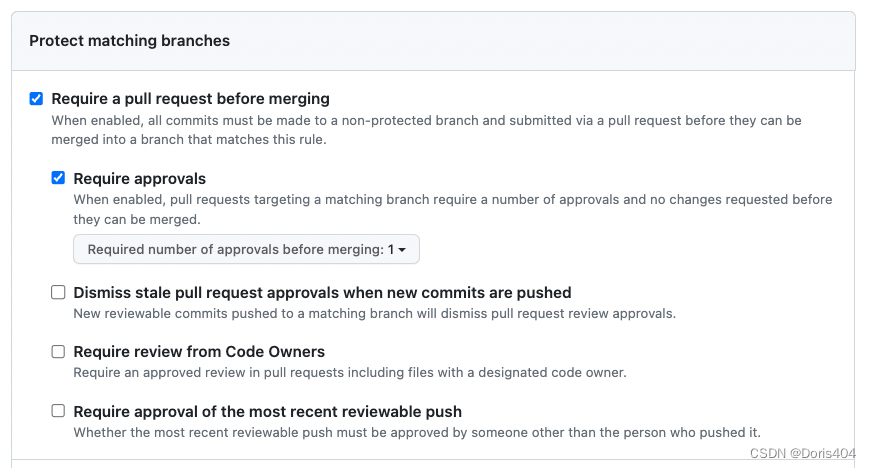
1、模型选择:GPT4
2、需求:在win10操作系统环境下,基于python3.10解释器,爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,并将爬取的信息写入Excel表中。
3、结果
它大致理解了我的需求,生成了一个名为douban_scraper的项目文件夹

其中主体程序文件在douban_scraper子文件夹中:

在自己手动安装依赖库之后,尝试直接运行,发现仍然出现中文乱码情况

经过人工修改,程序最终能运行,但是未能爬取到最终的结果

4、原因分析
首先发现request返回的状态码是418,思考了一下,应该是生成的代码没有请求头,对此,我手动添加了一下,状态码返回了200。然后运行程序报错:

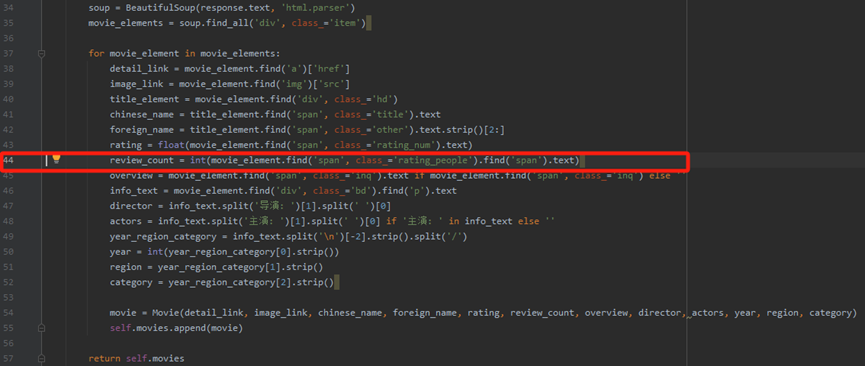
这肯定是bs4解析代码存在问题,生成的解析网页的代码段如下,红色方框中为报错的行:
查看网页元素代码
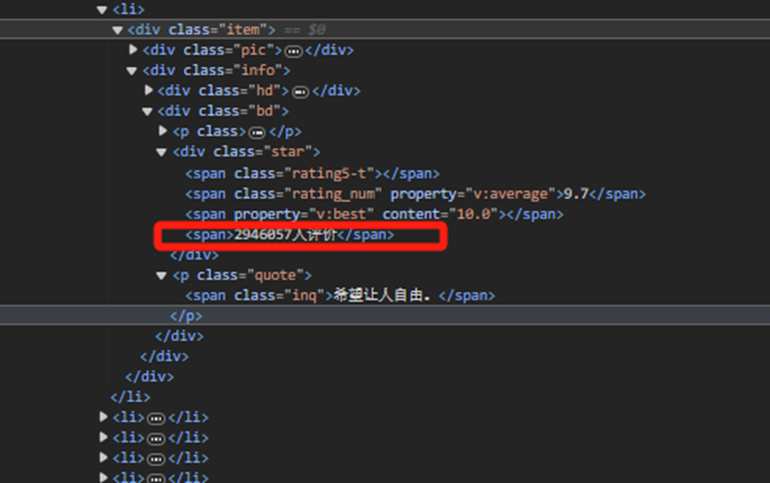
这表明,生成的代码都是盲写,与实际的情况无法验证是否一致,改为采用正则表达的方法对评价人数这个字段进行提取
review_count = re.findall(re.compile(r'<span>(\d*)人评价</span>'), str(movie_element))[0]
最终程序运行成功
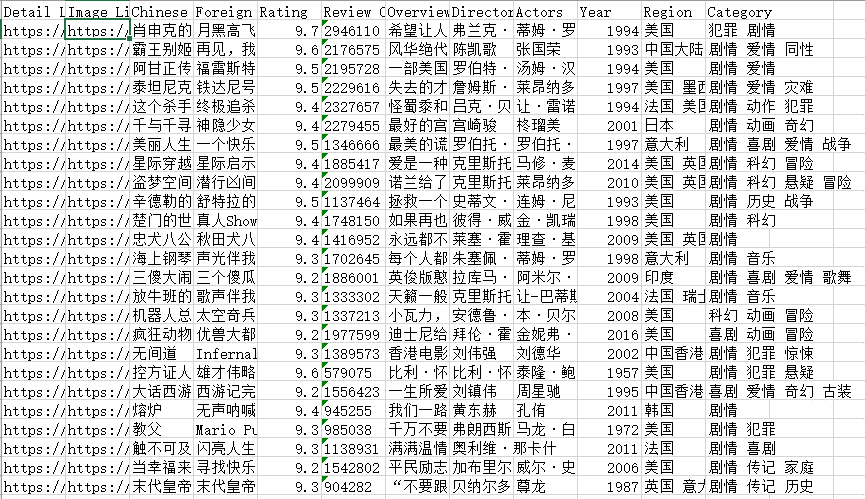
虽然代码运行成功了,但是并没有完全达到我的需求,我的需求是爬取豆瓣电影Top250的相关信息,而生成的代码只爬取了第一页,对此,我对main函数的base_url进行修改,改为:
base_url = "https://movie.douban.com/top250?start="
并加入循环,依次读取每一页
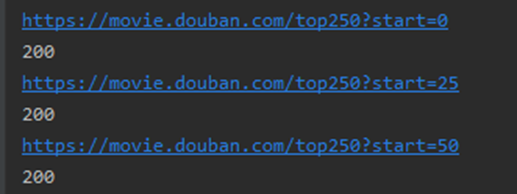
接着又报错了
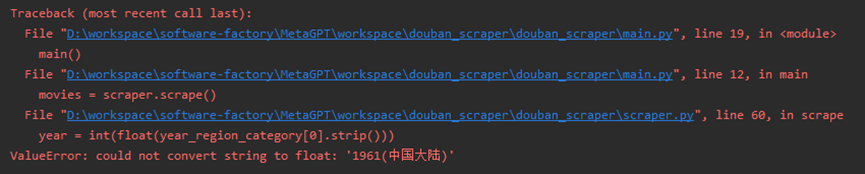
原来是由于这个电影的年份出现了(中国大陆),应该是解析出现了问题,
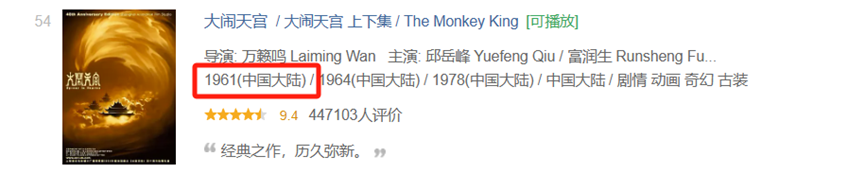
生成代码是这样的,这里代码的逻辑是取列表的一个元素为年份,第二个元素为地区,第三个元素为类型,但是对于第54个电影,第一个元素,第二个元素、第三个元素都是1961(中国大陆),属于字符串型,且后面提取出来的元素也会出错。

