目录
1、什么是延时任务,分别可以使用哪些技术实现?
1.2 使用 Redis 和 DB 相结合的思路图以及分析
2、实现添加任务、删除任务、拉取任务
3、实现未来数据的定时更新
4、将数据库中的任务数据,同步到 Redis 中

1、什么是延时任务,分别可以使用哪些技术实现?
延时任务:有固定周期的,有明确的触发时间
延迟队列:没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟

使用场景:
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,则任务取消
场景二:接口对接出现网络问题,1分钟后重试,如果失败,2分钟重试,直到出现阈值终止
常用的技术方案:
DelayQueue(JDK自带):是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素
弊端:使用线程池或者原生 DelayQueue 程序挂掉之后,任务都是放在内存,需要考虑未处理消息的丢失带来的影响,如何保证数据不丢失,需要持久化(磁盘)
RabbitMQ(消息中间件):允许不同应用之间通过消息传递进行通信,提供了可靠的消息传递机制(将消息保存在磁盘中),支持多种消息模式,包括点对点和发布/订阅。RabbitMQ基于AMQP(高级消息队列协议)设计,具有高度的可扩展性和灵活性
使用 Redis 结合 DB 实现:能够充分利用Redis的高性能特性和灵活的数据结构,同时结合数据库的持久化和数据管理能力(存在磁盘,不易丢失),为系统提供高效、实时、可靠的延时任务处理机制
这里我们选用的是 Redis 结合DB进行实现 ![]()
【问题】
为什么选用 Redis + DB ,而不选用 RabbitMQ ?
1、Redis 相对于 RabbitMQ 更加轻量级,对于简单的延时任务队列,可能更倾向于使用轻量级的Redis而不是引入RabbitMQ等消息中间件的复杂性
2、Redis通常更容易集成和维护,因为它是一个简单的键值存储系统,而RabbitMQ是一个完整的消息中间件系统。对于一些小型项目或者对于消息中间件功能的需求不是很大的情况下,选择Redis可能更为经济实惠
1.2 使用 Redis 和 DB 相结合的思路图以及分析
【整体流程图】

【分析问题】
1、为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑(不容易丢失)
2、为什么 Redis 中使用两种数据类型,list 和 zset?
结合场景,考虑效率问题以及算法的时间复杂度
3、在添加 zset 数据的时候,为什么需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题;如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可
2、实现添加任务、删除任务、拉取任务
【数据库表结构信息】
Taskinfo

TaskinfoLog

【添加任务】
将任务添加到数据库中
这里 TaskinfoLog 内置了 version 版本号,即乐观锁,保证同一时刻只有一个线程执行成功;其中,Task 是 DTO 数据,Taskinfo(任务) 与 TaskinfoLog(任务日志)是DB数据
private boolean addTackToDB(Task task) {boolean loop = false;try {//1.保存任务表Taskinfo taskinfo = new Taskinfo();BeanUtils.copyProperties(task, taskinfo);taskinfo.setExecuteTime(new Date(task.getExecuteTime()));taskinfoMapper.insert(taskinfo);task.setTaskId(taskinfo.getTaskId()); //将 任务ID 传给前端//2.保存日志数据TaskinfoLogs taskinfoLogs = new TaskinfoLogs();BeanUtils.copyProperties(taskinfo, taskinfoLogs);taskinfoLogs.setVersion(1);taskinfoLogs.setStatus(ScheduleConstants.SCHEDULED); //初始化taskinfoLogsMapper.insert(taskinfoLogs);loop = true;}catch (Exception exception){exception.printStackTrace();}return loop;}
将任务添加到 Redis 中
这里调用 Calender.getInstance() 获得任务预设时间(这里是当前时间5min后);将小于等于 LocalTime 的任务放入 List 中,否则,则将预设任务放入 Zset 进行暂存
