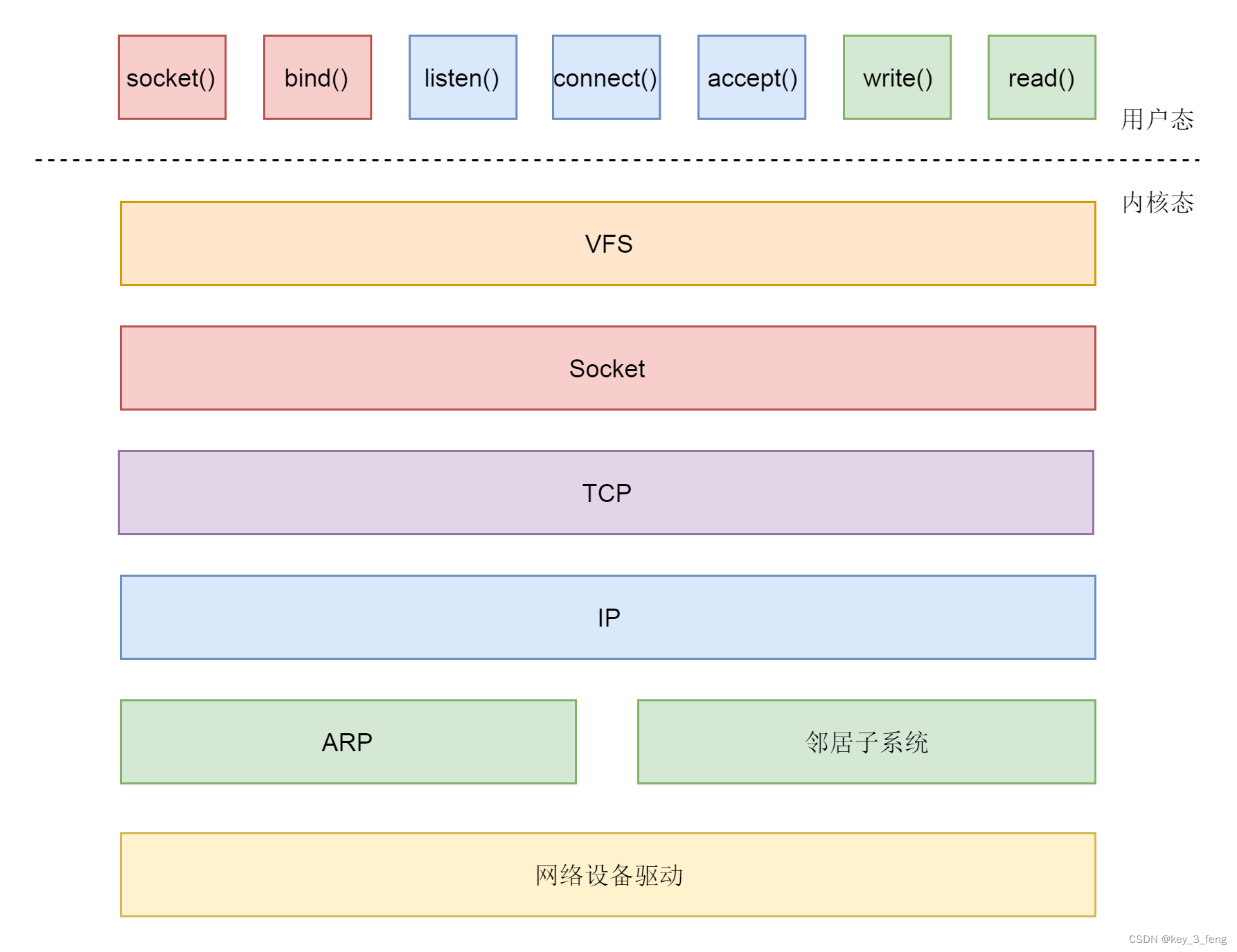
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击、输入、选择等等。它支持多种浏览器,包括Chrome、Firefox、Safari等等,并且可以在多个平台上运行。
安装和配置Selenium
在使用Selenium之前,需要安装Selenium和相应的浏览器驱动程序。这里我们以Chrome浏览器为例,介绍如何安装和配置Selenium。
首先,我们需要安装Selenium库。可以通过以下命令来安装:
pip install selenium
接下来,我们需要下载Chrome浏览器驱动程序。可以从ChromeDriver官网 ↗上下载适合自己的版本。下载完成后,将驱动程序所在的路径添加到环境变量中。
from selenium import webdriver# 指定驱动程序所在路径
driver_path = '/path/to/chromedriver'# 创建Chrome浏览器实例
browser = webdriver.Chrome(executable_path=driver_path)# 打开网页
browser.get("https://www.baidu.com")
上面的代码中,我们首先导入了webdriver模块,并指定了Chrome浏览器驱动程序所在的路径。接下来,我们创建了一个Chrome浏览器实例,并打开了百度首页。
模拟用户操作
接下来,我们将介绍如何使用Selenium模拟用户在浏览器中的操作。比如,我们可以使用Selenium来自动登录某个网站,或者自动填写表单等等。
点击元素
要点击一个元素,可以使用click()方法。比如,我们可以点击一个链接:
# 点击百度首页的新闻链接
news_link = browser.find_element_by_link_text("新闻")
news_link.click()
上面的代码中,我们首先找到了百度首页中的新闻链接,然后使用click()方法来点击它。
输入文本
要输入文本,可以使用send_keys()方法。比如,我们可以在搜索框中输入关键字:
# 在百度搜索框中输入关键字
search_box = browser.find_element_by_id("kw")
search_box.send_keys("Python")
上面的代码中,我们首先找到了百度搜索框,然后使用send_keys()方法来输入关键字。
选择元素
有时候,我们需要从下拉列表或者单选框中选择一个选项。可以使用select()方法来实现这个功能。比如,我们可以选择一个下拉列表中的选项:
from selenium.webdriver.support.ui import Select# 选择一个下拉列表中的选项
select = Select(browser.find_element_by_name("select"))
select.select_by_value("value")
上面的代码中,我们首先找到了一个下拉列表,然后创建了一个Select对象。接下来,我们使用select_by_value()方法来选择一个选项。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】
作者:黑马程序员Python
链接:https://www.zhihu.com/question/484129957/answer/3158567803