为此,我们对代码加入异常处理,并对代码进行优化:
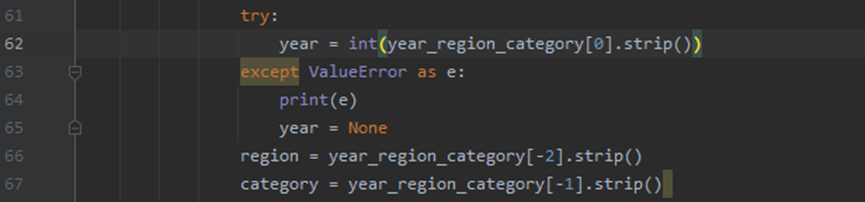
最终程序运行成功,需求得到了满足。

5、总结
基于大语言模型的软件开发多智能体框架MetaGPT,并不可靠。GPT4的理解能力和代码审查能力明显要优于GPT3.5,但是对于一个简单的爬虫任务,MetaGPT也无法实现一步到位就能直接运行得到用户想要的结果。
主要原因有以下几点:
(1)首先对于MetaGPT生成的软件项目在本地运行如果本地缺少项目中需要的一些依赖项,则需要自己安装依赖库,这就可能导致版本的兼容问题。
(2)其次,程序中的一些参数设置需要人工配置,比如发出网页请求,需要加入请求头部信息,否则无法返回网页信息,也就无法解析内容返回结果,而请求头信息是需要用户提供的。
(3)还有,MetaGPT属于盲写代码,生成的代码是通用的情况,而实际运行过程会出现很多特殊的情况,导致程序报错,哪怕程序虽然不会报错,也有可能不会达到用户的需求,当前只能起到辅助提高效率,人需要程序员进行不断地调式。
(4)用户提出需求之后,无法参与到软件开发的过程中,无法参与反馈。
总之,提示和模型的性能对结果影响很大。MetaGPT编码的规范性很强,也有一定的逻辑,但是对于涉及到人工干预的任务,或者遇到一些情况特殊的任务,往往达不到预期。
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,对Python有一定认知和理解,会结合自身科研实践经历不定期分享关于python、机器学习、深度学习等基础知识与应用案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、邀请三个朋友关注本订阅号或2、分享/在看任意订阅号的三篇文章即可在后台联系我获取相关数据集和源码。
2、关注“数据杂坛”公众号,点击“领资料”即可免费领取资料书籍。
3、如果对本文有疑问,或者有论文指导的相关需求,点击“联系我”添加作者微信直接交流。