private void addTaskToRedis(Task task) {String key = task.getTaskType() + "_" +task.getPriority();//1.获取未来 5 分钟之后的预设时间Calendar calendar = Calendar.getInstance(); //获取当前日期和时间的日历实例calendar.add(Calendar.MINUTE,5);long calendarTimeInMillis = calendar.getTimeInMillis(); //获取其毫秒值//2.1 若任务执行的时间小于当前时间,则直接放入 list 数据结构中if(task.getExecuteTime() <= System.currentTimeMillis()){cacheService.lLeftPush(ScheduleConstants.TOPIC+key, JSON.toJSONString(task));}else if(task.getExecuteTime() <= calendarTimeInMillis){//2.2 若任务执行的时间大于当前时间 并且 小于等于预设时间(未来5分钟),则直接放入 zset 中按照分值排序进行存储cacheService.zAdd(ScheduleConstants.FUTURE+ key,JSON.toJSONString(task),task.getExecuteTime());}}
调用以上方法
public long addTask(Task task) {//1.添加任务到 DB 中,保证任务的持久化boolean res = addTackToDB(task);if(res) {//2.将任务添加到 redis 中addTaskToRedis(task);}return task.getTaskId();}
【删除任务】
删除数据库中的任务,并更新对应任务的任务日志
private Task deleteTask_UpdateTaskLog(long taskId, int status) {Task task =null;try {//1.删除任务taskinfoMapper.deleteById(taskId);//2.更新任务日志TaskinfoLogs taskinfoLogs = taskinfoLogsMapper.selectById(taskId);taskinfoLogs.setStatus(status);taskinfoLogsMapper.updateById(taskinfoLogs);task = new Task();BeanUtils.copyProperties(taskinfoLogs,task);task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime()); //更新当前执行时间}catch (Exception e){log.error("任务处理失败,异常任务ID:{}",taskId);e.printStackTrace();}return task;}
根据任务的时间类型,删除 Redis 中 List 与 Zset 中保存的任务信息
private void removeTaskFromRedis(Task task) {String key = task.getTaskType() + "_" +task.getPriority();//1. 执行时间小于当前时间,则进行删除任务if(task.getExecuteTime() <= System.currentTimeMillis()){cacheService.lRemove(ScheduleConstants.TOPIC+key,0,JSON.toJSONString(task)); //list}else{cacheService.zRemove(ScheduleConstants.FUTURE+key,JSON.toJSONString(task)); //zset}}
调用以上方法
public boolean cancelTask(long taskId) {boolean loop = false;//1.删除任务,更新任务日志Task task = deleteTask_UpdateTaskLog (taskId,ScheduleConstants.CANCELLED);//2.删除 redis 中的数据if(task!=null){removeTaskFromRedis(task);loop = true;}return loop;}
【拉取任务】
由于 List 中存储的任务是以 JSON 的形式进行存储的,所以需要将其进行 parseObj 序列化
使用 lRightPop() 将需要立即执行的任务从 List 中拉取出来,并更新任务日志的状态
