id` INT NOT NULL COMMENT '主键' ,`name` VARCHAR(255) NOT NULL COMMENT '普通数据' ,PRIMARY KEY (`id`)
);INSERT INTO `xdx_lock_new`(`id`, `name`) VALUES ('5', 'java');
INSERT INTO `xdx_lock_new`(`id`, `name`) VALUES ('10', 'c');
INSERT INTO `xdx_lock_new`(`id`, `name`) VALUES ('15', 'go');
INSERT INTO `xdx_lock_new`(`id`, `name`) VALUES ('20', 'lua');
INSERT INTO `xdx_lock_new`(`id`, `name`) VALUES ('25', 'js');
where id > 9
where id > 9 and id < 18
where id = 10
where id = 7
锁非唯一索引
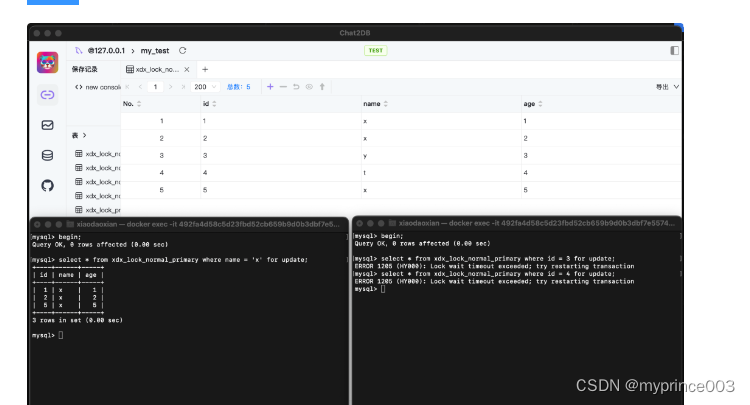
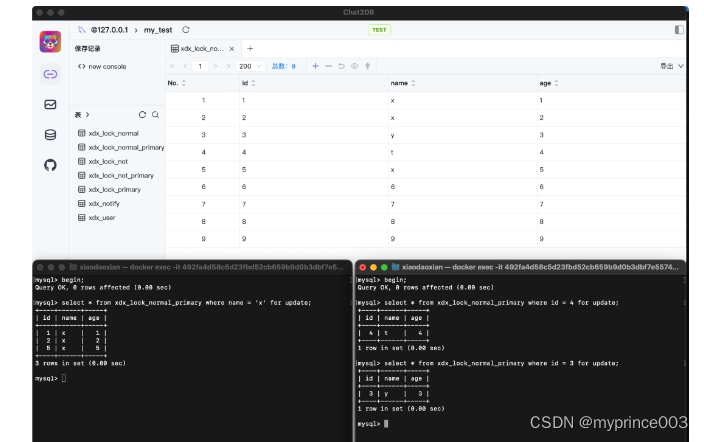
基于唯一索引或主键索引,间隙锁的范围很好理解,但是基于非唯一索引进行数据锁定的时候,SQL优化器最终执行的结果可能和我们想象的并不一样。比如下面这个案例,相同的SQL,但是表数据不一样的时候,直接结果也不一样。
CREATE TABLE `xdx_lock_normal_primary` (`id` int(11) NOT NULL,`name` varchar(255) NOT NULL,`age` int(11) NOT NULL,PRIMARY KEY (`id`),KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
结果一
结果二
总结
来看一下GPT的回答,我觉得应当是如此的,简单来说就是查询优化器觉得不需要间隙锁了,直接转成具体的记录锁。
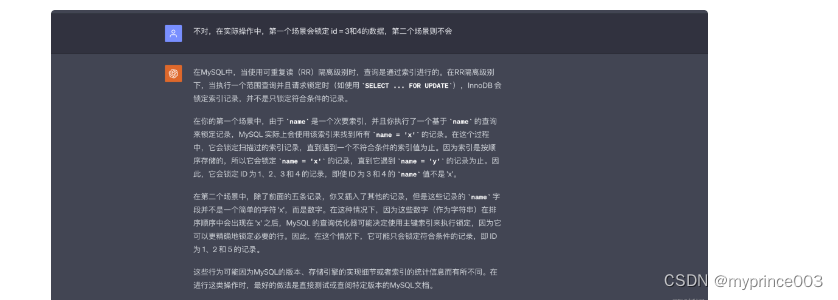
注:在第一种情况下,的确是因为加了间隙锁导致的,因为间隙锁的目的是防止幻读,是在RR级别下的,当我把全局事务改成RC的时候,第一种数据集也不会锁 3、4 两行数据。
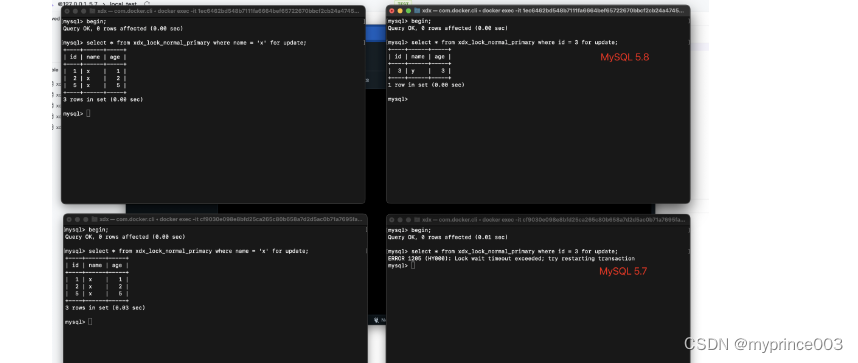
但其实这也不是必然的,在MySQL5.8和5.7里面的结果是不一样的
临键锁
MySQL默认的锁就是临键锁,当写一个SQL的时候就有可能触发临键锁,但临键锁并不是一个单独的锁,临键锁 = 记录锁 + 间隙锁,所以分析的时候我们可以单独的判断它当前加了那种记录锁,然后再单独看它是否被加了间隙锁,再结合起来判断。
表锁、页面锁、行锁
在学习MySQL锁的时候这些锁给我带来了很大的困扰,其实它们只是表示我们当前这次操作锁了多少数据而已,比是一行数据还是整个表的数据。
MySQL官方文档里面并未对这几个锁做出解释。
死锁
死锁其上并不属于MySQL锁的范围,它只是基于锁而产生的一种现象