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
等待元素
有时候,我们需要等待某个元素出现再进行操作。可以使用WebDriverWait类来实现这个功能。比如,我们可以等待一个元素出现后再点击它:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 等待一个元素出现后再点击它
element = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "element_id"))
)
element.click()
上面的代码中,我们使用WebDriverWait类来等待一个元素的出现,然后使用click()方法来点击它。
实战应用
在实际项目中,我们可以使用Selenium来完成一些重复性的任务,比如自动化测试、数据采集等等。下面,我们将介绍如何使用Selenium来爬取某个网站的数据。
分析网站结构
在爬取网站数据之前,我们需要先了解网站的结构。比如,我们可以使用Chrome浏览器的开发者工具来查看网站的HTML代码和CSS样式。
爬取数据
假设我们要爬取某个电商网站的商品数据,包括商品名称、价格、销量等等。我们可以通过以下步骤来实现:
- 打开网站,并搜索关键字;
- 获取搜索结果页面中的商品列表;
- 遍历商品列表,获取每个商品的名称、价格、销量等信息;
- 将商品信息保存到文件中。
下面是代码示例:
# 打开网站,并搜索关键字
browser.get("https://www.example.com/")
search_box = browser.find_element_by_id("search_box")
search_box.send_keys("Python")
search_button = browser.find_element_by_id("search_button")
search_button.click()# 获取搜索结果页面中的商品列表
product_list = browser.find_elements_by_class_name("product")# 遍历商品列表,获取每个商品的名称、价格、销量等信息
for product in product_list:name = product.find_element_by_class_name("name").textprice = product.find_element_by_class_name("price").textsales = product.find_element_by_class_name("sales").text# 将商品信息保存到文件中with open("products.txt", "a") as f:f.write(f"{name}\t{price}\t{sales}\n")
上面的代码中,我们首先打开了某个电商网站,并搜索了关键字。然后获取搜索结果页面中的商品列表,遍历商品列表,获取每个商品的名称、价格、销量等信息,并将商品信息保存到文件中。
技术总结
在本篇文章中,我们介绍了如何使用Python的Selenium库进行Web自动化,并且演示了如何将它应用于实际项目中。如果你想要提高工作效率,或者想要学习如何进行自动化测试、数据采集等等,那么Selenium是一个非常好的选择。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】