public Task pullTask(int type, int priority) {Task task = null;try {String key = type + "_" +priority;//1.从 list 中使用 pop 拉取任务String taskJSON = cacheService.lRightPop(key); //解析出来的信息是 JSON 字段if(StringUtils.isNotBlank(taskJSON)){task = JSON.parseObject(taskJSON, Task.class);//1.1.在数据库中删除任务,更新任务日志deleteTask_UpdateTaskLog(task.getTaskId(), ScheduleConstants.EXECUTED); //已执行}}catch (Exception e){e.printStackTrace();log.error("拉取任务异常!");}return task;}
3、实现未来数据的定时更新
将任务根据执行的时间,分别存入 Redis 中的 List 与 Zset 中后
还需要判断 Zset 中进行预设时间的任务,是否到了需要执行的时间,到了的话需要进行任务消费
所以,需要设定一个时间,定时的将 Zset 中的数据推送到 List 中,避免任务的堆积与消费延时
【分析问题】
在任务推送时,需要将 Redis 中所有的 future 任务提取出来进行遍历判断(通过 key 获取)
在进行全局模糊匹配 Key 值获取的时候,一般有两种方法:Keys 和 Scan
Keys:keys的模糊匹配功能很方便也很强大,但是在生产环境需要慎用;开发中使用 keys的模糊匹配却发现 Redis 的 CPU 使用率极高,Redis是单线程,会被堵塞
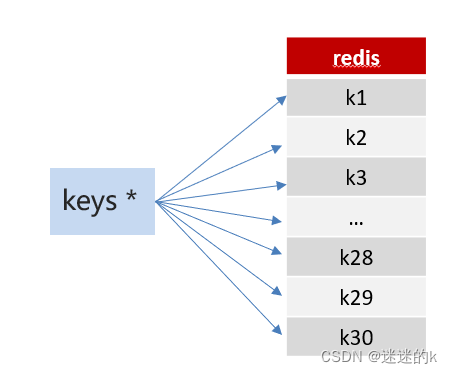
Scan:SCAN 命令是一个基于游标的迭代器,SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程
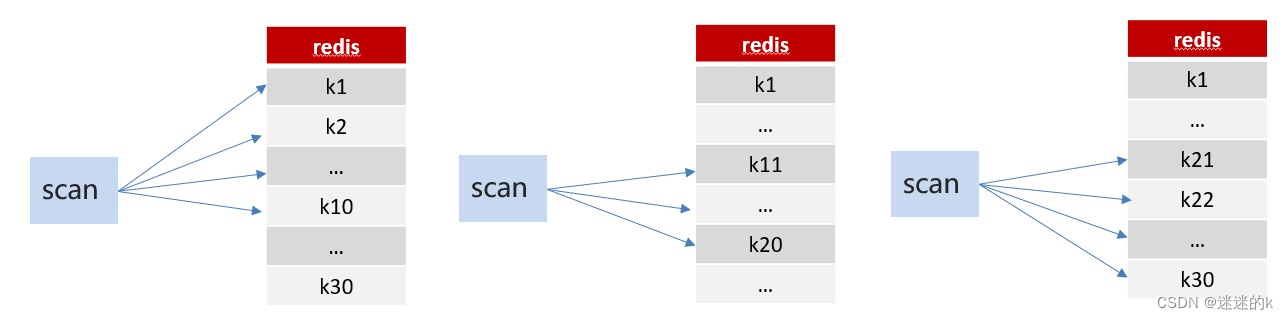
这里,我们使用 Scan 技术进行模糊匹配
根据模糊匹配获取对应的任务后,需要进行消息的推送,Redis 中一般存在两种消息交互的方法:
普通 Redis 客户端和服务器交互模式
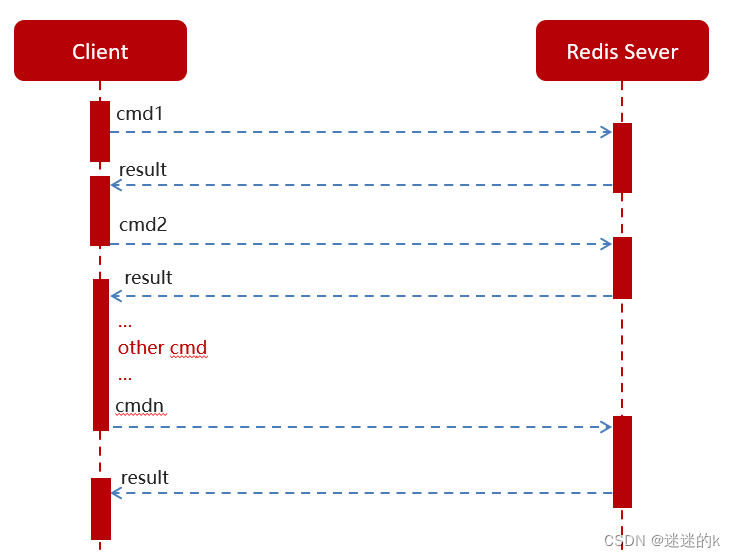
Pipeline 消息管道的请求模型

根据场景以及考虑到效率的问题,这里我们使用管道技术进行消息的推送
以上代码实现:
//1.查询所有未来数值的 keySet<String> future_keys = cacheService.scan(ScheduleConstants.FUTURE + "*");future_keys.forEach(new Consumer<String>() { //future_100_20@Overridepublic void accept(String future_key) {//以 future 进行分组 =》 future + 100_20 ,然后以 topic 前缀进行拼接String topic_Key = ScheduleConstants.TOPIC + future_key.split(ScheduleConstants.FUTURE)[1];//1.1 根据 key 查询符合条件的信息(即判断执行的时间是否大于当前时间,若小于或等于,则符合条件)Set<String> tasks = cacheService.zRangeByScore(future_key, 0, System.currentTimeMillis());//2. 进行同步数据if (!tasks.isEmpty()) {//2.1 使用管道技术,将任务数据批量同步到 list 中,等待消费cacheService.refreshWithPipeline(future_key, topic_Key, tasks);log.info("将定时任务 " + future_key + " 刷新到了 " + topic_Key);}}});
【分析问题】
这是在单服务下进行消息的推送,若在多服务下进行,由于多个 Tomcat 中对应着不同的 JVM ,所以所控制的锁也不一样,这样,就又会出现线程同步问题
【解决问题】
对于这种情况,使用分布式锁可能是最好的选择;而实现分布式锁的方法多种多样,而 Redis 中所提供的 SetNX 正好可以解决

SetNX 分布式锁代码如下:
/*** 使用 setnx 实现分布式锁*/public String tryLock(String name, long expire) {name = name + "_lock";String token = UUID.randomUUID().toString();RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory();RedisConnection conn = factory.getConnection();try {//参考redis命令://set key value [EX seconds] [PX milliseconds] [NX|XX]Boolean result = conn.set(name.getBytes(),token.getBytes(),Expiration.from(expire, TimeUnit.MILLISECONDS),RedisStringCommands.SetOption.SET_IF_ABSENT //NX);if (result != null && result)return token;} finally {RedisConnectionUtils.releaseConnection(conn, factory,false);}return null;}
完整代码如下:
@Scheduled(cron = "0 */1 * * * ?") //定时,每分钟刷新一次public void refreshTask(){String token = cacheService.tryLock("FUTURE_TASK_SN", 1000 * 30);if(StringUtils.isNotBlank(token) && token.length()!=0) { //进行 NX 加锁操作,使不同服务下同一时刻只能有一个抢占当前任务//1.查询所有未来数值的 keySet<String> future_keys = cacheService.scan(ScheduleConstants.FUTURE + "*");future_keys.forEach(new Consumer<String>() { //future_100_20@Overridepublic void accept(String future_key) {//以 future 进行分组 =》 future + 100_20 ,然后以 topic 前缀进行拼接String topic_Key = ScheduleConstants.TOPIC + future_key.split(ScheduleConstants.FUTURE)[1];//1.1 根据 key 查询符合条件的信息(即判断执行的时间是否大于当前时间,若小于或等于,则符合条件)Set<String> tasks = cacheService.zRangeByScore(future_key, 0, System.currentTimeMillis());//2. 进行同步数据if (!tasks.isEmpty()) {//2.1 使用管道技术,将任务数据批量同步到 list 中,等待消费cacheService.refreshWithPipeline(future_key, topic_Key, tasks);log.info("将定时任务 " + future_key + " 刷新到了 " + topic_Key);}}});}}
4、将数据库中的任务数据,同步到 Redis 中
由于时间是流动的,任务的执行时间是死的,所以需要进行动态的数据更新,保证数据的有效性
流程图如下所示:
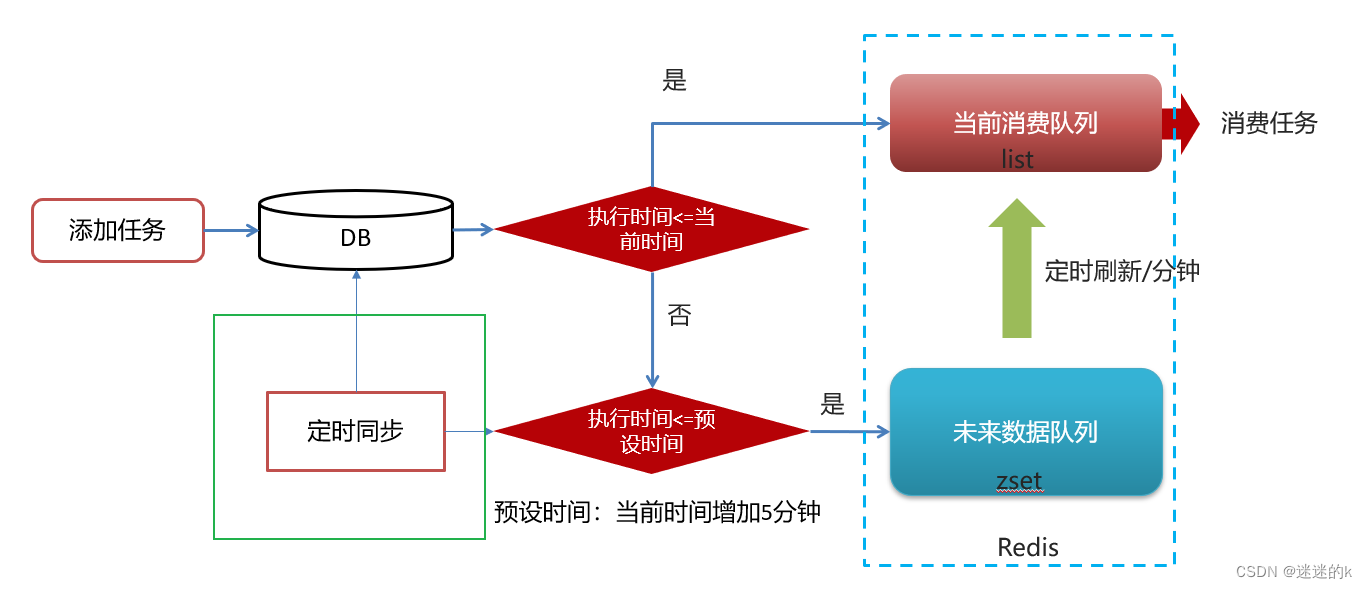
为了数据同步的时候,避免数据库中的数据,与 Redis 中未消费的任务的重复;所以,需要清除 Redis 中所有任务的缓存数据,以确保同步到 Redis 中的数据是最新的
public void clearCacheByRedis(){Set<String> topic_keys = cacheService.scan(ScheduleConstants.TOPIC + "*"); //list 中的所有任务的 keySet<String> future_keys = cacheService.scan(ScheduleConstants.FUTURE + "*"); //zset 中所有任务中的 keycacheService.delete(topic_keys);cacheService.delete(future_keys);}
任务同步的代码如下:
这里使用 @PostConstruct 注解 进行方法的初始化操作(根据实际情况定义)
@PostConstruct //进行初始化操作,每当启动微服务时,当前方法就会执行一次@Scheduled(cron = "0 */5 * * * ?") //每五分钟执行一次public void renewDBTasks_To_Redis(){//1.清除 redis 中的缓存clearCacheByRedis();//2.查询 DB 中执行时间小于预设时间的任务//2.1.获取未来 5 分钟之后的预设时间Calendar calendar = Calendar.getInstance(); //获取当前日期和时间的日历实例calendar.add(Calendar.MINUTE,5);long calendarTimeInMillis = calendar.getTimeInMillis(); //获取其毫秒值LambdaQueryWrapper<Taskinfo> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.lt(Taskinfo::getExecuteTime,calendarTimeInMillis);List<Taskinfo> taskInfos = taskinfoMapper.selectList(queryWrapper);//3.将数据库中数据同步保存到 redis 中if(taskInfos!=null && taskInfos.size()>0) {taskInfos.forEach(new Consumer<Taskinfo>() {@Overridepublic void accept(Taskinfo taskinfo) {Task task = new Task();BeanUtils.copyProperties(taskinfo,task);task.setExecuteTime(taskinfo.getExecuteTime().getTime());//3.1 由它内部判断,是存储在 list 中还是 zset 中addTaskToRedis(task);}});}log.info("成功将数据库中的数据更新同步到了 redis 中");}
所有方法的完整代码:
@Slf4j
@Service
@Transactional
public class TaskServiceImpl implements TaskService {@Resourceprivate TaskinfoMapper taskinfoMapper;@Resourceprivate TaskinfoLogsMapper taskinfoLogsMapper;@Resourceprivate CacheService cacheService;/*** 添加任务* @param task 任务对象* @return 任务ID*/@Overridepublic long addTask(Task task) {//1.添加任务到 DB 中,保证任务的持久化boolean res = addTackToDB(task);if(res) {//2.将任务添加到 redis 中addTaskToRedis(task);}return task.getTaskId();}/*** 将已完成的任务删除*/@Overridepublic boolean cancelTask(long taskId) {boolean loop = false;//1.删除任务,更新任务日志Task task = deleteTask_UpdateTaskLog (taskId,ScheduleConstants.CANCELLED);//2.删除 redis 中的数据if(task!=null){removeTaskFromRedis(task);loop = true;}return loop;}/*** 按照类型和优先级进行拉取 list 中的任务*/@Overridepublic Task pullTask(int type, int priority) {Task task = null;try {String key = type + "_" +priority;//1.从 list 中使用 pop 拉取任务String taskJSON = cacheService.lRightPop(key); //解析出来的信息是 JSON 字段if(StringUtils.isNotBlank(taskJSON)){task = JSON.parseObject(taskJSON, Task.class);//1.1.在数据库中删除任务,更新任务日志deleteTask_UpdateTaskLog(task.getTaskId(), ScheduleConstants.EXECUTED); //已执行}}catch (Exception e){e.printStackTrace();log.error("拉取任务异常!");}return task;}/*** 未来数据的更新,将 zset 中的任务推送到 list 中*/@Scheduled(cron = "0 */1 * * * ?") //定时,每分钟刷新一次public void refreshTask(){String token = cacheService.tryLock("FUTURE_TASK_SN", 1000 * 30);if(StringUtils.isNotBlank(token) && token.length()!=0) { //进行 NX 加锁操作,使不同服务下同一时刻只能有一个抢占当前任务//1.查询所有未来数值的 keySet<String> future_keys = cacheService.scan(ScheduleConstants.FUTURE + "*");future_keys.forEach(new Consumer<String>() { //future_100_20@Overridepublic void accept(String future_key) {//以 future 进行分组 =》 future + 100_20 ,然后以 topic 前缀进行拼接String topic_Key = ScheduleConstants.TOPIC + future_key.split(ScheduleConstants.FUTURE)[1];//1.1 根据 key 查询符合条件的信息(即判断执行的时间是否大于当前时间,若小于或等于,则符合条件)Set<String> tasks = cacheService.zRangeByScore(future_key, 0, System.currentTimeMillis());//2. 进行同步数据if (!tasks.isEmpty()) {//2.1 使用管道技术,将任务数据批量同步到 list 中,等待消费cacheService.refreshWithPipeline(future_key, topic_Key, tasks);log.info("将定时任务 " + future_key + " 刷新到了 " + topic_Key);}}});}}/*** 数据库中的任务同步到 redis 中,保证数据的一致性*/@PostConstruct //进行初始化操作,每当启动微服务时,当前方法就会执行一次@Scheduled(cron = "0 */5 * * * ?") //每五分钟执行一次public void renewDBTasks_To_Redis(){//1.清除 redis 中的缓存clearCacheByRedis();//2.查询 DB 中执行时间小于预设时间的任务//2.1.获取未来 5 分钟之后的预设时间Calendar calendar = Calendar.getInstance(); //获取当前日期和时间的日历实例calendar.add(Calendar.MINUTE,5);long calendarTimeInMillis = calendar.getTimeInMillis(); //获取其毫秒值LambdaQueryWrapper<Taskinfo> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.lt(Taskinfo::getExecuteTime,calendarTimeInMillis);List<Taskinfo> taskInfos = taskinfoMapper.selectList(queryWrapper);//3.将数据库中数据同步保存到 redis 中if(taskInfos!=null && taskInfos.size()>0) {taskInfos.forEach(new Consumer<Taskinfo>() {@Overridepublic void accept(Taskinfo taskinfo) {Task task = new Task();BeanUtils.copyProperties(taskinfo,task);task.setExecuteTime(taskinfo.getExecuteTime().getTime());//3.1 由它内部判断,是存储在 list 中还是 zset 中addTaskToRedis(task);}});}log.info("成功将数据库中的数据更新同步到了 redis 中");}/******************************************************************************************************************** 删除 redis 中对应的任务*/private void removeTaskFromRedis(Task task) {String key = task.getTaskType() + "_" +task.getPriority();//1. 执行时间小于当前时间,则进行删除任务if(task.getExecuteTime() <= System.currentTimeMillis()){cacheService.lRemove(ScheduleConstants.TOPIC+key,0,JSON.toJSONString(task)); //list}else{cacheService.zRemove(ScheduleConstants.FUTURE+key,JSON.toJSONString(task)); //zset}}/*** 删除 redis 中所有的缓存数据*/public void clearCacheByRedis(){Set<String> topic_keys = cacheService.scan(ScheduleConstants.TOPIC + "*"); //list 中的所有任务的 keySet<String> future_keys = cacheService.scan(ScheduleConstants.FUTURE + "*"); //zset 中所有任务中的 keycacheService.delete(topic_keys);cacheService.delete(future_keys);}/*** 在数据库中删除任务,更新任务日志*/private Task deleteTask_UpdateTaskLog(long taskId, int status) {Task task =null;try {//1.删除任务taskinfoMapper.deleteById(taskId);//2.更新任务日志TaskinfoLogs taskinfoLogs = taskinfoLogsMapper.selectById(taskId);taskinfoLogs.setStatus(status);taskinfoLogsMapper.updateById(taskinfoLogs);task = new Task();BeanUtils.copyProperties(taskinfoLogs,task);task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime()); //更新当前执行时间}catch (Exception e){log.error("任务处理失败,异常任务ID:{}",taskId);e.printStackTrace();}return task;}/*** 将任务存到 redis 中*/private void addTaskToRedis(Task task) {String key = task.getTaskType() + "_" +task.getPriority();//1.获取未来 5 分钟之后的预设时间Calendar calendar = Calendar.getInstance(); //获取当前日期和时间的日历实例calendar.add(Calendar.MINUTE,5);long calendarTimeInMillis = calendar.getTimeInMillis(); //获取其毫秒值//2.1 若任务执行的时间小于当前时间,则直接放入 list 数据结构中if(task.getExecuteTime() <= System.currentTimeMillis()){cacheService.lLeftPush(ScheduleConstants.TOPIC+key, JSON.toJSONString(task));}else if(task.getExecuteTime() <= calendarTimeInMillis){//2.2 若任务执行的时间大于当前时间 并且 小于等于预设时间(未来5分钟),则直接放入 zset 中按照分值排序进行存储cacheService.zAdd(ScheduleConstants.FUTURE+ key,JSON.toJSONString(task),task.getExecuteTime());}}/*** 将任务添加到数据库中*/private boolean addTackToDB(Task task) {boolean loop = false;try {//1.保存任务表Taskinfo taskinfo = new Taskinfo();BeanUtils.copyProperties(task, taskinfo);taskinfo.setExecuteTime(new Date(task.getExecuteTime()));taskinfoMapper.insert(taskinfo);task.setTaskId(taskinfo.getTaskId()); //将 任务ID 传给前端//2.保存日志数据TaskinfoLogs taskinfoLogs = new TaskinfoLogs();BeanUtils.copyProperties(taskinfo, taskinfoLogs);taskinfoLogs.setVersion(1);taskinfoLogs.setStatus(ScheduleConstants.SCHEDULED); //初始化taskinfoLogsMapper.insert(taskinfoLogs);loop = true;}catch (Exception exception){exception.printStackTrace();}return loop;}


![[MySQL] MySQL 表的增删查改](https://img-blog.csdnimg.cn/5c67abcd3dac4a119c643865e33383ba.png)